Best AI tools for< Extract Data From Text >
20 - AI tool Sites
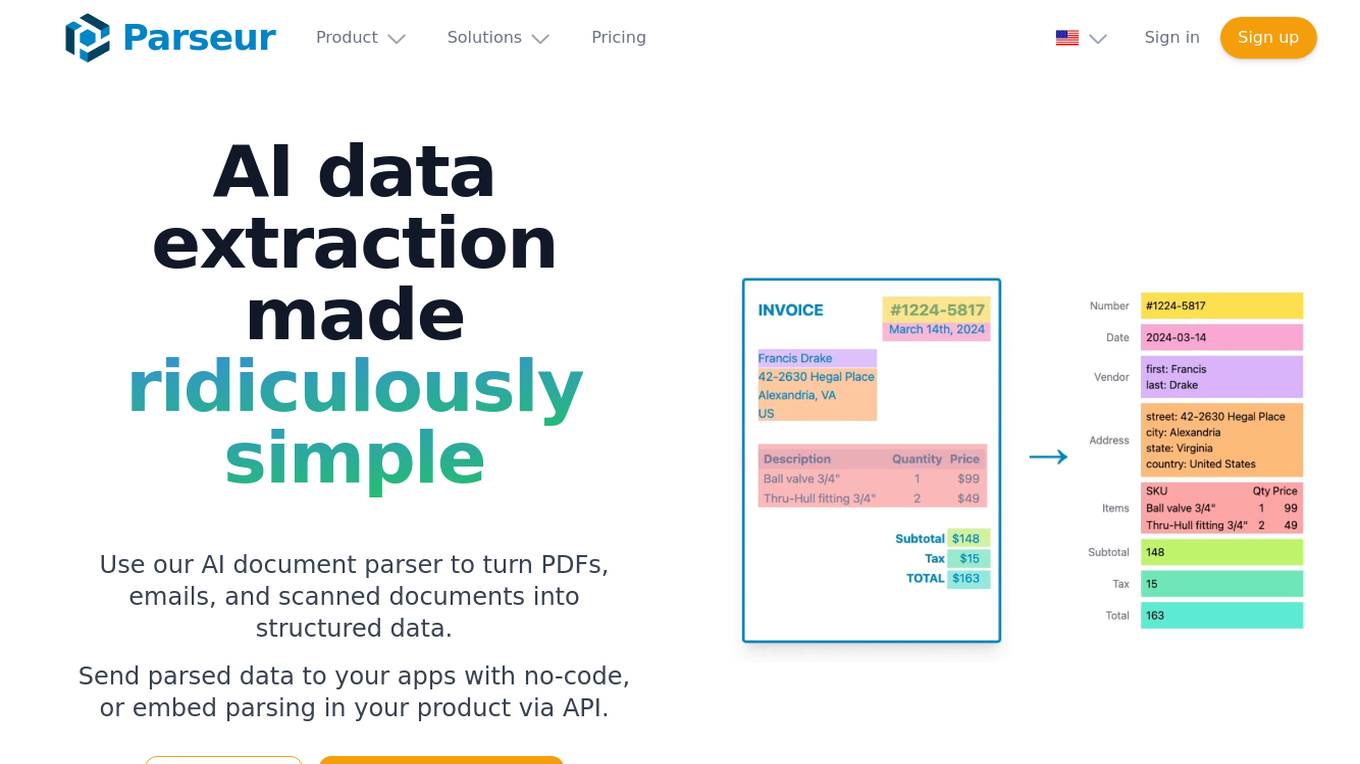
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
Docugami
Docugami is an AI-powered document engineering platform that enables business users to extract, analyze, and automate data from various types of documents. It empowers users with immediate impact without the need for extensive machine learning investments or IT development. Docugami's proprietary Business Document Foundation Model leverages Generative AI to transform unstructured text into structured information, allowing users to unlock insights and drive business processes efficiently.
PrivacyDoc
PrivacyDoc is an AI-powered portal that allows users to analyze and query PDF and ebooks effortlessly. By leveraging advanced NLP technology, PrivacyDoc enables users to uncover insights and conduct thorough document analysis. The platform offers features such as easy file upload, query functionality, enhanced security measures, and free access to powerful PDF analysis tools. With PrivacyDoc, users can experience the convenience of logging in with their Google account, submitting queries for prompt AI-driven responses, and ensuring data privacy with secure file handling.
Docugami
Docugami is an AI-powered document engineering platform that enables business users to extract, analyze, and automate data from various types of documents. It empowers users with immediate impact without the need for extensive machine learning investments or IT development. Docugami's proprietary Business Document Foundation Model and Generative AI technology transform unstructured text and tables into structured information, allowing users to unlock insights, increase productivity, and ensure compliance.

Extractify.co
Extractify.co is a website that offers a variety of tools and services for extracting information from different sources. The platform provides users with the ability to extract data from websites, documents, and other sources in a quick and efficient manner. With a user-friendly interface, Extractify.co aims to simplify the process of data extraction for individuals and businesses alike. Whether you need to extract text, images, or other types of data, Extractify.co has the tools to help you get the job done. The platform is designed to be intuitive and easy to use, making it accessible to users of all skill levels.

Scrol.ai
Scrol.ai is a powerful AI-powered tool that allows users to search, analyze, and generate data from various sources. It utilizes advanced language models like GPT-4 and ChatGPT to provide users with a seamless and efficient way to extract insights, summarize information, and create new content. With its user-friendly interface and robust features, Scrol.ai empowers users to streamline their workflow, enhance productivity, and make informed decisions.
ChatPDF
ChatPDF is an AI-powered tool that allows users to interact with PDF documents in a conversational manner. It uses natural language processing (NLP) to understand user queries and provide relevant information or perform actions on the PDF. With ChatPDF, users can ask questions about the content of the PDF, search for specific information, extract data, translate text, and more, all through a simple chat-like interface.
Axiom.ai
Axiom.ai is a no-code browser automation tool that allows users to automate website actions and repetitive tasks on any website or web app. It is a Chrome Extension that is simple to install and free to try. Once installed, users can pin Axiom to the Chrome Toolbar and click on the icon to open and close. Users can build custom bots or use templates to automate actions like clicking, typing, and scraping data from websites. Axiom.ai can be integrated with Zapier to trigger automations based on external events.
Dreamervision.ai
Dreamervision.ai is an innovative AI tool that utilizes advanced machine learning algorithms to analyze and interpret images and videos. The tool is designed to provide users with valuable insights and information based on visual content, enabling them to make informed decisions and enhance their understanding of the world around them. With its cutting-edge technology, Dreamervision.ai offers a seamless and efficient way to extract meaningful data from visual media, making it a valuable asset for professionals in various industries.

FranzAI LLM Playground
FranzAI LLM Playground is an AI-powered tool that helps you extract, classify, and analyze unstructured text data. It leverages transformer models to provide accurate and meaningful results, enabling you to build data applications faster and more efficiently. With FranzAI, you can accelerate product and content classification, enhance data interpretation, and advance data extraction processes, unlocking key insights from your textual data.
Airparser
Airparser is an AI-powered email and document parser tool that revolutionizes data extraction by utilizing the GPT parser engine. It allows users to automate the extraction of structured data from various sources such as emails, PDFs, documents, and handwritten texts. With features like automatic extraction, export to multiple platforms, and support for multiple languages, Airparser simplifies data extraction processes for individuals and businesses. The tool ensures data security and offers seamless integration with other applications through APIs and webhooks.
FileAI
The FileAI website offers an AI-powered file reading assistant that specializes in data extraction from structured documents like financial statements, legal documents, and research papers. It automates tasks related to legal and compliance review, finance and accounting report preparation, and research and academia support. The tool aims to streamline document processing, enhance learning processes, and improve research efficiency. With features like summarizing complex texts, extracting key information, and detecting plagiarism, FileAI caters to users in various industries and educational fields. The platform prioritizes data security and user privacy, ensuring that data is used solely for its intended purpose and deleted after 7 days of non-use.
basebox
basebox is an AI application designed to provide secure and efficient AI solutions for businesses across various industries. It offers a range of features such as secure text editing, data extraction from PDFs and Excel documents, academic text summarization, multilingual translation, and blog post creation. With a focus on data privacy and security, basebox ensures end-to-end encryption, GDPR compliance, and hosting in Europe. The application is user-friendly, requiring no technical expertise for setup, and offers transparent pricing based on actual usage.
AlphaResearch
AlphaResearch is an AI-powered search engine and research platform for investors. It provides access to millions of global filings, transcripts, press releases, and reports, and uses machine learning and NLP techniques to extract insights from text data. AlphaResearch helps investors save time on research, understand market sentiment, and make better investment decisions.
Visus
Visus is a tool that allows you to create your own ChatGPT AI. With Visus, you can train your AI on your own data, ask it questions, and get instant answers. Visus is designed to understand your language and provide quick and accurate responses to any question you may have about your documents. It can help you uncover valuable insights from your data quickly and effortlessly.
Base64.ai
Base64.ai is an AI-powered document intelligence platform that offers a comprehensive solution for document processing and data extraction. It leverages advanced AI technology to streamline workflows, improve accuracy, and drive digital transformation for organizations. With features like Generative AI agents, workflow automation, and data intelligence, Base64.ai enables users to extract insights from structured and unstructured documents with ease. The platform is designed to enhance efficiency, reduce processing time, and increase productivity by eliminating manual document processing tasks.
TextUnbox
TextUnbox is an AI-powered tool that allows users to extract text from images, generate images from text descriptions, translate text, remove image backgrounds, and more. It supports over 20 languages and can be used in the browser or integrated into custom solutions using its REST API.
TextMine
TextMine is an AI-powered knowledge base that helps businesses analyze, manage, and search thousands of documents. It uses AI to analyze unstructured textual data and document databases, automatically retrieving key terms to help users make informed decisions. TextMine's features include a document vault for storing and managing documents, a categorization system for organizing documents, and a data extraction tool for extracting insights from documents. TextMine can help businesses save time, money, and improve efficiency by automating manual data entry and information retrieval tasks.
Nuclia
Nuclia is an AI-powered search engine that helps businesses unlock the value of their unstructured data. With Nuclia, businesses can quickly and easily search, analyze, and extract insights from their data, regardless of its format or location. Nuclia's AI capabilities include natural language processing, machine learning, and deep learning, which allow it to understand the context and meaning of data, and to generate human-like text and code. Nuclia is used by businesses of all sizes across a variety of industries, including financial services, healthcare, manufacturing, and retail.
1 - Open Source AI Tools

instructor-js
Instructor is a Typescript library for structured extraction in Typescript, powered by llms, designed for simplicity, transparency, and control. It stands out for its simplicity, transparency, and user-centric design. Whether you're a seasoned developer or just starting out, you'll find Instructor's approach intuitive and steerable.
20 - OpenAI Gpts
Spreadsheet Composer
Magically turning text from emails, lists and website content into spreadsheet tables
PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.

Regex Wizard
Generate and explain regex patterns from your description, it support English and Chinese.


QCM
ce GPT va recevoir des images dans lesquelles il y a des questions QCM codingame ou Problem Solving sur les sujets : Java, Hibernate, Angular, Spring Boot, SQL. Il doit extraire le texte depuis l'image et répondre au question QCM le plus rapidement possible.
FREE Keyword Extraction Tool
Keyword Extraction Tool: Efficiently extracts keywords from various texts, social media, and customer feedback with our user-friendly, scalable tool.

kz image 2 typescript 2 image
Generate a Structured description in typescript format from the image and generate an image from that description. and OCR
Property Manager Document Assistant
Provides analysis and data extraction of Property Management documents and contracts for managers

Fill PDF Forms
Fill legal forms & complex PDF documents easily! Upload a file, provide data sources and I'll handle the rest.