Best AI tools for< Evaluate Trained Models >
20 - AI tool Sites
Fritz AI
Fritz AI is an AI tool that scans and ranks all AI tools, apps, and websites based on a set of criteria to determine the best and most ethical options. They provide technical guides, reviews, and tutorials to help users get started with machine learning. Fritz AI focuses on ethics, functionality, user experience, and innovation when evaluating tools. Users can contribute tool suggestions and collaborate with the Fritz AI team. The platform also offers beginner-friendly guides, consulting services, and promotes ethical use of AI and machine learning technologies.
TenderPilot
TenderPilot is an AI-powered SaaS platform designed for Australian small and medium businesses to improve their success in government tenders. It guides users through analyzing, writing, reviewing, and submitting tender proposals efficiently. The platform is trained on actual government procurement policies and evaluation models, offering expert strategy, secure data hosting, and tailored bid recommendations to help SMEs win more contracts faster and smarter.

Machine Translation Research Hub
This website is a comprehensive resource for research in statistical and neural machine translation. It provides information, tools, and datasets related to the translation of text from one human language to another using computer algorithms trained on vast amounts of translated text.
micro1
micro1 is an AI recruitment tool that leverages human data produced by subject matter experts to help companies identify and hire top talent efficiently. The platform offers end-to-end post-training solutions, high-quality data for model training, pre-vetted AI trainers, and enterprise-grade LLM evaluations. With a focus on tech startups, staffing agencies, and enterprises, micro1 aims to streamline the recruitment process and save costs for businesses.
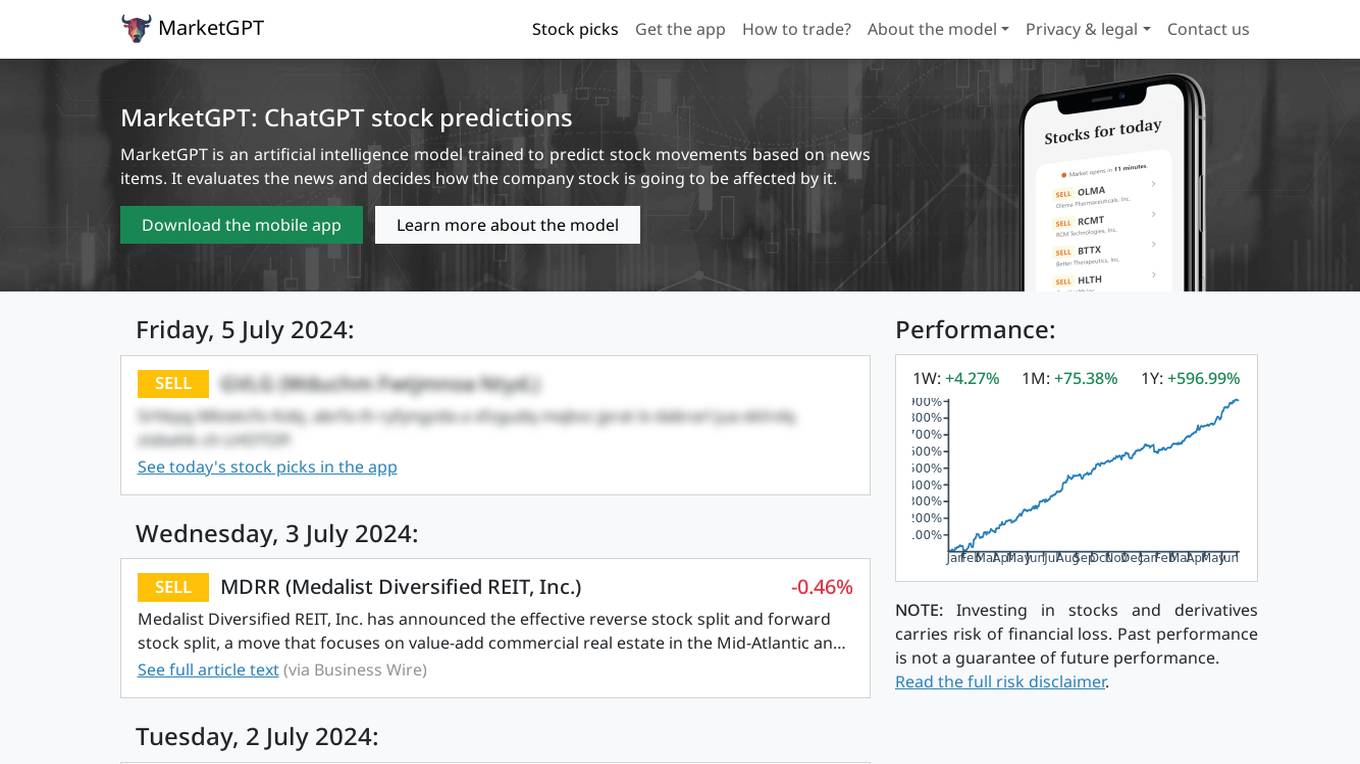
MarketGPT
MarketGPT is an artificial intelligence model trained to predict stock movements based on news items. It evaluates the news and decides how the company stock is going to be affected by it. Users can access the model through the MarketGPT website or mobile app to get stock predictions and picks. The model's performance can be viewed for different time frames such as 1 week, 1 month, and 1 year. However, users are advised that investing in stocks and derivatives carries a risk of financial loss, and past performance is not a guarantee of future performance. MarketGPT is designed to assist users in making informed decisions in the stock market.
Qumis
Qumis is an AI Coverage Intelligence Platform designed for insurance professionals. It offers attorney-trained AI to help users understand insurance policies with legal-grade analysis and market intelligence. The platform allows for quick and accurate coverage assessments, defensible decision-making, and compliance checks. Qumis is trusted by industry leaders for its precision and efficiency in analyzing policies and delivering market-backed insights.
Studious Score AI
Studious Score AI is an AI-powered platform that offers knowledge and skill evaluation services supported by reputable individuals and organizations. The platform aims to revolutionize credentialing by providing a new approach. Studious Score AI is on a mission to establish itself as the global benchmark for assessing skills and knowledge in various aspects of life. Users can explore different categories and unlock their potential through the platform's innovative evaluation methods.
Emerj
Emerj is a leading provider of enterprise AI insights, research, and connections to the right AI tools and providers. We cover AI use-cases and impact in the world’s largest organizations. Our mission is to help businesses understand and implement AI to achieve their business goals.
BodyFatEstimator.ai
BodyFatEstimator.ai is an AI tool that analyzes photos of people and estimates their body fat percentage. It uses computer vision to evaluate visible body composition, fat distribution, and proportions directly. Users can upload a photo and receive a visual body fat estimate in seconds. The tool is designed for frequent progress tracking and is ideal for weekly or monthly check-ins to understand changes in body composition over time.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, acting as a one-person team for their business dreams. From evaluating and assessing business ideas to creating detailed business plans, RebeccAi revolutionizes idea validation with the power of AI.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.
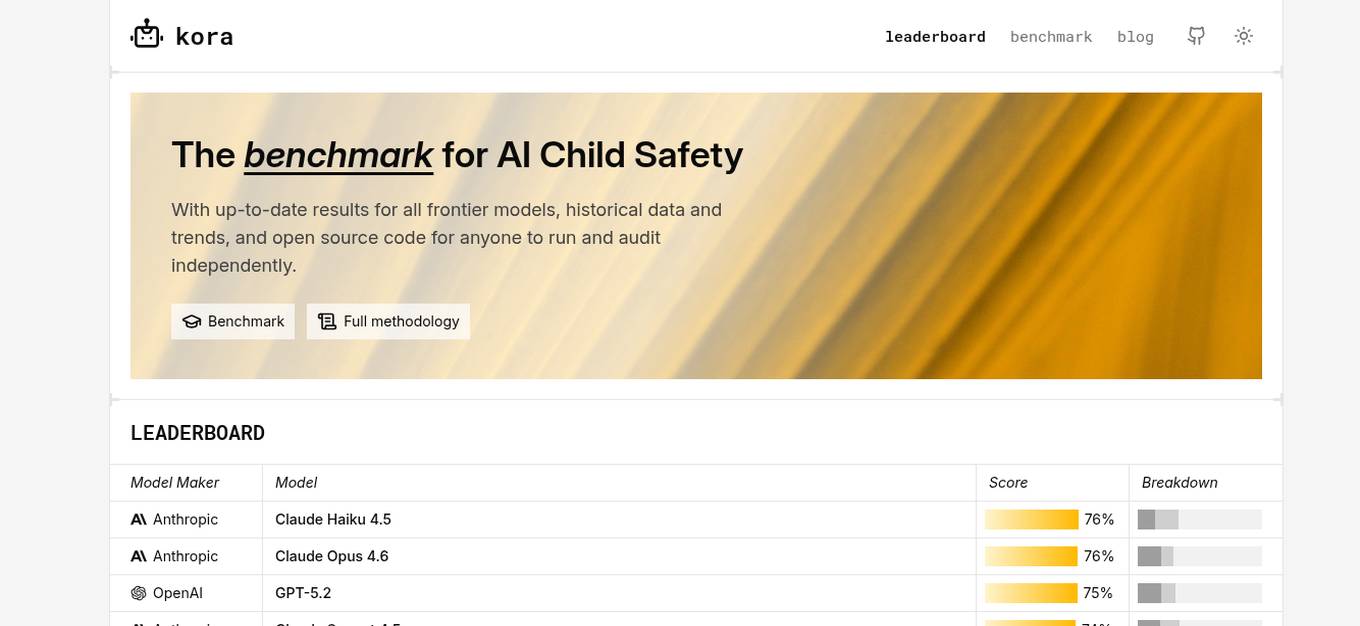
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.

Brevoir
Brevoir is an AI-powered decision-grade due diligence tool designed for startup investing. It consolidates founder diligence, market and competitor research, risk assessment, and investment-ready writeups in one platform. Tailored for angel investors and startup evaluators, Brevoir streamlines the startup evaluation process by extracting key information from pitch decks or company URLs, verifying claims, mapping competitors, and providing structured reports with risks and opportunities. The tool aims to provide clear answers, identify market trends, evaluate team credibility, assess traction and risks, and offer pricing plans that scale with user needs.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.
1 - Open Source AI Tools
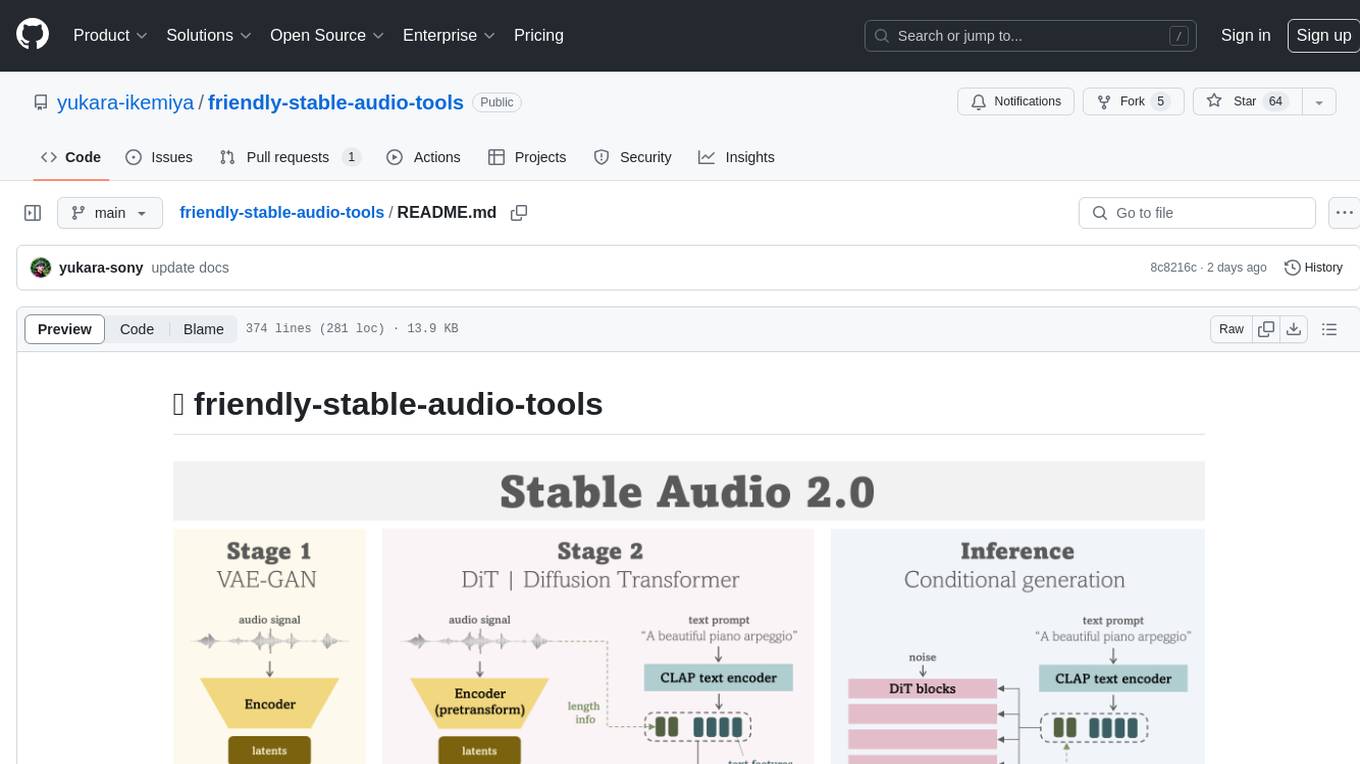
friendly-stable-audio-tools
This repository is a refactored and updated version of `stable-audio-tools`, an open-source code for audio/music generative models originally by Stability AI. It contains refactored codes for improved readability and usability, useful scripts for evaluating and playing with trained models, and instructions on how to train models such as `Stable Audio 2.0`. The repository does not contain any pretrained checkpoints. Requirements include PyTorch 2.0 or later for Flash Attention support and Python 3.8.10 or later for development. The repository provides guidance on installing, building a training environment using Docker or Singularity, logging with Weights & Biases, training configurations, and stages for VAE-GAN and Diffusion Transformer (DiT) training.
20 - OpenAI Gpts

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch

Corporate Trainer
Develops training programs, customizing content to fit corporate culture and objectives.
Pocket Training Activity Expert
Expert in engaging, interactive training methods and activities.

Workshop Builder
Create an actionable plan for a workshop using expert facilitator knowledge


Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.