Best AI tools for< Evaluate Llm Quality >
20 - AI tool Sites
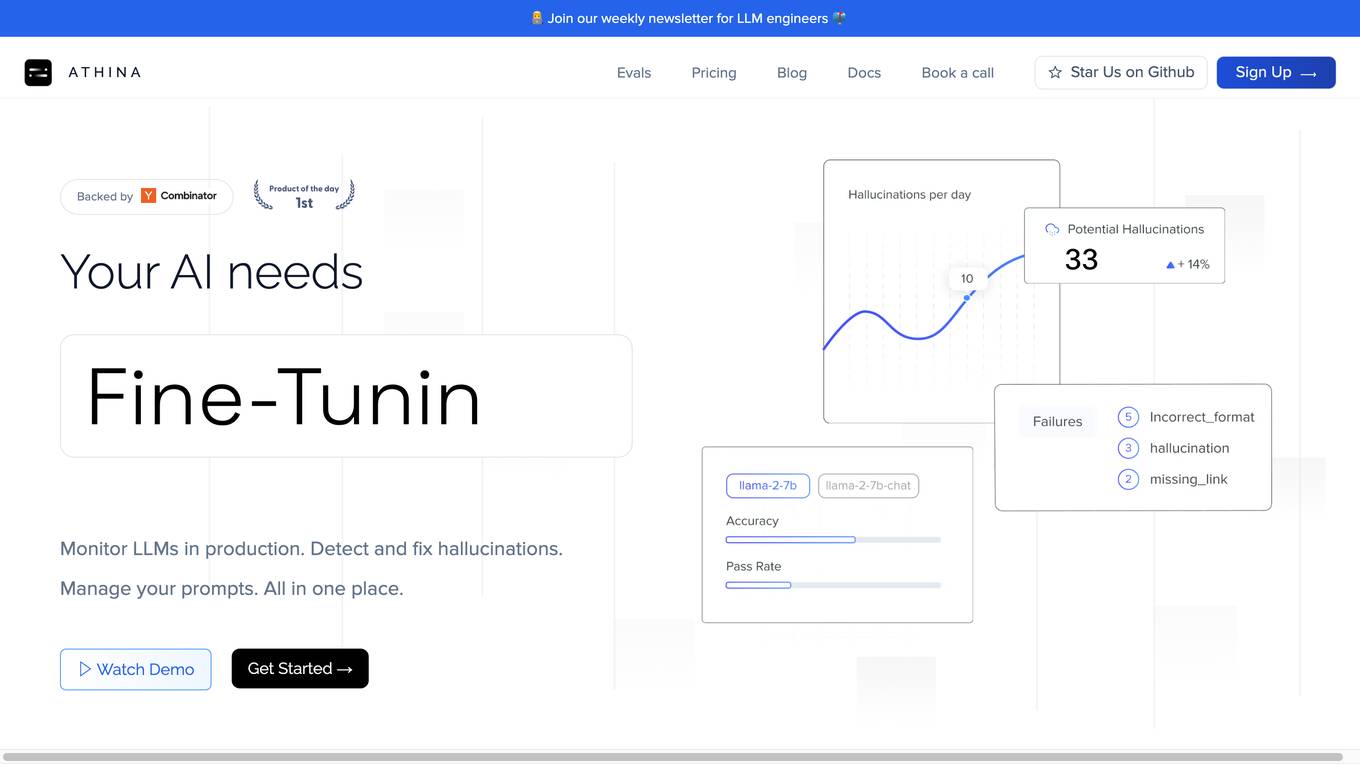
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
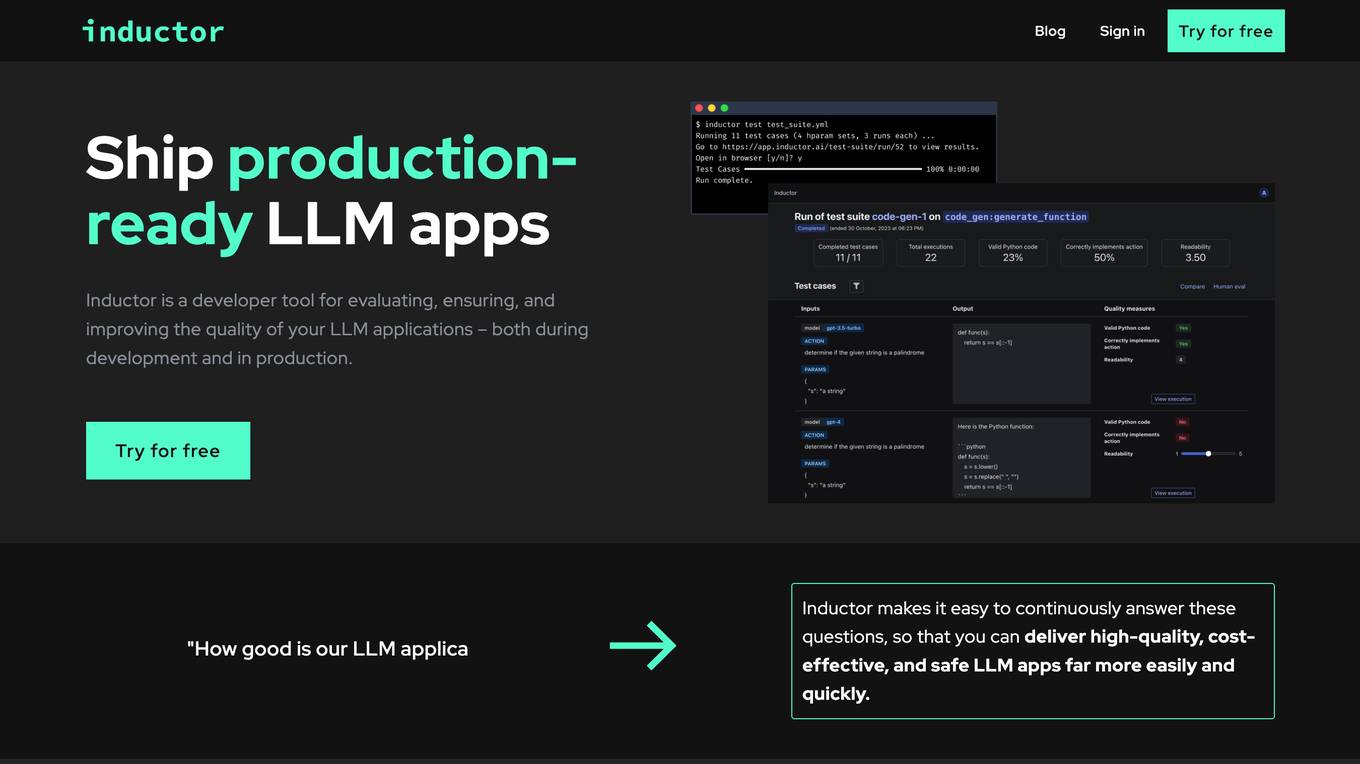
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

Truesight
Goodeye Labs offers Truesight, an AI evaluation tool designed for domain experts to assess the performance of AI products without the need for extensive technical expertise. Truesight bridges the gap between domain knowledge and technical implementation, enabling users to evaluate AI-generated content against specific standards and factors. By empowering domain experts to provide judgment on AI performance, Truesight streamlines the evaluation process, reducing costs, meeting deadlines, and enhancing the reliability of AI products.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Confident AI
Confident AI is an AI evaluation and observability platform designed to help engineers, QA teams, and product leaders build reliable AI systems. It offers best-in-class evaluation metrics powered by DeepEval, real-time production alerts, and tools for tracing and monitoring AI performance. The platform aims to streamline dataset curation, metric alignment, and LLM testing automation, ultimately saving time, reducing costs, and ensuring continuous improvement of AI models.
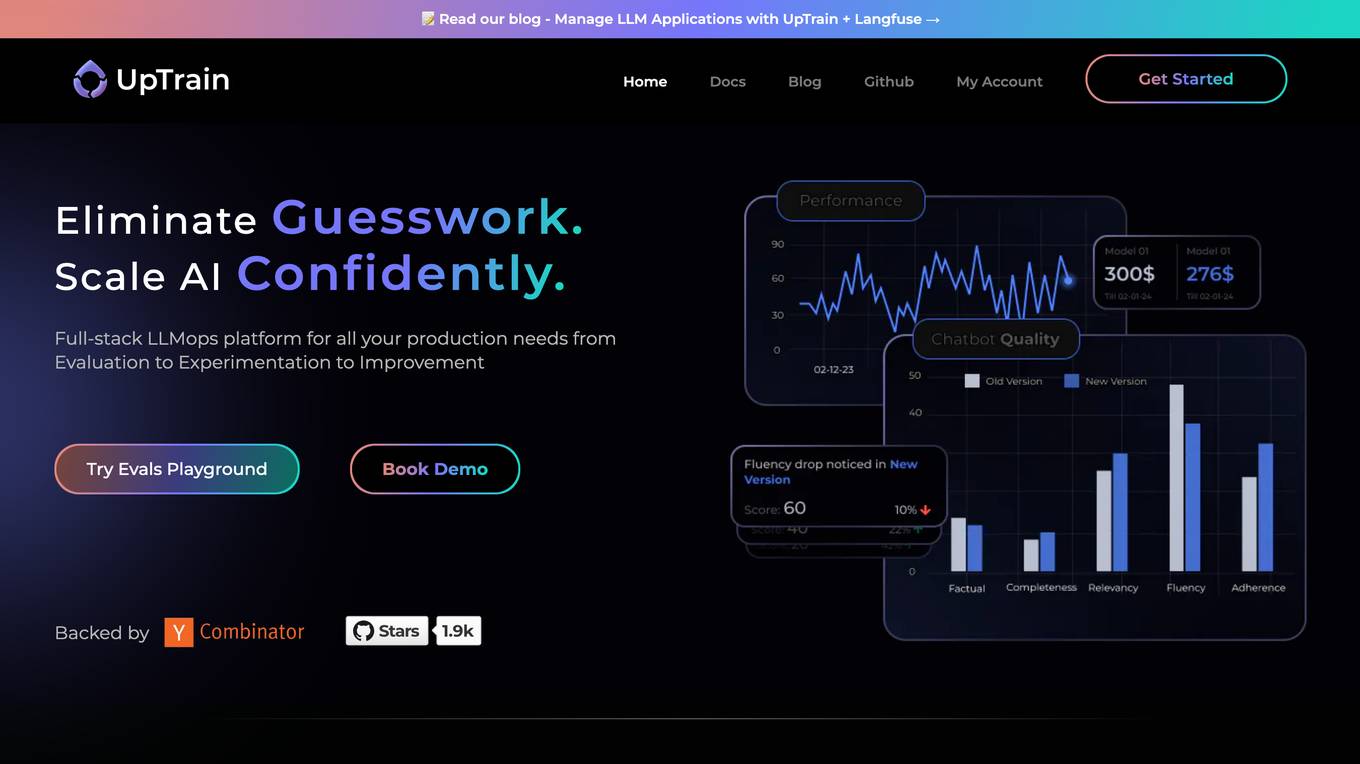
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
ThitaHire
ThitaHire is an AI Interview Platform designed for recruiters to automate first-round interviews and provide structured decision-ready feedback. It offers a world-class AI interviewer for modern hiring teams, enabling a shift from manual screening to dependable AI interviews with better speed, consistent quality, and recruiter-friendly feedback. ThitaHire supports various interview types including software engineering, data science, AI/LLM, product, behavioral, HLD, and LLD rounds. The platform is trusted by top companies like Google, Meta, Amazon, Microsoft, Stripe, Atlassian, Databricks, and Flipkart.
DeepEval
DeepEval by Confident AI is a comprehensive LLM Evaluation Framework used by leading AI companies. It enables users to build reliable evaluation pipelines to test any AI system. With 50+ research-backed metrics, native multi-modal support, and auto-optimization of prompts, DeepEval offers a sophisticated evaluation ecosystem for AI applications. The framework covers unit-testing for LLMs, single and multi-turn evaluations, generation & simulation of test data, and state-of-the-art evaluation techniques like G-Eval and DAG. DeepEval is integrated with Pytest and supports various system architectures, making it a versatile tool for AI testing.
micro1
micro1 is an AI recruitment tool that leverages human data produced by subject matter experts to help companies identify and hire top talent efficiently. The platform offers end-to-end post-training solutions, high-quality data for model training, pre-vetted AI trainers, and enterprise-grade LLM evaluations. With a focus on tech startups, staffing agencies, and enterprises, micro1 aims to streamline the recruitment process and save costs for businesses.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
AARENA
AARENA is an AI-powered platform that allows users to build fully functional apps and websites through simple conversations. It provides a user-friendly interface where individuals can create various digital products without the need for coding knowledge. AARENA leverages AI technology to streamline the development process and empower users to bring their ideas to life efficiently.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.

DeepTeam
DeepTeam by Confident AI is an AI-powered red teaming framework designed to detect over 40 LLM vulnerabilities automatically. It offers state-of-the-art adversarial attacks like prompt injections and gray box techniques to jailbreak LLMs. The framework includes OWASP Top 10 for LLMs, NIST AI, and comprehensive documentation to guide users in evaluating and enhancing the safety of their models. DeepTeam fosters a vibrant red teaming community through GitHub, Discord, and newsletters, empowering users to stay updated on the latest advancements in AI security.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.
LlamaIndex
LlamaIndex is a leading data framework designed for building LLM (Large Language Model) applications. It allows enterprises to turn their data into production-ready applications by providing functionalities such as loading data from various sources, indexing data, orchestrating workflows, and evaluating application performance. The platform offers extensive documentation, community-contributed resources, and integration options to support developers in creating innovative LLM applications.
LlamaIndex
LlamaIndex is a framework for building context-augmented Large Language Model (LLM) applications. It provides tools to ingest and process data, implement complex query workflows, and build applications like question-answering chatbots, document understanding systems, and autonomous agents. LlamaIndex enables context augmentation by combining LLMs with private or domain-specific data, offering tools for data connectors, data indexes, engines for natural language access, chat engines, agents, and observability/evaluation integrations. It caters to users of all levels, from beginners to advanced developers, and is available in Python and Typescript.
Respan
Respan is an AI observability platform designed to trace, evaluate, optimize, deploy, and monitor AI agents. It provides self-driving observability and evaluations for agents, allowing users to surface issues automatically, fix problems faster, and ensure that AI behaves as intended. The platform offers features such as tracing agent behavior, evaluating system performance, optimizing prompts and tools, deploying through a single gateway, and monitoring production shifts. Respan is loved by world-class founders, engineers, and product teams for its user-friendly interface and real-time observability capabilities.
0 - Open Source AI Tools
20 - OpenAI Gpts

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.


IELTS Writing Test
Simulates the IELTS Writing Test, evaluates responses, and estimates band scores.