Best AI tools for< Evaluate Instructions >
20 - AI tool Sites
Q, ChatGPT for Slack
The website offers 'Q, ChatGPT for Slack', an AI tool that functions like ChatGPT within your Slack workspace. It allows on-demand URL and file reading, custom instructions for tailored use, and supports various URLs and files. With Q, users can summarize, evaluate, brainstorm ideas, self-review, engage in Q&A, and more. The tool enables team-specific rules, guidelines, and templates, making it ideal for emails, translations, content creation, copywriting, reporting, coding, and testing based on internal information.
Mangus
Mangus is an AI-powered learning platform that provides personalized learning paths for employees and students. It offers a wide range of courses and programs in various disciplines, including business, education, technology, and more. Mangus uses gamification and artificial intelligence to create an engaging and effective learning experience.

MASCAA
MASCAA is a comprehensive human confidence analysis platform that focuses on evaluating the confidence of users through video and audio during various tasks. It integrates advanced facial expression and voice analysis technologies to provide valuable feedback for students, instructors, individuals, businesses, and teams. MASCAA offers quick and easy test creation, evaluation, and confidence assessment for educational settings, personal use, startups, small organizations, universities, and large organizations. The platform aims to unlock long-term value and enhance customer experience by helping users assess and improve their confidence levels.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, acting as a one-person team for their business dreams. From evaluating and assessing business ideas to creating detailed business plans, RebeccAi revolutionizes idea validation with the power of AI.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.
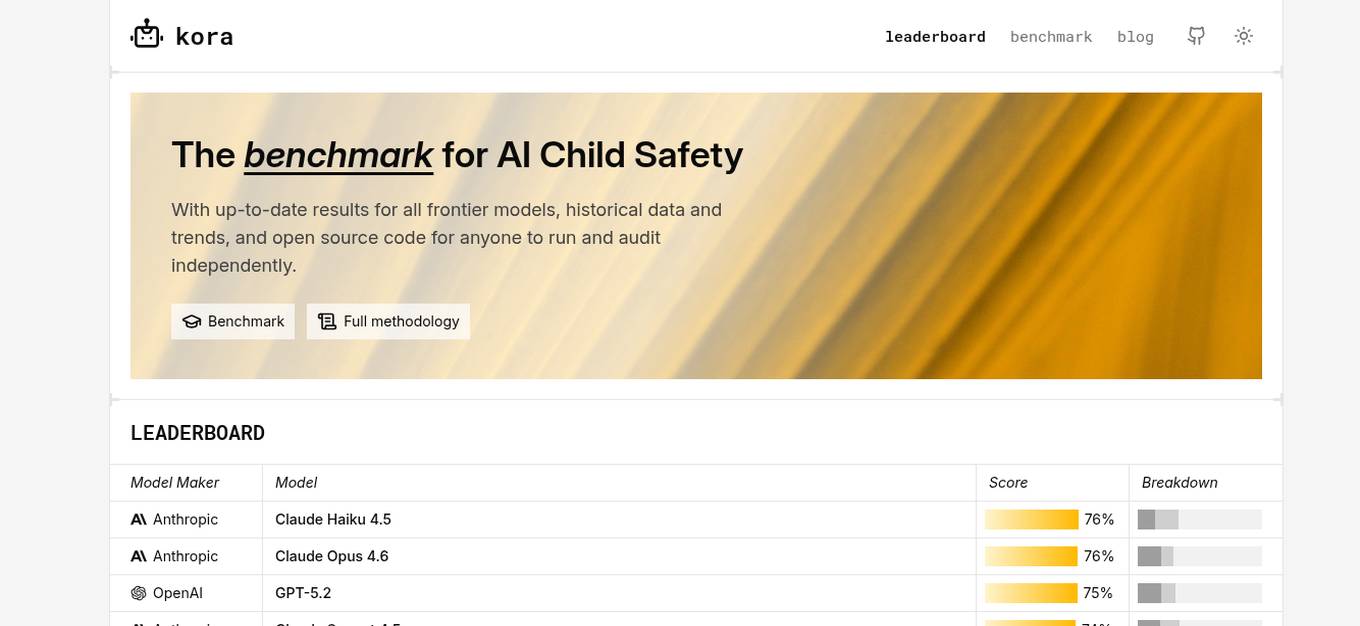
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.

Brevoir
Brevoir is an AI-powered decision-grade due diligence tool designed for startup investing. It consolidates founder diligence, market and competitor research, risk assessment, and investment-ready writeups in one platform. Tailored for angel investors and startup evaluators, Brevoir streamlines the startup evaluation process by extracting key information from pitch decks or company URLs, verifying claims, mapping competitors, and providing structured reports with risks and opportunities. The tool aims to provide clear answers, identify market trends, evaluate team credibility, assess traction and risks, and offer pricing plans that scale with user needs.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
SymptomChecker.io
SymptomChecker.io is an AI-powered medical symptom checker that allows users to describe their symptoms in their own words and receive non-reviewed AI-generated responses. It is important to note that this tool is not intended to offer medical advice, diagnosis, or treatment and should not be used as a substitute for professional medical advice. In the case of a medical emergency, please contact your physician or dial 911 immediately.
ELSA
ELSA is an AI-powered English speaking coach that helps you improve your pronunciation, fluency, and confidence. With ELSA, you can practice speaking English in short, fun dialogues and get instant feedback from our proprietary artificial intelligence technology. ELSA also offers a variety of other features, such as personalized lesson plans, progress tracking, and games to help you stay motivated.
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on your speech. It helps users improve their pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English speaking skills and communication abilities.
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
Workable
Workable is a leading recruiting software and hiring platform that offers a full Applicant Tracking System with built-in AI sourcing. It provides a configurable HRIS platform to securely manage employees, automate hiring tasks, and offer actionable insights and reporting. Workable helps companies streamline their recruitment process, from sourcing to employee onboarding and management, with features like sourcing and attracting candidates, evaluating and collaborating with hiring teams, automating hiring tasks, onboarding and managing employees, and tracking HR processes.
1 - Open Source AI Tools
EasyInstruct
EasyInstruct is a Python package proposed as an easy-to-use instruction processing framework for Large Language Models (LLMs) like GPT-4, LLaMA, ChatGLM in your research experiments. EasyInstruct modularizes instruction generation, selection, and prompting, while also considering their combination and interaction.
20 - OpenAI Gpts
Instructional Design and Technology Expert
A master of instructional design and technology.


Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.
EduCheck
Automatically evaluates uploaded lesson plans against educational standards. Upload text or a PDF.
Diseñando Experiencias de Formación
Asistente especializado en diseño y planificación de formación profesional

Training Material Design Advisor
Designs effective training materials to enhance organizational learning and performance.
Course Architect
Assists in course design, offering expandable responses based on user input.
Learning Hero
Your personal A.I. learning hero when creating interactive e-learning content

E-Learning Development Advisor
Enhances corporate training through innovative e-learning solutions.
Learning Experience Designer™
A Learning Experience Designer (LXD) - in support of LXDs and those who work with them.
The Learning Architect
An all-in-one, consultative L&D expert AI helping you build impactful, customized learning solutions for your organization.
Course Creator Assistant
Expert in online course creation, offering detailed feedback and tailored advice. Feel free to enter in the details you want for your course, and you will receive an outline and more! For more course creation support, see my offerings at https://impactful-teaching.newzenler.com/courses
Pocket Training Activity Expert
Expert in engaging, interactive training methods and activities.
Learning & Development Advisor
Enhances organizational performance through employee learning and development initiatives.

Corporate Trainer
Develops training programs, customizing content to fit corporate culture and objectives.