Best AI tools for< Evaluate Coding Performance >
20 - AI tool Sites
AARENA
AARENA is an AI-powered platform that allows users to build fully functional apps and websites through simple conversations. It provides a user-friendly interface where individuals can create various digital products without the need for coding knowledge. AARENA leverages AI technology to streamline the development process and empower users to bring their ideas to life efficiently.
SQOR
SQOR is a plug-n-play AI tool designed for C-Level Executives to make stress-free decision-making in business intelligence. It provides a zero-code BI solution, offering KPIs at your fingertips without the need for expert knowledge. The platform enables users to access and share business intelligence data from various SaaS tools, facilitating collaboration and informed decision-making across the organization. SQOR's unique Execution Score Algorithm evaluates execution health at different levels, ensuring stakeholders are empowered with actionable insights.
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.
Vals AI
Vals AI is an advanced AI tool that provides benchmark reports and comparisons for various models in the fields of finance, coding, and law. The platform offers insights into the performance of different AI models across different tasks and industries. Vals AI aims to bridge the gap in model benchmarking and provide valuable information for users looking to evaluate and compare AI models for specific tasks.
bottest.ai
bottest.ai is an AI-powered chatbot testing tool that focuses on ensuring quality, reliability, and safety in AI-based chatbots. The tool offers automated testing capabilities without the need for coding, making it easy for users to test their chatbots efficiently. With features like regression testing, performance testing, multi-language testing, and AI-powered coverage, bottest.ai provides a comprehensive solution for testing chatbots. Users can record tests, evaluate responses, and improve their chatbots based on analytics provided by the tool. The tool also supports enterprise readiness by allowing scalability, permissions management, and integration with existing workflows.
ParallelDots
ParallelDots is a next-generation retail execution software powered by image recognition technology. The software offers solutions like ShelfWatch, Saarthi, and SmartGaze to enhance the efficiency of sales reps and merchandisers, provide faster training of image recognition models, and offer automated gaze-coding solutions for mobile and retail eye-tracking research. ParallelDots' computer vision technology helps CPG and retail brands track in-store compliance, address gaps in retail execution, and gain real-time insights into brand performance. The platform enables users to generate real-time KPI insights, evaluate compliance levels, convert insights into actionable strategies, and integrate computer vision with existing retail solutions seamlessly.
Talynce
Talynce is an AI-powered technical interview platform that revolutionizes the recruitment process by automating candidate screening through live coding interviews and technical Q&A sessions. It helps companies assess coding skills and theoretical knowledge efficiently, empowering them to identify top technical talent faster.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.
Wix
Wix.com is a website builder platform that allows users to create stunning websites without the need for coding skills. With a user-friendly interface and a wide range of customizable templates, Wix empowers individuals and businesses to establish their online presence effortlessly. Users can choose from various design elements, add functionalities through apps, and optimize their websites for different devices. Wix also provides hosting services and domain registration to simplify the entire website creation process.
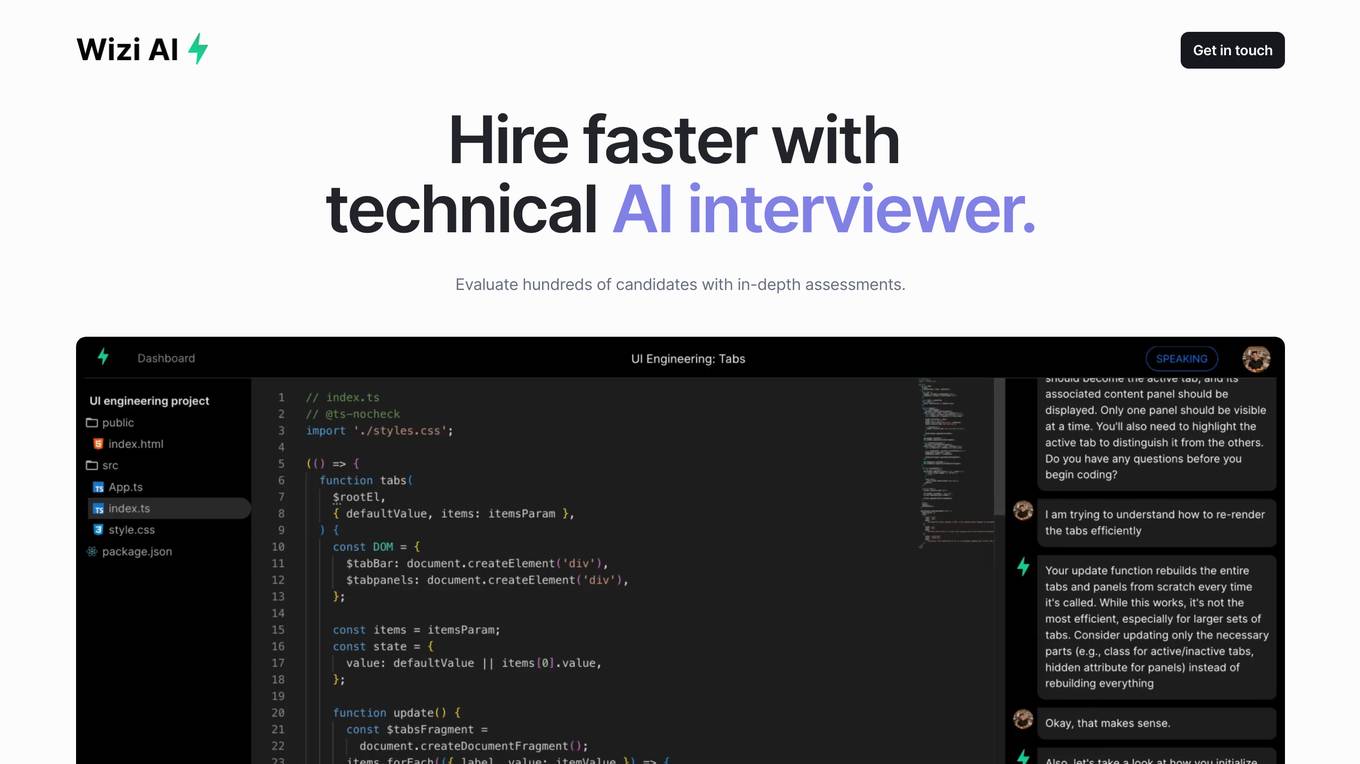
Wizi AI
Wizi AI is a technical AI interviewer that helps employers evaluate hundreds of candidates with in-depth assessments. It goes beyond basic coding challenges and conducts an onsite interview experience for every candidate. Employers get actionable hiring signals with in-depth reports on system design, project implementation, domain expertise, and debugging skills. Wizi AI saves teams time by screening all candidates with AI and bringing only the best to onsites.

HappyML
HappyML is an AI tool designed to assist users in machine learning tasks. It provides a user-friendly interface for running machine learning algorithms without the need for complex coding. With HappyML, users can easily build, train, and deploy machine learning models for various applications. The tool offers a range of features such as data preprocessing, model evaluation, hyperparameter tuning, and model deployment. HappyML simplifies the machine learning process, making it accessible to users with varying levels of expertise.
Q, ChatGPT for Slack
The website offers 'Q, ChatGPT for Slack', an AI tool that functions like ChatGPT within your Slack workspace. It allows on-demand URL and file reading, custom instructions for tailored use, and supports various URLs and files. With Q, users can summarize, evaluate, brainstorm ideas, self-review, engage in Q&A, and more. The tool enables team-specific rules, guidelines, and templates, making it ideal for emails, translations, content creation, copywriting, reporting, coding, and testing based on internal information.
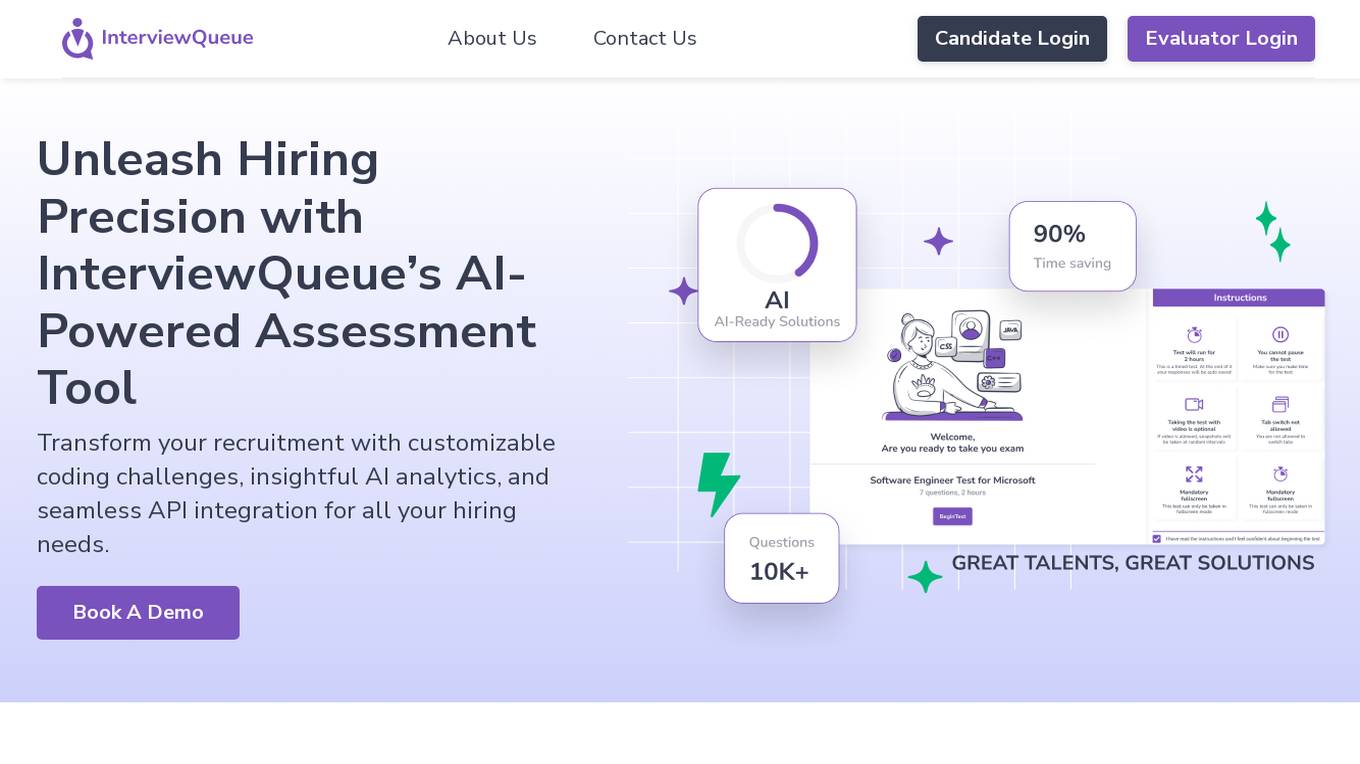
InterviewQueue
InterviewQueue is an AI-powered online assessment software platform that revolutionizes the recruitment process. It offers customizable coding challenges, insightful AI analytics, and seamless API integration for efficient hiring. With features like custom assessments, AI evaluation, and API integration, InterviewQueue aims to streamline the recruitment process and provide objective evaluations. The platform helps in making data-driven hiring decisions, optimizing the interview process, and enhancing the candidate experience. InterviewQueue focuses on efficiency, customization, objective evaluation, data-driven decisions, and candidate-centric assessments.
Web3 Summary
Web3 Summary is an AI-powered platform that simplifies on-chain research across multiple chains and protocols, helping users find trading alpha in the DeFi and NFT space. It offers a range of products including a trading terminal, wallet study tool, Discord bot, mobile app, and Chrome extension. The platform aims to streamline the process of understanding complex crypto projects and tokenomics using AI and ChatGPT technology.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.
1 - Open Source AI Tools

can-ai-code
Can AI Code is a self-evaluating interview tool for AI coding models. It includes interview questions written by humans and tests taken by AI, inference scripts for common API providers and CUDA-enabled quantization runtimes, a Docker-based sandbox environment for validating untrusted Python and NodeJS code, and the ability to evaluate the impact of prompting techniques and sampling parameters on large language model (LLM) coding performance. Users can also assess LLM coding performance degradation due to quantization. The tool provides test suites for evaluating LLM coding performance, a webapp for exploring results, and comparison scripts for evaluations. It supports multiple interviewers for API and CUDA runtimes, with detailed instructions on running the tool in different environments. The repository structure includes folders for interviews, prompts, parameters, evaluation scripts, comparison scripts, and more.
20 - OpenAI Gpts
Lifeeventprobabilityanalyzer
Map or simulate a scenario real time analyze probability of a life event coming true based on circumstances

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.