Best AI tools for< Evaluate Ai Performance >
20 - AI tool Sites
Compassionate AI
Compassionate AI is a cutting-edge AI-powered platform that empowers individuals and organizations to create and deploy AI solutions that are ethical, responsible, and aligned with human values. With Compassionate AI, users can access a comprehensive suite of tools and resources to design, develop, and implement AI systems that prioritize fairness, transparency, and accountability.
Teammately
Teammately is an AI tool that redefines how Human AI-Engineers build AI. It is an Agentic AI for AI development process, designed to enable Human AI-Engineers to focus on more creative and productive missions in AI development. Teammately follows the best practices of Human LLM DevOps and offers features like Development Prompt Engineering, Knowledge Tuning, Evaluation, and Optimization to assist in the AI development process. The tool aims to revolutionize AI engineering by allowing AI AI-Engineers to handle technical tasks, while Human AI-Engineers focus on planning and aligning AI with human preferences and requirements.
RagaAI Catalyst
RagaAI Catalyst is a sophisticated AI observability, monitoring, and evaluation platform designed to help users observe, evaluate, and debug AI agents at all stages of Agentic AI workflows. It offers features like visualizing trace data, instrumenting and monitoring tools and agents, enhancing AI performance, agentic testing, comprehensive trace logging, evaluation for each step of the agent, enterprise-grade experiment management, secure and reliable LLM outputs, finetuning with human feedback integration, defining custom evaluation logic, generating synthetic data, and optimizing LLM testing with speed and precision. The platform is trusted by AI leaders globally and provides a comprehensive suite of tools for AI developers and enterprises.
Encord
Encord is a leading data development platform designed for computer vision and multimodal AI teams. It offers a comprehensive suite of tools to manage, clean, and curate data, streamline labeling and workflow management, and evaluate AI model performance. With features like data indexing, annotation, and active model evaluation, Encord empowers users to accelerate their AI data workflows and build robust models efficiently.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.
Arthur
Arthur is an industry-leading MLOps platform that simplifies deployment, monitoring, and management of traditional and generative AI models. It ensures scalability, security, compliance, and efficient enterprise use. Arthur's turnkey solutions enable companies to integrate the latest generative AI technologies into their operations, making informed, data-driven decisions. The platform offers open-source evaluation products, model-agnostic monitoring, deployment with leading data science tools, and model risk management capabilities. It emphasizes collaboration, security, and compliance with industry standards.
Vocera
Vocera is an AI voice agent testing tool that allows users to test and monitor voice AI agents efficiently. It enables users to launch voice agents in minutes, ensuring a seamless conversational experience. With features like testing against AI-generated datasets, simulating scenarios, and monitoring AI performance, Vocera helps in evaluating and improving voice agent interactions. The tool provides real-time insights, detailed logs, and trend analysis for optimal performance, along with instant notifications for errors and failures. Vocera is designed to work for everyone, offering an intuitive dashboard and data-driven decision-making for continuous improvement.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.
Legal Benchmarks
Legal Benchmarks is a platform that provides independent lawyer-led AI evaluations for in-house legal work in the legal industry. The platform evaluates AI assistants on critical legal tasks like contract drafting and information extraction. It offers rankings based on how different AI tools perform on real-world legal tasks, helping legal teams understand and adopt AI solutions. Legal Benchmarks also allows legal AI vendors to submit their tools for evaluation and provides access to customized private reports, insights, and practical breakdowns of AI tools' performance.
Getbound
Getbound is an AI solutions provider that enables companies to evaluate, customize, and scale technology solutions with artificial intelligence easily and quickly. They offer services such as AI consulting, NLP solutions, MLOps, generative AI development, data engineering services, and computer vision solutions. Getbound empowers businesses to turn data into savings, automate processes, and improve overall performance through AI technologies.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.

Sereda.ai
Sereda.ai is an AI-powered platform designed to unleash a team's potential by offering solutions for employee knowledge management, surveys, performance reviews, learning, and more. It integrates artificial intelligence to streamline HR processes, improve employee engagement, and boost productivity. The platform provides a user-friendly interface, personalized settings, and automation features to enhance organizational efficiency and reduce costs.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.
RevSure
RevSure is an AI-powered platform designed for high-growth marketing teams to optimize marketing ROI and attribution. It offers full-funnel attribution, deep funnel optimization, predictive insights, and campaign performance tracking. The platform integrates with various data sources to provide unified funnel reporting and personalized recommendations for improving pipeline health and conversion rates. RevSure's AI engine powers features like campaign spend reallocation, next-best touch analysis, and journey timeline construction, enabling users to make data-driven decisions and accelerate revenue growth.
MonitUp
MonitUp is an AI-powered time tracking software that helps you track computer activity, gain insights into work habits, and boost productivity. It uses artificial intelligence to generate personalized suggestions to help you increase productivity and work more efficiently. MonitUp also offers a performance appraisal feature for remote employees, allowing you to evaluate and improve their performance based on objective data.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
bottest.ai
bottest.ai is an AI-powered chatbot testing tool that focuses on ensuring quality, reliability, and safety in AI-based chatbots. The tool offers automated testing capabilities without the need for coding, making it easy for users to test their chatbots efficiently. With features like regression testing, performance testing, multi-language testing, and AI-powered coverage, bottest.ai provides a comprehensive solution for testing chatbots. Users can record tests, evaluate responses, and improve their chatbots based on analytics provided by the tool. The tool also supports enterprise readiness by allowing scalability, permissions management, and integration with existing workflows.
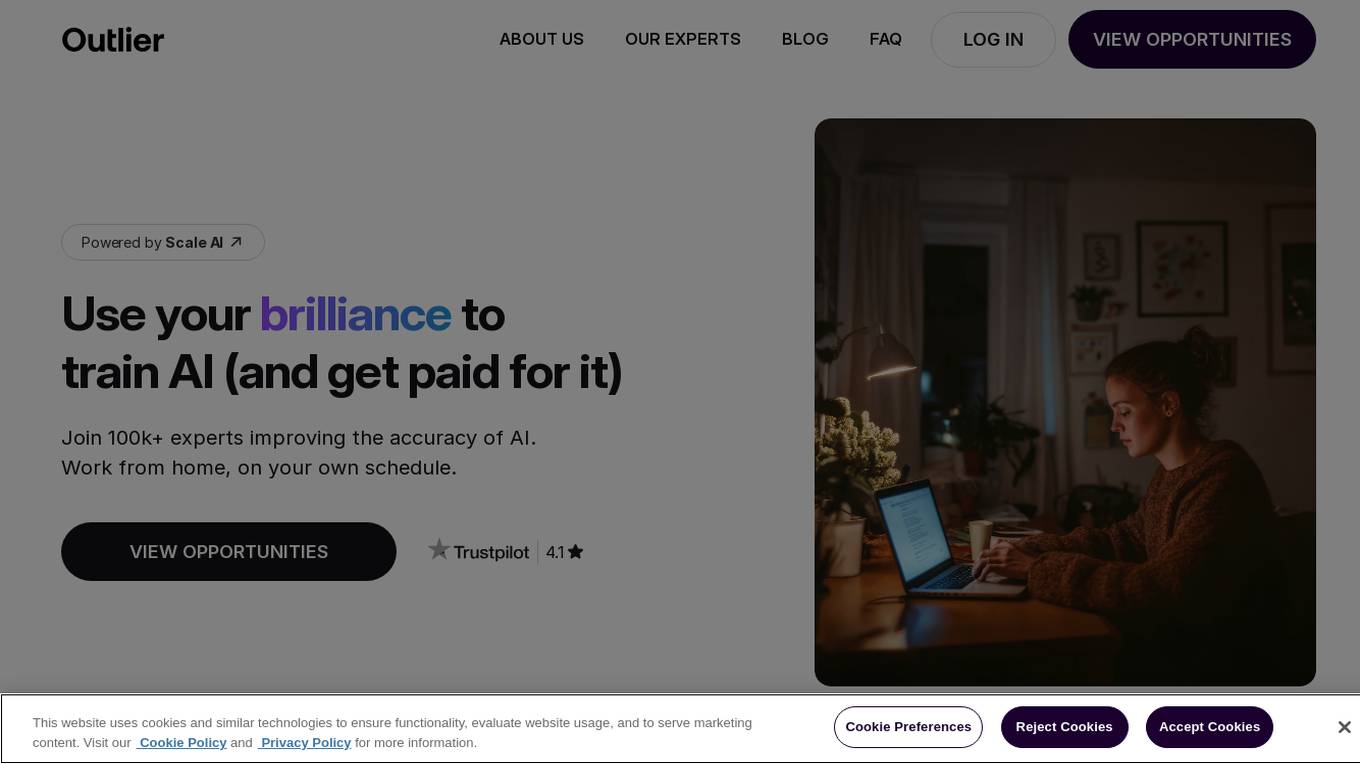
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.
1 - Open Source AI Tools

LLM-Agent-Survey
Autonomous agents are designed to achieve specific objectives through self-guided instructions. With the emergence and growth of large language models (LLMs), there is a growing trend in utilizing LLMs as fundamental controllers for these autonomous agents. This repository conducts a comprehensive survey study on the construction, application, and evaluation of LLM-based autonomous agents. It explores essential components of AI agents, application domains in natural sciences, social sciences, and engineering, and evaluation strategies. The survey aims to be a resource for researchers and practitioners in this rapidly evolving field.
20 - OpenAI Gpts
Strategy Guide
An expert in AI strategy, offering insights on AI implementation and industry trends.

IELTS AI Checker (Speaking and Writing)
Provides IELTS speaking and writing feedback and scores.

Training Material Design Advisor
Designs effective training materials to enhance organizational learning and performance.

AI Golf Statistics
PGA Tour Golf statistics expert, provides up-to-date data and analysis.


AI Market Analyzer
Analyzes markets, offers predictions on commodities, crypto, and companies.
Wordon, World's Worst Customer | Divergent AI
I simulate tough Customer Support scenarios for Agent Training.

ecosystem.Ai Use Case Designer v2
The use case designer is configured with the latest Data Science and Behavioral Social Science insights to guide you through the process of defining AI and Machine Learning use cases for the ecosystem.Ai platform.

Europe Ethos Guide for AI
Ethics-focused GPT builder assistant based on European AI guidelines, recommendations and regulations


Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.