Best AI tools for< Encode Input Prompts >
6 - AI tool Sites
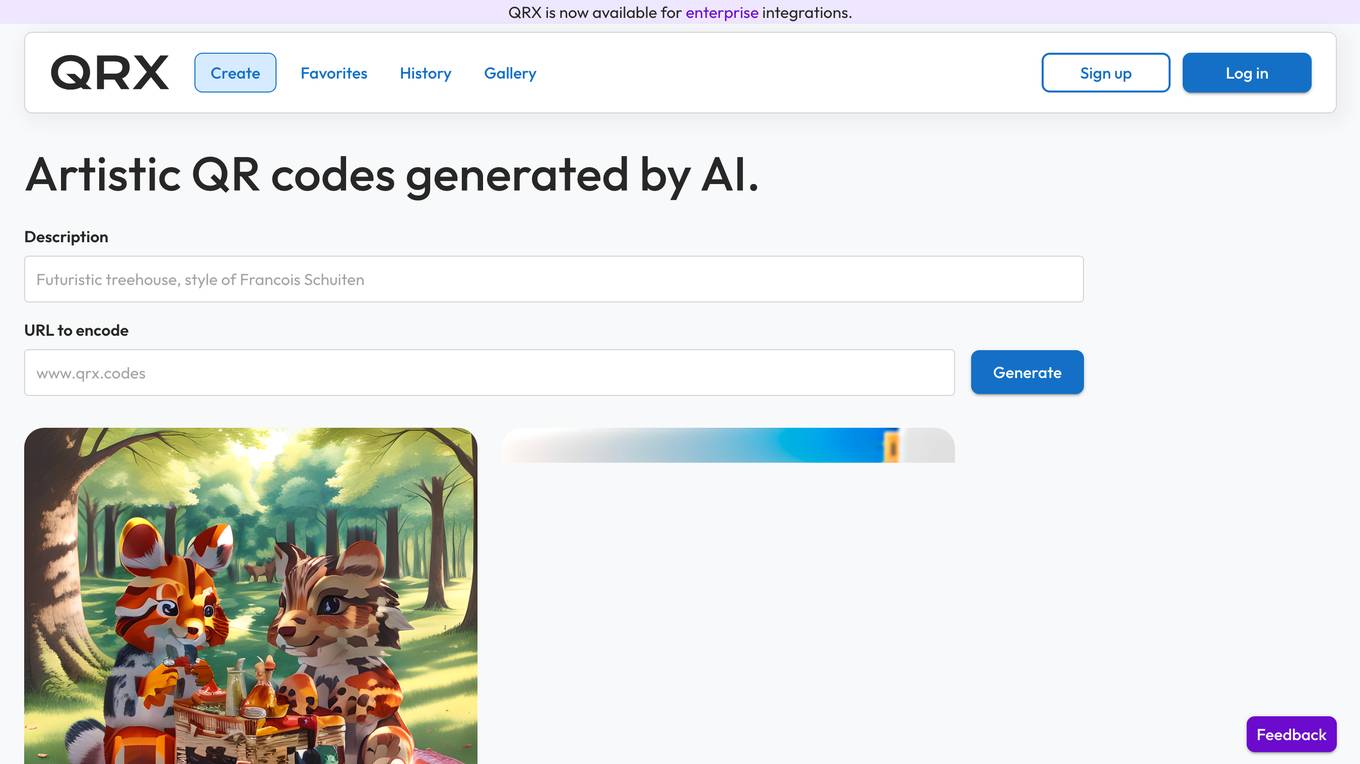
QRX Codes
QRX Codes is an AI tool that generates artistic QR codes. Users can create unique QR codes with images of woodland animals, floating castles, desert scenes, and more. The tool allows for customization of QR codes with premium designs like a dark blue Porsche, Iron Man inspired art, and underground cave themes. QRX is now available for enterprise integrations, offering a creative way to encode URLs and enhance user engagement. The tool is designed to provide a visually appealing and innovative approach to QR code generation.
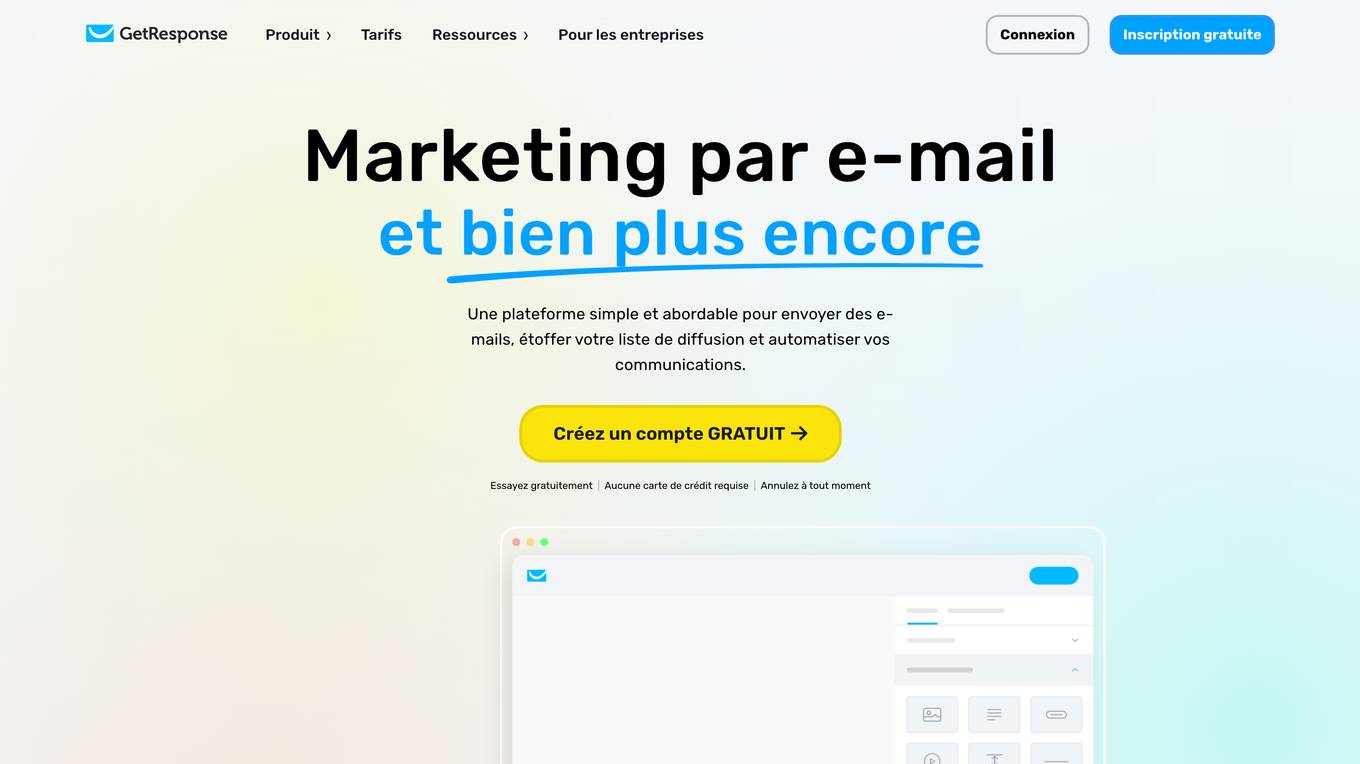
GetResponse
GetResponse is an email marketing and marketing automation platform that helps businesses of all sizes grow their audience, engage with customers, and drive sales. With a suite of powerful tools, including email marketing, landing pages, forms, and automation, GetResponse makes it easy to create and execute effective marketing campaigns. GetResponse also offers a range of integrations with other business tools, making it easy to connect your marketing efforts with your CRM, e-commerce platform, and more.
Productly
Productly is an AI-powered sales tool that helps businesses boost their sales performance. It uses machine learning to analyze customer data and identify opportunities for growth. Productly provides personalized recommendations for each customer, helping sales teams close more deals and increase revenue.
notionsmith.ai
The website notionsmith.ai appears to be experiencing a privacy error related to its security certificate. The error message indicates that the connection is not private and warns of potential information theft. The site's security certificate is issued by Microsoft Azure RSA TLS Issuing CA 08, with the subject *.azurewebsites.net. The error message suggests that the site's security certificate common name is invalid, potentially due to a misconfiguration or an attacker intercepting the connection. Users are advised to proceed to the site at their own risk, as it is flagged as unsafe.

MiniGPT-4
MiniGPT-4 is a powerful AI tool that combines a vision encoder with a large language model (LLM) to enhance vision-language understanding. It can generate detailed image descriptions, create websites from handwritten drafts, write stories and poems inspired by images, provide solutions to problems shown in images, and teach users how to cook based on food photos. MiniGPT-4 is highly computationally efficient and easy to use, making it a valuable tool for a wide range of applications.
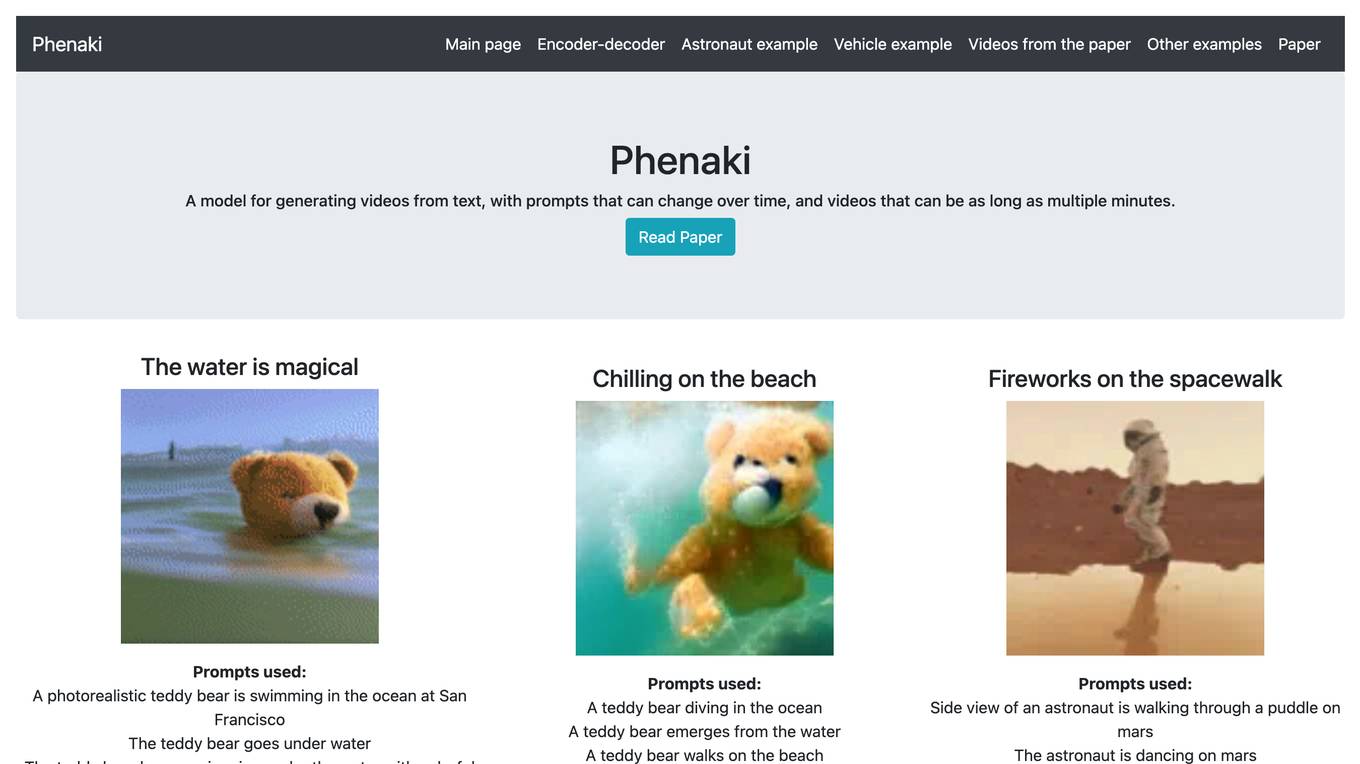
Phenaki
Phenaki is a model capable of generating realistic videos from a sequence of textual prompts. It is particularly challenging to generate videos from text due to the computational cost, limited quantities of high-quality text-video data, and variable length of videos. To address these issues, Phenaki introduces a new causal model for learning video representation, which compresses the video to a small representation of discrete tokens. This tokenizer uses causal attention in time, which allows it to work with variable-length videos. To generate video tokens from text, Phenaki uses a bidirectional masked transformer conditioned on pre-computed text tokens. The generated video tokens are subsequently de-tokenized to create the actual video. To address data issues, Phenaki demonstrates how joint training on a large corpus of image-text pairs as well as a smaller number of video-text examples can result in generalization beyond what is available in the video datasets. Compared to previous video generation methods, Phenaki can generate arbitrarily long videos conditioned on a sequence of prompts (i.e., time-variable text or a story) in an open domain. To the best of our knowledge, this is the first time a paper studies generating videos from time-variable prompts. In addition, the proposed video encoder-decoder outperforms all per-frame baselines currently used in the literature in terms of spatio-temporal quality and the number of tokens per video.
1 - Open Source AI Tools

xFasterTransformer
xFasterTransformer is an optimized solution for Large Language Models (LLMs) on the X86 platform, providing high performance and scalability for inference on mainstream LLM models. It offers C++ and Python APIs for easy integration, along with example codes and benchmark scripts. Users can prepare models in a different format, convert them, and use the APIs for tasks like encoding input prompts, generating token ids, and serving inference requests. The tool supports various data types and models, and can run in single or multi-rank modes using MPI. A web demo based on Gradio is available for popular LLM models like ChatGLM and Llama2. Benchmark scripts help evaluate model inference performance quickly, and MLServer enables serving with REST and gRPC interfaces.
7 - OpenAI Gpts