Best AI tools for< Deploy Inference Workflows >
20 - AI tool Sites
NeuReality
NeuReality is an AI-centric solution designed to democratize AI adoption by providing purpose-built tools for deploying and scaling inference workflows. Their innovative AI-centric architecture combines hardware and software components to optimize performance and scalability. The platform offers a one-stop shop for AI inference, addressing barriers to AI adoption and streamlining computational processes. NeuReality's tools enable users to deploy, afford, use, and manage AI more efficiently, making AI easy and accessible for a wide range of applications.
Modular
Modular is a fast, scalable Gen AI inference platform that offers a comprehensive suite of tools and resources for AI development and deployment. It provides solutions for AI model development, deployment options, AI inference, research, and resources like documentation, models, tutorials, and step-by-step guides. Modular supports GPU and CPU performance, intelligent scaling to any cluster, and offers deployment options for various editions. The platform enables users to build agent workflows, utilize AI retrieval and controlled generation, develop chatbots, engage in code generation, and improve resource utilization through batch processing.
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.
Cirrascale Cloud Services
Cirrascale Cloud Services is an AI tool that offers cloud solutions for Artificial Intelligence applications. The platform provides a range of cloud services and products tailored for AI innovation, including NVIDIA GPU Cloud, AMD Instinct Series Cloud, Qualcomm Cloud, Graphcore, Cerebras, and SambaNova. Cirrascale's AI Innovation Cloud enables users to test and deploy on leading AI accelerators in one cloud, democratizing AI by delivering high-performance AI compute and scalable deep learning solutions. The platform also offers professional and managed services, tailored multi-GPU server options, and high-throughput storage and networking solutions to accelerate development, training, and inference workloads.
ThirdAI
ThirdAI is an AI platform that offers a production-ready solution for building and deploying AI applications quickly and efficiently. It provides advanced AI/GenAI technology that can run on any infrastructure, reducing barriers to delivering production-grade AI solutions. With features like enterprise SSO, built-in models, no-code interface, and more, ThirdAI empowers users to create AI applications without the need for specialized GPU servers or AI skills. The platform covers the entire workflow of building AI applications end-to-end, allowing for easy customization and deployment in various environments.
Lamini
Lamini is an enterprise-level LLM platform that offers precise recall with Memory Tuning, enabling teams to achieve over 95% accuracy even with large amounts of specific data. It guarantees JSON output and delivers massive throughput for inference. Lamini is designed to be deployed anywhere, including air-gapped environments, and supports training and inference on Nvidia or AMD GPUs. The platform is known for its factual LLMs and reengineered decoder that ensures 100% schema accuracy in the JSON output.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.
Salad
Salad is a distributed GPU cloud platform that offers fully managed and massively scalable services for AI applications. It provides the lowest priced AI transcription in the market, with features like image generation, voice AI, computer vision, data collection, and batch processing. Salad democratizes cloud computing by leveraging consumer GPUs to deliver cost-effective AI/ML inference at scale. The platform is trusted by hundreds of machine learning and data science teams for its affordability, scalability, and ease of deployment.
TitanML
TitanML is a platform that provides tools and services for deploying and scaling Generative AI applications. Their flagship product, the Titan Takeoff Inference Server, helps machine learning engineers build, deploy, and run Generative AI models in secure environments. TitanML's platform is designed to make it easy for businesses to adopt and use Generative AI, without having to worry about the underlying infrastructure. With TitanML, businesses can focus on building great products and solving real business problems.
Groq
Groq is a fast AI inference tool that offers GroqCloud™ Platform and GroqRack™ Cluster for developers to build and deploy AI models with ultra-low-latency inference. It provides instant intelligence for openly-available models like Llama 3.1 and is known for its speed and compatibility with other AI providers. Groq powers leading openly-available AI models and has gained recognition in the AI chip industry. The tool has received significant funding and valuation, positioning itself as a strong challenger to established players like Nvidia.

Groq
Groq is a fast AI inference tool that offers instant intelligence for openly-available models like Llama 3.1. It provides ultra-low-latency inference for cloud deployments and is compatible with other providers like OpenAI. Groq's speed is proven to be instant through independent benchmarks, and it powers leading openly-available AI models such as Llama, Mixtral, Gemma, and Whisper. The tool has gained recognition in the industry for its high-speed inference compute capabilities and has received significant funding to challenge established players like Nvidia.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.

PoplarML
PoplarML is a platform that enables the deployment of production-ready, scalable ML systems with minimal engineering effort. It offers one-click deploys, real-time inference, and framework agnostic support. With PoplarML, users can seamlessly deploy ML models using a CLI tool to a fleet of GPUs and invoke their models through a REST API endpoint. The platform supports Tensorflow, Pytorch, and JAX models.
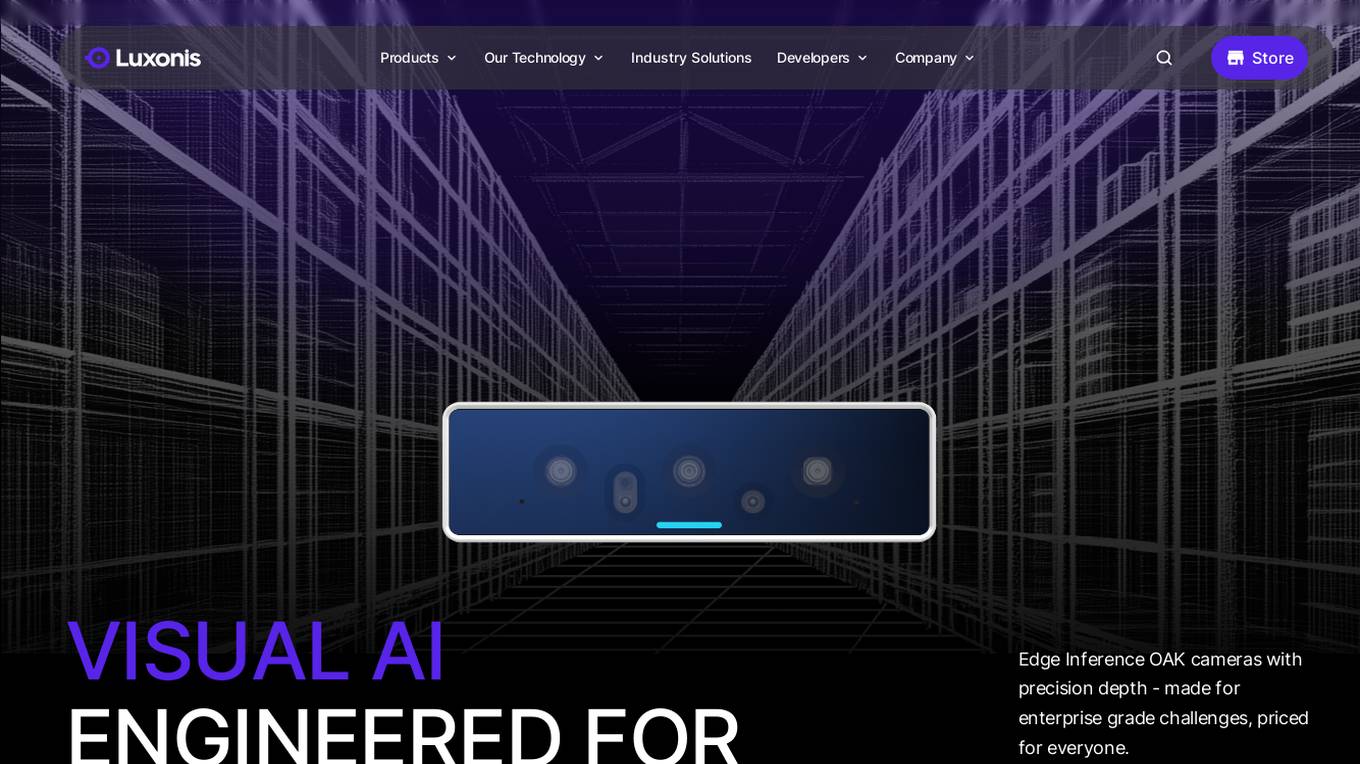
Luxonis
Luxonis is an AI application that offers Visual AI solutions engineered for precision edge inference. The application provides stereo depth cameras with unique features and quality, enabling users to perform advanced vision tasks on-device, reducing latency and bandwidth demands. With open-source DepthAI API, users can create and deploy custom vision solutions that scale with their needs. Luxonis also offers real-world training data for self-improving vision intelligence and operates flawlessly through vibrations, temperature shifts, and extended use. The application integrates advanced sensing capabilities with up to 48MP cameras, wide field of view, IMUs, microphones, ToF, thermal, IR illumination, and active stereo for unparalleled perception.

Wallaroo.AI
Wallaroo.AI is an AI inference platform that offers production-grade AI inference microservices optimized on OpenVINO for cloud and Edge AI application deployments on CPUs and GPUs. It provides hassle-free AI inferencing for any model, any hardware, anywhere, with ultrafast turnkey inference microservices. The platform enables users to deploy, manage, observe, and scale AI models effortlessly, reducing deployment costs and time-to-value significantly.
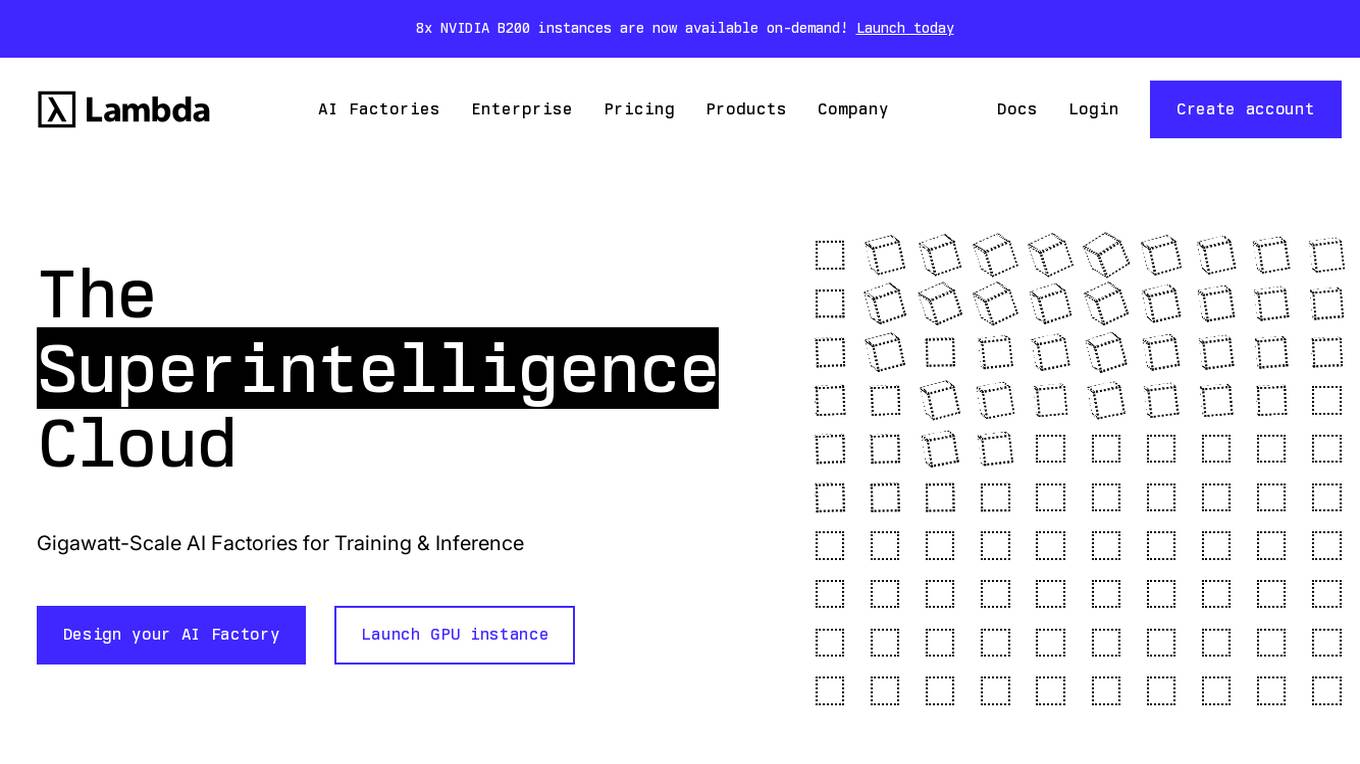
Lambda
Lambda is a superintelligence cloud platform that offers on-demand GPU clusters for multi-node training and fine-tuning, private large-scale GPU clusters, seamless management and scaling of AI workloads, inference endpoints and API, and a privacy-first chat app with open source models. It also provides NVIDIA's latest generation infrastructure for enterprise AI. With Lambda, AI teams can access gigawatt-scale AI factories for training and inference, deploy GPU instances, and leverage the latest NVIDIA GPUs for high-performance computing.
Axelera AI
Axelera AI is an AI tool that offers datacenter performance and edge efficiency through AI accelerators and AI processing units. The platform provides hardware and software solutions for accelerating inference at the edge, bringing data insights and analytics to various industries such as industrial manufacturing, retail, security, healthcare, smart cities, robotics, agriculture, and computer vision. Axelera AI aims to boost AI applications' performance with cost-effective and efficient inference chips, seamlessly integrating into innovations to enhance customer focus.
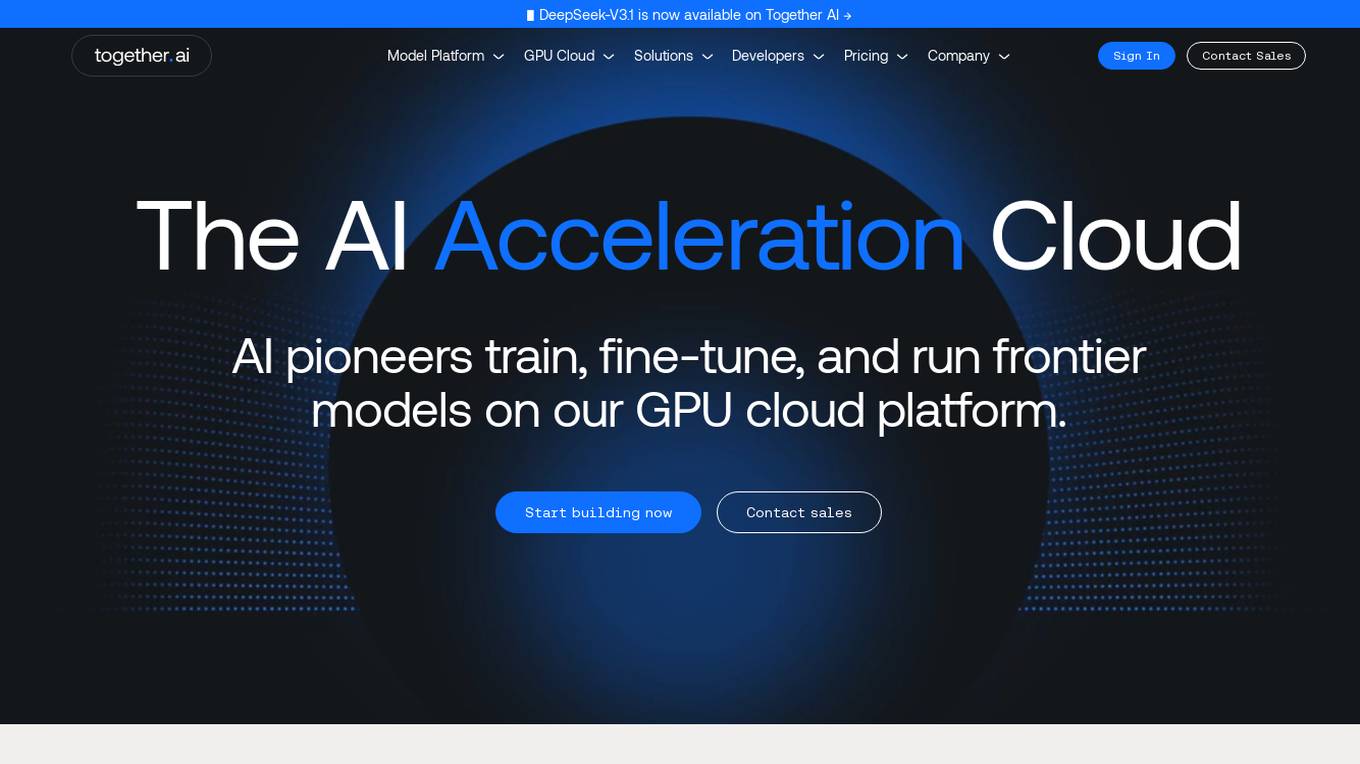
Together AI
Together AI is an AI Acceleration Cloud platform that offers fast inference, fine-tuning, and training services. It provides self-service NVIDIA GPUs, model deployment on custom hardware, AI chat app, code execution sandbox, and tools to find the right model for specific use cases. The platform also includes a model library with open-source models, documentation for developers, and resources for advancing open-source AI. Together AI enables users to leverage pre-trained models, fine-tune them, or build custom models from scratch, catering to various generative AI needs.
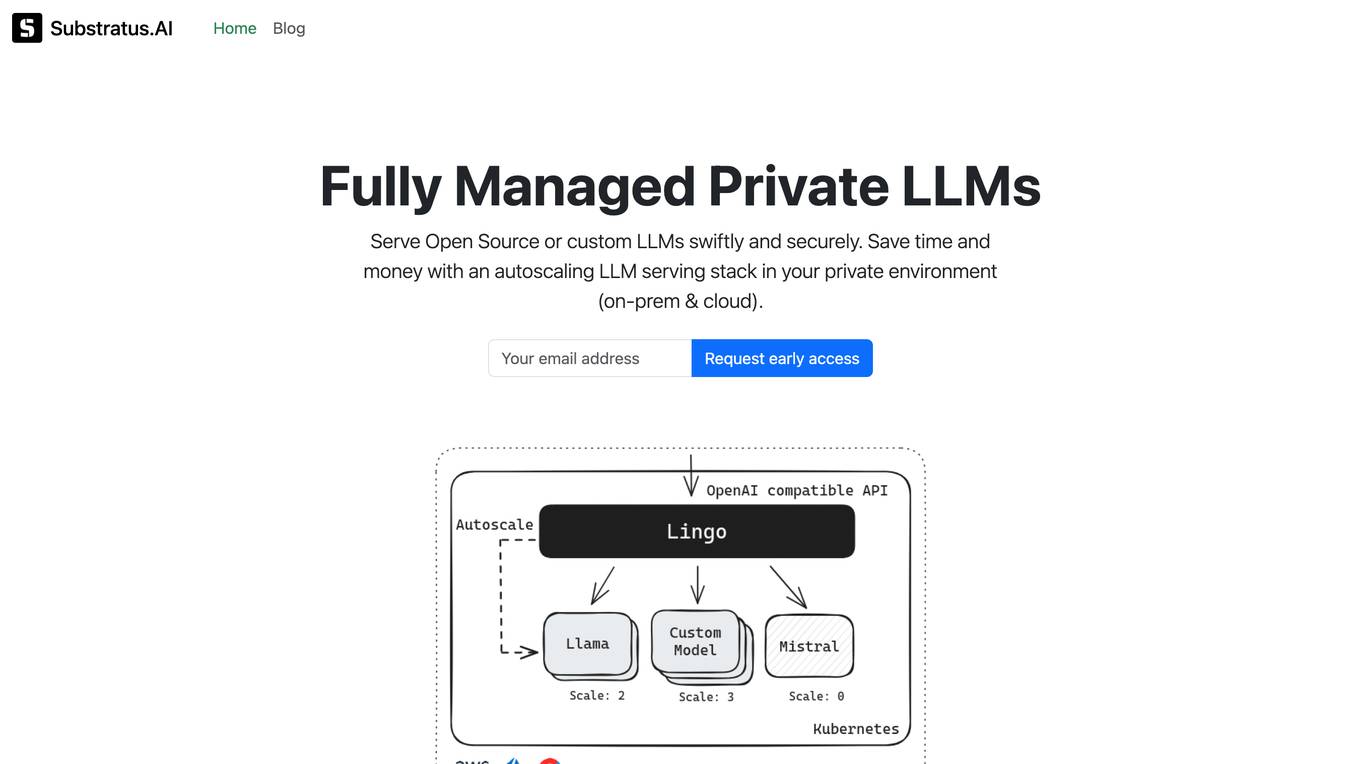
Substratus.AI
Substratus.AI is a fully managed private LLMs platform that allows users to serve LLMs (Llama and Mistral) in their own cloud account. It enables users to keep control of their data while reducing OpenAI costs by up to 10x. With Substratus.AI, users can utilize LLMs in production in hours instead of weeks, making it a convenient and efficient solution for AI model deployment.
0 - Open Source AI Tools
20 - OpenAI Gpts

Frontend Developer
AI front-end developer expert in coding React, Nextjs, Vue, Svelte, Typescript, Gatsby, Angular, HTML, CSS, JavaScript & advanced in Flexbox, Tailwind & Material Design. Mentors in coding & debugging for junior, intermediate & senior front-end developers alike. Let’s code, build & deploy a SaaS app.





Azure Arc Expert
Azure Arc expert providing guidance on architecture, deployment, and management.


Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.

Docker and Docker Swarm Assistant
Expert in Docker and Docker Swarm solutions and troubleshooting.



Cloudwise Consultant
Expert in cloud-native solutions, provides tailored tech advice and cost estimates.