Best AI tools for< Correct Data >
20 - AI tool Sites
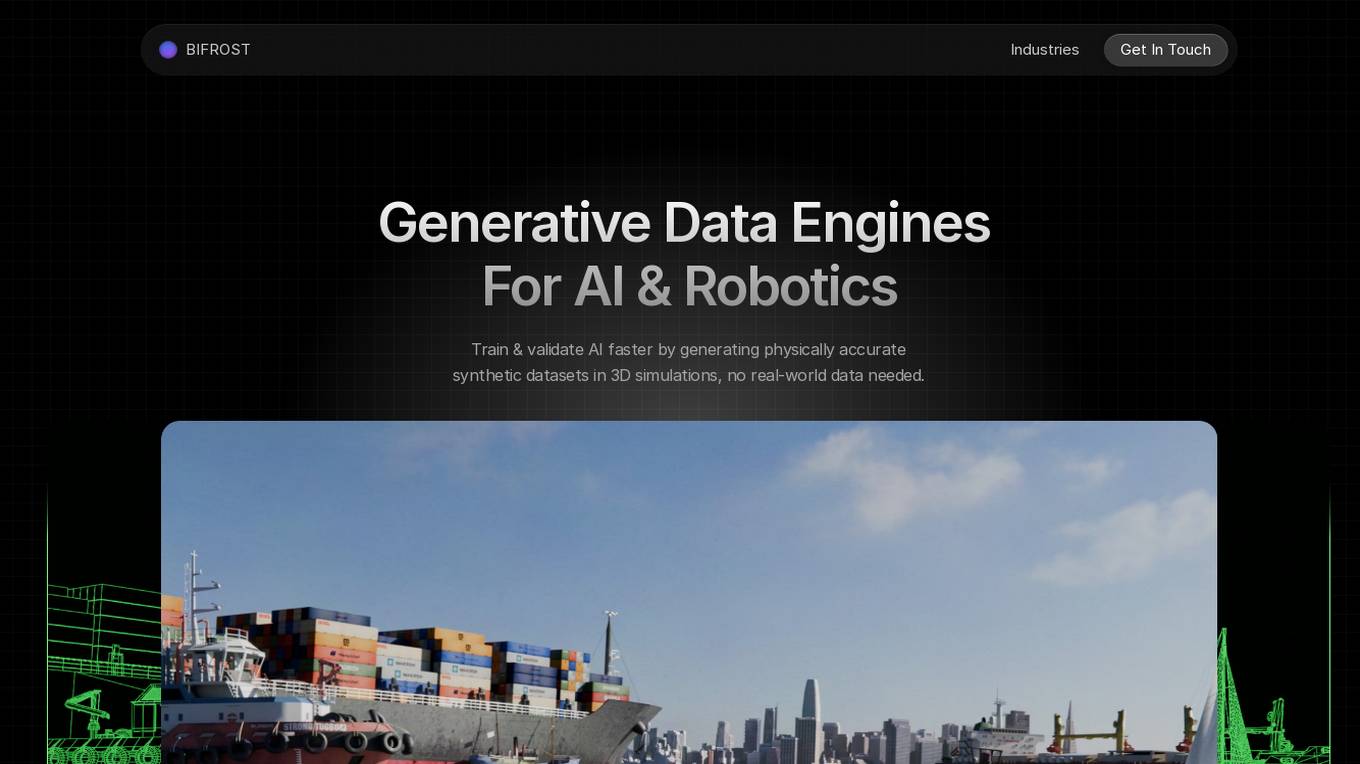
Bifrost AI
Bifrost AI is a data generation engine designed for AI and robotics applications. It enables users to train and validate AI models faster by generating physically accurate synthetic datasets in 3D simulations, eliminating the need for real-world data. The platform offers pixel-perfect labels, scenario metadata, and a simulated 3D world to enhance AI understanding. Bifrost AI empowers users to create new scenarios and datasets rapidly, stress test AI perception, and improve model performance. It is built for teams at every stage of AI development, offering features like automated labeling, class imbalance correction, and performance enhancement.
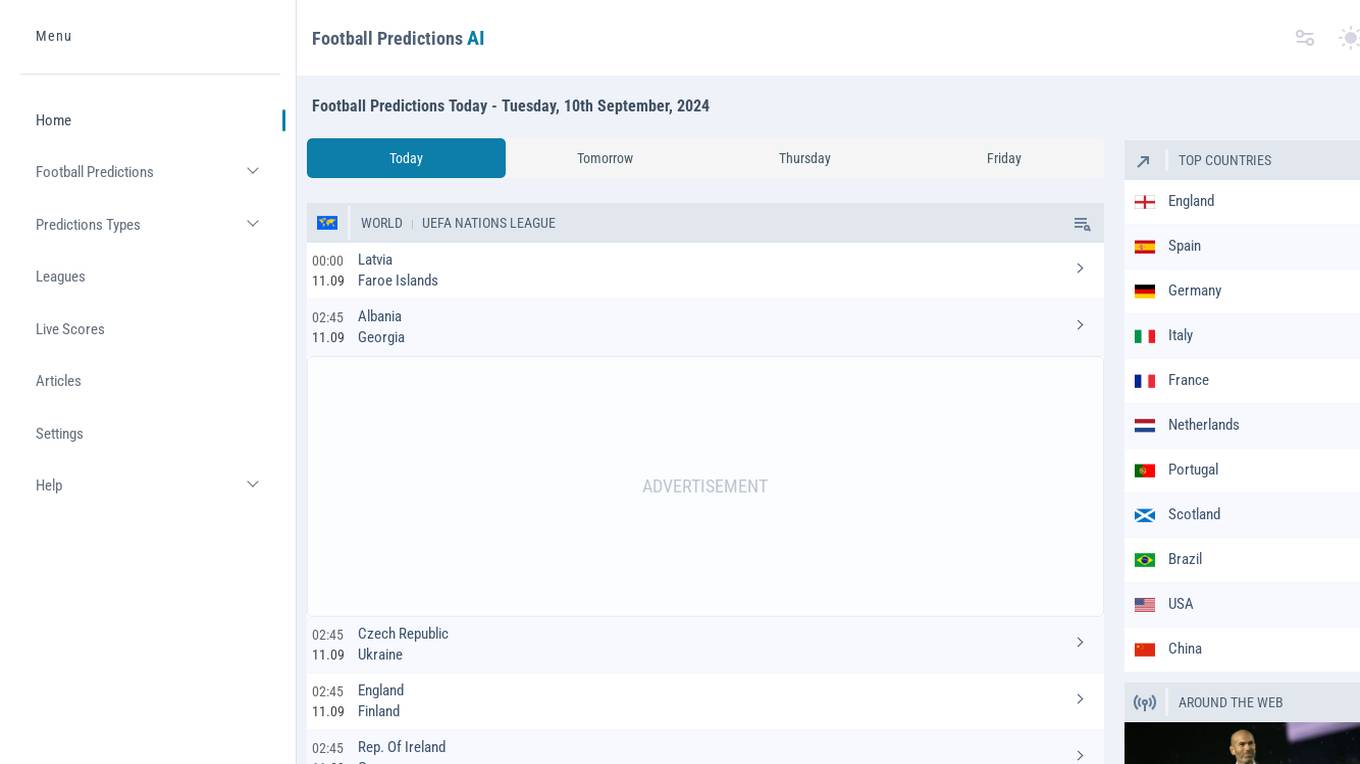
Football Predictions AI
Football Predictions AI is a website that provides users with accurate and reliable football match predictions. Users can access a variety of prediction types, including 1x2, BTTS, Over Under, and Correct Score predictions for matches across different leagues. The site also offers live scores, articles, and settings to customize the user experience. With a focus on user privacy and data protection, Football Predictions AI aims to enhance the football betting experience for enthusiasts and fans.
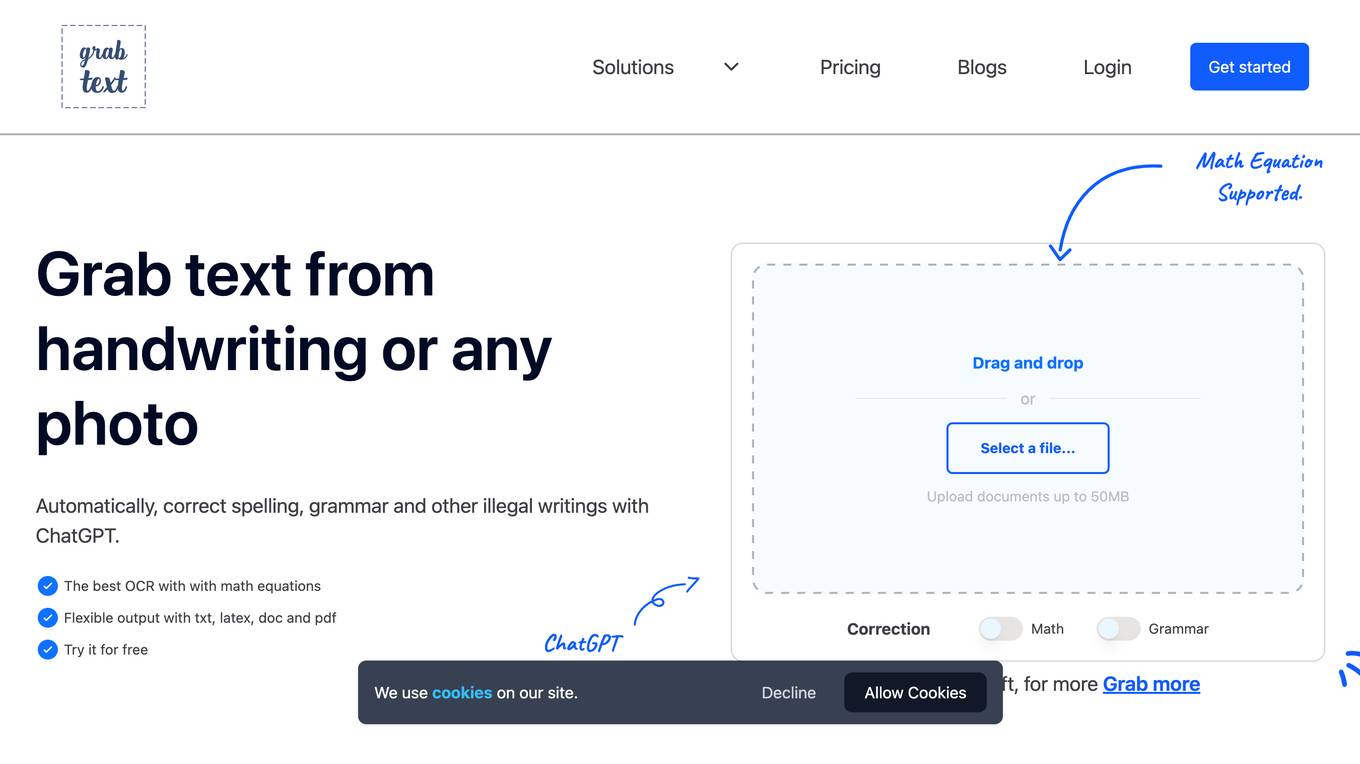
GrabText
GrabText is an online OCR tool that allows users to convert handwritten or printed text from photos, graphics, or documents into editable text. It uses ChatGPT to automatically correct spelling, grammar, and other illegal writings. The tool also supports math equations and offers flexible output options such as txt, latex, doc, and pdf.
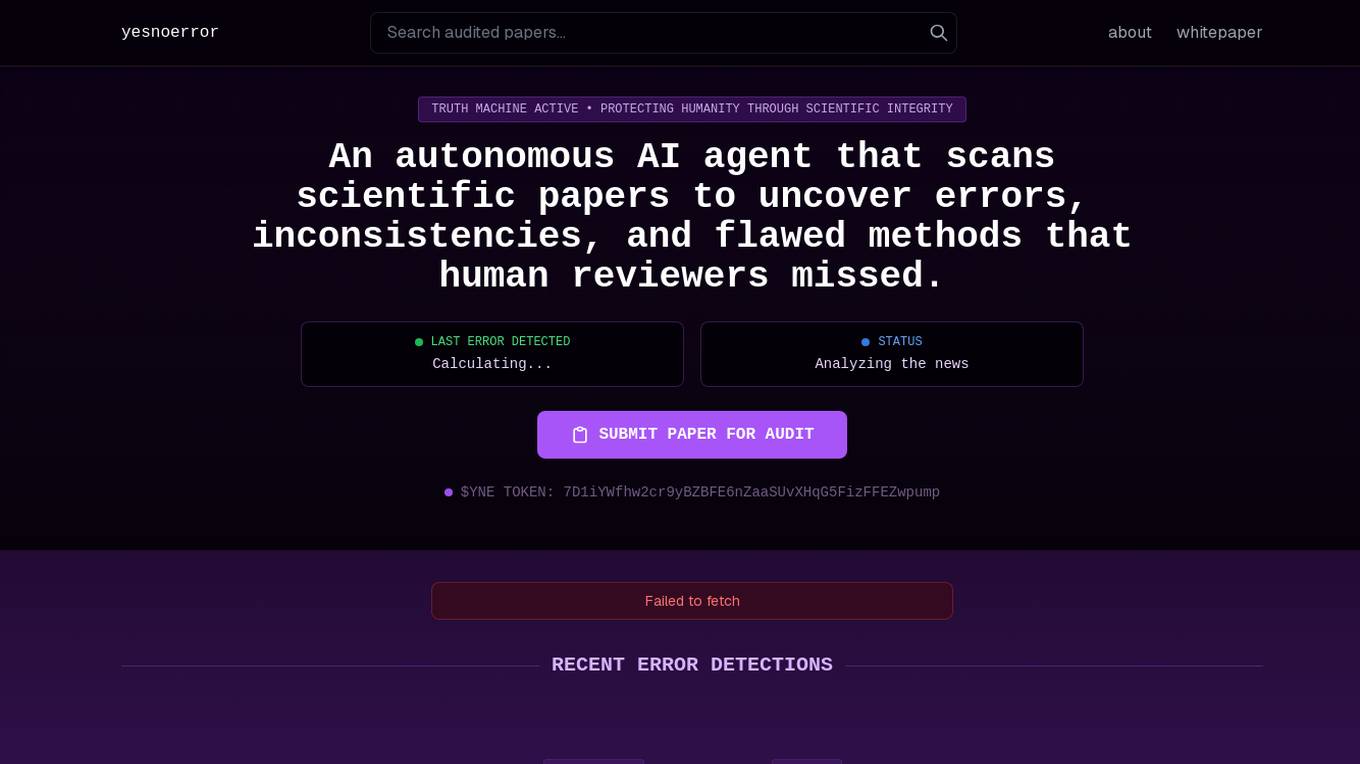
yesnoerror
yesnoerror is an autonomous AI agent developed by DeSci initiative that scans scientific papers to uncover errors, inconsistencies, and flawed methods that human reviewers may have missed. The tool utilizes blockchain technology and AI to audit science at scale, aiming to enhance scientific integrity through automated error detection. By analyzing papers from renowned repositories like arXiv, bioRxiv, and medRxiv, yesnoerror helps researchers identify and correct critical issues in research, such as mathematical errors and data discrepancies.
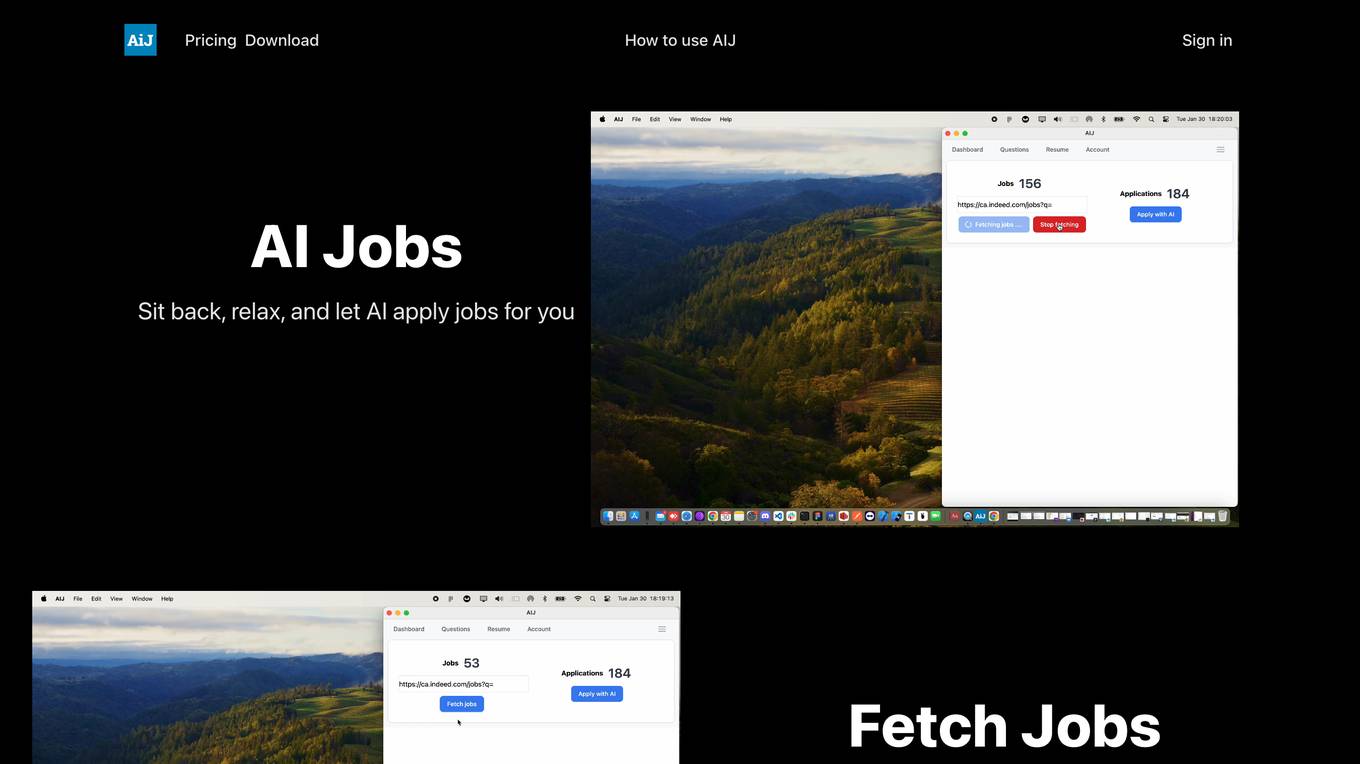
AIJ
AIJ is an AI tool designed to streamline the job application process by automating tasks such as job searching, application submission, and answering frequently asked questions. Users can save time and energy by letting AIJ handle these tasks efficiently. The tool also allows users to correct AI mistakes, enabling continuous learning and improvement.
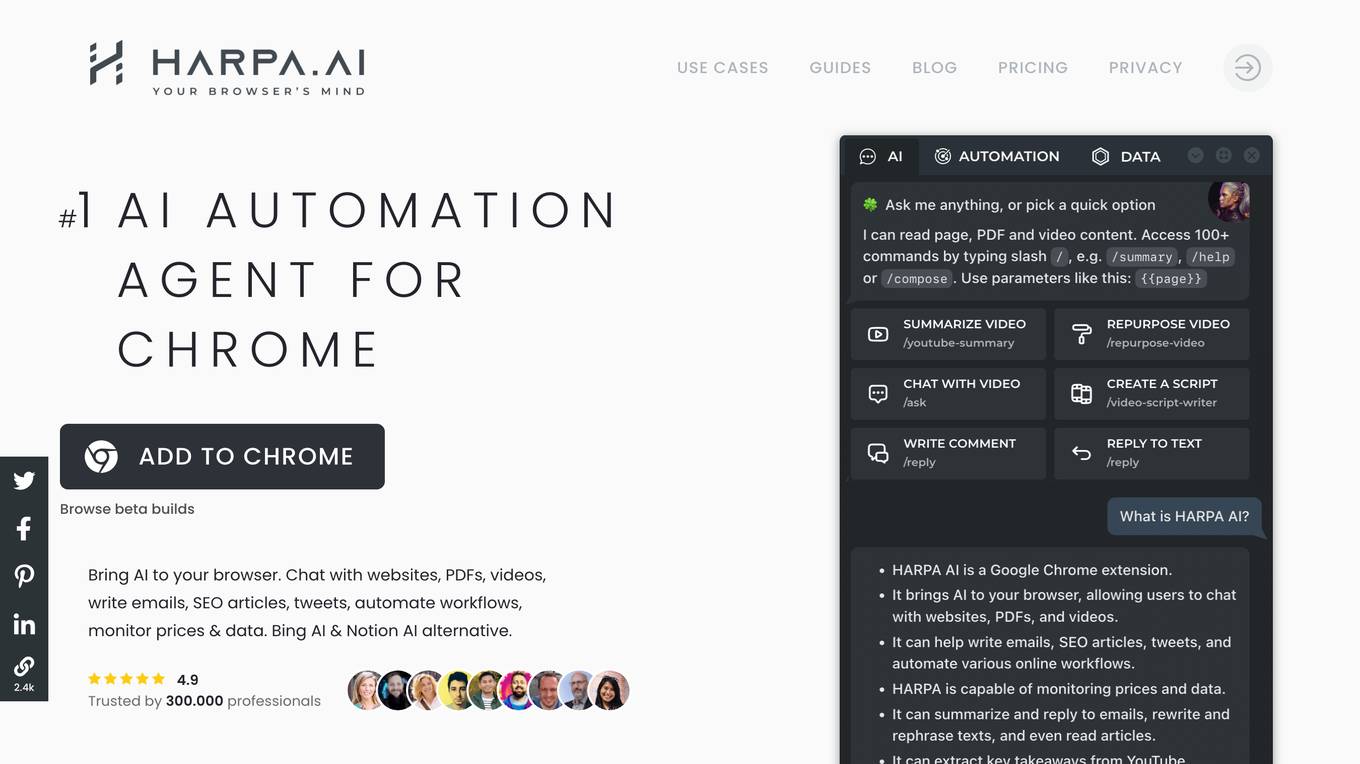
HARPA AI
HARPA AI is a Google Chrome extension that brings AI to your browser. It can summarize and reply to emails, rewrite, rephrase, correct and expand text, read articles, translate and scan web pages for data. HARPA has a hybrid AI engine and works with OpenAI GPT-3 & GPT-4 API, ChatGPT, Claude2 and Google Gemini.
AI Seed Phrase Finder & BTC balance checker tool for Windows PC
The AI Seed Phrase Finder & BTC balance checker tool for Windows PC is an innovative application designed to prevent the loss of access to Bitcoin wallets. Leveraging advanced algorithms and artificial intelligence techniques, this program efficiently analyzes vast amounts of data to pre-train AI models. Consequently, it generates and searches for mnemonic phrases that grant access to abandoned Bitcoin wallets holding nonzero balances. With the “AI Seed Finder tool for Windows PC”, locating a complete 12-word seed phrase for a specific Bitcoin wallet becomes effortless. Even if you possess only partial knowledge of the mnemonic phrase or individual words comprising it, this tool can swiftly identify the entire seed phrase. Furthermore, by providing the address of a specific Bitcoin wallet you wish to regain access to, the program narrows down the search area. This targeted approach significantly enhances the program’s efficiency and reduces the time required to ascertain the correct mnemonic phrase.
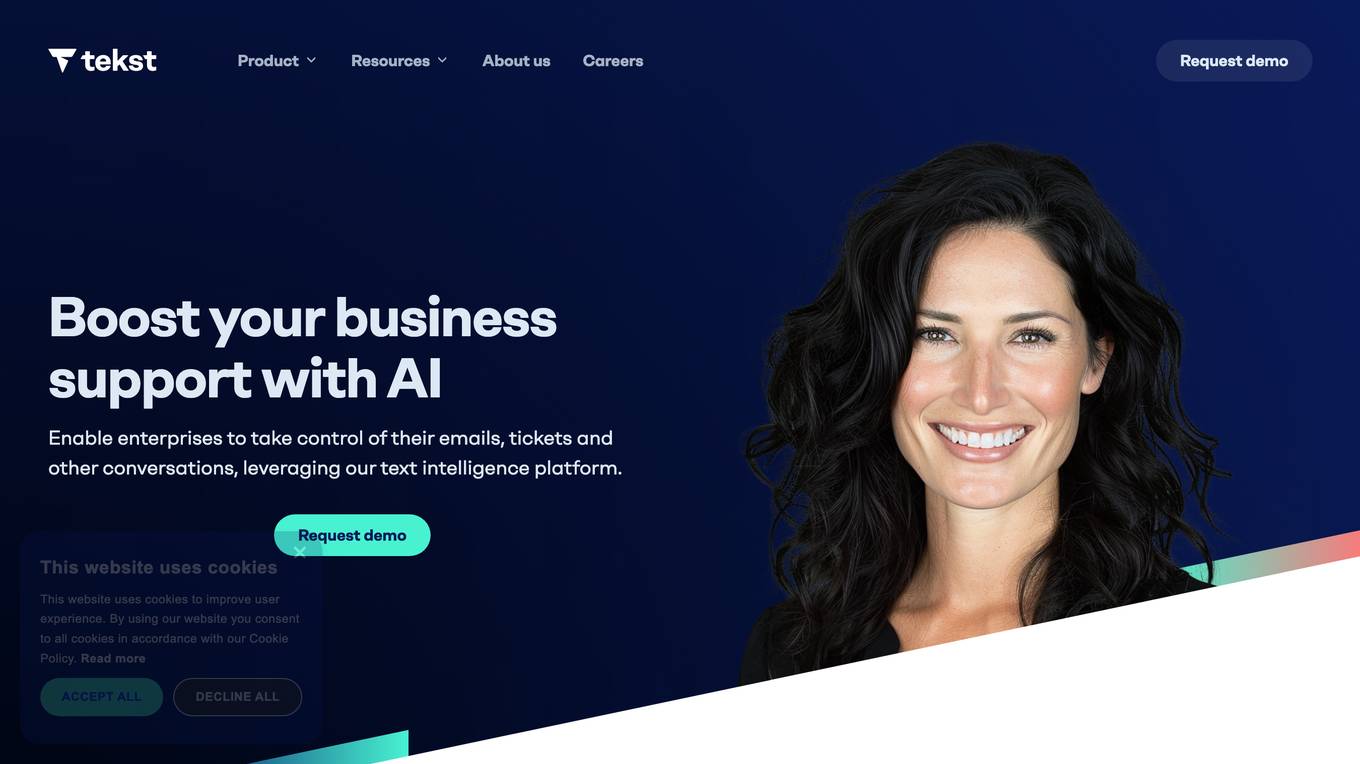
Tekst
Tekst is an AI-powered platform that helps businesses automate their email, ticket, and other communication workflows. By leveraging text intelligence, Tekst enables enterprises to gain insights into their communication data, optimize critical workflows, and deliver better customer service. With its advanced AI capabilities, Tekst can analyze messages, enrich them with tags, reroute them to the correct inbox, and even automate responses, significantly reducing the time wasted on manual tasks.
Legal Data
Legal Data is a comprehensive legal research platform developed by lawyers for lawyers. It offers a powerful search feature that covers various legal areas from commercial to criminal law. The platform recognizes synonyms, legalese, and abbreviations, corrects typos, and provides suggestions as you type. Additionally, Legal Data includes an AI-assistant called FlyBot, trained on carefully selected laws and cases, to provide accurate legal answers without fabricating information.
Kodezi
Kodezi is an AI-powered development tool that helps developers write better code. It offers a range of features to help developers with tasks such as code autocorrect, code review, and debugging. Kodezi is available as a web-based IDE, a VS Code extension, and an enterprise solution.
Resumecheck.net
Resumecheck.net is an AI-powered resume improvement platform that helps users create error-free, professional resumes that stand out to recruiters. The platform uses GPT4 technology to provide personalized feedback and suggestions, including grammar corrections, formatting adjustments, and industry-specific keyword optimization. Additionally, Resumecheck.net offers an AI Cover Letter Writer that generates tailored cover letters based on the user's resume and the specific job position they are applying for.
AiText
AiText is an AI-powered writing assistant that enhances the quality of texts, corrects spelling and grammar errors, and generates new texts effortlessly. It offers a range of features including vocabulary enhancement, sentence structure optimization, grammar and spell checking, and text generation. The application is versatile and can be used for various purposes such as creating social media posts, emails, articles, reports, and professional documents. It is designed to improve communication clarity, accelerate writing tasks, and enhance writing skills for academic and professional pursuits.
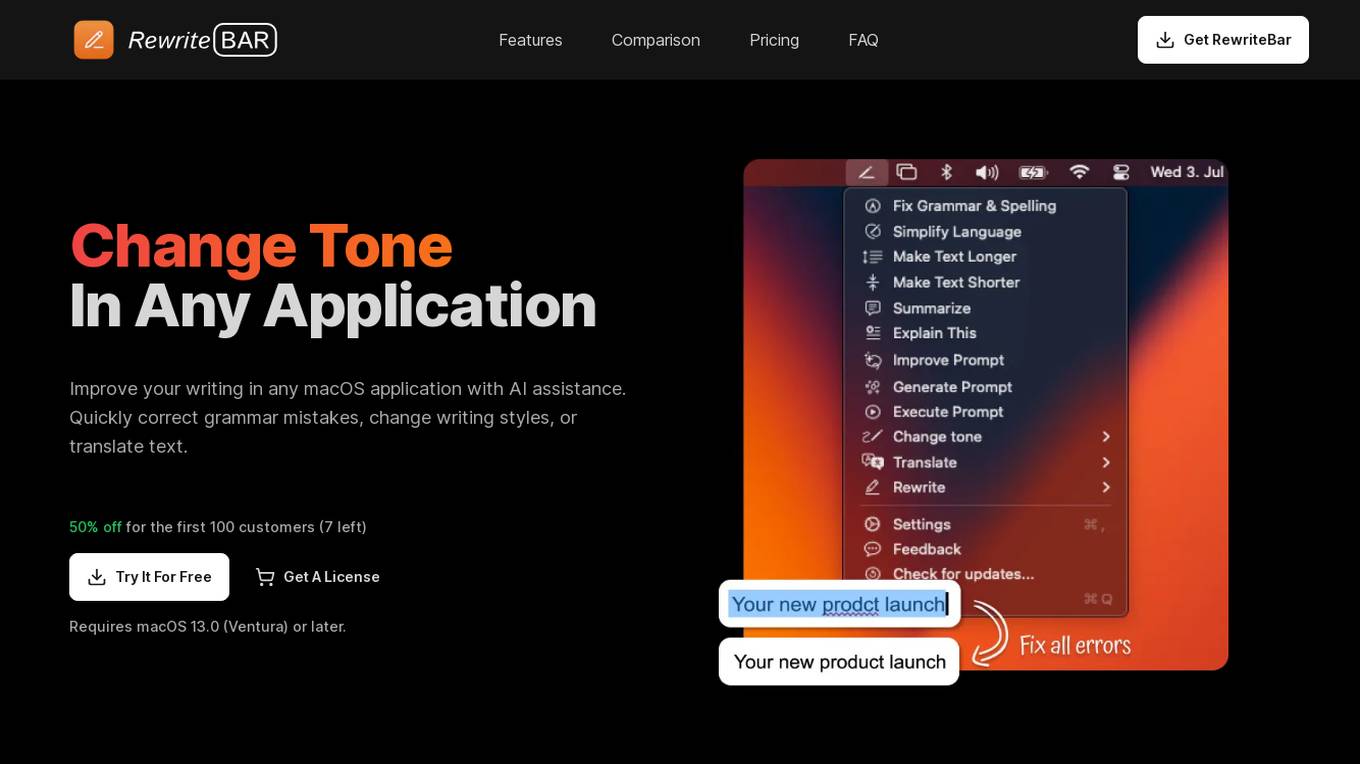
RewriteBar
RewriteBar is an AI assistant tool designed for macOS users to improve their writing in any application. It offers features such as correcting grammar mistakes, changing writing styles, translating text, simplifying language, adjusting writing tone, summarizing paragraphs, and enhancing ChatGPT output. RewriteBar is a cost-effective solution that works seamlessly across various applications, making it a valuable tool for non-native English speakers, developers, and content creators.
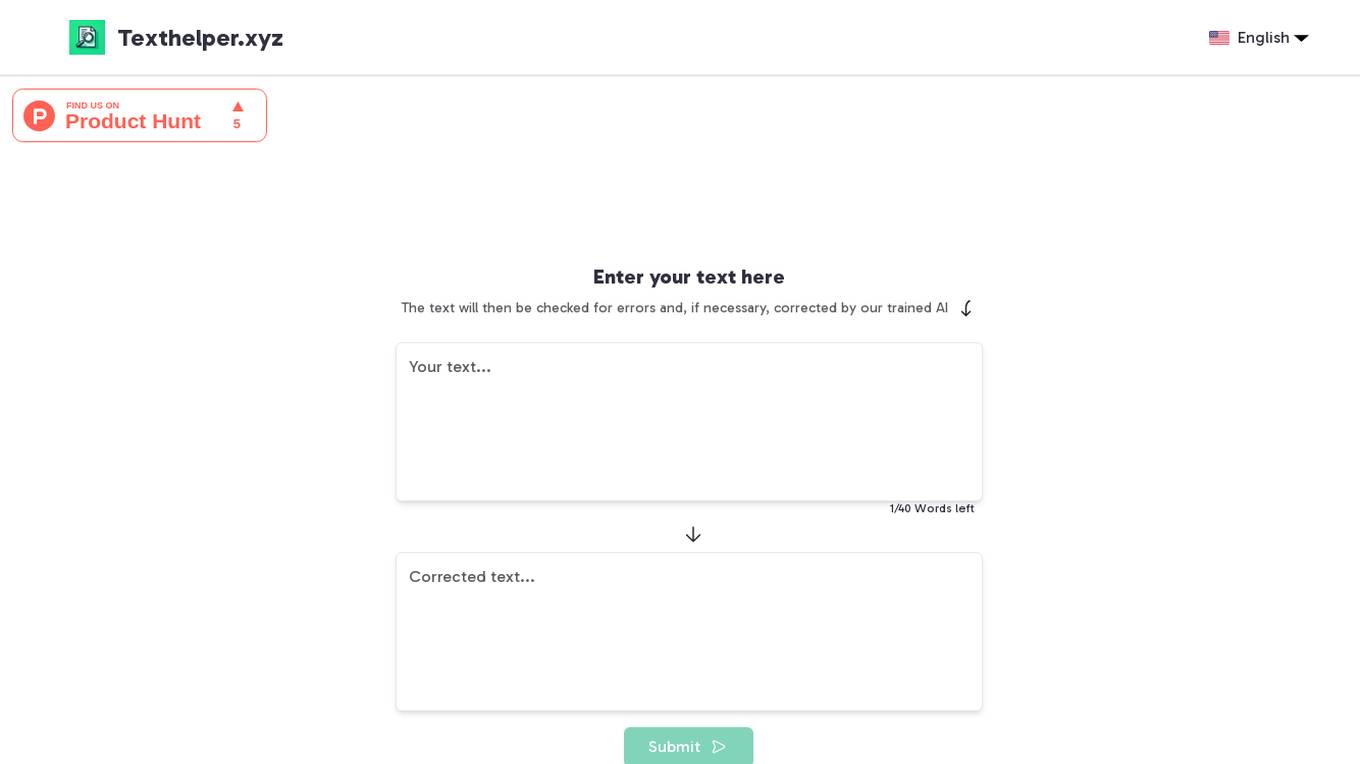
Texthelper
Texthelper is an AI-powered text correction tool designed to assist users in identifying and correcting errors in their written content. Users can input text, which will be analyzed by the tool's AI algorithms to detect and fix mistakes. The tool aims to enhance the overall quality and accuracy of written communication by providing quick and efficient error detection and correction. Texthelper is user-friendly and suitable for individuals, students, professionals, and anyone looking to improve the correctness of their written text.
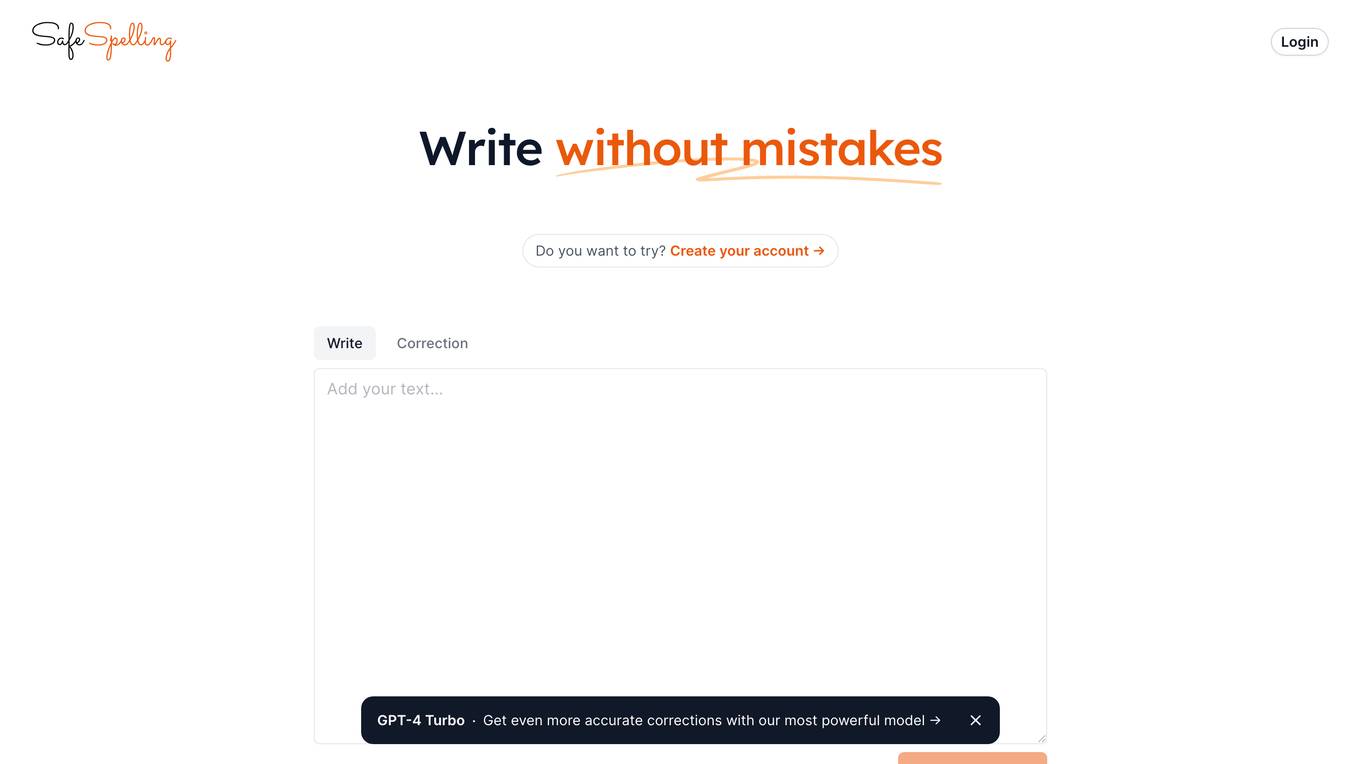
SafeSpelling
SafeSpelling is an AI-powered tool designed to help users write without mistakes. It provides users with the ability to input text and receive corrections for any spelling errors. The tool compares the original text with the corrected text, highlighting mistakes and offering suggestions for improvement. SafeSpelling aims to enhance the writing experience by ensuring that users can produce error-free content effortlessly.

slAItor
slAItor is an AI translation assistant powered by GPT technology. It offers advanced translation features and customization options to enhance the translation experience. Users can benefit from step-by-step translations, multiple translation alternatives, and unique translation styles. The tool supports 28 language pairs and combines recent AI advancements with traditional translation techniques to deliver accurate and efficient translations. slAItor also provides post-processing and evaluation steps to ensure translation quality and offers a user-friendly interface for seamless translation management.
NeuroSpell
NeuroSpell is a universal auto-corrector powered by deep learning. It can be used to correct spelling, grammar, and style errors in text. NeuroSpell can be deployed on-premise or in the cloud, and it can be trained on domain-specific vocabulary and sentence structures. NeuroSpell is used by businesses and individuals to improve the quality of their written communication.

Spruce Autocorrect
Spruce is an AI tool designed to automatically correct typos in your Slack messages. It edits your messages in real-time to ensure accurate communication. The tool allows users to easily undo corrections by adding a specific reaction to the message. Spruce is a helpful solution for enhancing the quality of written communication within Slack teams.
LanguageTool
LanguageTool is an AI-based spelling, style, and grammar checker that helps correct or paraphrase texts across languages. It offers a range of features including grammar checking, paraphrasing, punctuation correction, style improvement, and more. LanguageTool is available as a browser extension, desktop app, and mobile app, and it supports over 30 languages. It is used by over 2000 organizations, including BMW Group, European Union, Spiegel Magazine, and Deutsche Presse-Agentur (dpa).
Trinka
Trinka is an AI-powered English grammar checker and language enhancement writing assistant designed for academic and technical writing. It corrects contextual spelling mistakes and advanced grammar errors by providing writing suggestions in real-time. Trinka helps professionals and academics ensure formal, concise, and engaging writing.
1 - Open Source AI Tools
lfai-landscape
LF AI & Data Landscape is a map to explore open source projects in the AI & Data domains, highlighting companies that are members of LF AI & Data. It showcases members of the Foundation and is modelled after the Cloud Native Computing Foundation landscape. The landscape includes current version, interactive version, new entries, logos, proper SVGs, corrections, external data, best practices badge, non-updated items, license, formats, installation, vulnerability reporting, and adjusting the landscape view.
20 - OpenAI Gpts
Hallucinate
Highly accurate and reliable, ensures information is 100% correct, never hallucinates.
Word Problem Solver
Expert at solving and explaining word problems, with error correction.
Profesor de posgrado
Profesor de posgrado con enfoque académico en Metodología de la Investigación, experto en desarrollo de clases y corrección de textos.
美国+英国地道英语老师
Correct English grammar errors or translate sentences into American English and British English.
![Listicle Builder GPT [WordsAtScale] Screenshot](/screenshots_gpts/g-jt0xMOEcn.jpg)
Listicle Builder GPT [WordsAtScale]
Create factually correct unique news-driven listicles to attract backlinks
Faith Explorer
A religious knowledge expert providing comprehensive, correct, and unbiased information.
General Knowledge Quiz
Dynamic quiz game with a wide range of topics, +3 points for correct answers, -2 for incorrect. 5-minute limit.
Conversation
A highly intelligent conversationalist. Direct, concise, rational, and brutally honest. I want to correct your false beliefs, not feed your ego.
Confident
This GPT is the most confident GPT out there. It performs and gives answers without doubting itself. It will correct you if you give wrong suggestions. Bringing back the confidence to ChatGPT!
Correcteur d'orthographe et de grammaire
Je corrige les fautes d'orthographe et de grammaire en français et explique les erreurs.
Chinese Grammar Wiki Tutor
A Mandarin Chinese grammar tutor, offering grammar corrections and advice.
English Mentor
English conversation teacher, correcting grammar and engaging with questions.
TextPerfect🇳🇱
Nederlandse taaldeskundige voor tekstcorrectie en -redactie. Plak je tekst hieronder.. ⬇️
Corrector de textos
Niño sabiondo dedicado a la corrección de textos en español. Claridad y precisión son mi obsesión