Best AI tools for< Compare Evaluations >
20 - AI tool Sites
Fahim AI
Fahim AI is a premier destination for in-depth reviews and analyses of the latest advancements in artificial intelligence and software technology. The website empowers tech enthusiasts, professionals, and casual readers with reliable information to stay ahead in the rapidly evolving digital world. It offers comprehensive evaluations of cutting-edge AI systems, detailed reviews of software solutions, insights on the latest tech gadgets integrated with AI capabilities, side-by-side product comparisons, easy-to-follow tutorials and guides, expert opinions from industry leaders, and a community platform for sharing experiences and connecting with like-minded individuals.
AIPresentationMakers
The website is a platform that provides reviews and recommendations for AI presentation makers. It offers in-depth guides on various AI presentation generators and helps users choose the best one for their needs. The site features detailed reviews of different AI presentation software, including their features, pros, and cons. Users can find information on popular AI tools like Plus AI, Canva, Beautiful.ai, and more. The platform also includes comparisons between different AI tools, pricing details, and evaluations of AI outputs and design components.
Softwareviews.net
Softwareviews.net is an AI tool that provides reviews and recommendations for various AI LinkedIn photo generators and headshot generators. The website offers insights and evaluations on the best AI headshot generators of 2025, helping users make informed decisions when choosing a tool for creating professional profile pictures. With detailed reviews and comparisons, softwareviews.net aims to assist individuals in finding the most suitable AI tool for their needs.

AI Tool Reviews
The website is a platform that provides comprehensive and unbiased reviews of various AI tools and applications. It aims to help users, especially small businesses, make informed decisions about selecting the right AI tools to enhance productivity and stay ahead of the competition. The site offers detailed comparisons, interviews with AI innovators, expert tips, and insights into the future of artificial intelligence. It also features blog posts on AI-related topics, free resources, and a newsletter for staying updated on the latest AI trends and tools.
Vals AI
Vals AI is an advanced AI tool that provides benchmark reports and comparisons for various models in the fields of finance, coding, and law. The platform offers insights into the performance of different AI models across different tasks and industries. Vals AI aims to bridge the gap in model benchmarking and provide valuable information for users looking to evaluate and compare AI models for specific tasks.
1st things 1st
1st things 1st is an online tool that helps users prioritize tasks and make decisions. It offers two prioritization tools: intuitive and smart. The intuitive tool allows users to compare options in pairs and organize them based on personal preferences. The smart tool uses AI-powered autosuggestion and fast evaluations to help users make confident and informed decisions. 1st things 1st also provides customizable templates and allows users to export their priorities to their favorite productivity apps. The tool is designed to help users clarify their goals, make complex decisions, and achieve their objectives.
Weights & Biases
Weights & Biases is an AI tool that offers documentation, guides, tutorials, and support for using AI models in applications. The platform provides two main products: W&B Weave for integrating AI models into code and W&B Models for building custom AI models. Users can access features such as tracing, output evaluation, cost estimates, hyperparameter sweeps, model registry, and more. Weights & Biases aims to simplify the process of working with AI models and improving model reproducibility.

Brevoir
Brevoir is an AI-powered decision-grade due diligence tool designed for startup investing. It consolidates founder diligence, market and competitor research, risk assessment, and investment-ready writeups in one platform. Tailored for angel investors and startup evaluators, Brevoir streamlines the startup evaluation process by extracting key information from pitch decks or company URLs, verifying claims, mapping competitors, and providing structured reports with risks and opportunities. The tool aims to provide clear answers, identify market trends, evaluate team credibility, assess traction and risks, and offer pricing plans that scale with user needs.
MindpoolAI
MindpoolAI is a tool that allows users to access multiple leading AI models with a single query. This means that users can get the answers they are looking for, spark ideas, and fuel their work, creativity, and curiosity. MindpoolAI is easy to use and does not require any technical expertise. Users simply need to enter their prompt and select the AI models they want to compare. MindpoolAI will then send the query to the selected models and present the results in an easy-to-understand format.
CV Ranker AI
CV Ranker AI is an AI-powered tool designed to streamline the hiring process by analyzing and ranking CVs based on job requirements. It saves time by providing instant candidate rankings with detailed match breakdowns, skill analysis, and consistent evaluation metrics. The tool helps in identifying top candidates efficiently, reducing the risk of missing qualified individuals and ensuring objective comparison of applicants.

usefulAI
usefulAI is a platform that allows users to easily add AI features to their products in minutes. Users can find AI features that best meet their needs, test them using the platform's playground, and integrate them into their products through a single API. The platform offers a user-friendly playground to test and compare AI solutions, provides pricing and metrics for evaluation, and allows integration within applications using a single API. usefulAI aims to provide practical AI engines in one place, without hype, for users to leverage in their products.
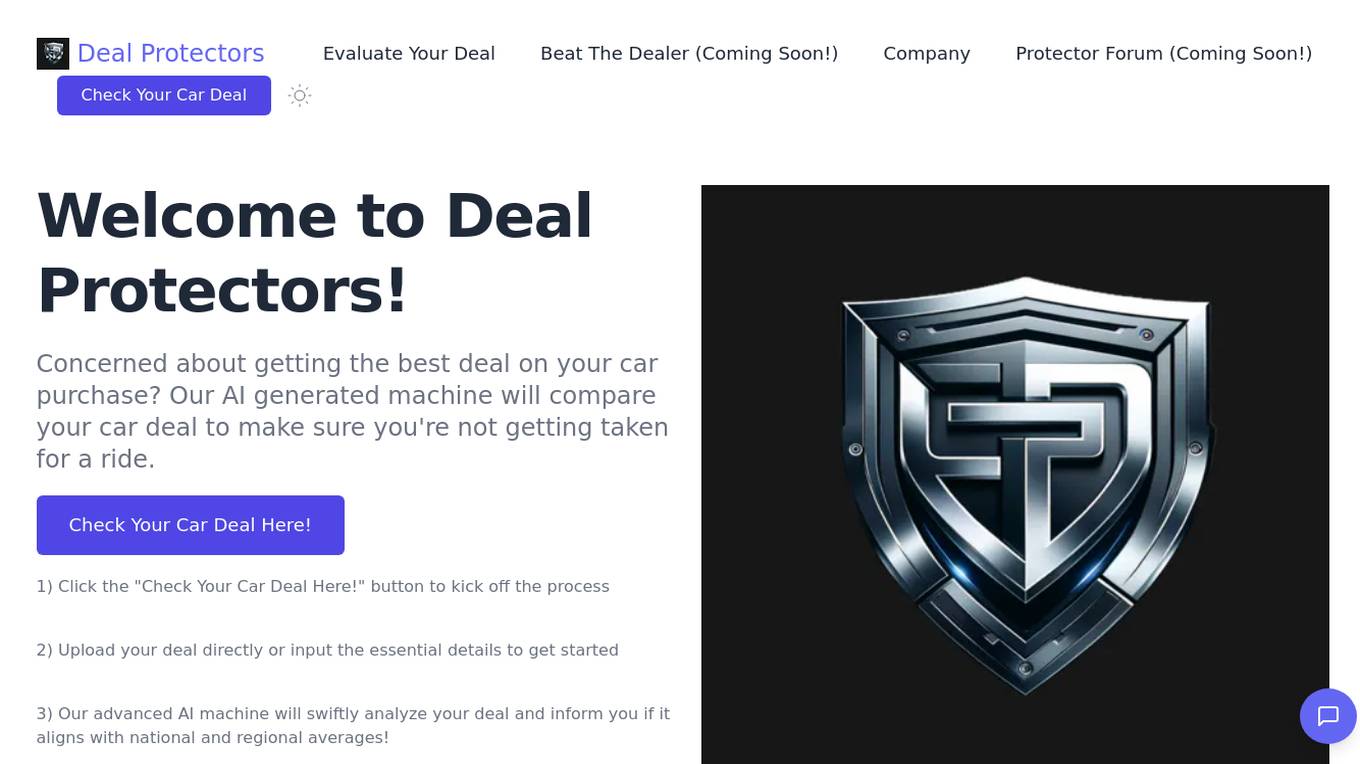
Deal Protectors
Deal Protectors is an AI-driven website designed to help users evaluate their car deals to ensure they are getting the best possible price. The platform allows users to upload their deal or input essential details for analysis by an advanced AI machine. Deal Protectors aims to provide transparency, empowerment, and community support in the car purchasing process by comparing deals with national and regional averages. Additionally, the website features a protection forum for sharing dealership experiences, a game called 'Beat The Dealer,' and testimonials from satisfied customers.

Rawbot
Rawbot is an AI model comparison tool that simplifies the process of selecting the best AI models for projects and applications. It allows users to compare various AI models side-by-side, providing insights into their performance, strengths, weaknesses, and suitability. Rawbot helps users make informed decisions by identifying the most suitable AI models based on specific requirements, leading to optimal results in research, development, and business applications.
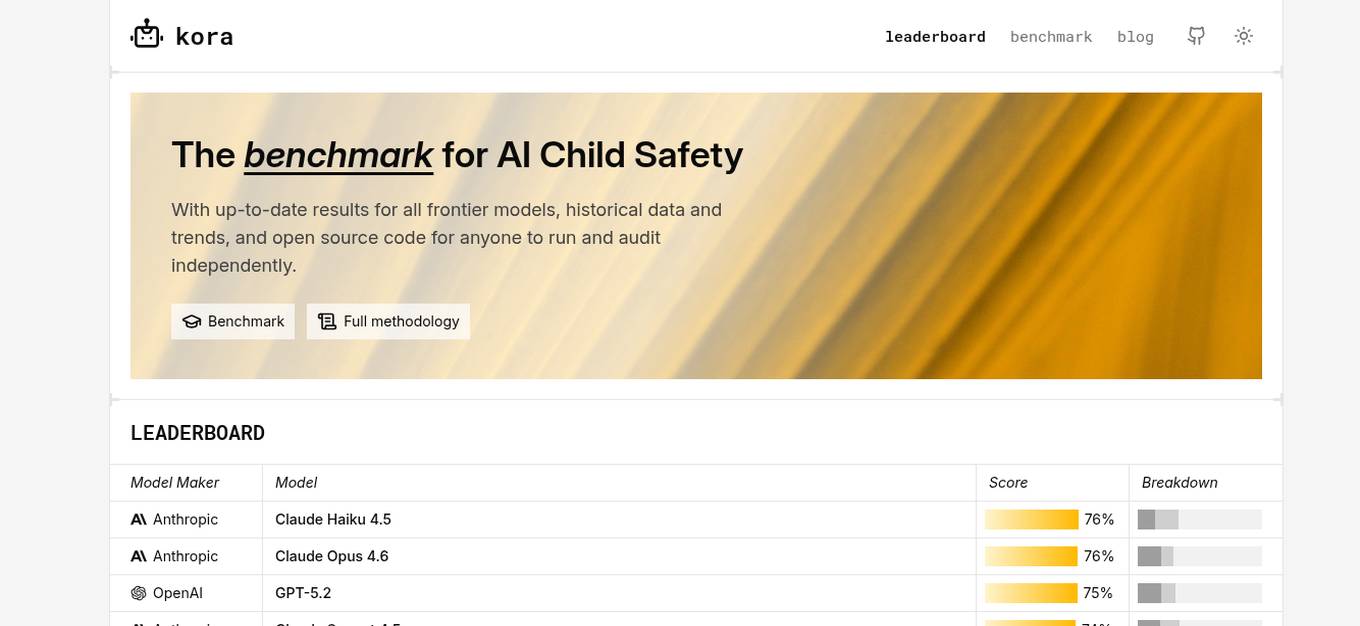
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.
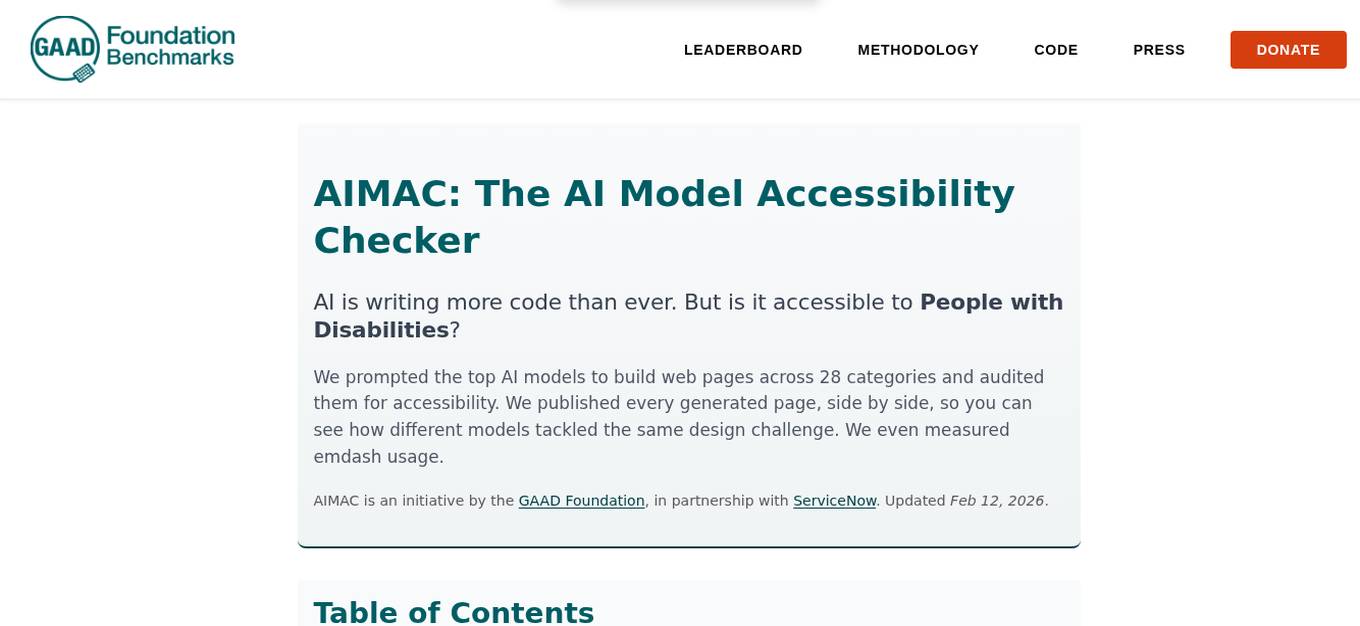
AIMAC Leaderboard
AIMAC Leaderboard is an AI Model Accessibility Checker that evaluates the accessibility of web pages generated by AI models across 28 categories. It compares top AI models side by side, auditing them for accessibility and measuring their performance. The initiative aims to ensure that AI models write accessible code by default. The project is a collaboration between the GAAD Foundation and ServiceNow, providing insights into how different models handle the same design challenges.
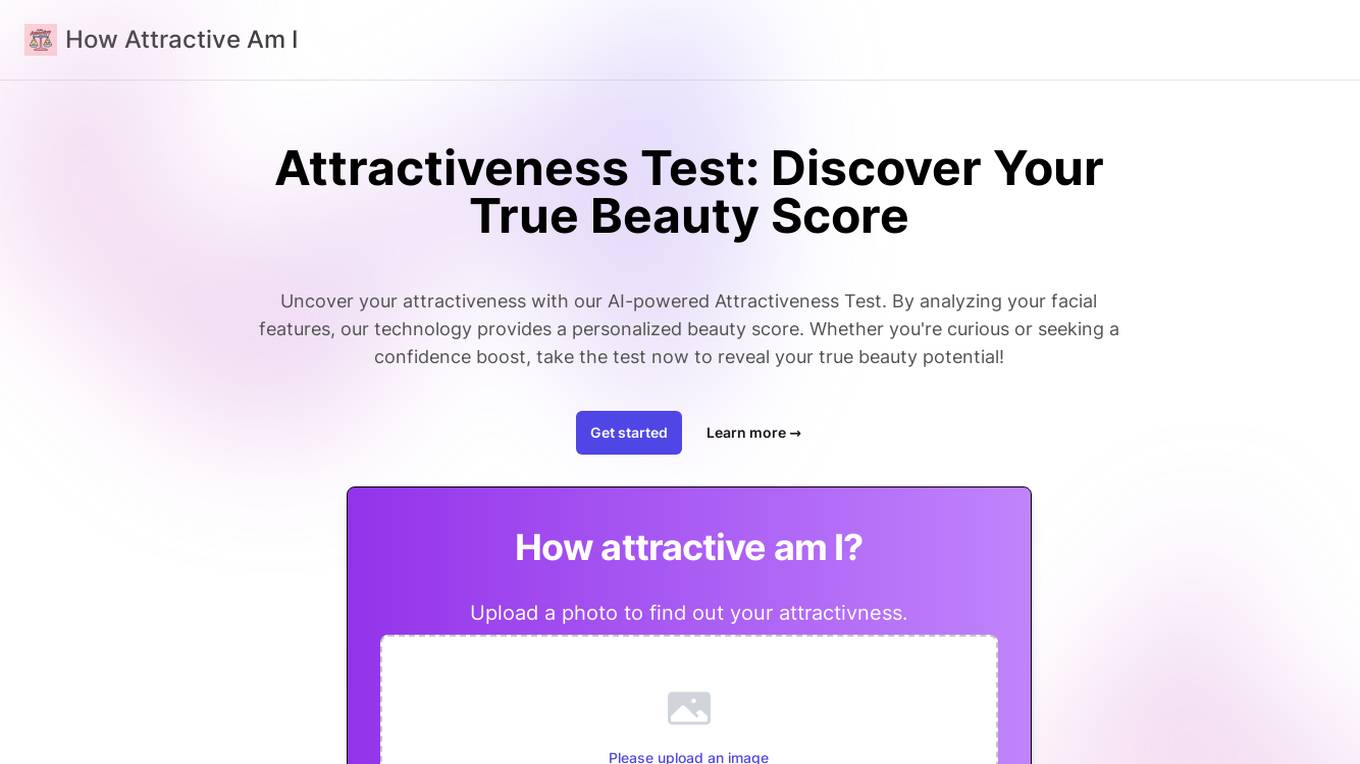
How Attractive Am I
How Attractive Am I is an AI-powered tool that analyzes facial features to calculate an attractiveness score. By evaluating symmetry and proportions, the tool provides personalized beauty scores. Users can upload a photo to discover their true beauty potential. The tool ensures accuracy by providing guidelines for taking photos and offers a fun and insightful way to understand facial appeal.
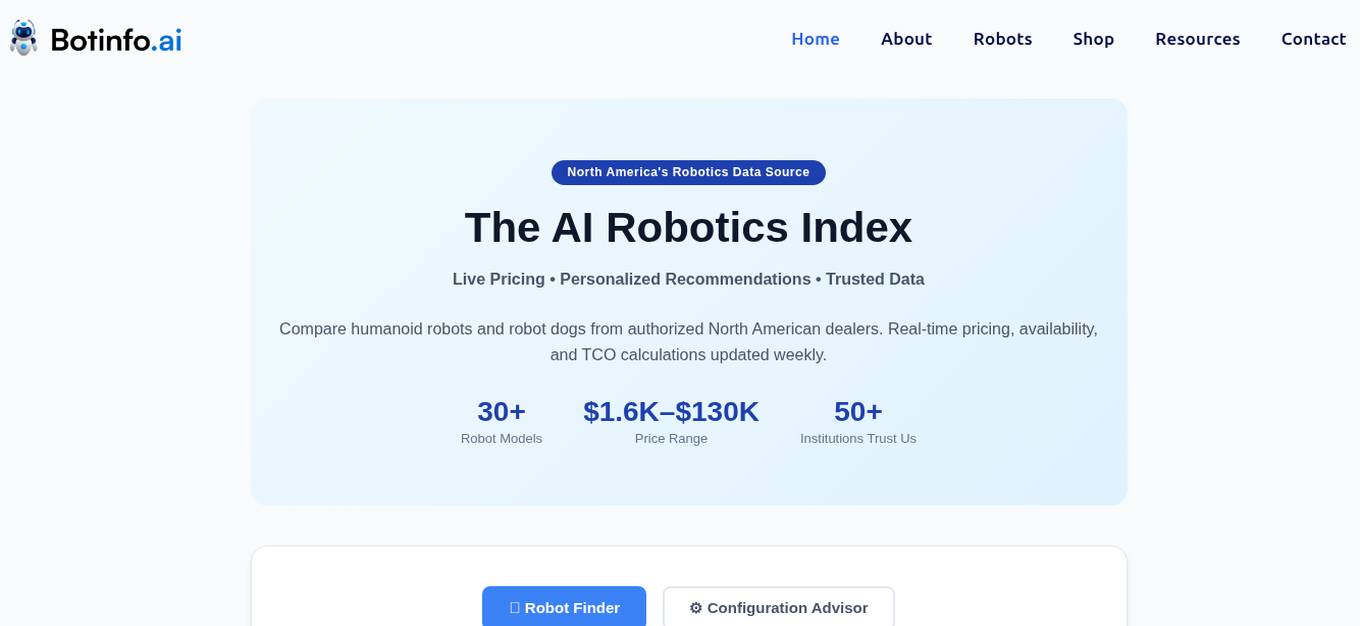
BotInfo.ai
BotInfo.ai is an AI application that serves as the AI Robotics Index providing live prices and personalized recommendations for humanoid robots and robot dogs. It offers a comprehensive platform for comparing and evaluating various robot models, along with real-time pricing, availability, and total cost of ownership calculations. Users can generate procurement packages, download PDFs with specifications, and receive assistance in selecting the right robot for their specific needs. The platform caters to a wide range of organizations, including universities, research labs, schools, corporations, and government/military entities, offering tailored solutions for different use cases and budgets.
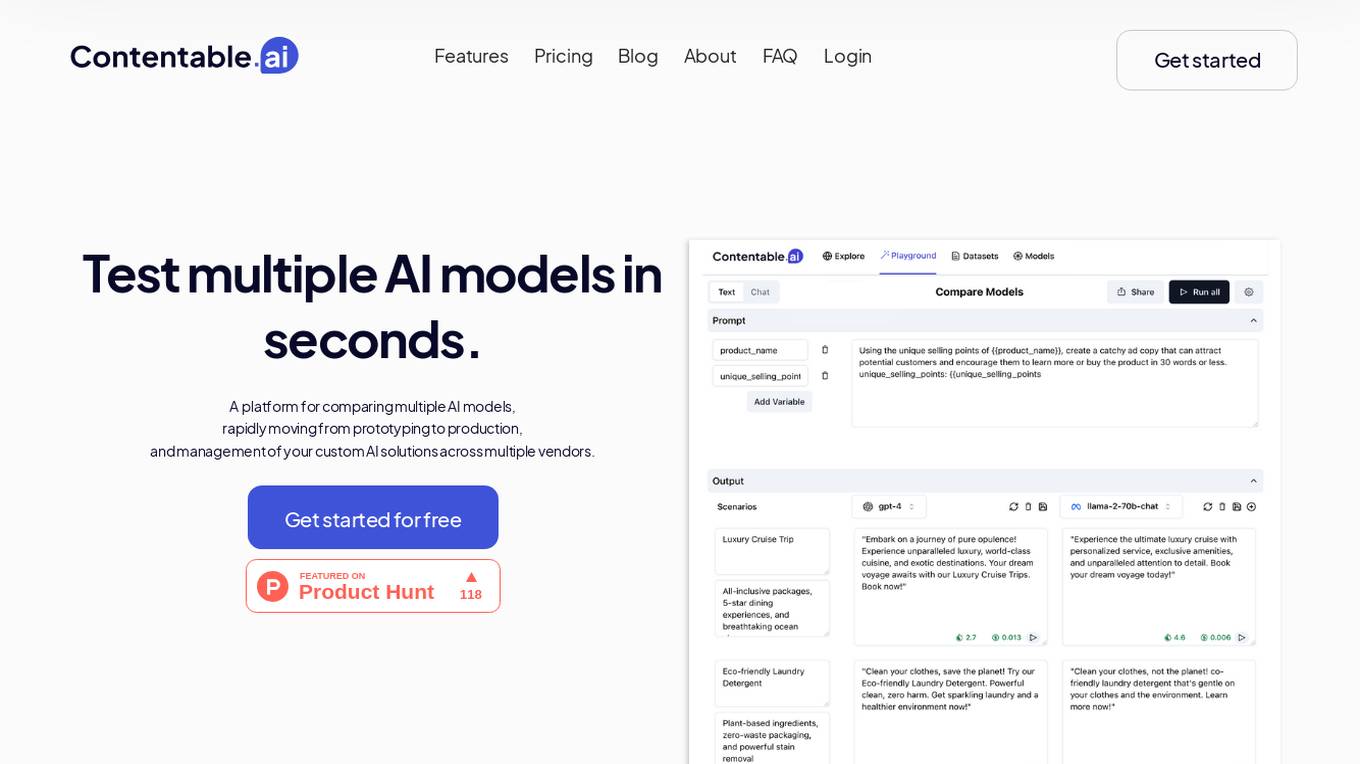
Contentable.ai
Contentable.ai is a platform for comparing multiple AI models, rapidly moving from prototyping to production, and management of your custom AI solutions across multiple vendors. It allows users to test multiple AI models in seconds, compare models side-by-side across top AI providers, collaborate on AI models with their team seamlessly, design complex AI workflows without coding, and pay as they go.
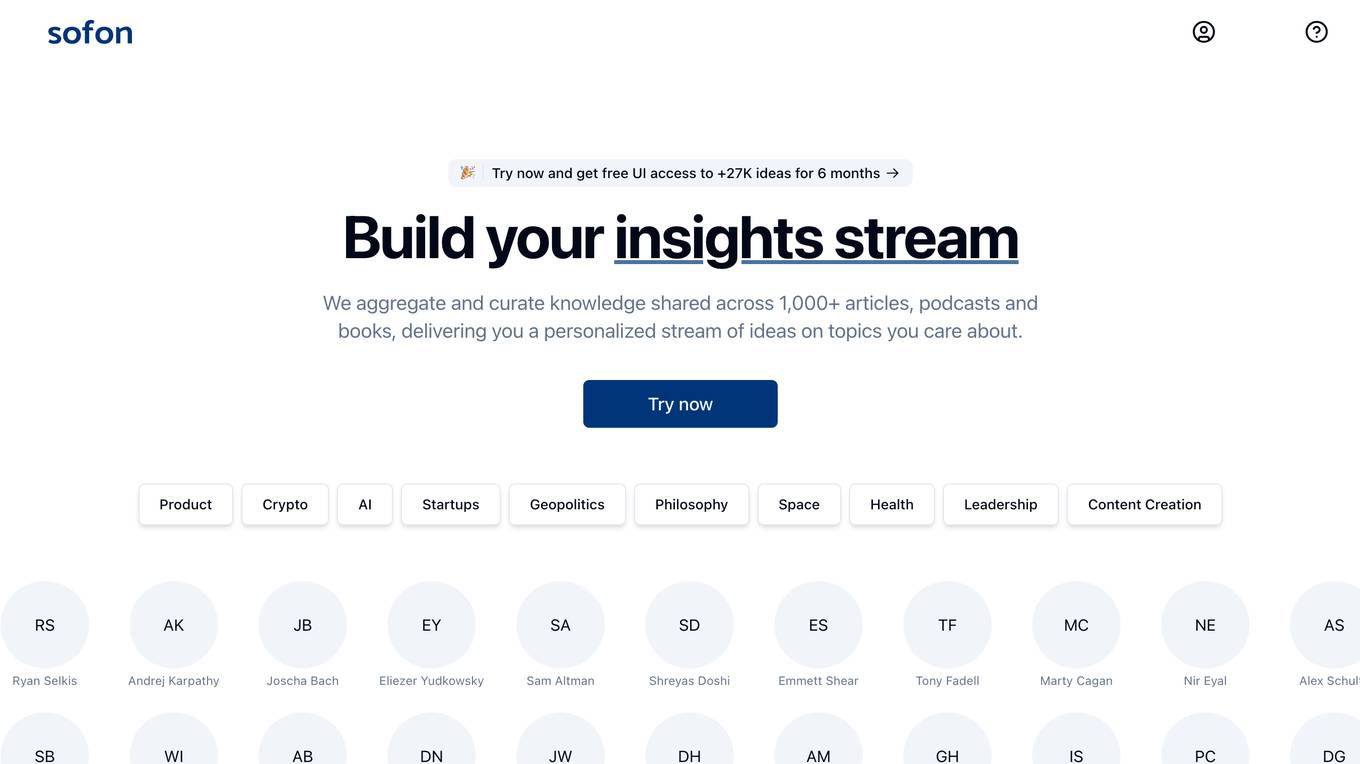
Sofon
Sofon is a knowledge aggregation and curation platform that provides users with personalized insights on topics they care about. It aggregates and curates knowledge shared across 1,000+ articles, podcasts, and books, delivering a personalized stream of ideas to users. Sofon uses AI to compare ideas across hundreds of people on any question, saving users thousands of hours of curation. Users can indicate the people they want to learn from, and Sofon will curate insights across all their knowledge. Users can receive an idealetter, which is a unique combination of ideas across all the people they've selected around a common theme, delivered at an interval of their choice.
Product Discovery & Comparison Platform
The website is a platform that allows users to discover and compare various products across different categories such as cars, phones, laptops, TVs, smartwatches, and more. Users can easily find information on high-end, mid-tier, and low-cost options for each product category, enabling them to make informed purchasing decisions. The site aims to simplify the process of product research and comparison for consumers looking to buy different items.
1 - Open Source AI Tools

can-ai-code
Can AI Code is a self-evaluating interview tool for AI coding models. It includes interview questions written by humans and tests taken by AI, inference scripts for common API providers and CUDA-enabled quantization runtimes, a Docker-based sandbox environment for validating untrusted Python and NodeJS code, and the ability to evaluate the impact of prompting techniques and sampling parameters on large language model (LLM) coding performance. Users can also assess LLM coding performance degradation due to quantization. The tool provides test suites for evaluating LLM coding performance, a webapp for exploring results, and comparison scripts for evaluations. It supports multiple interviewers for API and CUDA runtimes, with detailed instructions on running the tool in different environments. The repository structure includes folders for interviews, prompts, parameters, evaluation scripts, comparison scripts, and more.
20 - OpenAI Gpts


EduCheck
Automatically evaluates uploaded lesson plans against educational standards. Upload text or a PDF.
Software Comparison
I compare different software, providing detailed, balanced information.


Best Spy Apps for Android (Q&A)
FREE tool to compare best spy apps for Android. Get answers to your questions and explore features, pricing, pros and cons of each spy app.

GPTValue
Compare similar GPTs outputs quality on the same question, identify the most valuable one.
TV Comparison | Comprehensive TV Database
Compare TV Devices Uncover the pros and cons of different latest TV models.
PerspectiveBot
Provide TOPIC & different views to compare: Gateway to Informed Comparisons. Harness AI-powered insights to analyze and score different viewpoints on any topic, delivering balanced, data-driven perspectives for smarter decision-making.
Calorie Count & Cut Cost: Food Data
Apples vs. Oranges? Optimize your low-calorie diet. Compare food items. Get tailored advice on satiating, nutritious, cost-effective food choices based on 240 items.
Best price kuwait
A customized GPT model for price comparison would search and compare product prices on websites in Kuwait, tailored to local markets and languages.
Website Conversion by B12
I'll help you optimize your website for more conversions, and compare your site's CRO potential to competitors’.
Course Finder
Find the perfect online course in tech, business, marketing, programming, and more. Compare options from top platforms like Udemy, Coursera, and EDX.
AI Hub
Your Gateway to AI Discovery – Ask, Compare, Learn. Explore AI tools and software with ease. Create AI Tech Stacks for your business and much more – Just ask, and AI Hub will do the rest!

🔵 GPT Boosted
GPT- 5 ? | Enhanced version of GPT-4 Turbo, don't believe, try and compare! | ver .001
