Best AI tools for< Clone Voice >
10 - AI tool Sites
Translate.Video
Translate.Video is an AI multi-speaker video translation tool that offers speaker diarization, voice cloning, text-to-speech, and instant voice cloning features. It allows users to translate videos to over 75 languages with just one click, making content creation and translation efficient and accessible. The tool also provides plugins for popular design software like Photoshop, Illustrator, and Figma, enabling users to accelerate creative translation. Translate.Video is designed to help creators, influencers, and enterprises reach a global audience by simplifying the captioning, subtitling, and dubbing process.
Fineshare
Fineshare is an online AI audio creator tool that offers a wide range of features for voice, music, and sound generation. Users can transform their voice, create AI covers, generate audio from videos, transcribe audio to text, and more. The tool provides advanced AI technology to simplify audio creation and unlock creativity. Fineshare is trusted by over 10 million customers worldwide and offers personalized AI voice and professional-grade video voiceover capabilities.
Voicemy.ai
Voicemy.ai is an AI application that allows users to create AI voices and songs. Users can clone voices of famous personalities, compose melodies, and convert text into spoken words using chosen voice models. The platform aims to inspire creativity and enable users to share their passion with the world.
Invideo AI
Invideo AI is an AI video creator tool that allows users to easily turn their ideas into videos using pre-made templates. With features like text prompts, voiceover, subtitles, and music, users can create publish-ready videos without any video creation skills. The tool offers the ability to generate videos in multiple languages, clone voice with AI, and collaborate in real-time with multiplayer editing. Invideo AI aims to provide a complete video solution for individuals and businesses to create engaging video content effortlessly.

Voice.ai
Voice.ai is a free real-time voice changer and the largest ecosystem of free AI voice tools. With Voice.ai, you can change your voice in real-time, clone voices, create soundboards, and more. Voice.ai is perfect for streamers, content creators, gamers, and anyone who wants to have fun with their voice.
ToneShift
ToneShift is an AI-powered platform that allows users to clone voices, separate music, and join a community of voices. With ToneShift, users can transform recordings into versatile voices for various purposes, separate vocals and instrumentals from songs to create new remixes and mashups, and join a community to discover new tones, contribute their creations, and collaborate with others.
VideoDubber
VideoDubber is an AI-powered video translation and text-to-speech tool that offers premium video translation with voice cloning at a fraction of the market price. It enables users to make their videos speak in the language of their audience's choice using Generative AI. The platform supports translation to over 150 languages and accents, providing features like voice cloning, subtitles modification, and dubbing minutes. VideoDubber caters to a wide range of users, including Youtubers, businesses, and content creators, helping them reach a global audience and enhance viewer engagement through multilingual content.
Speax AI
Speax AI is a cutting-edge AI technology company that specializes in revolutionizing dubbing processes. The platform offers instant and accurate translations in over 29 languages, allowing users to upload videos and receive perfectly dubbed content in minutes. With advanced AI capabilities, Speax AI ensures seamless voice synchronization and cultural accuracy at affordable rates, making it easy for users to connect with global audiences effortlessly. Additionally, the platform provides smart translation and paraphrasing algorithms for elevated content precision, as well as voice cloning features for multilingual voice replication. Speax AI also offers background music and sound effects to enhance video content, all while maintaining the highest quality standards at competitive prices.
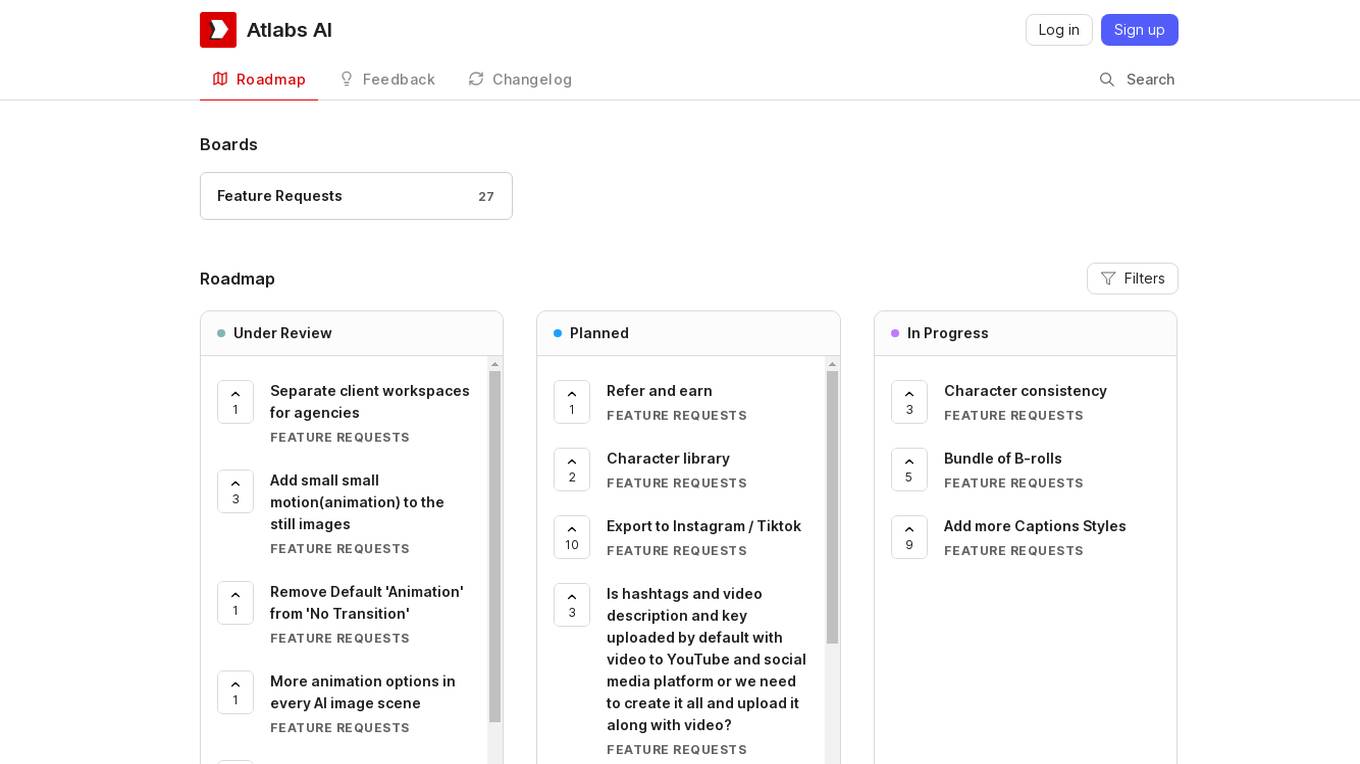
Atlabs AI
Atlabs AI is an innovative AI application that offers a range of features to enhance image and video editing processes. Users can create captivating animations, customize transitions, and access a diverse character library. The tool simplifies social media content creation by providing options to export directly to platforms like Instagram and TikTok. With advanced capabilities such as voice cloning and character consistency, Atlabs AI empowers users to produce professional-quality multimedia content effortlessly.
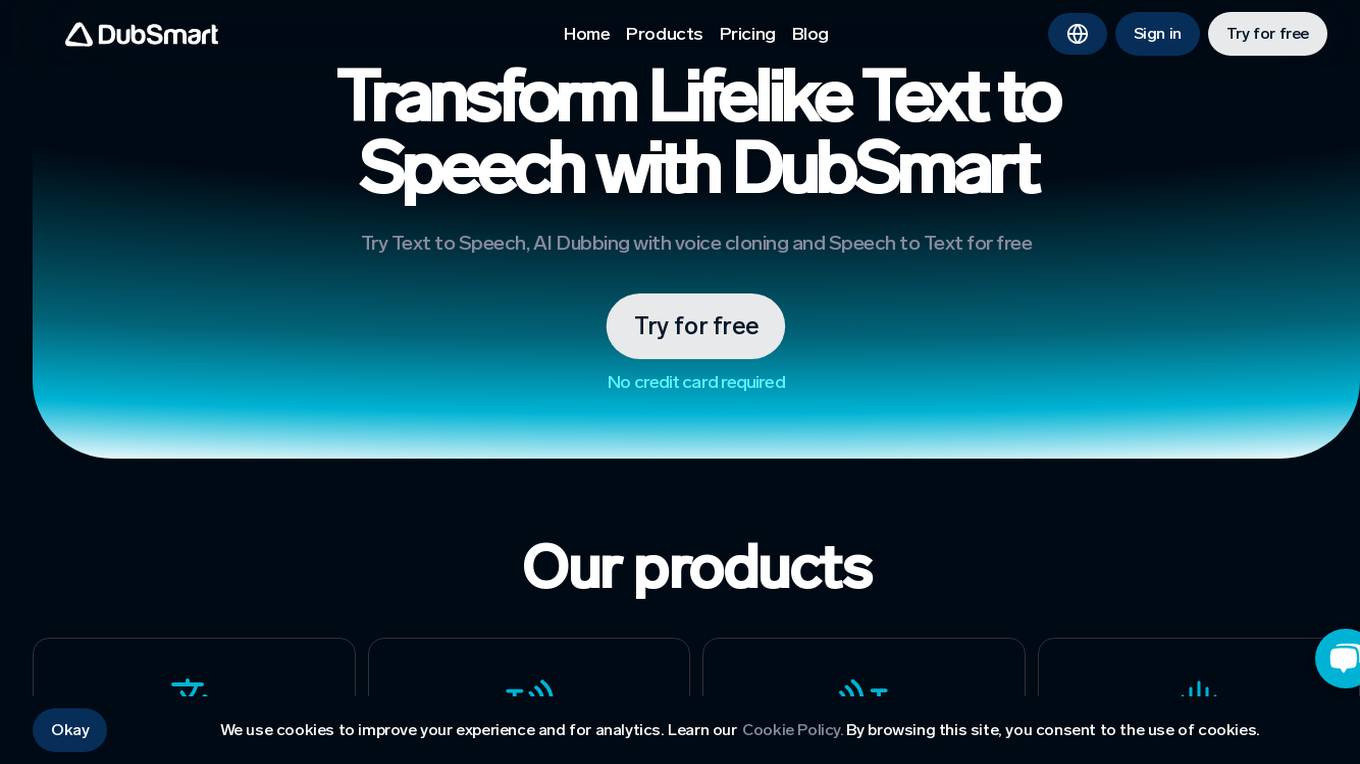
DubSmart
DubSmart is an AI-powered platform that offers advanced video dubbing and voice cloning services. It allows users to transform text into lifelike speech, dub videos with voice cloning technology, and generate subtitles for audio or video content. With a user-friendly interface, DubSmart enables users to create unique voices, edit projects, and download finished projects in various formats. The platform supports 33 languages for AI dubbing and 60+ languages for speech-to-text conversion. DubSmart caters to small creators, YouTubers, and companies looking to enhance their audiovisual content with personalized voices and multilingual capabilities.
2 - Open Source AI Tools

Applio
Applio is a VITS-based Voice Conversion tool focused on simplicity, quality, and performance. It features a user-friendly interface, cross-platform compatibility, and a range of customization options. Applio is suitable for various tasks such as voice cloning, voice conversion, and audio editing. Its key features include a modular codebase, hop length implementation, translations in over 30 languages, optimized requirements, streamlined installation, hybrid F0 estimation, easy-to-use UI, optimized code and dependencies, plugin system, overtraining detector, model search, enhancements in pretrained models, voice blender, accessibility improvements, new F0 extraction methods, output format selection, hashing system, model download system, TTS enhancements, split audio, Discord presence, Flask integration, and support tab.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
20 - OpenAI Gpts

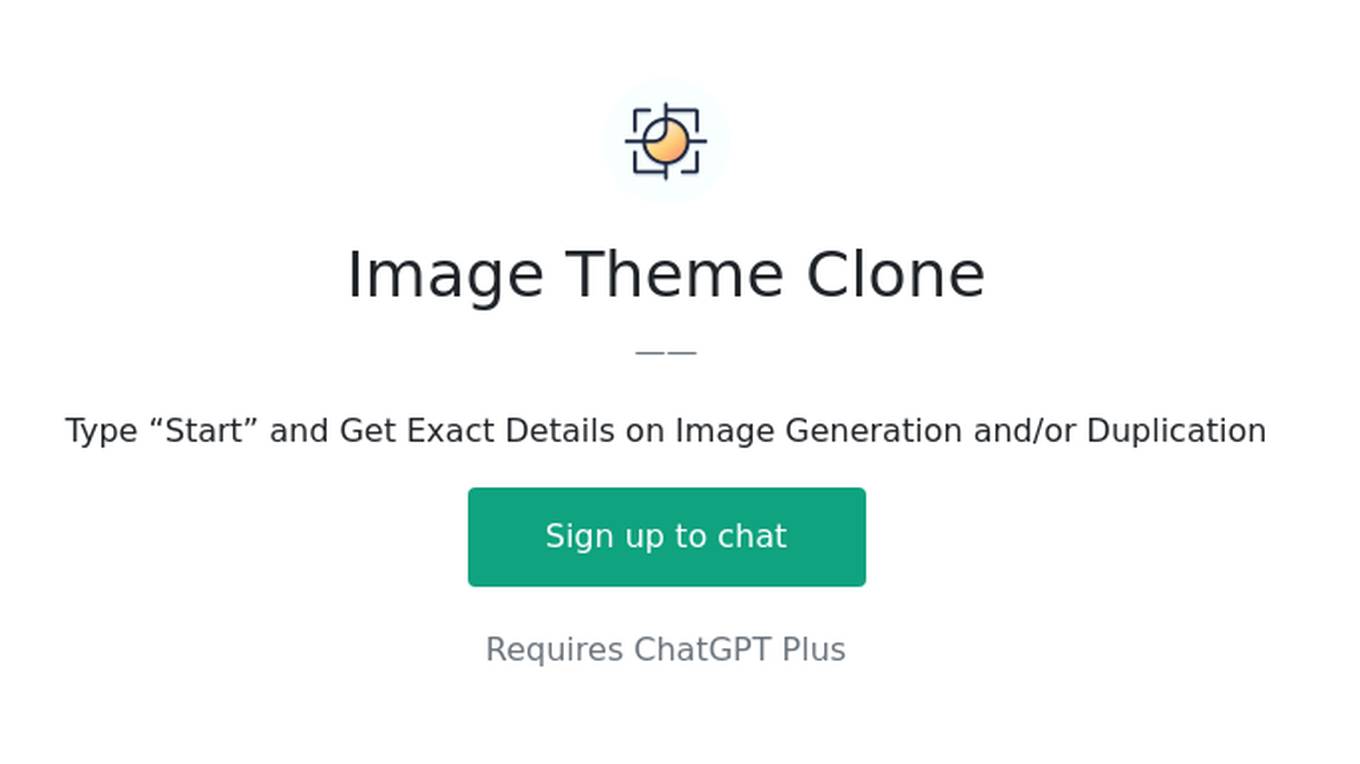
Image Theme Clone
Type “Start” and Get Exact Details on Image Generation and/or Duplication
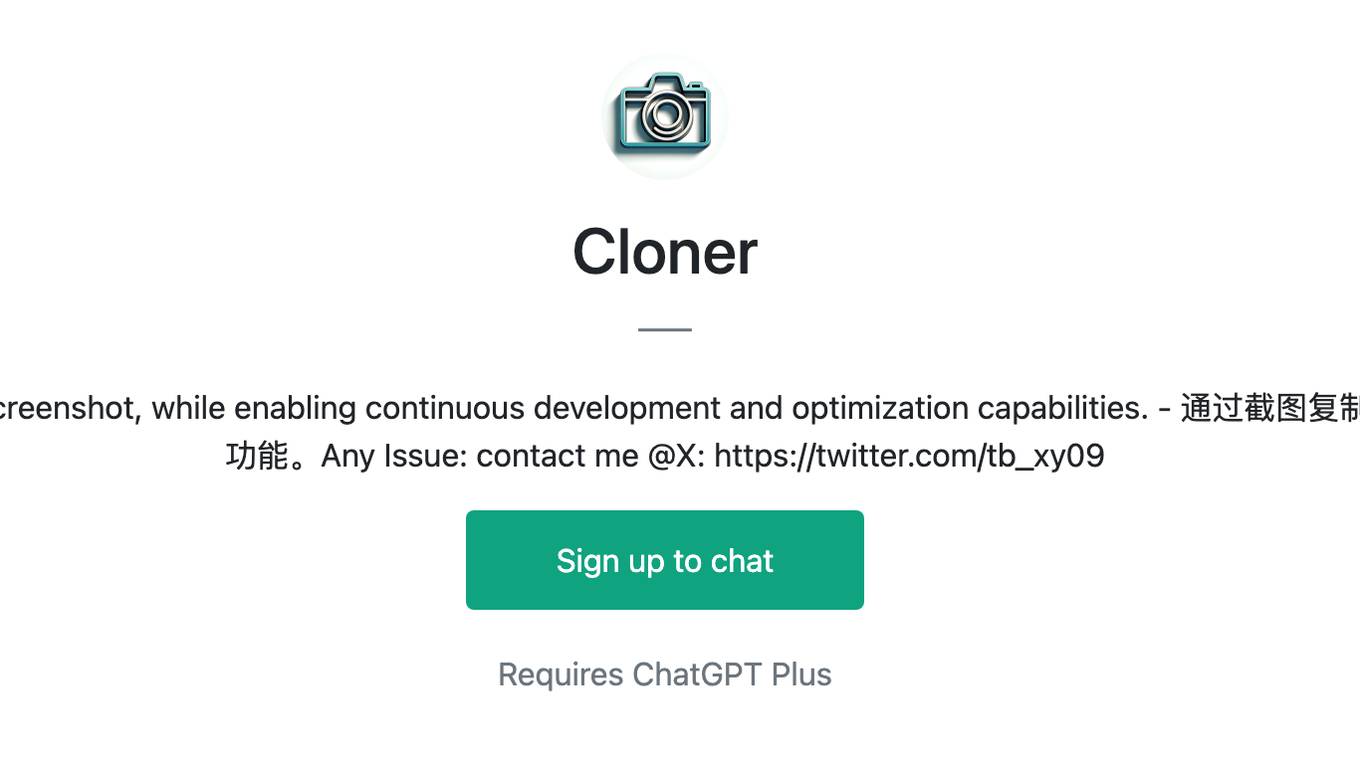
Cloner
Clone and replicate the source site using a screenshot, while enabling continuous development and optimization capabilities. - 通过截图复制源站点前端代码,同时具备持续开发和优化功能。Any Issue: contact me @X: https://twitter.com/tb_xy09

Style Cloner GPT
Imitates a specific individual's style and opinions accurately and ethically.


REPO MASTER
Expert at fetching repository information from GitHub, Hugging Face. and you local repositories
Image cloner
From an attached image, the bot will generate a prompt to replicate the image in a digital art bot such as Midjourney or DALL-E
Cosmic Contact
Expert on extraterrestrial abductions and close encounters, with a verification process for accuracy.

Solar Pro Advisor
Your guide in solar sales mastery, offering in-depth resources for handling objections and effective marketing strategies. Over 7 Years of Proprietary data and a Knowledge Base from within the Solar Industry with battle Tested Ads and Real Training.
Master of Power Negotiating
Negotiation assistant based on Roger Dawson's strategies. You will never make money faster than when you are negotiating!