Best AI tools for< Caption Audio >
20 - AI tool Sites
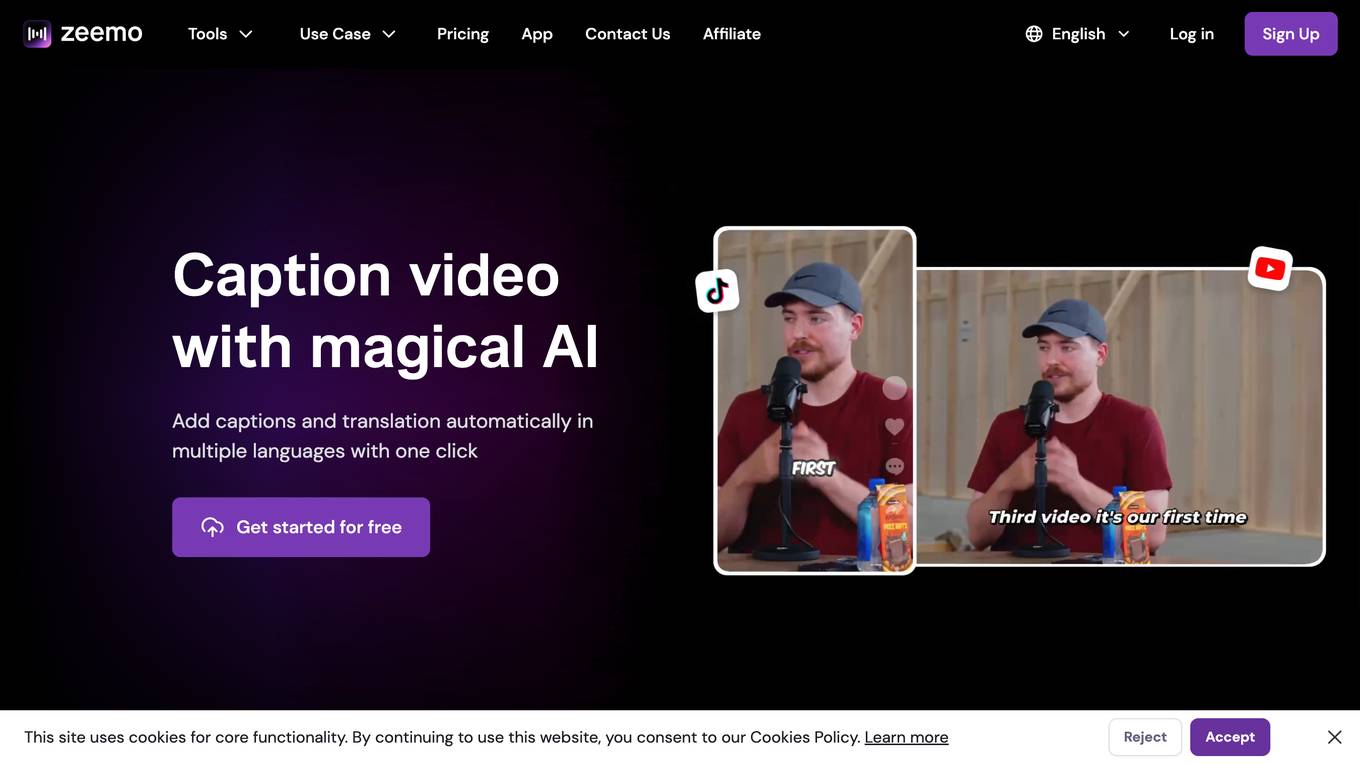
Zeemo AI
Zeemo AI is a powerful caption generator tool that enables users to add subtitles to videos, transcribe video and audio to text, and generate captions using AI technology. It supports multiple languages and provides dynamic visual effects for captions. The tool is designed for content creators, educators, and product sellers to enhance their videos and reach a wider audience across various platforms.
Verbit
Verbit is an AI transcription and captioning tool that utilizes advanced artificial intelligence technology to convert audio and video files into accurate text. The platform offers high-quality transcription services for various industries, including legal, media, education, and more. Verbit's AI algorithms ensure fast and precise transcriptions, saving time and effort for users. With a user-friendly interface and customizable features, Verbit is a reliable solution for all transcription needs.
AirCaption
AirCaption is an AI-powered speech to text transcription tool that enables users to transcribe audio and video content quickly and efficiently. It offers the ability to generate AI captions, review and edit them, and export caption files in up to 60 languages. The application works offline, ensuring privacy by keeping media and captions on the user's computer. AirCaption is suitable for various professionals such as video editors, podcasters, language learners, legal professionals, marketers, researchers, event organizers, online course creators, and journalists.
Maestra AI
Maestra AI is an advanced platform offering transcription, subtitling, and voiceover tools powered by artificial intelligence technology. It allows users to automatically transcribe audio and video files, generate subtitles in multiple languages, and create voiceovers with diverse AI-generated voices. Maestra's services are designed to help users save time and easily reach a global audience by providing accurate and efficient transcription, captioning, and voiceover solutions.
Vatis Tech
Vatis Tech is an AI-powered speech-to-text infrastructure that offers transcription software to help teams and individuals streamline their workflow. The platform provides accurate, accessible, and affordable speech-to-text API, caption generator, and audio intelligence solutions. It caters to various industries such as contact centers, broadcasting, medical, legal, media, newsrooms, and more. Vatis Tech's technology is powered by state-of-the-art AI, enabling near-human accuracy in transcribing speech with fast turnaround times. The platform also offers features like real-time transcription, custom AI models, and support for multiple languages.
Wordly AI Translation
Wordly AI Translation is a leading AI application that specializes in providing live translation and captioning services for meetings and events. With over 3 million users across 60+ countries, Wordly offers a comprehensive solution to make events more inclusive, language accessible, and engaging. The platform supports two-way translation for 50+ languages in various event formats, including in-person, virtual, webinar, and video. Wordly ensures high-quality translation output through extensive language testing and optimization, along with powerful glossary tools. The application also prioritizes security and privacy, meeting SOC 2 Type II compliance requirements. Wordly's AI translation technology has been recognized for its speed, ease of use, and affordability, making it a trusted choice for event organizers worldwide.
Whisper API
Whisper API is an affordable transcription API that can be used to transcribe audio and video files. It is a cloud-based service that is easy to use and can be integrated with a variety of applications. Whisper API is powered by artificial intelligence, which allows it to transcribe audio and video files with high accuracy.
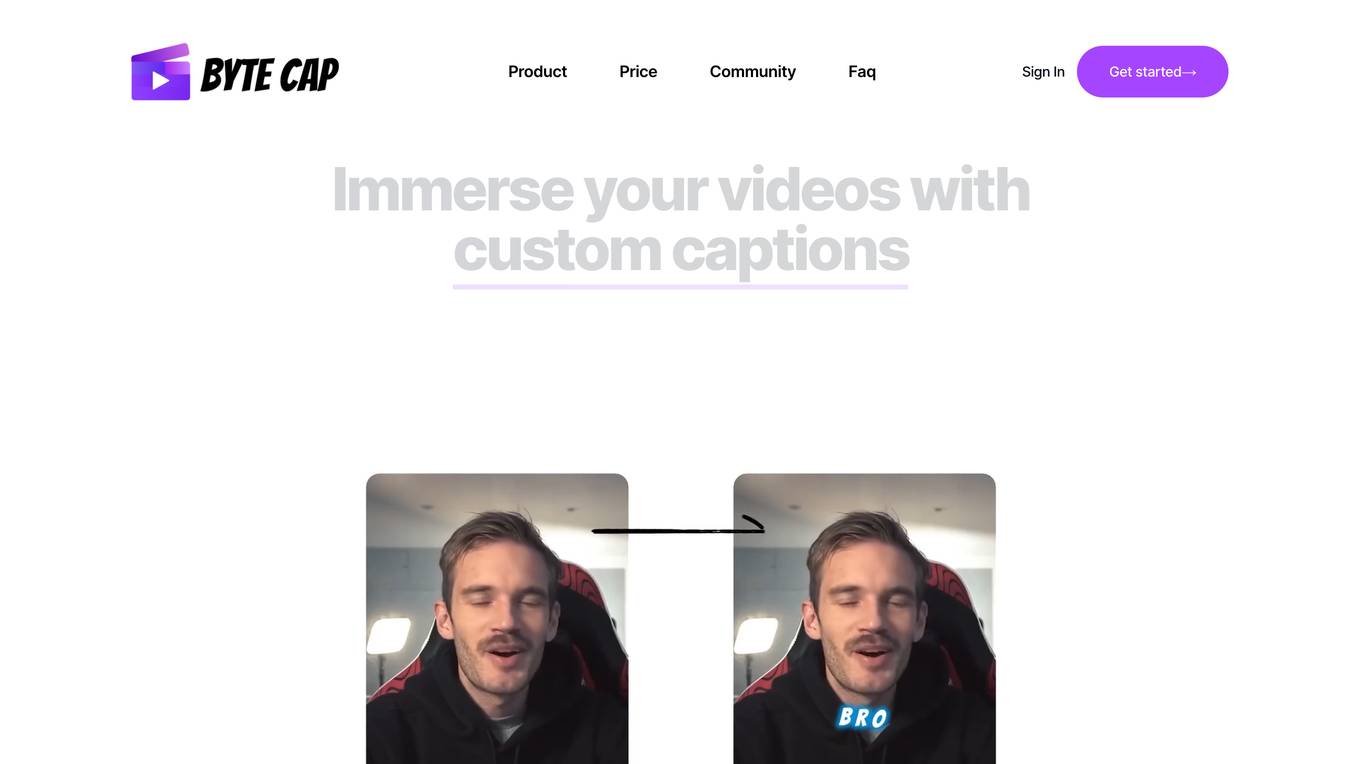
ByteCap
ByteCap is an AI-powered video editing tool that allows users to create engaging and captivating videos with custom AI captions. With advanced speech recognition technology, users can auto-create accurate captions in multiple languages. The tool also enables the creation of stunning faceless videos by incorporating AI images, voice, and captions. Users can personalize their videos with custom captions, images, emojis, effects, music, and highlights. ByteCap offers a range of features such as customizable AI faceless videos, support for various caption formats, trendy sounds, background music, and expertly crafted caption themes. It is a versatile solution for video editors, content creators, podcasters, and streamers to enhance their video content and reach a wider audience.
Verbit
Verbit is an AI-based transcription and captioning service that provides unmatched accuracy with actionable insights. It offers services such as live and recorded captioning, transcription, audio description, translation, note-taking, and dubbing. Verbit caters to various industries including media & entertainment, legal, education, corporate & market research, and government. The platform leverages AI technologies like Automatic Speech Recognition engine (Captivate™) and Generative AI technology (Gen.V™) to provide real-time insights and seamless integration into existing workflows. Verbit aims to make speech-to-text conversion more accessible and productive for its users.
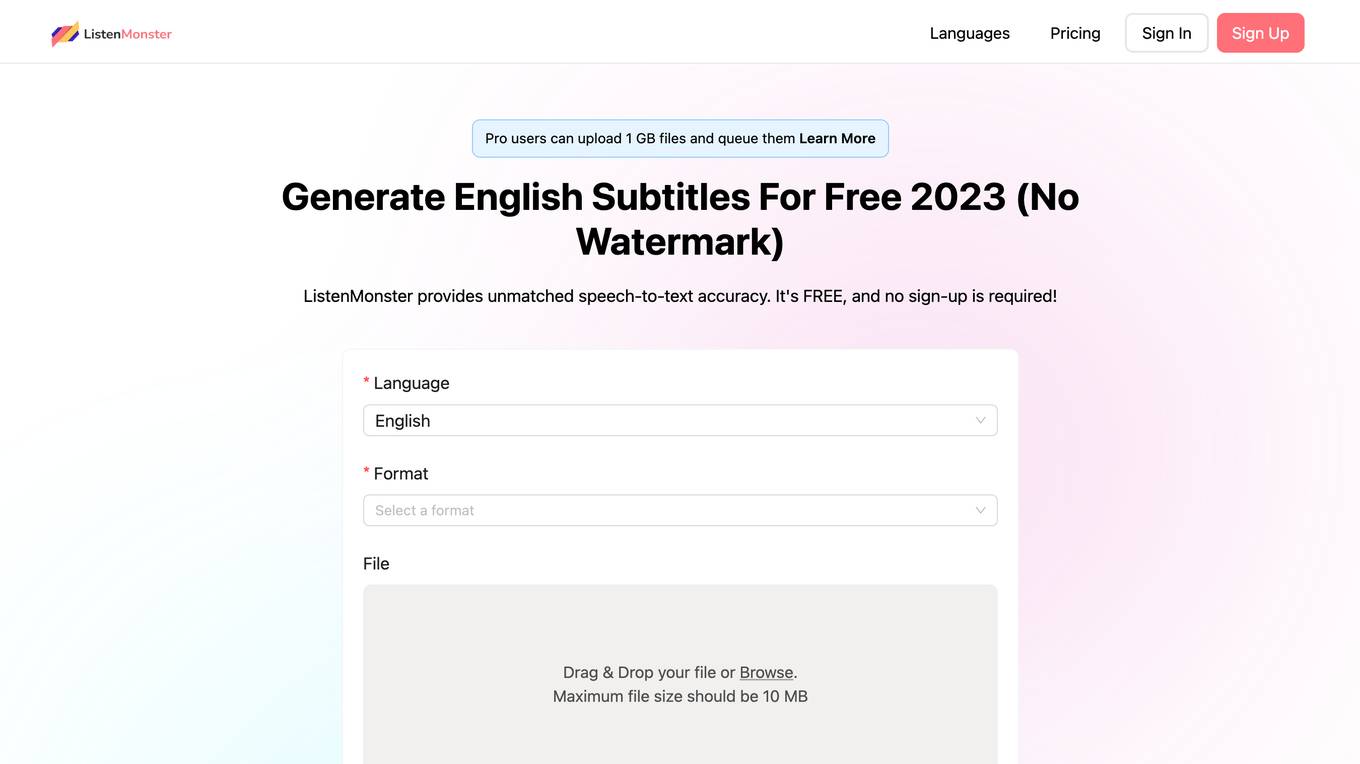
ListenMonster
ListenMonster is a free video caption generator tool that provides unmatched speech-to-text accuracy. It allows users to generate automatic subtitles in multiple languages, customize video captions, remove background noise, and export results in various formats. ListenMonster aims to offer high accuracy transcription at affordable prices, with instant results and support for 99 languages. The tool features a smart editor for easy customization, flexible export options, and automatic language detection. Subtitles are emphasized as a necessity in today's world, offering benefits such as global reach, SEO boost, accessibility, and content repurposing.
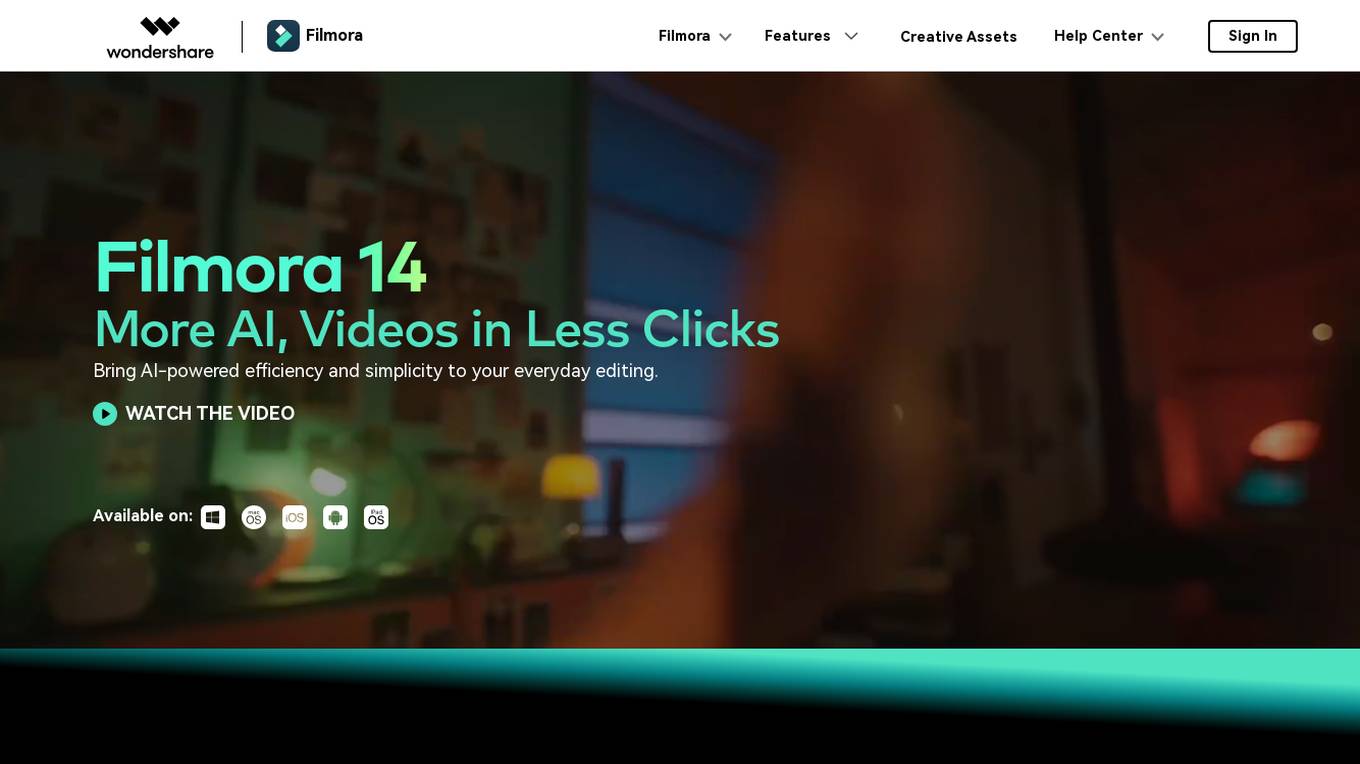
Wondershare Filmora
Wondershare Filmora is an AI-powered video editing software that offers a wide range of features to simplify the video editing process. It provides AI-driven tools for editing, audio enhancement, effects, color correction, and more. With features like AI Text-To-Video, AI Thumbnail Maker, and AI Music Generator, Filmora aims to enhance efficiency and creativity in video editing. The application caters to both beginners and experts, offering a user-friendly interface and advanced editing capabilities. Filmora stands out for its simplicity, affordability, and extensive collection of effects and templates, making it a popular choice among content creators and professionals.
Deepgram
Deepgram is a speech recognition and transcription service that uses artificial intelligence to convert audio into text. It is designed to be accurate, fast, and easy to use. Deepgram offers a variety of features, including: - Automatic speech recognition - Speaker diarization - Language identification - Custom acoustic models - Real-time transcription - Batch transcription - Webhooks - Integrations with popular platforms such as Zoom, Google Meet, and Microsoft Teams
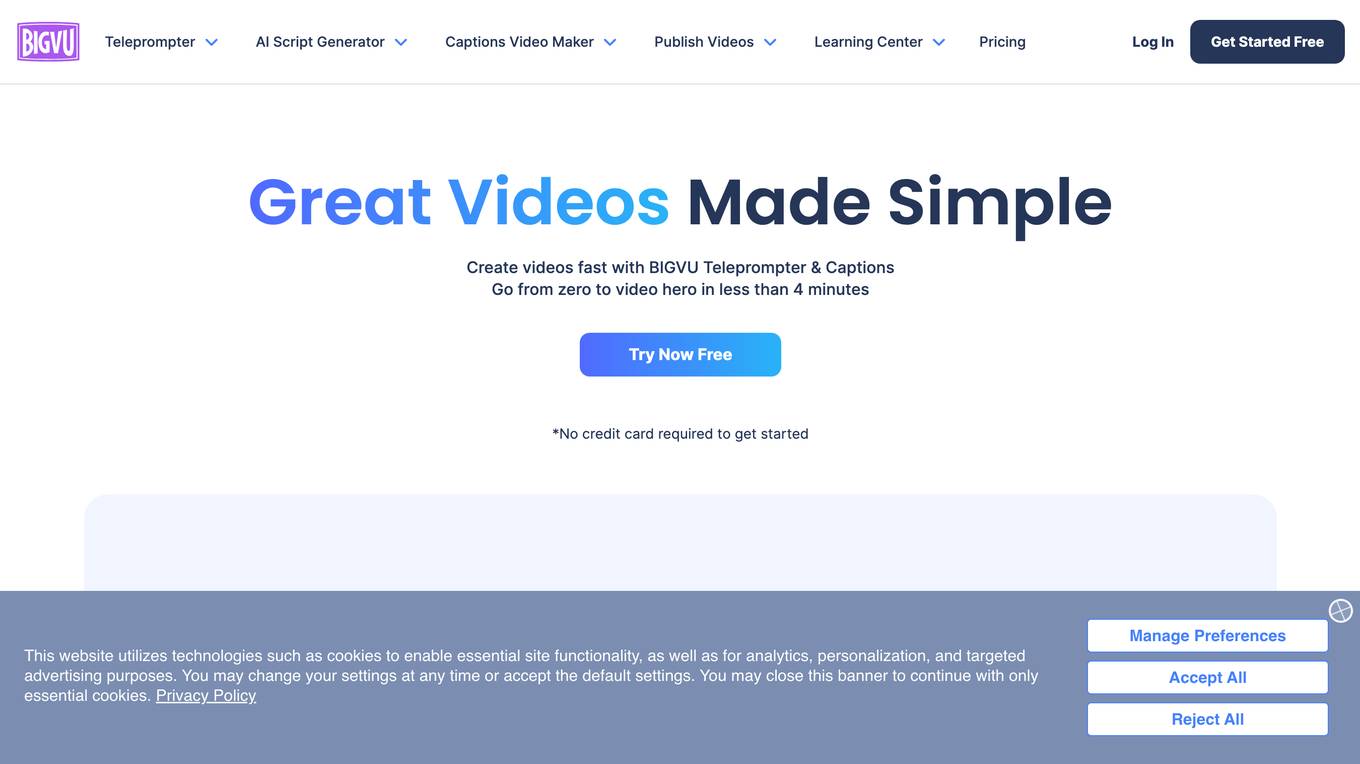
BIGVU
BIGVU is a comprehensive video creation platform that offers a wide range of AI-powered tools to help users create professional-looking videos quickly and easily. With BIGVU, users can create engaging video scripts, use a teleprompter with beauty filters, add captions and edit videos, and automate posting to social media accounts. BIGVU is designed to be user-friendly and accessible to users of all skill levels, making it an ideal tool for businesses, marketers, educators, and anyone looking to create high-quality videos.
Verbit Go
Verbit Go is an AI-powered transcription and captioning platform that automates the process of converting audio and video files into text. It utilizes advanced speech recognition technology to provide accurate and efficient transcriptions, making it ideal for professionals in various industries such as legal, media, education, and more. Verbit Go offers a user-friendly interface, customizable settings, and secure cloud storage for easy access to transcribed content. With its AI capabilities, Verbit Go significantly reduces the time and effort required for transcription tasks, improving productivity and workflow efficiency.
DreamShorts
DreamShorts is an AI-powered toolkit for video and audio content creation. It offers a range of features to help users create original, unique, copyright-free scripts and video content. These features include a script generator, video content generator, AI narrator, social media integrations, and auto-captioning. DreamShorts is designed to be easy to use and affordable, making it a great option for content creators of all levels.
Robo Translator
Robo Translator is an AI-powered translation tool that enables users to easily localize their content into multiple languages. With the latest OpenAI models and Azure-powered text-to-speech technology, it offers accurate translation, audio transcription, and closed caption localization services. Users can translate audio, video, and text documents, auto-translate YouTube video captions, and localize software files effortlessly. The tool provides encrypted file uploads for enhanced privacy and offers a pay-as-you-go pricing model. Robo Translator simplifies the localization process, making content more accessible to a global audience.
Edit-Videos-Online.com
Edit-Videos-Online.com is a free online video editor that allows users to edit and create videos without the need for registration or software installation. It supports a wide range of popular video formats and offers a variety of features such as video trimming, background removal, automatic caption generation, text and image addition, and audio editing. The editor is easy to use and provides a seamless video editing experience for both novices and experts.
Scribewave
Scribewave is an AI-powered online transcription tool that allows users to automatically transcribe audio and video files into text. It supports over 90 languages and dialects, offers accurate transcription with speaker recognition, and provides features like subtitles generation, audio-to-video conversion, and translations to multiple languages. Scribewave is designed to simplify content conversion, saving users time and enabling them to focus on more critical tasks.
AI Instagram Caption Generator
The FREE AI Instagram Caption Generator Tool is a user-friendly application that helps users create captivating captions for their Instagram posts. Powered by the latest AI technology, this tool allows users to enhance their social media presence with just one click. Users can choose from various writing styles, call-to-action options, and caption lengths to tailor their messages for maximum impact. The tool generates creative and engaging captions, eliminating writer's block and providing endless inspiration. It is perfect for individuals and businesses looking to create compelling captions that resonate with their audience.
Bytecap
Bytecap is an AI application that allows users to immerse their videos with custom AI captions. It offers features such as auto creation of 99% accurate captions using advanced speech recognition, customization of captions with fonts, colors, emojis, effects, music, and highlights, and AI-generated hook titles and descriptions for boosting engagement. Bytecap supports over 99 languages, provides complete caption control, and offers trendy sounds and background music options. The application caters to video editors, content creators, podcasters, and streamers, enabling them to save time, expand reach, and increase brand awareness. Bytecap ensures privacy and security, offers free trial options, and allows users to edit captions after creation.
1 - Open Source AI Tools
videokit
VideoKit is a full-featured user-generated content solution for Unity Engine, enabling video recording, camera streaming, microphone streaming, social sharing, and conversational interfaces. It is cross-platform, with C# source code available for inspection. Users can share media, save to camera roll, pick from camera roll, stream camera preview, record videos, remove background, caption audio, and convert text commands. VideoKit requires Unity 2022.3+ and supports Android, iOS, macOS, Windows, and WebGL platforms.
20 - OpenAI Gpts
【インスタグラム特化】投稿自動作成ツール
投稿ジャンルと対象者を入力するだけでインスタグラムの投稿を自動で作成してくれます。投稿ネタが思いつかない・時間がないというときに活用してみて下さい。

www.captiongenerator.com
Free AI TikTok Caption Generator - Generates catchy TikTok captions from video scripts
Afbeeldingen preppen voor web
TOOL die je een ALT-tekst, caption, titel en description in het Nederlands geeft. Handig voor in je HTML of pagebuilder. VOEG GEWOON JE AFBEELDINGEN TOE

OneWord GPT
SuccintBot delivers concise one-word answers, offering a unique twist on language model interactions with brevity at its core.

MELODICA
Give me an image or idea and I will create captions designed for generate images with 'Sable Diffusion'.