Best AI tools for< Benchmark On Datasets >
20 - AI tool Sites
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.
AI Alliance
The AI Alliance is a community dedicated to building and advancing open-source AI agents, data, models, evaluation, safety, applications, and advocacy to ensure everyone can benefit. They focus on various areas such as skills and education, trust and safety, applications and tools, hardware enablement, foundation models, and advocacy. The organization supports global AI skill-building, education, and exploratory research, creates benchmarks and tools for safe generative AI, builds capable tools for AI model builders and developers, fosters AI hardware accelerator ecosystem, enables open foundation models and datasets, and advocates for regulatory policies for healthy AI ecosystems.
INOP
INOP is an impact-driven professional network that uses advanced AI matching algorithms to connect professionals with like-minded individuals, job opportunities, and companies that share their values and interests. The platform offers personalized job alerts, geolocation features, and actionable compensation insights. INOP goes beyond traditional networking platforms by providing rich enterprise-level insights on company culture, values, reputation, and ESG data sets. Users can access salary benchmarks, career path insights, and skills benchmarking to make informed career decisions.
Am I On AI
Am I On AI is a platform designed to help businesses improve their visibility in AI responses, specifically focusing on ChatGPT. It provides personalized action plans to enhance brand visibility, track mentions, identify source websites, benchmark against competitors, and execute strategic improvements. The platform offers features such as AI brand monitoring, competitor rank analysis, sentiment analysis, citation tracking, and actionable insights. With a user-friendly interface and measurable results, Am I On AI is a valuable tool for marketers, SEO professionals, and agencies looking to optimize their AI visibility.
ADSoar
ADSoar is a powerful AI-driven Google Ads spy tool that provides official data and AI scoring to help advertisers spy on competitors, scale ads, and win bigger. It offers industry-first waterfall charts to track competitor expansion across 50+ countries, 6-point AI scoring to identify winning ads, and features like ad intelligence, global expansion tracking, audience targeting analysis, and ad performance benchmarking. ADSoar aims to solve specific challenges faced by advertisers by providing real features and insights, not empty promises.
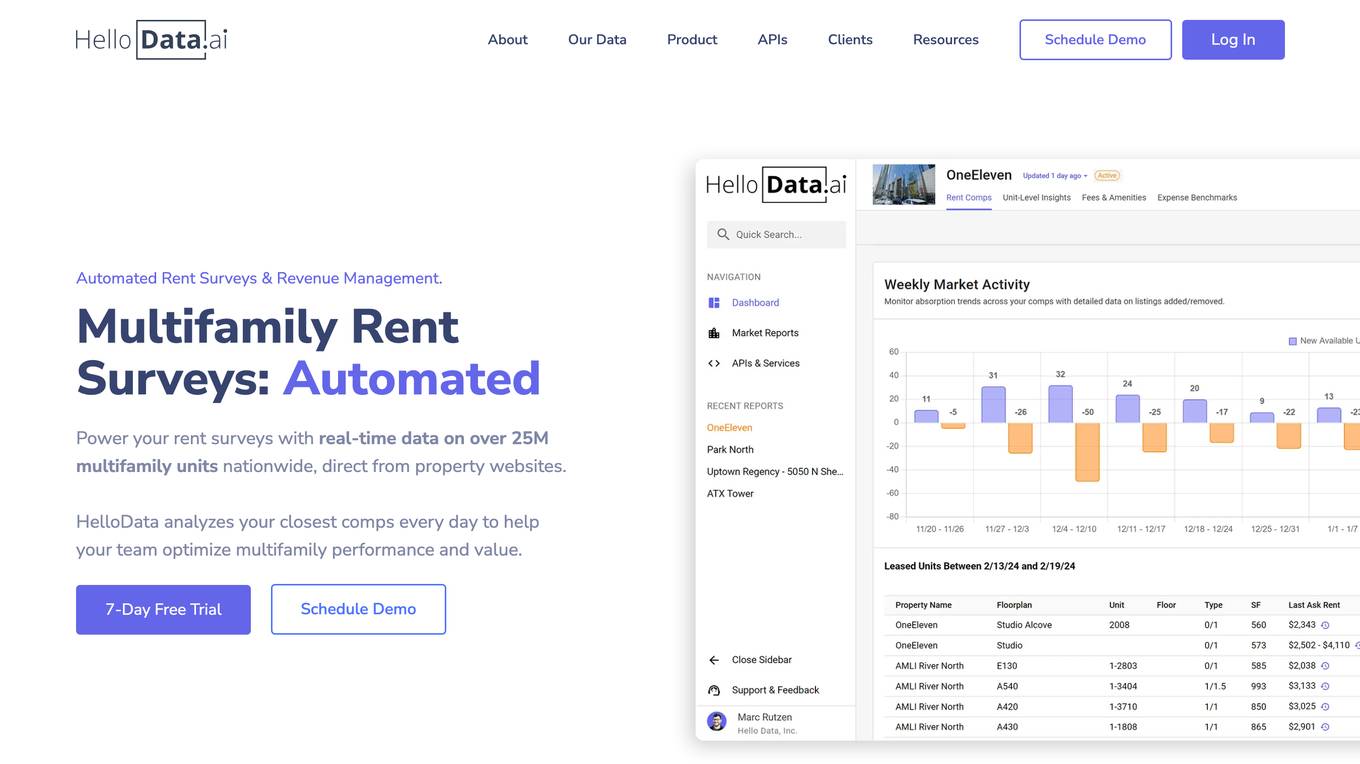
HelloData
HelloData is an AI-powered multifamily market analysis platform that automates market surveys, unit-level rent analysis, concessions monitoring, and development feasibility reports. It provides financial analysis tools to underwrite multifamily deals quickly and accurately. With custom query builders and Proptech APIs, users can analyze and download market data in bulk. HelloData is used by over 15,000 multifamily professionals to save time on market research and deal analysis, offering real-time property data and insights for operators, developers, investors, brokers, and Proptech companies.

Report Card AI
Report Card AI is an AI Writing Assistant that helps users generate high-quality, unique, and personalized report card comments. It allows users to create a quality benchmark by writing their first draft of comments with the assistance of AI technology. The tool is designed to streamline the report card writing process for teachers, ensuring error-free and eloquently written comments that meet specific character count requirements. With features like 'rephrase', 'Max Character Count', and easy exporting options, Report Card AI aims to enhance efficiency and accuracy in creating report card comments.
Clarity AI
Clarity AI is an AI-powered technology platform that offers a Sustainability Tech Kit for sustainable investing, shopping, reporting, and benchmarking. The platform provides built-in sustainability technology with customizable solutions for various needs related to data, methodologies, and tools. It seamlessly integrates into workflows, offering scalable and flexible end-to-end SaaS tools to address sustainability use cases. Clarity AI leverages powerful AI and machine learning to analyze vast amounts of data points, ensuring reliable and transparent data coverage. The platform is designed to empower users to assess, analyze, and report on sustainability aspects efficiently and confidently.
Comparables.ai
Comparables.ai is an AI-powered company and market intelligence platform designed for M&A professionals. It offers comprehensive data insights, valuation multiples, and market analysis to help users make informed decisions in investment banking, private equity, and corporate finance. The platform leverages AI technology to provide relevant company information, financial data, and M&A transaction history, enabling users to identify new investment targets, benchmark companies, and conduct market analysis efficiently.
ARC Prize
ARC Prize is a platform hosting a $1,000,000+ public competition aimed at beating and open-sourcing a solution to the ARC-AGI benchmark. The platform is dedicated to advancing open artificial general intelligence (AGI) for the public benefit. It provides a formal benchmark, ARC-AGI, created by François Chollet, to measure progress towards AGI by testing the ability to efficiently acquire new skills and solve open-ended problems. ARC Prize encourages participants to try solving test puzzles to identify patterns and improve their AGI skills.
Groq
Groq is a fast AI inference tool that offers GroqCloud™ Platform and GroqRack™ Cluster for developers to build and deploy AI models with ultra-low-latency inference. It provides instant intelligence for openly-available models like Llama 3.1 and is known for its speed and compatibility with other AI providers. Groq powers leading openly-available AI models and has gained recognition in the AI chip industry. The tool has received significant funding and valuation, positioning itself as a strong challenger to established players like Nvidia.
Junbi.ai
Junbi.ai is an AI-powered insights platform designed for YouTube advertisers. It offers AI-powered creative insights for YouTube ads, allowing users to benchmark their ads, predict performance, and test quickly and easily with fully AI-powered technology. The platform also includes expoze.io API for attention prediction on images or videos, with scientifically valid results and developer-friendly features for easy integration into software applications.
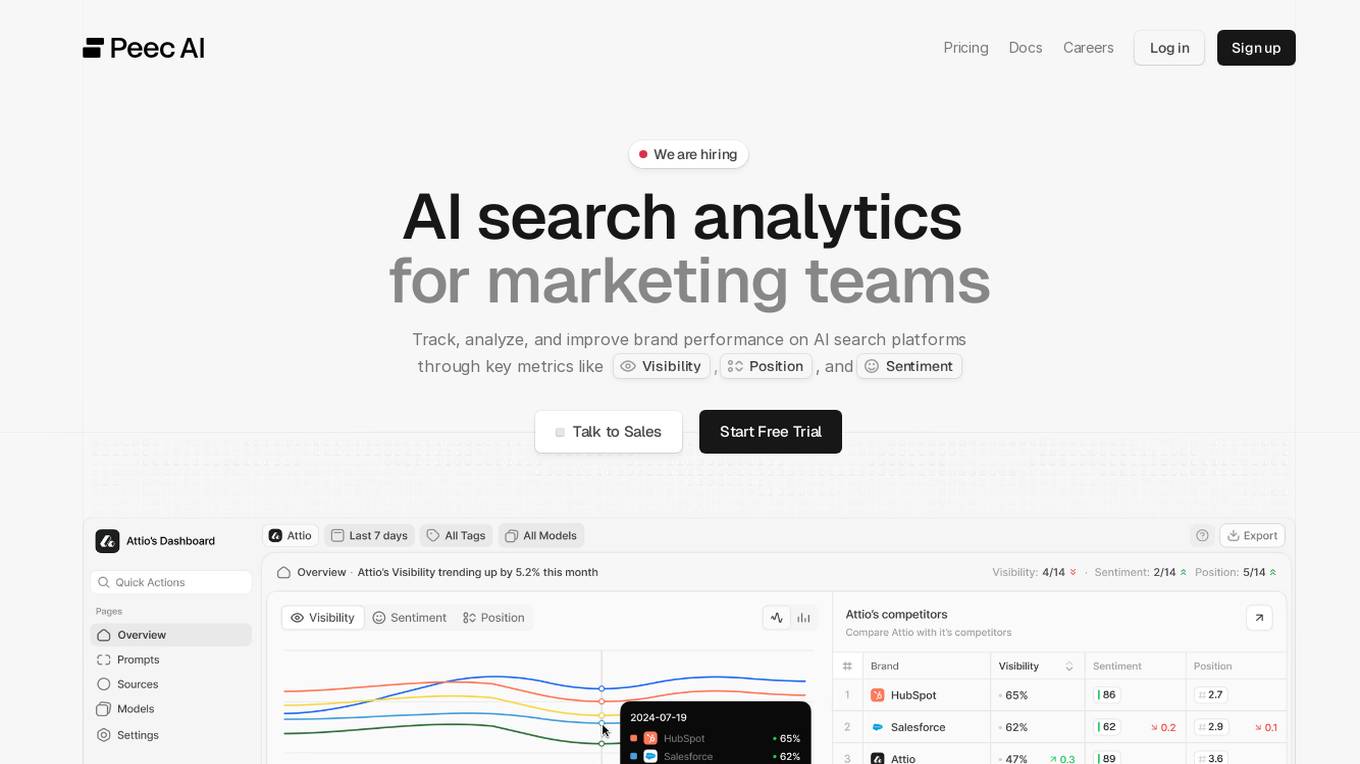
Peec AI
Peec AI is an AI search analytics tool designed for marketing teams to track, analyze, and improve brand performance on AI search platforms. It provides key metrics such as Visibility, Position, and Sentiment to help businesses understand how AI perceives their brand. The platform offers insights on AI visibility, prompts analysis, and competitor tracking to enhance marketing strategies in the era of AI and generative search.

Reflection 70B
Reflection 70B is a next-gen open-source LLM powered by Llama 70B, offering groundbreaking self-correction capabilities that outsmart GPT-4. It provides advanced AI-powered conversations, assists with various tasks, and excels in accuracy and reliability. Users can engage in human-like conversations, receive assistance in research, coding, creative writing, and problem-solving, all while benefiting from its innovative self-correction mechanism. Reflection 70B sets new standards in AI performance and is designed to enhance productivity and decision-making across multiple domains.

Gorilla
Gorilla is an AI tool that integrates a large language model (LLM) with massive APIs to enable users to interact with a wide range of services. It offers features such as training the model to support parallel functions, benchmarking LLMs on function-calling capabilities, and providing a runtime for executing LLM-generated actions like code and API calls. Gorilla is open-source and focuses on enhancing interaction between apps and services with human-out-of-loop functionality.

SocialOpinionAI
The website offers a powerful AI tool for conducting social media opinion research on platforms like TikTok, Snapchat, LinkedIn, and more. It utilizes advanced algorithms to analyze and extract insights from user-generated content, helping businesses and individuals understand public sentiment and trends across various social media channels.
Embedl
Embedl is an AI tool that specializes in developing advanced solutions for efficient AI deployment in embedded systems. With a focus on deep learning optimization, Embedl offers a cost-effective solution that reduces energy consumption and accelerates product development cycles. The platform caters to industries such as automotive, aerospace, and IoT, providing cutting-edge AI products that drive innovation and competitive advantage.
SaaSlidator
SaaSlidator is an AI-powered application designed to help users validate their project ideas efficiently and effectively. By providing a project name and description, SaaSlidator offers valuable insights to support decision-making on whether to proceed with building and launching a minimum viable product (MVP). The platform leverages AI algorithms to analyze data, offer market demand insights, competition analysis, and assess the feasibility of project ideas. With features like rapid validation, monetization suggestions, and benchmarking data, SaaSlidator aims to streamline the idea validation process and empower users to make informed decisions for successful project development.
Quolity AI
Quolity is an AI-powered platform designed for Answer Engine Optimization (AEO) to help brands and businesses enhance their online visibility and credibility in AI search engines. It offers insights, quality scores, and actions based on analyzing AI citations, brand mentions, and competitive link analysis. Quolity tracks brand mentions, provides quality analysis, and offers recommendations to improve AEO performance. The platform caters to startups, B2B SaaS, agencies, and content-driven brands aiming to excel in the evolving landscape of AI search.
1 - Open Source AI Tools

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.
10 - OpenAI Gpts
SaaS Navigator
A strategic SaaS analyst for CXOs, with a focus on market trends and benchmarks.

HVAC Apex
Benchmark HVAC GPT model with unmatched expertise and forward-thinking solutions, powered by OpenAI


Transfer Pricing Advisor
Guides businesses in managing global tax liabilities efficiently.
Salary Guides
I provide monthly salary data in euros, using a structured format for global job roles.
Performance Testing Advisor
Ensures software performance meets organizational standards and expectations.