Best AI tools for< Voice Technology Developer >
Infographic
20 - AI tool Sites
Elixir
Elixir is an AI tool designed for observability and testing of AI voice agents. It offers features such as automated testing, call review, monitoring, analytics, tracing, scoring, and reviewing. Elixir helps in simulating realistic test calls, analyzing conversations, identifying mistakes, and debugging issues with audio snippets and call transcripts. It provides detailed traces for complex abstractions, streamlines manual review processes, and allows for simulating thousands of calls for full test coverage. The tool is suitable for monitoring agent performance, detecting anomalies in real-time, and improving conversational systems through human-in-the-loop feedback.
AssemblyAI
AssemblyAI is an industry-leading Speech AI tool that offers powerful SpeechAI models for accurate transcription and understanding of speech. It provides breakthrough speech-to-text models, real-time captioning, and advanced speech understanding capabilities. AssemblyAI is designed to help developers build world-class products with unmatched accuracy and transformative audio intelligence.

PlayAI
PlayAI is an AI tool designed for businesses and developers to create voice interfaces effortlessly. The platform allows users to generate conversational agents by simply tapping or clicking, enabling them to shuffle, share, and clone voices. PlayAI offers a user-friendly interface for building agents, making it easy to customize and deploy voice interactions. With a focus on simplicity and efficiency, PlayAI aims to revolutionize the way businesses and developers engage with their audience through voice technology.
LookupKit AI Tools Directory
LookupKit AI Tools Directory is a platform that offers a curated collection of AI tools for various purposes. Users can explore and discover cutting-edge AI applications in different domains such as text-writing, image processing, video creation, coding assistance, voice technology, business analytics, marketing automation, AI detection, chatbot development, design, art, life assistance, 3D modeling, education, productivity enhancement, and more. The platform aims to provide a comprehensive directory of AI tools to cater to the diverse needs of users across industries and sectors.
AIGO.tools
AIGO.tools is an AI application that serves as a comprehensive directory of AI tools, apps, and websites designed to enhance personal and business productivity. The platform offers a wide range of AI-powered solutions across various categories such as text and writing, chatbot design, art generation, image and video editing, voice technology, 3D modeling, AI detection, business tools, coding and IT resources, educational aids, life assistance tools, marketing solutions, and other productivity applications. Users can explore and discover innovative AI tools to tackle challenges and boost efficiency in different aspects of their lives.
Sesame AI
Sesame AI is an advanced AI voice synthesis platform that revolutionizes digital speech creation by combining AI technology with natural language processing. It offers incredibly lifelike voices with emotional expression and conversational flow, making it ideal for content creators, developers, and businesses seeking to enhance their applications with natural voice capabilities.
Foreva AI
Foreva AI is a restaurant voice AI application that never misses an order. It offers a complete solution for handling voice orders, with 99% order accuracy and support for English & Spanish customers. The application can work standalone or integrate with existing POS systems, providing enterprise-scale volume handling capabilities. Foreva AI is designed to help restaurants increase revenue, improve order accuracy, and enhance customer satisfaction through voice AI technology.
SagaSwipe
SagaSwipe is an interactive audio adventure application designed for iOS and Android users. It offers a unique experience where users can immerse themselves in infinite audio realms guided solely by touch. Unlike traditional sleep apps, SagaSwipe provides engaging escapes into magical realms, vibrant cities, serene landscapes, or mysterious outer space. The application combines AI and voice synthesis technology with an intuitive interface to generate personalized audio worlds for users to explore and relax.
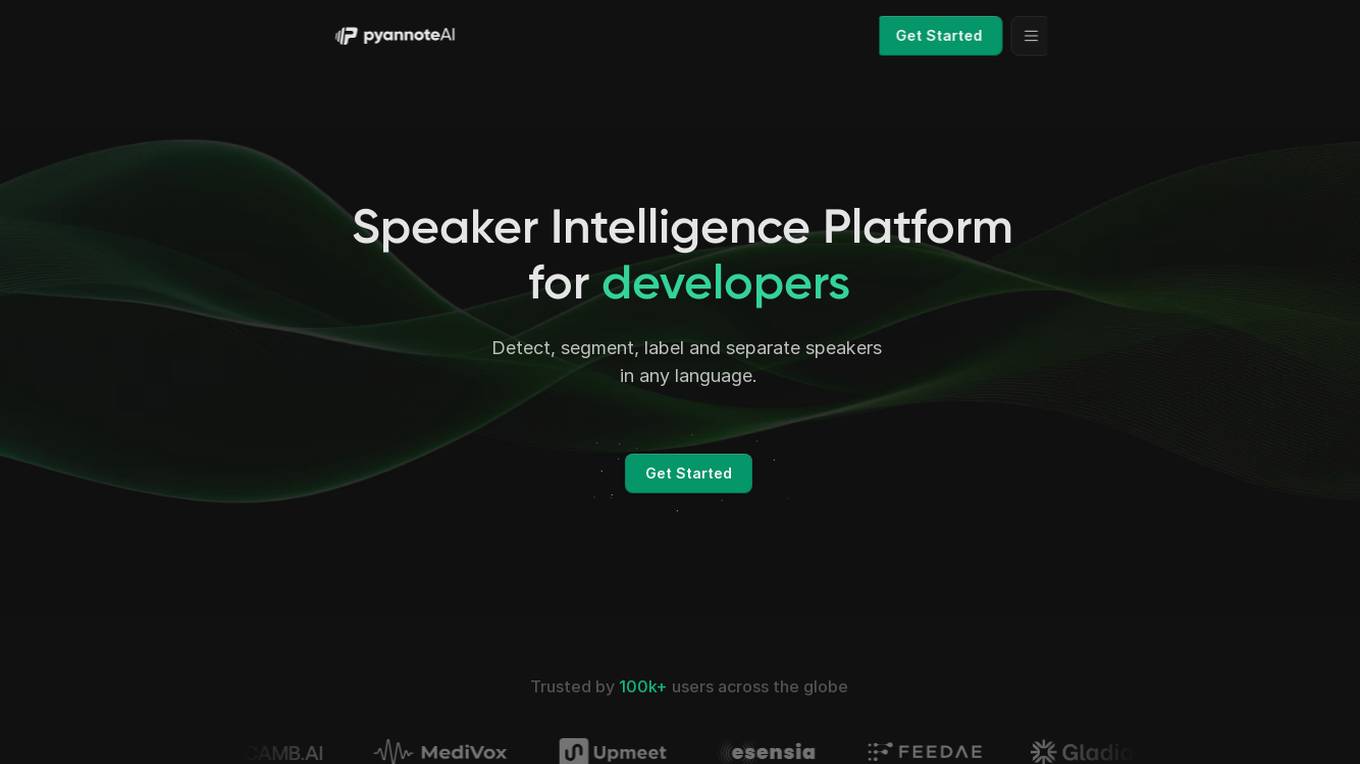
pyannote AI Speaker Intelligence Platform
The pyannote AI Speaker Intelligence Platform is an advanced AI tool designed for developers to detect, segment, label, and separate speakers in any language. It offers state-of-the-art speaker diarization models that accurately identify speakers in audio recordings, providing valuable insights and improving productivity. With optimized AI models, the platform saves time, effort, and money by delivering top-tier performance. The tool is language agnostic and offers advanced features such as speaker partitioning, identification, overlapping speech detection, voice activity detection, speaker separation, and confidence scoring.
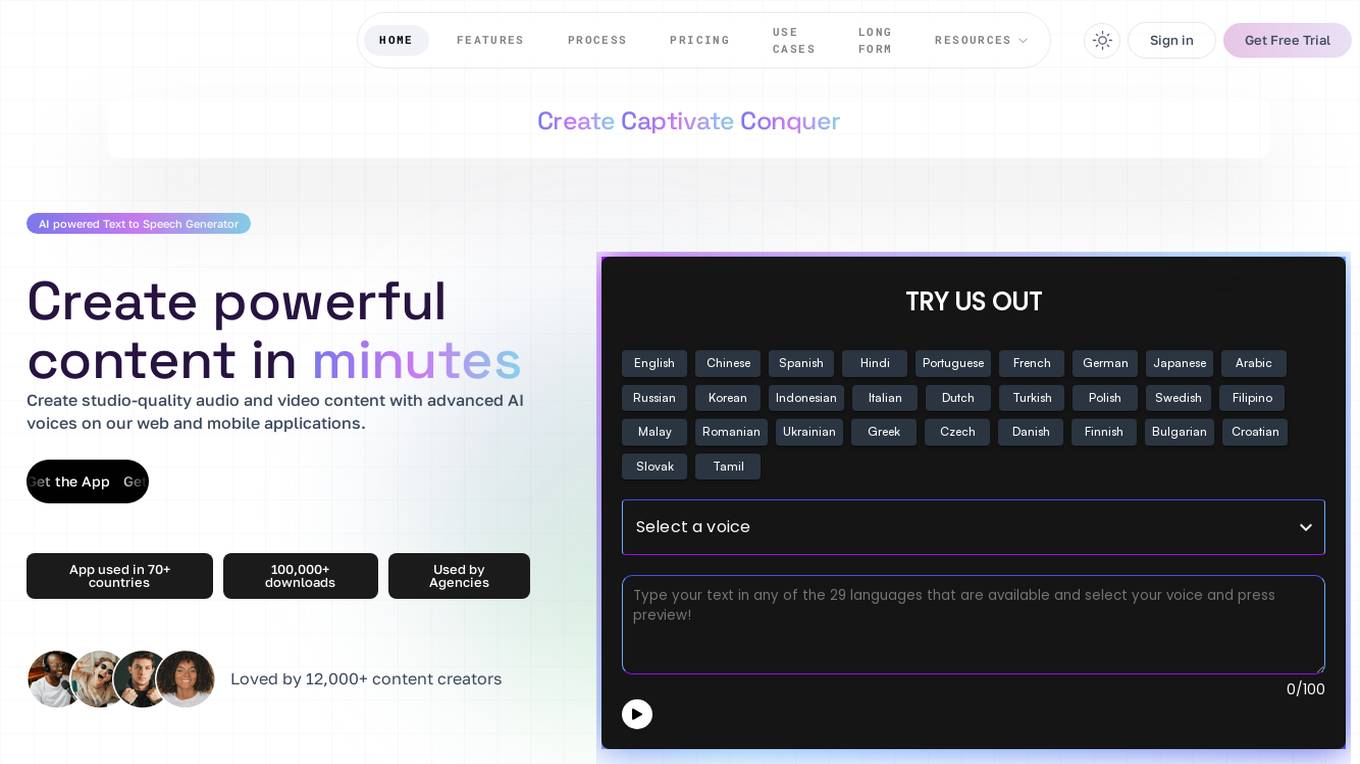
Voice Air
Voice Air is an AI-powered Text to Speech Generator that allows users to create studio-quality audio and video content with advanced AI voices on web and mobile applications. It offers cutting-edge features to enhance content creation, such as human-like voiceovers, award-winning music library, and AI features for content scaling. Voice Air is used in 70+ countries, with 100,000+ downloads and is loved by 12,000+ content creators. The application aims to revolutionize content creation by providing high-quality, natural-sounding voices and innovative features.

Altered Studio
Altered Studio is a Voice Content Creation platform that provides exclusive access to our unique Speech-To-Speech Voice Morphing and integrates various Voice AI technologies into a single user friendly application for media production.
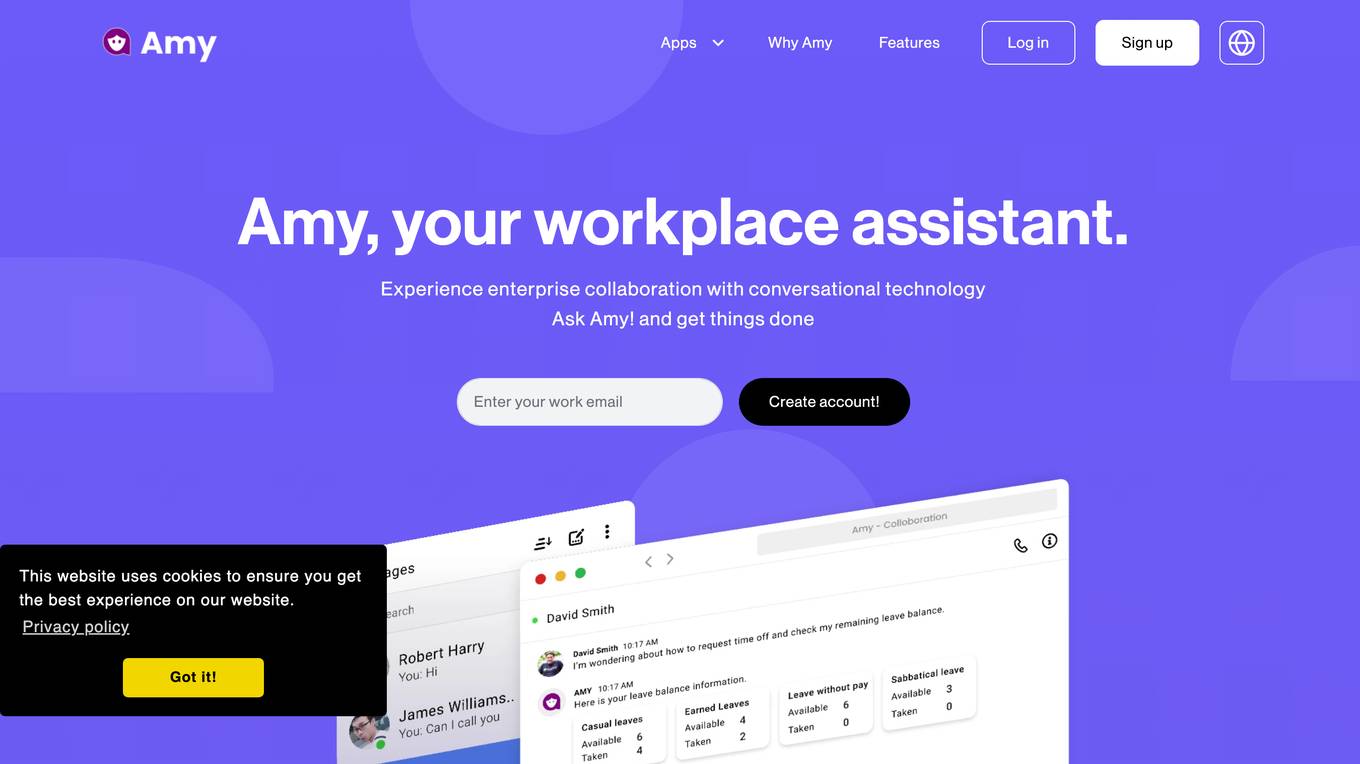
Amy
Amy is a workplace assistant that uses conversational technology to help users with a variety of tasks, including communication, HR, web management, and recruitment. Amy can be used to send messages, schedule meetings, manage attendance and leaves, update websites, post blogs and jobs, and find talent. Amy is designed to be easy to use and can be accessed through a variety of devices, including smartphones, tablets, and computers.
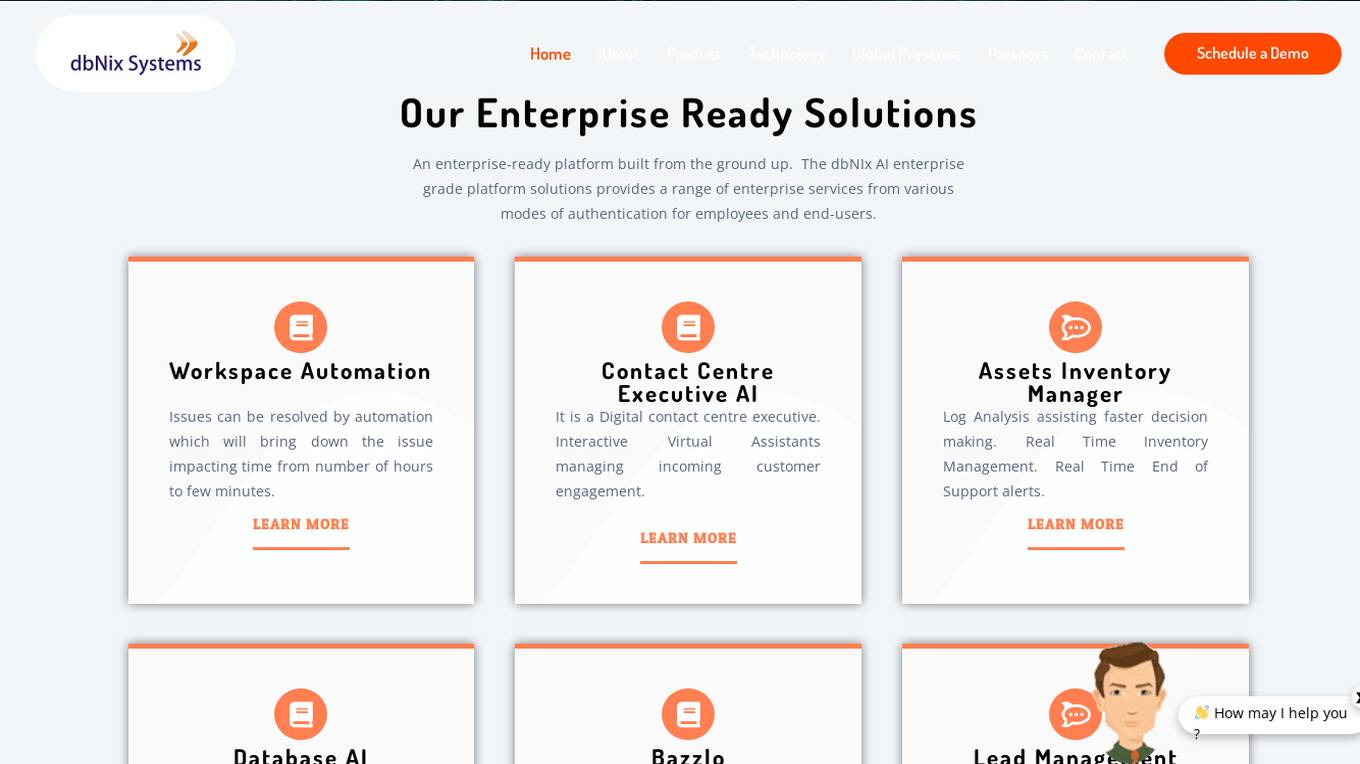
dbNix AI
dbNix AI is an enterprise AI company that provides a range of AI-powered solutions for businesses. Their platform offers various services, including workspace automation, contact center automation, asset inventory management, database AI, digital persona sharing, lead management, human resource AI, and network monitoring. dbNix AI's mission is to provide customers with the most compelling AI solutions and deliver the highest quality of customer service.
ChatTTS
ChatTTS is an open-source text-to-speech model designed for dialogue scenarios, supporting both English and Chinese speech generation. Trained on approximately 100,000 hours of Chinese and English data, it delivers speech quality comparable to human dialogue. The tool is particularly suitable for tasks involving large language model assistants and creating dialogue-based audio and video introductions. It provides developers with a powerful and easy-to-use tool based on open-source natural language processing and speech synthesis technologies.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
VoiceGen
VoiceGen is an AI audio platform that enables users to create realistic speech using the best technology from leading providers like OpenAI, Google, AWS, and Azure. It offers natural, high-quality voices with support for multiple languages and unrestricted commercial use. VoiceGen prioritizes simplicity, transparency, and innovation, providing an accessible and affordable solution for voice generation needs. The platform ensures security and privacy of user data, offering a pay-as-you-go pricing model with fair and transparent costs.
LMNT
LMNT is an ultrafast lifelike AI speech pricing API that offers low latency streaming for conversational apps, agents, and games. It provides lifelike voices through studio-quality voice clones and instant voice clones. Engineered by an ex-Google team, LMNT ensures reliable performance under pressure with consistent low latency and high availability. The platform enables real-time conversation, content creation at scale, and product marketing through captivating voiceovers. With a user-friendly interface and developer API, LMNT simplifies voice cloning and synthesis for both beginners and professionals.

AiCogni
AiCogni is a multi-lingual voice chat bot and writing assistant, powered by ChatGPT. It is designed to be a versatile AI companion that can help users with a wide range of tasks, from learning and communication to creativity and productivity. AiCogni's advanced ChatGPT technology enables it to understand and respond to user queries in a natural and informative way, making it an ideal tool for anyone looking to enhance their communication and learning experiences.
AIEasyUse
AIEasyUse is a user-friendly website that provides easy-to-use AI tools for businesses and individuals. With over 60+ content creation templates, our AI-powered content writer can help you quickly generate high-quality content for your blog, website, or marketing materials. Our AI-powered image generator can create custom images for your content. Simply input your desired image parameters and our AI technology will generate a unique image for you. Our AI-powered chatbot is available 24/7 to help you with any questions you may have about our platform or your content. Our chatbot can handle common inquiries and provide personalized support. Our AI-powered code generator can help you write code for your web or mobile app faster and more efficiently. Easily convert speech files to text for transcription or captioning purposes.
Respeecher
Respeecher is an AI tool that combines technology and magic to deliver authentic voices across various industries. It uses cutting-edge public models and proprietary technology to provide high-quality voice solutions. The team of dedicated sound professionals at Respeecher ensures ethical use of synthetic media, making it a trusted choice for voice cloning and voice conversion services.
2 - Open Source Tools

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.

VoiceBench
VoiceBench is a repository containing code and data for benchmarking LLM-Based Voice Assistants. It includes a leaderboard with rankings of various voice assistant models based on different evaluation metrics. The repository provides setup instructions, datasets, evaluation procedures, and a curated list of awesome voice assistants. Users can submit new voice assistant results through the issue tracker for updates on the ranking list.
20 - OpenAI Gpts
Anime Voice Match
Anime Voice Match, identifies anime characters similar to the user's voice.
Voice/Style/Tone AI Prompt Snippet Generator
Analyzes your writing and produces a prompt snippet you can use in any other prompt to guide AI in replicating your voice, style, and tone. Just provide the text in the prompt box or in a document (don't use a link or image). You don't need to write any additional prompt language with your text.


Voice Memo
Record your thoughts with ChatGPT Voice Conversations 💡. Get started by clicking the 🎧 icon right to the chat input. Available on mobile only. Ask 'how do you work?' to learn more.
Vedic Voice
A scholar in Hindu literature providing positive, brief insights against negativity.

Skillful Voice
Premier expert in household management, offering unparalleled advice and guidance.


Earth Conscious Voice
Hi ;) Ask me for data & insights gathered from an environmentally aware global community
Bring Your Writing Voice to Every Task
This GPT will help you recreate your writing voice across multiple tasks. All you need is a prior writing sample (email, blog, article, tweet) and a new task.
Passive to Active Voice Text Converter AI
I convert and rewrite passive voice text into active voice tone and language. Simply put your passive voice text below! Perfect for sentences, paragraphs, daily emails, and longer texts.