Best AI tools for< Visual Question Answerer >
Infographic
20 - AI tool Sites
Joseph Chet Redmon's Computer Vision Platform
The website is a platform maintained by Joseph Chet Redmon, a graduate student working on computer vision. It features information on his projects, publications, talks, and teaching activities. The site also includes details about the Darknet Neural Network Framework, tactics in Coq, and research work. Visitors can learn about computer vision, object recognition, and visual question answering through the resources provided on the site.
Socratic
Socratic is an AI-powered learning tool that provides students with personalized support in various subjects, including Science, Math, Literature, and Social Studies. It utilizes text and speech recognition to surface relevant learning resources and offers visual explanations of important concepts. Socratic is highly regarded by both teachers and students for its ability to clarify complex topics and supplement classroom learning.
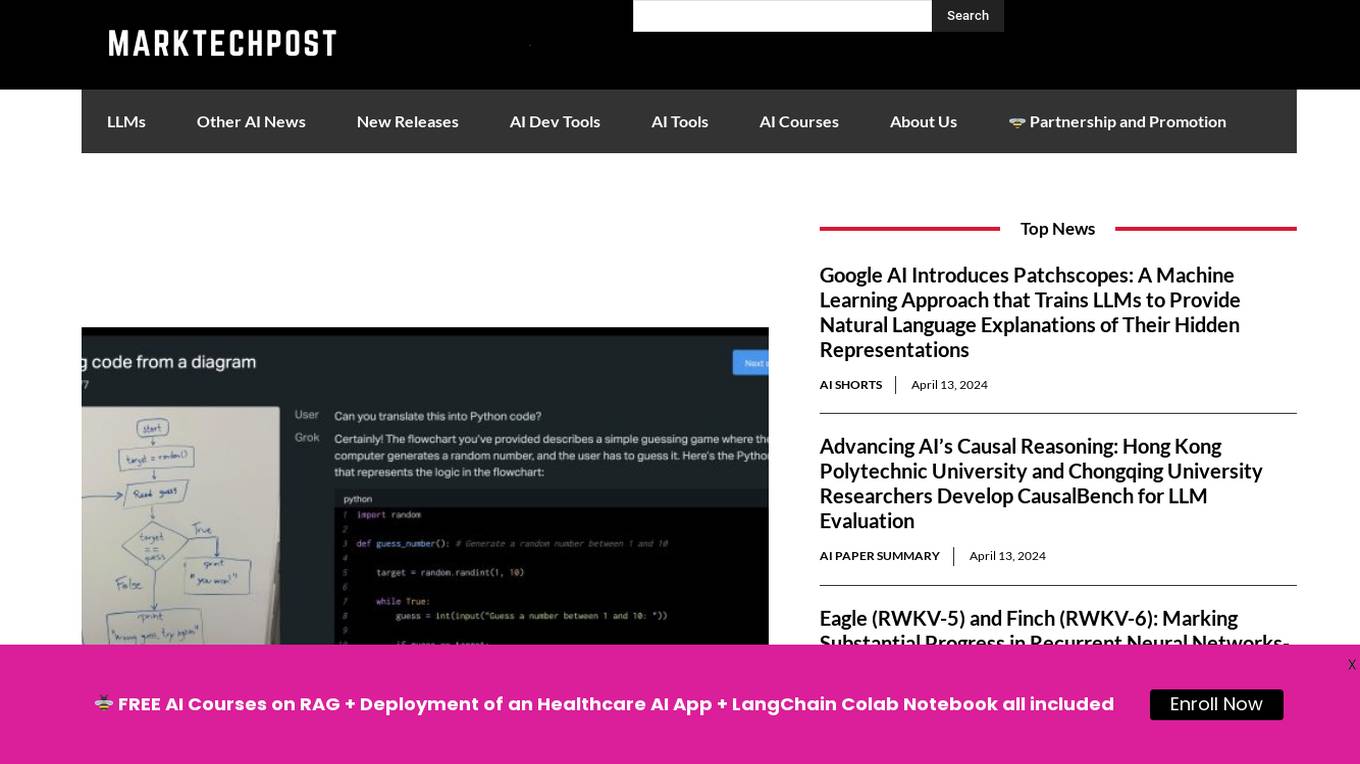
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.
Summify
Summify is an AI-powered tool that helps users summarize YouTube videos, podcasts, and other audio-visual content. It offers a range of features to make it easy to extract key points, generate transcripts, and transform videos into written content. Summify is designed to save users time and effort, and it can be used for a variety of purposes, including content creation, blogging, learning, digital marketing, and research.
ChatCube
ChatCube is an AI-powered chatbot maker that allows users to create chatbots for their websites without coding. It uses advanced AI technology to train chatbots on any document or website within 60 seconds. ChatCube offers a range of features, including a user-friendly visual editor, lightning-fast integration, fine-tuning on specific data sources, data encryption and security, and customizable chatbots. By leveraging the power of AI, ChatCube helps businesses improve customer support efficiency and reduce support ticket reductions by up to 28%.
Scribe
Scribe is a tool that allows users to create step-by-step guides for any process. It uses AI to automatically generate instructions and screenshots, and it can be used to document processes, train employees, and answer questions. Scribe is available as a Chrome extension and a desktop app.

Supersimple
Supersimple is an AI-native data analytics platform that combines a semantic data modeling layer with the ability to answer ad hoc questions, giving users reliable, consistent data to power their day-to-day work.
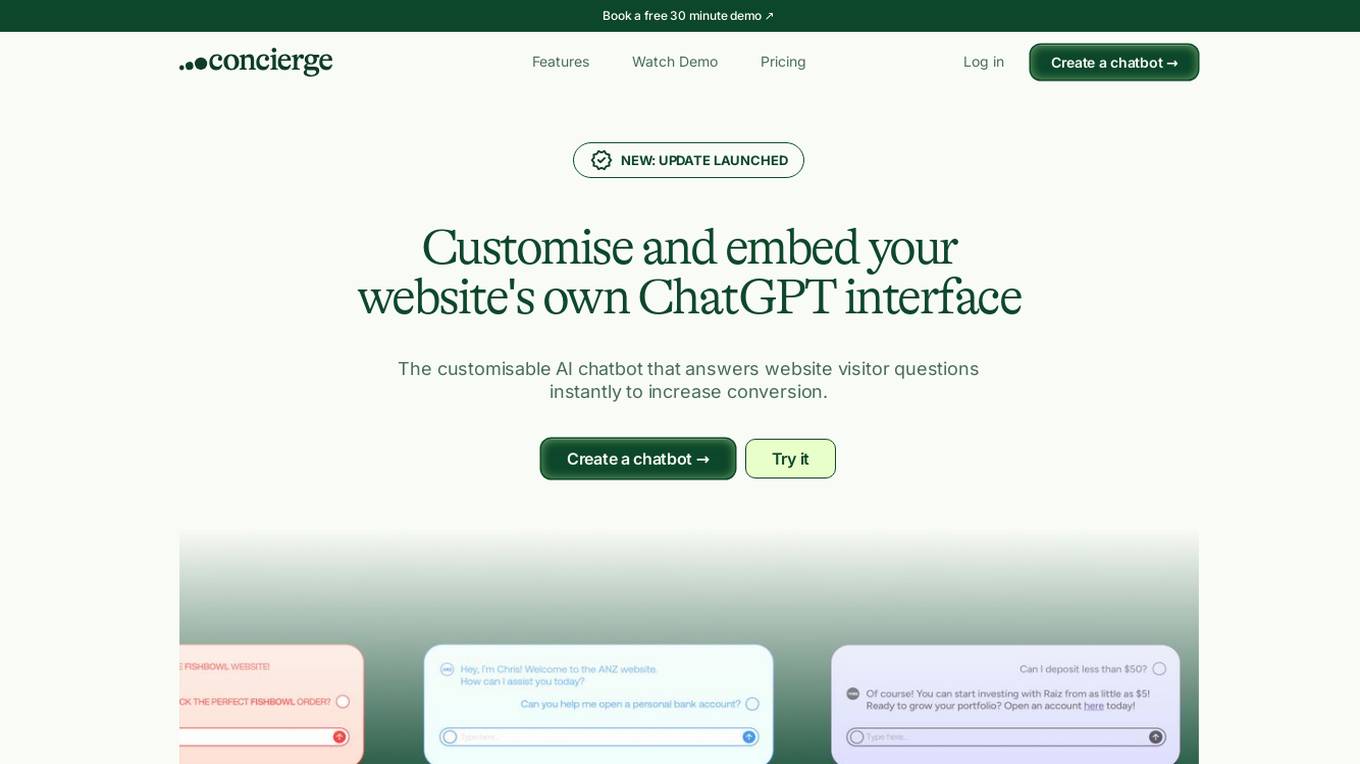
Concierge
Concierge is an AI-powered chatbot application designed to help businesses answer website visitor questions instantly, boosting engagement and conversions. It is a lightweight and powerful tool that is easy to embed, customize, and personalize to match the brand's voice and visual identity. Concierge offers features such as effortless setup, contextual AI training, flexible customization, and fast and easy results. It is a no-brainer add-on that modernizes websites with expert AI assistance.
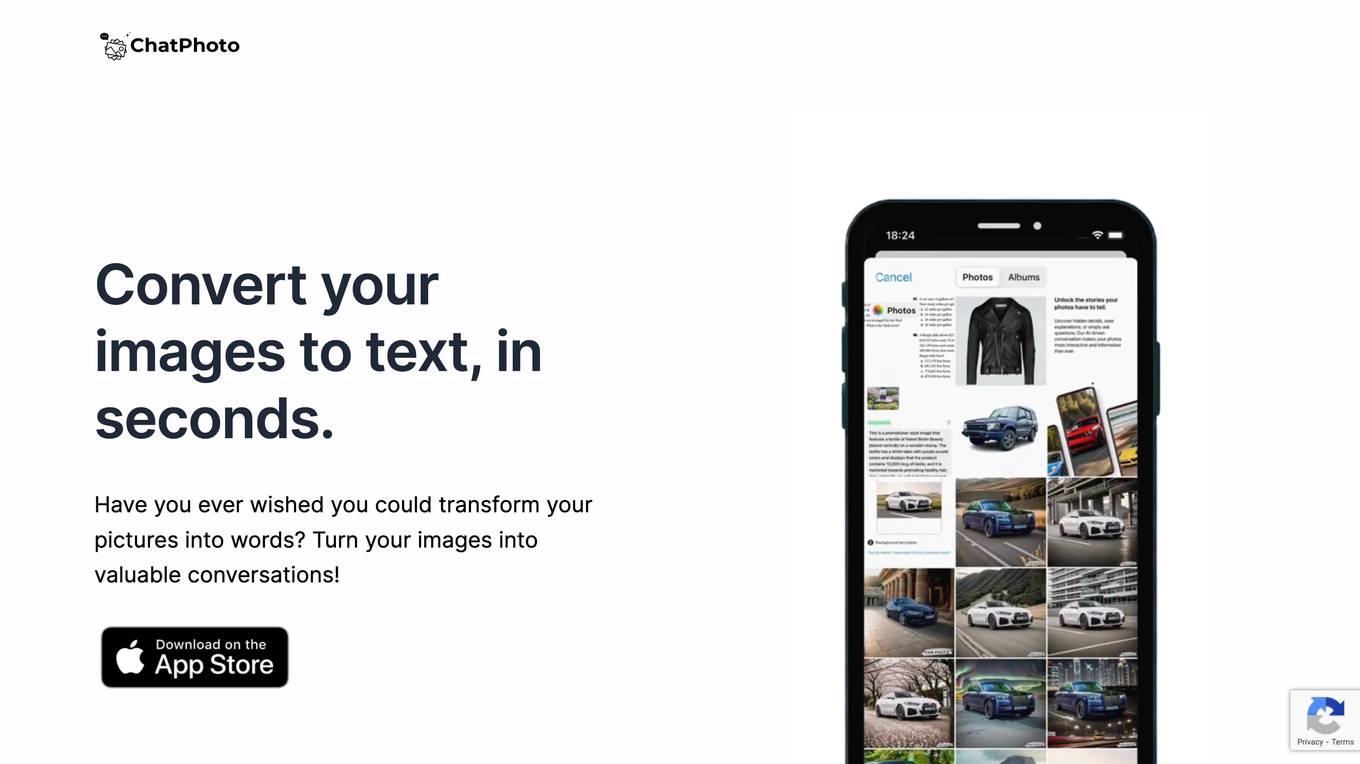
ChatPhoto
ChatPhoto is an AI-powered application that allows users to convert images to text in seconds. It offers a unique way to transform pictures into words, enabling users to ask questions about their photos and receive insightful responses. The application supports multiple languages, making it accessible to users worldwide. ChatPhoto aims to provide detailed and accurate answers by delving into the visual depths of images, turning them into stories or helping users find the right words for captions. With features like image to text conversion, language support, and interactive exploration, ChatPhoto offers a fun and easy way to engage with images.
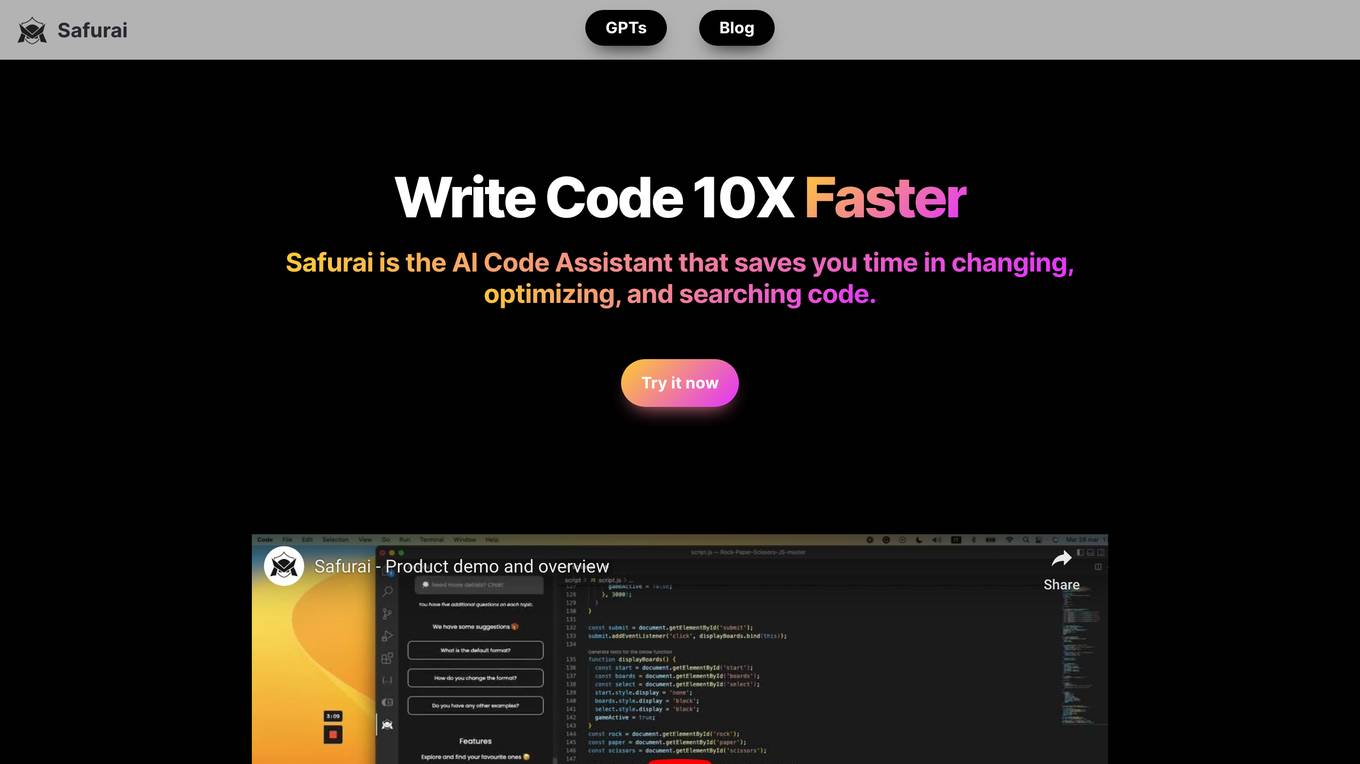
Safurai
Safurai is an AI-powered coding assistant that helps developers write code faster, safer, and better. It offers a range of features, including a textbox for asking questions and getting code suggestions, shortcuts for code optimization and unit testing, the ability to train the assistant on specific projects, and a natural language search for finding code. Safurai is compatible with various IDEs, including Visual Studio Code, IntelliJ, and PyCharm.
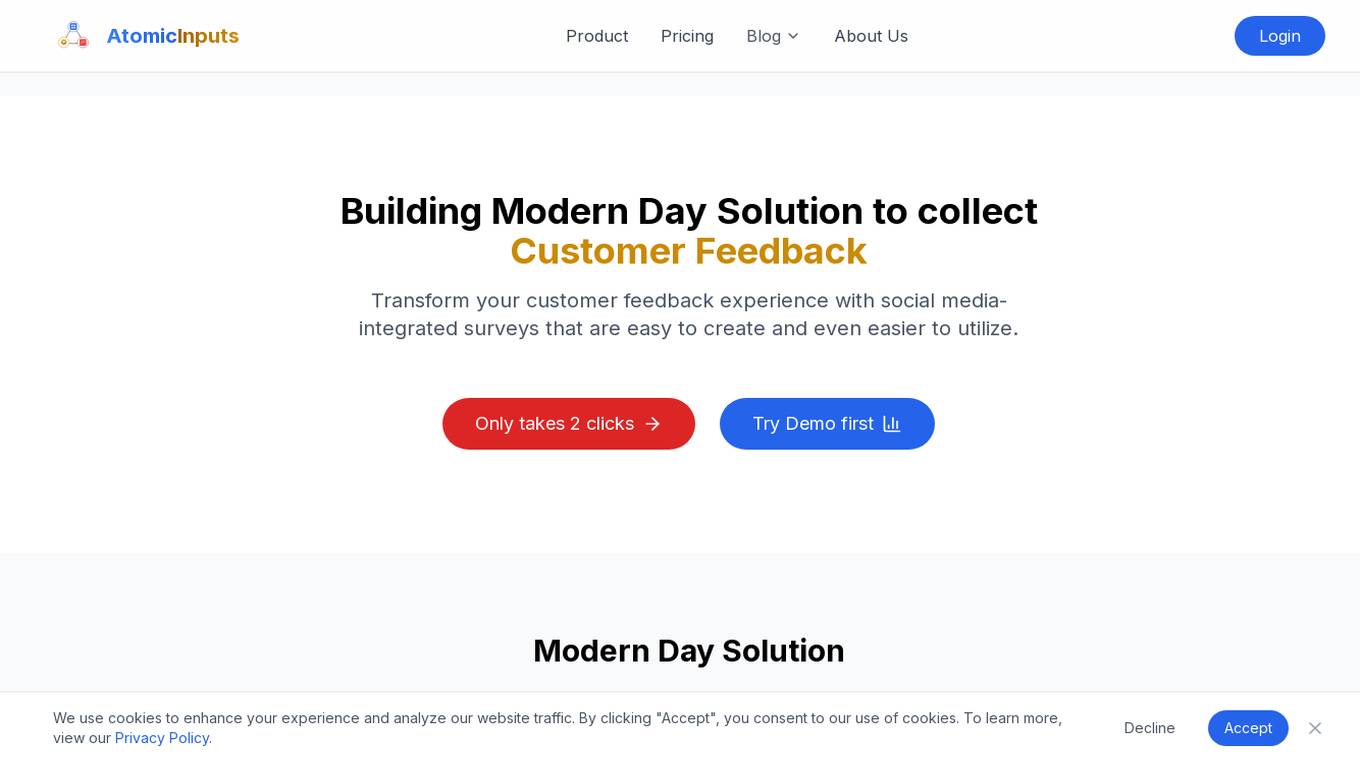
Atomic Inputs
Atomic Inputs is a modern customer feedback solution that leverages AI technology to collect, analyze, and transform customer feedback into actionable insights. The platform offers social media-integrated surveys, expertly crafted templates, visual analytics, and AI-powered recommendations to enhance customer experience. With features like customizable engagement, transparent pricing, and seamless integration with popular platforms, Atomic Inputs simplifies feedback collection and business metrics interpretation. The application caters to businesses of all sizes, providing tailored solutions for growth and enterprise needs.
Copalot AI Copilot
Copalot is an AI copilot application designed to provide AI chat and visual video support for small businesses. It helps in reducing customer interaction and support costs by offering AI chat and video FAQ bots that can be embedded in websites or linked to products. Copalot allows users to create custom ChatGPT and FAQs based on their own content, supporting multiple file formats and webpages. The application is user-friendly and multilingual, catering to a global customer base.
ChatBot
ChatBot is an AI chat bot software designed to provide quick and accurate AI-generated answers to customer questions on websites. It offers a range of features such as Visual Builder, Dynamic Responses, Analytics, and Solutions for various industries. The platform allows users to create their ideal chatbot without coding, powered by generative AI technology. ChatBot aims to enhance customer engagement, streamline workflows, and boost online sales through personalized interactions and automated responses.
VoiceGPT
VoiceGPT is an Android app that provides a voice-based interface to interact with AI language models like ChatGPT, Bing AI, and Bard. It offers features such as unlimited free messages, voice input and output in 67+ languages, a floating bubble for easy switching between apps, OCR text recognition, code execution, image generation with DALL-E 2, and support for ChatGPT Plus accounts. VoiceGPT is designed to be accessible for users with visual impairments, dyslexia, or other conditions, and it can be set as the default assistant to be activated hands-free with a custom hotword.
Meya
Meya is a chatbot platform that allows users to build and launch custom chatbots. It provides a variety of features, including a visual flow editor, a code editor, and a variety of integrations. Meya is designed to be easy to use, even for non-technical users. It is also highly extensible, allowing users to add their own custom code and integrations.
Glassix
Glassix is an AI-powered customer communication and messaging platform that helps businesses manage all their customer conversations from a single inbox. It offers a range of features, including a conversation routing engine, cross-channel continuity, customer conversation history, and rich media & large files sharing. Glassix also offers a visual chatbot builder that allows businesses to create automated flows coupled with Conversational AI, and deploy them to all channels with just one click. With Glassix, businesses can improve customer satisfaction, reduce operational costs, and increase efficiency.
Free ChatGPT Omni (GPT4o)
Free ChatGPT Omni (GPT4o) is a user-friendly website that allows users to effortlessly chat with ChatGPT for free. It is designed to be accessible to everyone, regardless of language proficiency or technical expertise. GPT4o is OpenAI's groundbreaking multimodal language model that integrates text, audio, and visual inputs and outputs, revolutionizing human-computer interaction. The website offers real-time audio interaction, multimodal integration, advanced language understanding, vision capabilities, improved efficiency, and safety measures.
OpenSpace
OpenSpace is a reality capture and construction site capture platform that provides a complete visual record of projects powered by AI. It offers fast and easy site documentation, automating site capture, simplifying documentation, and delivering flexible progress tracking. OpenSpace uses Spatial AI technology to deliver products that are the fastest and easiest in the industry, allowing builders to document projects, answer questions quickly, and solve problems through images.
August
August is a personal AI health assistant designed to provide direct answers to health questions, analyze lab reports and images, offer medical suggestions, and proactively check in on users' health. It aims to save time and reduce anxiety by providing tailored health information. August is not a replacement for medical advice but complements healthcare professionals' guidance. The platform prioritizes user privacy and data security, offering features like personalized nutritional planning, visual symptom checker, and medication/workout reminders.
HEAVY.AI
HEAVY.AI is a cutting-edge analytics and location intelligence platform that empowers users to make time-sensitive, high-impact decisions over vast datasets. The platform offers Conversational Analytics, enabling users to ask questions about their data in natural language and view actionable visualizations instantly. With HeavyEco, the platform also supports emergency response efforts by streamlining the management of weather events. HEAVY.AI combines interactive visual analytics, hardware-accelerated SQL, and advanced analytics & data science framework to uncover hidden opportunities and risks within enterprise datasets.
1 - Open Source Tools
GenAIExamples
This project provides a collective list of Generative AI (GenAI) and Retrieval-Augmented Generation (RAG) examples such as chatbot with question and answering (ChatQnA), code generation (CodeGen), document summary (DocSum), etc.
20 - OpenAI Gpts

Elementary School
Educational AI assistant for elementary students, focusing on English, math, social science, science, visual and performing arts, health, and physical education.

Culinary Food and Recipe Chef Companion
I pair every recipe with a visual aid for an enhanced cooking experience.
Stat Helper
I provide stats education with levels, summaries, quizzes, and visual aids for continuous learning.

Alpha Fitness and Nutrition Guide
Comprehensive fitness and nutrition guide with recipes and visuals.

Visual Storyteller
Extract the essence of the novel story according to the quantity requirements and generate corresponding images. The images can be used directly to create novel videos.小说推文图片自动批量生成,可自动生成风格一致性图片
Visual Pedestrian Pathfinder
I create tailored walks, asking detailed preferences and giving distance in km!
Visual Design GPT ✅ ❌
A resource for visual designers, "Principles and Pitfalls" details how to make impactful visual designs and avoid missteps.