Best AI tools for< Test Evaluator >
Infographic
20 - AI tool Sites
Prelaunch.com
Prelaunch.com is an AI-powered platform that provides bullet-proof insights from ready-to-buy customers for product development and market validation. It offers a range of features including performance dashboard, surveys, AI idea validation, AI market research, and next-gen focus groups. The platform helps businesses test and evaluate demand for products before production, ensuring optimal pricing, market positioning, and business model testing. Prelaunch.com leverages real-world audiences to gather genuine insights through surveys, interviews, and focus groups, enabling users to make informed decisions based on validated data.
Vocera
Vocera is an AI voice agent testing tool that allows users to test and monitor voice AI agents efficiently. It enables users to launch voice agents in minutes, ensuring a seamless conversational experience. With features like testing against AI-generated datasets, simulating scenarios, and monitoring AI performance, Vocera helps in evaluating and improving voice agent interactions. The tool provides real-time insights, detailed logs, and trend analysis for optimal performance, along with instant notifications for errors and failures. Vocera is designed to work for everyone, offering an intuitive dashboard and data-driven decision-making for continuous improvement.
Checkmyidea-IA
Checkmyidea-IA is an AI-powered tool that helps entrepreneurs and businesses evaluate their business ideas before launching them. It uses a variety of factors, such as customer interest, uniqueness, initial product development, and launch strategy, to provide users with a comprehensive review of their idea's potential for success. Checkmyidea-IA can help users save time, increase their chances of success, reduce risk, and improve their decision-making.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
DeepEval
DeepEval by Confident AI is a comprehensive LLM Evaluation Framework used by leading AI companies. It enables users to build reliable evaluation pipelines to test any AI system. With 50+ research-backed metrics, native multi-modal support, and auto-optimization of prompts, DeepEval offers a sophisticated evaluation ecosystem for AI applications. The framework covers unit-testing for LLMs, single and multi-turn evaluations, generation & simulation of test data, and state-of-the-art evaluation techniques like G-Eval and DAG. DeepEval is integrated with Pytest and supports various system architectures, making it a versatile tool for AI testing.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.
bottest.ai
bottest.ai is an AI-powered chatbot testing tool that focuses on ensuring quality, reliability, and safety in AI-based chatbots. The tool offers automated testing capabilities without the need for coding, making it easy for users to test their chatbots efficiently. With features like regression testing, performance testing, multi-language testing, and AI-powered coverage, bottest.ai provides a comprehensive solution for testing chatbots. Users can record tests, evaluate responses, and improve their chatbots based on analytics provided by the tool. The tool also supports enterprise readiness by allowing scalability, permissions management, and integration with existing workflows.
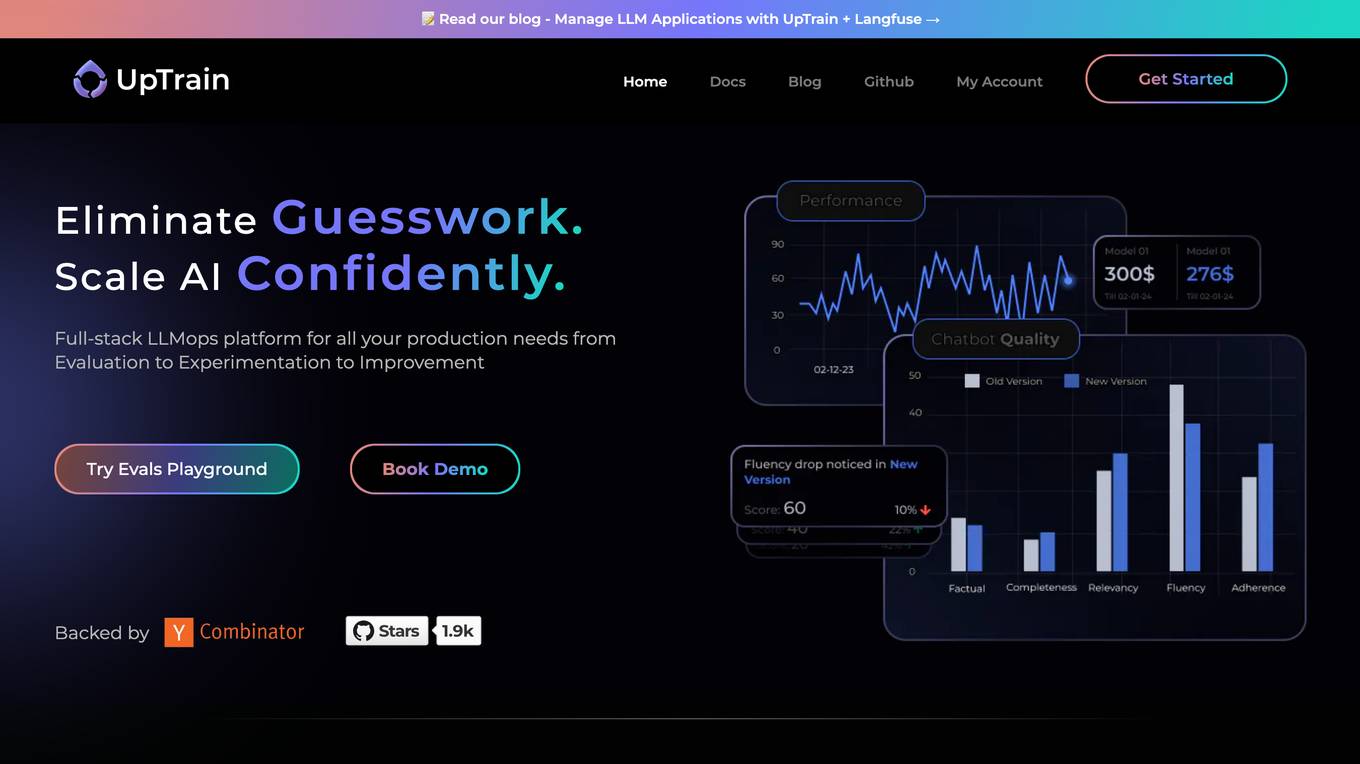
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
Autoblocks AI
Autoblocks AI is an AI application designed to help users build safe AI apps efficiently. It allows users to ship AI agents in minutes, speeding up the development process significantly. With Autoblocks AI, users can prototype quickly, test at a faster rate, and deploy with confidence. The application is trusted by leading AI teams and focuses on making AI agent development more predictable by addressing the unpredictability of user inputs and non-deterministic models.

Lisapet.AI
Lisapet.AI is an AI prompt testing suite designed for product teams to streamline the process of designing, prototyping, testing, and shipping AI features. It offers a comprehensive platform with features like best-in-class AI playground, variables for dynamic data inputs, structured outputs, side-by-side editing, function calling, image inputs, assertions & metrics, performance comparison, data sets organization, shareable reports, comments & feedback, token & cost stats, and more. The application aims to help teams save time, improve efficiency, and ensure the reliability of AI features through automated prompt testing.
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on your speech. It helps users improve their pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English speaking skills and communication abilities.
Galileo AI
Galileo AI is a platform that offers automated evaluations for AI applications, bringing automation and insight to AI evaluations to ensure reliable and confident shipping. It helps in eliminating 80% of evaluation time by replacing manual reviews with high-accuracy metrics, enabling rapid iteration, achieving real-time protection, and providing end-to-end visibility into agent completions. Galileo also allows developers to take control of AI complexity, de-risk AI in production, and deploy AI applications flexibly across different environments. The platform is trusted by enterprises and loved by developers for its accuracy, low-latency, and ability to run on L4 GPUs.
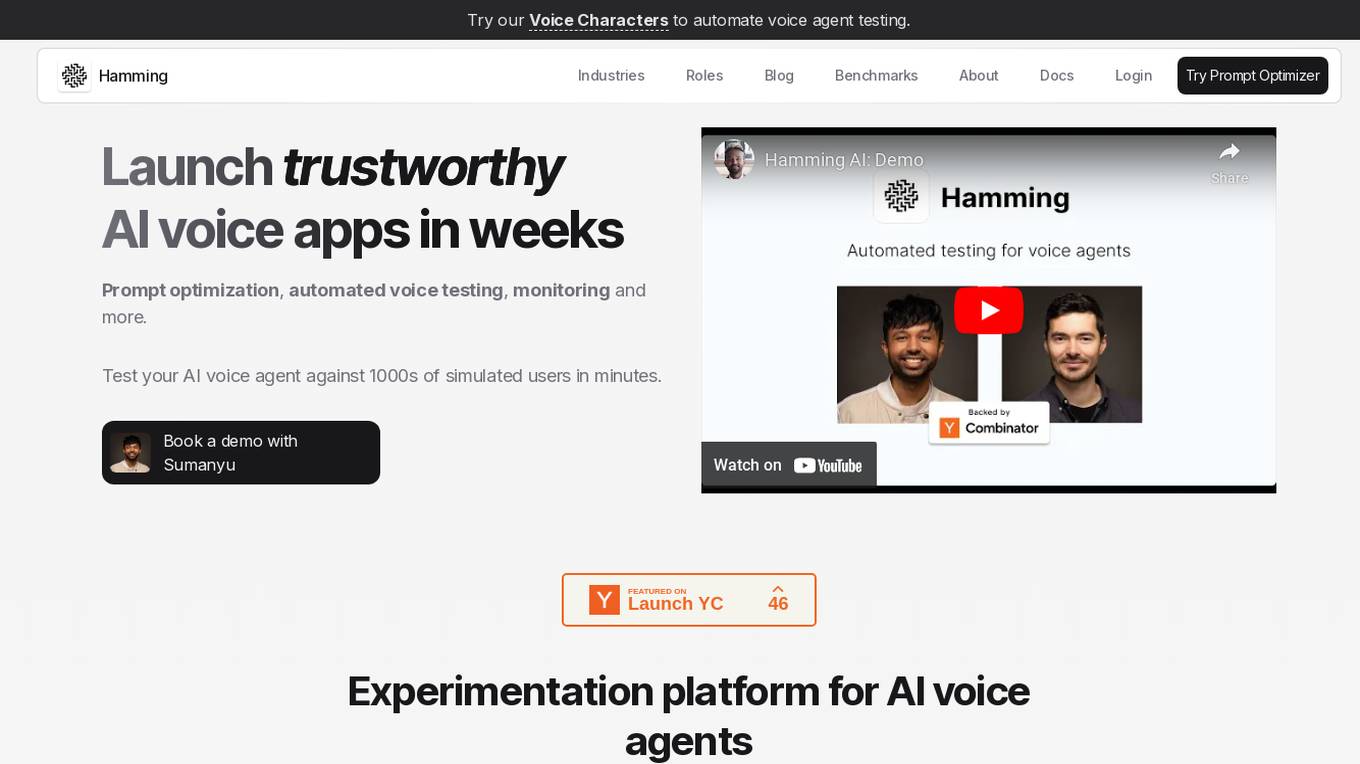
Hamming
Hamming is an AI tool designed to help automate voice agent testing and optimization. It offers features such as prompt optimization, automated voice testing, monitoring, and more. The platform allows users to test AI voice agents against simulated users, create optimized prompts, actively monitor AI app usage, and simulate customer calls to identify system gaps. Hamming is trusted by AI-forward enterprises and is built for inbound and outbound agents, including AI appointment scheduling, AI drive-through, AI customer support, AI phone follow-ups, AI personal assistant, and AI coaching and tutoring.
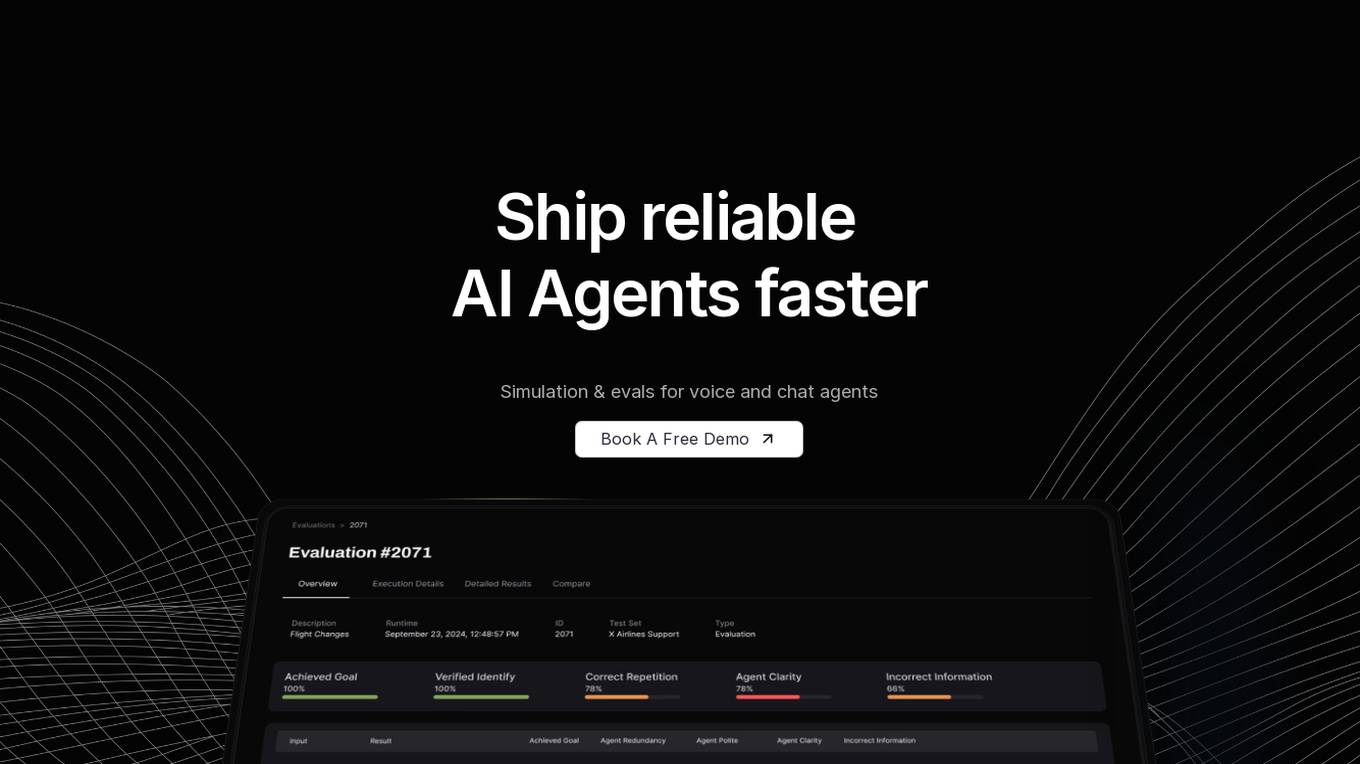
Coval
Coval is an AI tool designed to help users ship reliable AI agents faster by providing simulation and evaluations for voice and chat agents. It allows users to simulate thousands of scenarios from a few test cases, create prompts for testing, and evaluate agent interactions comprehensively. Coval offers AI-powered simulations, voice AI compatibility, performance tracking, workflow metrics, and customizable evaluation metrics to optimize AI agents efficiently.
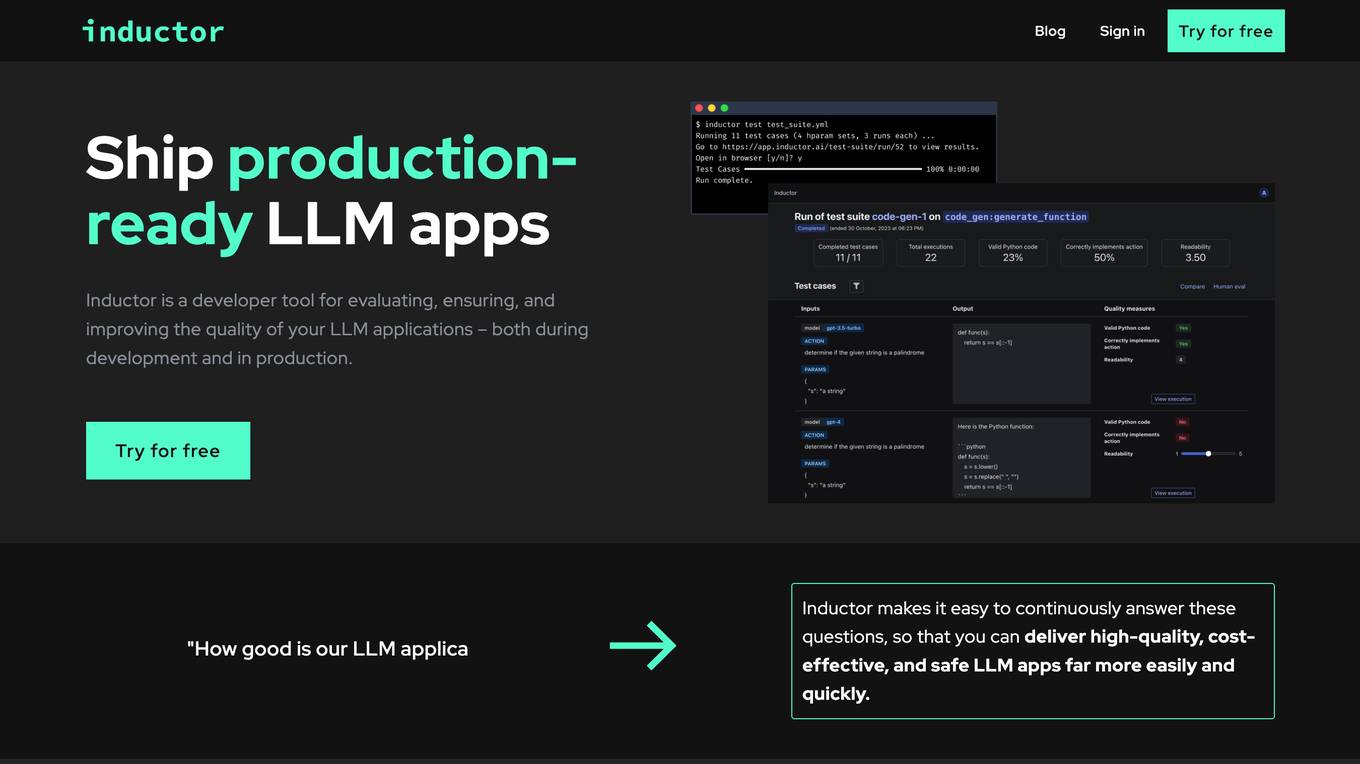
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.
Galleri
Galleri is a multi-cancer early detection test that uses a single blood draw to screen for over 50 types of cancer. It is recommended for adults aged 50 or older who are at an elevated risk for cancer. Galleri is not a diagnostic test and does not detect all cancers. A positive result requires confirmatory diagnostic evaluation by medically established procedures (e.g., imaging) to confirm cancer.

MASCAA
MASCAA is a comprehensive human confidence analysis platform that focuses on evaluating the confidence of users through video and audio during various tasks. It integrates advanced facial expression and voice analysis technologies to provide valuable feedback for students, instructors, individuals, businesses, and teams. MASCAA offers quick and easy test creation, evaluation, and confidence assessment for educational settings, personal use, startups, small organizations, universities, and large organizations. The platform aims to unlock long-term value and enhance customer experience by helping users assess and improve their confidence levels.
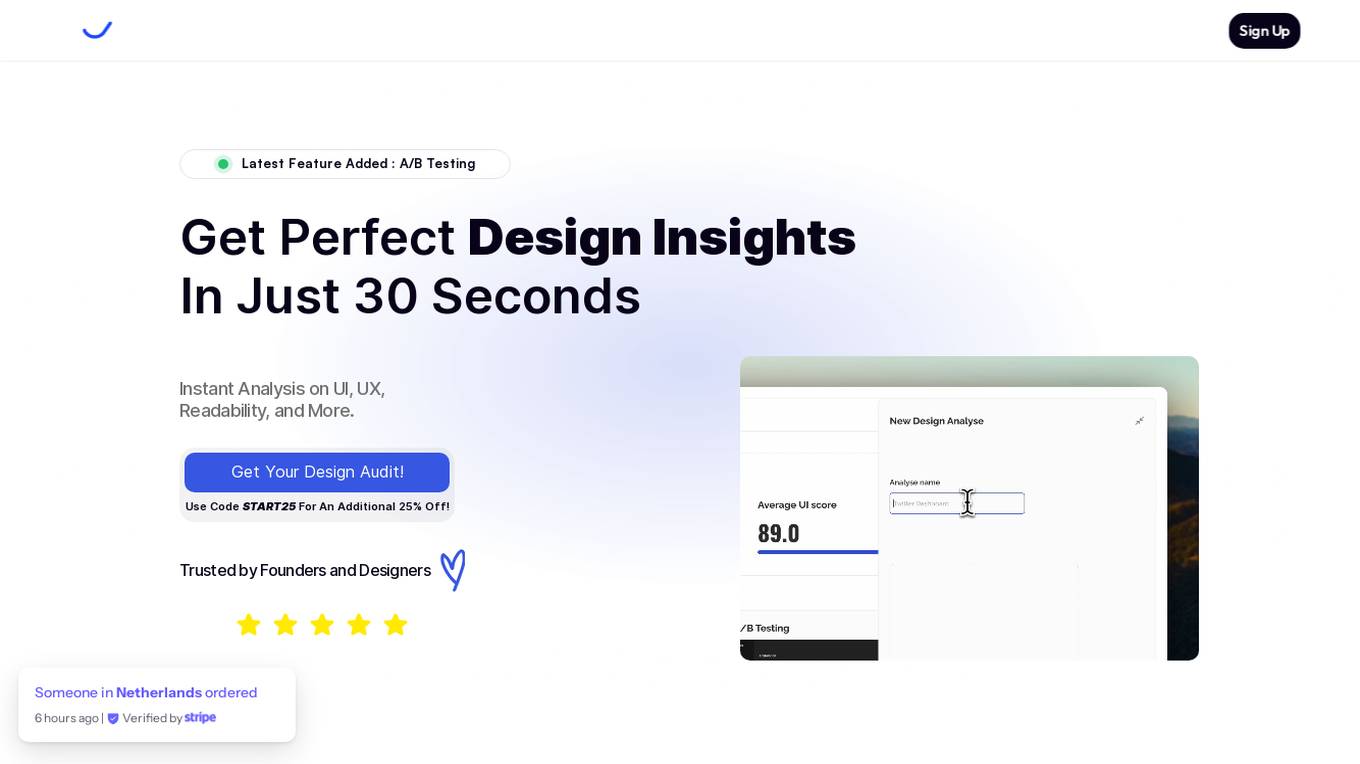
VisualHUB
VisualHUB is an AI-powered design analysis tool that provides instant insights on UI, UX, readability, and more. It offers features like A/B Testing, UI Analysis, UX Analysis, Readability Analysis, Margin and Hierarchy Analysis, and Competition Analysis. Users can upload product images to receive detailed reports with actionable insights and scores. Trusted by founders and designers, VisualHUB helps optimize design variations and identify areas for improvement in products.

Traceable
Traceable is an intelligent API security platform designed for enterprise-scale security. It offers unmatched API discovery, attack detection, threat hunting, and infinite scalability. The platform provides comprehensive protection against API attacks, fraud, and bot security, along with API testing capabilities. Powered by Traceable's OmniTrace Engine, it ensures unparalleled security outcomes, remediation, and pre-production testing. Security teams trust Traceable for its speed and effectiveness in protecting API infrastructures.
0 - Open Source Tools
20 - OpenAI Gpts

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

IELTS Writing Test
Simulates the IELTS Writing Test, evaluates responses, and estimates band scores.

API Evaluator Pro
Examines and evaluates public API documentation and offers detailed guidance for improvements, including AI usability
Product Improvement Research Advisor
Improves product quality through innovative research and development.
Concept Tutor
Assistant focused on teaching concepts, evaluating comprehension, and recommending subsequent topics. USE WITH VOICE.
IQ Test Assistant
An AI conducting 30-question IQ tests, assessing and providing detailed feedback.

Quality Assurance Advisor
Ensures product quality through systematic process monitoring and evaluation.

IELTS AI Checker (Speaking and Writing)
Provides IELTS speaking and writing feedback and scores.
Wordon, World's Worst Customer | Divergent AI
I simulate tough Customer Support scenarios for Agent Training.
Business Model Advisor
Business model expert, create detailed reports based on business ideas.
Immersive Experience Designer
This GPT Helps to Brainstorm Immersive Experience Ideas Using the TISECT Method
Test Shaman
Test Shaman: Guiding software testing with Grug wisdom and humor, balancing fun with practical advice.
Raven's Progressive Matrices Test
Provides Raven's Progressive Matrices test with explanations and calculates your IQ score.

Test Case GPT
I will provide guidance on testing, verification, and validation for QA roles.