Best AI tools for< Speech Pathologist >
Infographic
20 - AI tool Sites
Everbility
Everbility is an AI-powered clinical documentation tool designed for Allied Health Professionals. It helps in writing reports, synthesizing client notes, brainstorming ideas, and focusing on client care. The tool saves time by generating progress notes, letters, and assessment reports, while ensuring data privacy and compliance with regulations like HIPAA and Australian Privacy Principles.
Better Speech Online Speech Therapy
Better Speech Online Speech Therapy is an AI-driven platform that offers convenient, affordable, and effective speech therapy services for children and adults. The platform utilizes cutting-edge artificial intelligence to provide personalized practices and make speech therapy more engaging, convenient, and affordable. With a team of 250+ licensed and experienced therapists, Better Speech aims to help individuals of all ages improve their communication skills from the comfort of their homes. The platform offers unlimited speech practices between sessions, immediate availability, easy scheduling, and effective results comparable to in-person therapy.
JobsUSA
JobsUSA is an AI-powered platform that offers curated job opportunities in the US. The platform provides expert insights, tailored options, and innovative solutions to help users succeed confidently. JobsUSA connects exceptional talent with the right opportunities by embracing the latest technologies and continuously evolving to meet the changing job market landscape.
MediNav
MediNav is an AI-powered medical assistant application designed to streamline patient documentation processes for healthcare professionals. It utilizes advanced algorithms for extracting and learning medical information, reducing costs, saving time, and enhancing patient care. The application is not just a medical dictation tool but an intelligent assistant that continuously improves through user corrections. With features like speech recognition technology, natural language processing, and federated learning, MediNav offers efficient and accurate medical documentation solutions for various medical specialties.

Speech Studio
Speech Studio is a cloud-based speech-to-text and text-to-speech platform that enables developers to add speech capabilities to their applications. With Speech Studio, developers can easily transcribe audio and video files, generate synthetic speech, and build custom speech models. Speech Studio is a powerful tool that can be used to improve the accessibility, efficiency, and user experience of any application.
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on your speech. It helps users improve their pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English speaking skills and communication abilities.
AI Wedding Speech Generator
The AI wedding speech generator is an online tool that allows users to create personalized wedding speeches quickly and effortlessly. Users can select their role and style, input special details, and generate fully structured and emotional speeches within seconds. The tool offers multiple speech styles to match the wedding atmosphere, allows for personalization with shared memories and emotional connections, and provides high-quality customer support. It is a convenient solution for anyone looking to prepare touching and meaningful speeches for weddings.
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
Text-To-Speech OpenAI
Text-To-Speech OpenAI is a professional AI voice generator that allows users to convert text into natural-sounding speech. With advanced AI technology, it offers a wide range of voices, languages, and customization options to create realistic and engaging audio content. Whether you need to create voiceovers for videos, podcasts, e-learning courses, or any other project, Text-To-Speech OpenAI provides a powerful and user-friendly solution.
Text to Speech Online
Text to Speech Online is a free AI tool that offers unlimited text-to-speech conversion with over 409 realistic voices and 129 languages & dialects. Users can convert text to speech in seconds without the need to log in or sign up. The tool supports multiple languages and accents, including standard voices and AI voices, and offers flexible pricing models. Users can enjoy a full set of SSML features, create natural-sounding speech, download audio in MP3 or WAV formats, and share results on various platforms. Text to Speech Online is a versatile tool that can be used for various purposes, including providing audio cues for visually impaired users, assisting in education, creating audio versions of books, and developing virtual assistants.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
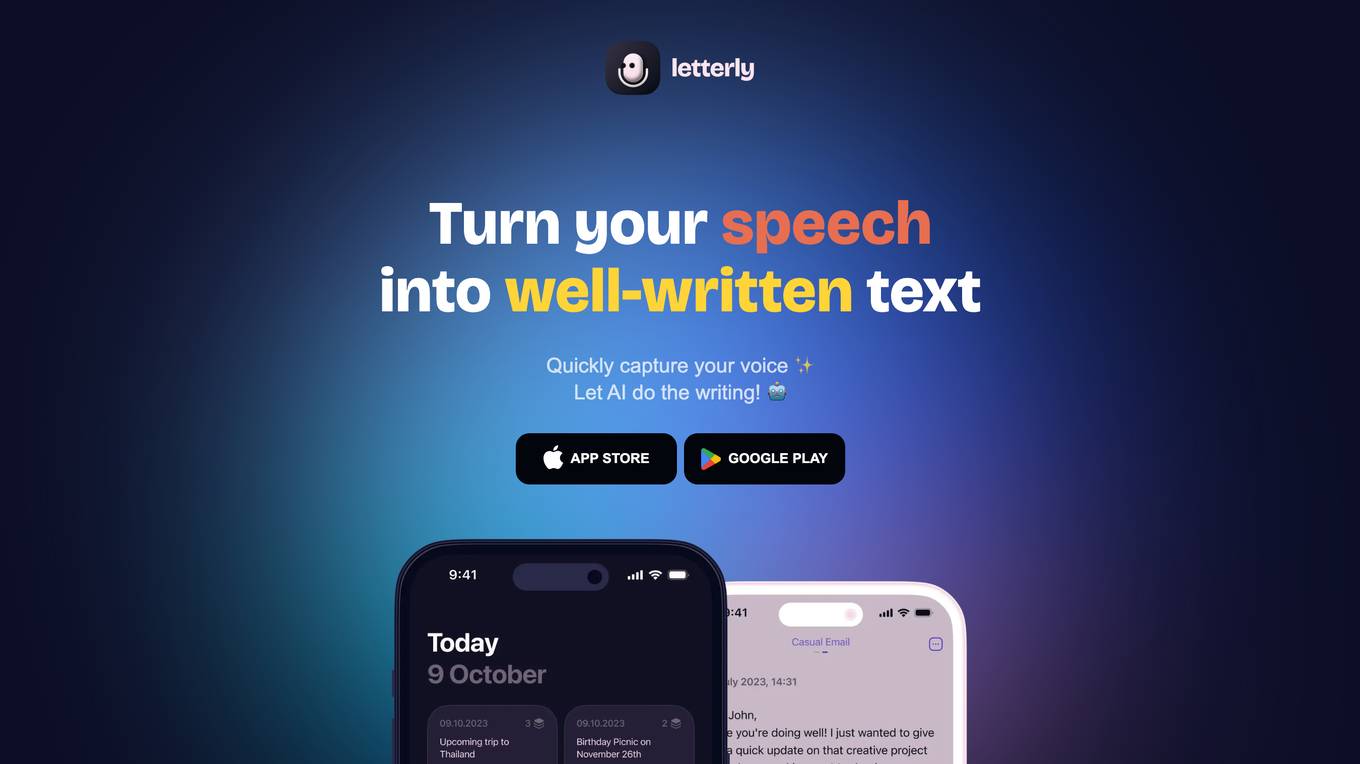
Letterly App
Letterly is an AI speech-to-text mobile app that allows users to quickly capture their voice and have AI convert it into well-crafted text. It offers features such as rewriting options, screen-off recording, multi-language support, and structured text inputs. Users can use Letterly for various tasks like sending clear emails by voice, generating social media posts, and creating to-do lists. The app has received positive reviews for its convenience and accuracy in transcribing voice messages.
Transgate
Transgate is an AI-powered speech-to-text conversion tool that allows users to convert audio/video files to text with high accuracy and efficiency. It offers a pay-as-you-go model, supports over 50 languages, and guarantees 98%+ accuracy. Transgate is designed to boost productivity by minimizing costs and eliminating manual transcription tasks, catering to industries like AI/ML, medical, legal, education, consulting, and market research.
AssemblyAI
AssemblyAI is an industry-leading Speech AI tool that offers powerful SpeechAI models for accurate transcription and understanding of speech. It provides breakthrough speech-to-text models, real-time captioning, and advanced speech understanding capabilities. AssemblyAI is designed to help developers build world-class products with unmatched accuracy and transformative audio intelligence.
Deepgram
Deepgram is a speech recognition and transcription service that uses artificial intelligence to convert audio into text. It is designed to be accurate, fast, and easy to use. Deepgram offers a variety of features, including: - Automatic speech recognition - Speaker diarization - Language identification - Custom acoustic models - Real-time transcription - Batch transcription - Webhooks - Integrations with popular platforms such as Zoom, Google Meet, and Microsoft Teams
Synthesis
Synthesis is a web-based application that allows users to create realistic-sounding synthetic speech from text. The application uses a variety of AI techniques, including natural language processing and machine learning, to generate speech that is both natural-sounding and easy to understand. Synthesis can be used for a variety of purposes, including creating voiceovers for videos, podcasts, and presentations.

Toastful
Toastful is an AI-powered wedding speech generator that helps users create personalized, memorable speeches for their special day. With its cutting-edge AI engine, Toastful guides users through a simple process of providing information about themselves, the couple, and sharing stories. The AI then crafts a unique speech that captures the essence of the relationship and the occasion. Toastful's speeches are highly personalized, tailored to the audience, and designed to captivate listeners. The platform offers a user-friendly interface, making it easy for anyone to create a heartfelt and meaningful speech, even those who may not be confident in their writing abilities.
Vocaldo
Vocaldo is a revolutionary speech-to-text application that utilizes cutting-edge AI technology to transcribe speech into text in over 100 languages. It offers accurate, fast, and easy-to-use transcription services, allowing users to effortlessly convert audio or video files into text with high precision. Vocaldo supports multiple speakers, various accents, and background noise, making it a versatile tool for content creators, journalists, and businesses worldwide.
Lemonfox.ai
Lemonfox.ai is an affordable and easy-to-use Speech-To-Text API that allows users to transcribe audio files quickly and accurately. With features like support for over 100 languages, speaker recognition, high accuracy, and secure processing, Lemonfox.ai is a cost-effective solution for developers and non-developers alike. The API offers simple and affordable pricing plans, with the first month free to get started. Privacy and data security are prioritized, with all data being deleted immediately after processing. Lemonfox.ai is powered by the latest speech recognition AI model, Whisper large-v3, ensuring top-notch performance and competitive pricing.
0 - Open Source Tools
20 - OpenAI Gpts
Dedicated Speech-Language Pathologist
Expert Speech-Language Pathologist offering tailored medical consultations.



Autism Pathway Companion
Expert in autism development, offering guidance on milestones and support strategies.
Neurodiversity Navigator
Autism and Beyond: Your Daily Companion for Neurodiversity Understanding and Support
Occupational Therapist Expert GPT
A robust assistant for OTs creating patient-focused plans.

SpeechTherapist GPT
Your very own speech therapy assistant. Completely private and confidential.

AI Speech Guide
A helpful coach for speech writing, offering constructive advice and support
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.

Detailed Speech Drafting Wizard
Crafts speeches from PowerPoint slides and reference materials, adding depth and context.
AI.EX Wedding Speech Consultant
Your partner in crafting perfect wedding speeches. Let me be your guide to writing impactful, memorable speeches for unforgettable moments.