Best AI tools for< Reinforcement Learning >
Infographic
20 - AI tool Sites
ApX Machine Learning
ApX Machine Learning is a comprehensive resource for AI students, developers, and researchers, offering tools and learning resources to pioneer the future of AI. It provides a wide range of courses, tools, and benchmarks for learners, developers, and researchers in the field of machine learning and artificial intelligence. The platform aims to enhance the capabilities of existing large language models (LLMs) through the Model Context Protocol (MCP), providing access to resources, benchmarks, and tools to improve LLM performance and efficiency.

The Farama Foundation
The Farama Foundation is a platform dedicated to maintaining and supporting the world's open-source reinforcement learning tools. With a large community of contributors and a vast number of installations, the foundation plays a crucial role in advancing the field of AI. They offer a range of tools and resources for developers and researchers interested in reinforcement learning.
PyTorch
PyTorch is an open-source machine learning library based on the Torch library. It is used for applications such as computer vision, natural language processing, and reinforcement learning. PyTorch is known for its flexibility and ease of use, making it a popular choice for researchers and developers in the field of artificial intelligence.
ACM Project
The ACM Project is an AI application focused on the research and development of artificial consciousness. It aims to develop artificial consciousness through emotional learning of AI systems, challenging the traditional approach by treating consciousness as an emergent solution to maintaining emotional equilibrium in unpredictable environments. The project utilizes advanced multimodal perception models, emotional drive reinforcement learning, and measurable awareness through Integrated Information Theory. With a focus on emotional bootstrapping, progressive complexity, and rigorous measurement, the ACM Project aims to engineer consciousness through intrinsic motivation and measurable outcomes.
TWIML
TWIML is a platform that provides intelligent content focusing on Machine Learning and Artificial Intelligence technologies. It offers podcasts, articles, and resources to practitioners, innovators, and leaders, giving insights into the present and future of ML & AI. The platform covers a wide range of topics such as deep reinforcement learning, fusion energy production, data-centric AI, responsible AI, and machine learning platform strategies.

Winder.ai
Winder.ai is an award-winning Enterprise AI Agency that specializes in AI development, consulting, and product development. They have expertise in Reinforcement Learning, MLOps, and Data Science, offering services to help businesses automate processes, scale products, and unlock new markets. With a focus on delivering AI solutions at scale, Winder.ai collaborates with clients globally to enhance operational efficiency and drive innovation through AI technologies.
Google DeepMind
Google DeepMind is a British artificial intelligence research laboratory owned by Google. The company was founded in 2010 by Demis Hassabis, Shane Legg, and Mustafa Suleyman. DeepMind's mission is to develop safe and beneficial artificial intelligence. The company's research focuses on a variety of topics, including machine learning, reinforcement learning, and computer vision. DeepMind has made significant contributions to the field of artificial intelligence, including the development of AlphaGo, the first computer program to defeat a professional human Go player.
Amazon Science
Amazon Science is a research and development organization within Amazon that focuses on developing new technologies and products in the fields of artificial intelligence, machine learning, and computer science. The organization is home to a team of world-renowned scientists and engineers who are working on a wide range of projects, including developing new algorithms for machine learning, building new computer vision systems, and creating new natural language processing tools. Amazon Science is also responsible for developing new products and services that use these technologies, such as the Amazon Echo and the Amazon Fire TV.

MIRI (Machine Intelligence Research Institute)
MIRI (Machine Intelligence Research Institute) is a non-profit research organization dedicated to ensuring that artificial intelligence has a positive impact on humanity. MIRI conducts foundational mathematical research on topics such as decision theory, game theory, and reinforcement learning, with the goal of developing new insights into how to build safe and beneficial AI systems.
Ferhat Erata
Ferhat Erata is an AI application developed by a Computer Science PhD graduate from Yale University. The application focuses on training transformers to solve NP-complete problems using reinforcement learning and improving test-time compute strategies for reasoning. It also explores learning randomized reductions and program properties for security, privacy, and side-channel resilience. Ferhat Erata is currently an Applied Scientist at the Automated Reasoning Group at AWS, working on Neuro-Symbolic AI to prevent factual errors caused by LLM hallucinations using mathematically sound Automated Reasoning checks.
Welo Data
Welo Data is an AI tool that specializes in AI benchmarking, model assessment, and training high-quality datasets for AI models. The platform offers services such as supervised fine tuning, reinforcement learning with human feedback, data generation, expert evaluations, and data quality framework to support the development of world-class AI models. With over 27 years of experience, Welo Data combines language expertise and AI data to deliver exceptional training and performance evaluation solutions.

John Schulman's Homepage
John Schulman's Homepage is an AI tool developed by a researcher at Anthropic. The website focuses on aligning large language models, scalable oversight, and developing better written specifications of model behavior. It showcases the researcher's work in the field of AI, including projects like ChatGPT and the OpenAI API. The homepage also highlights the researcher's academic background, including a PhD in Computer Science from UC Berkeley with a focus on robotics and reinforcement learning.

Center for Human-Compatible Artificial Intelligence
The Center for Human-Compatible Artificial Intelligence (CHAI) is dedicated to building exceptional AI systems for the benefit of humanity. Their mission is to steer AI research towards developing systems that are provably beneficial. CHAI collaborates with researchers, faculty, staff, and students to advance the field of AI alignment and care-like relationships in machine caregiving. They focus on topics such as political neutrality in AI, offline reinforcement learning, and coordination with experts.

Artificial Intelligence: A Modern Approach, 4th US ed.
Artificial Intelligence: A Modern Approach, 4th US ed. is the authoritative, most-used AI textbook, adopted by over 1500 schools. It covers the entire spectrum of AI, from the fundamentals to the latest advances. The book is written in a clear and concise style, with a wealth of examples and exercises. It is suitable for both undergraduate and graduate students, as well as professionals in the field of AI.
StartKit.AI
StartKit.AI is a boilerplate code for AI products that helps users build their AI startups 100x faster. It includes pre-built REST API routes for all common AI functionality, a pre-configured Pinecone for text embeddings and Retrieval-Augmented Generation (RAG) for chat endpoints, and five React demo apps to help users get started quickly. StartKit.AI also provides a license key and magic link authentication, user & API limit management, and full documentation for all its code. Additionally, users get access to guides to help them get set up and one year of updates.
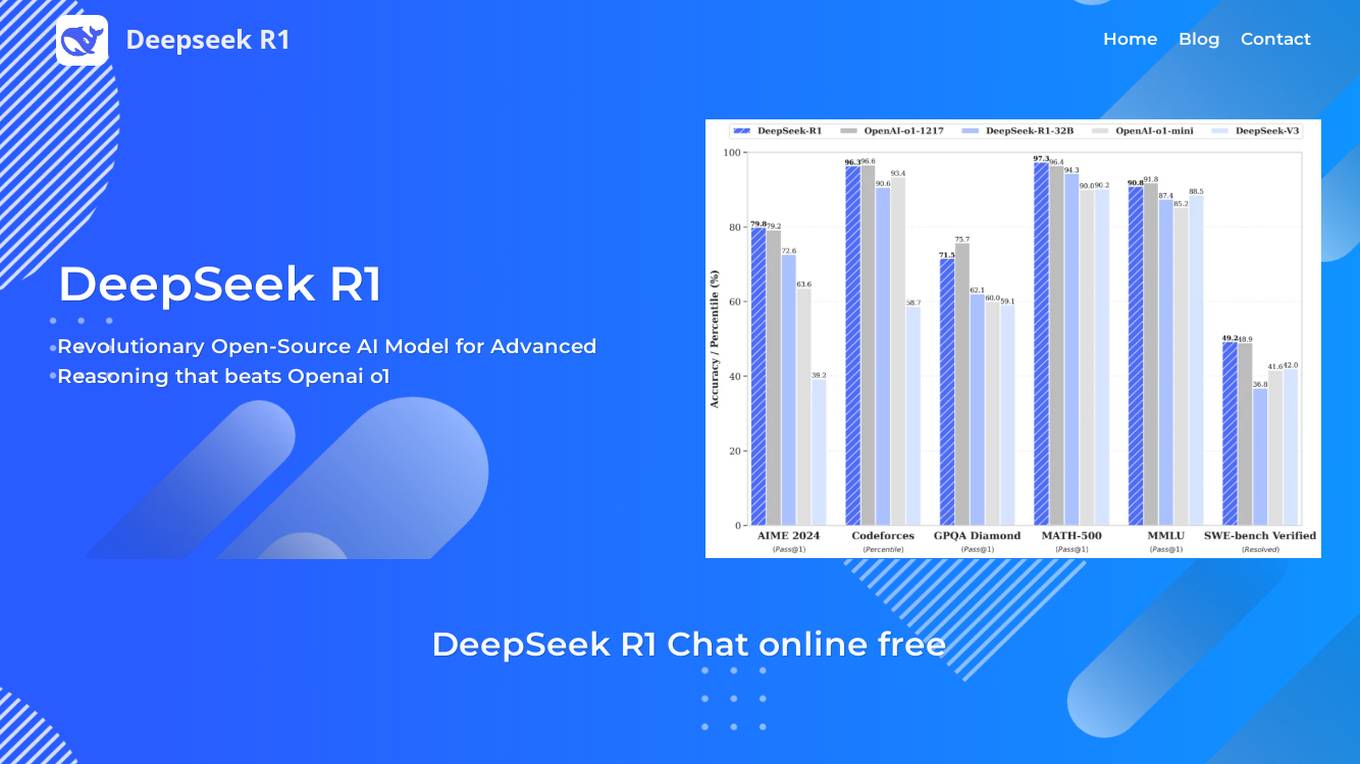
DeepSeek R1
DeepSeek R1 is a revolutionary open-source AI model for advanced reasoning that outperforms leading AI models in mathematics, coding, and general reasoning tasks. It utilizes a sophisticated MoE architecture with 37B active/671B total parameters and 128K context length, incorporating advanced reinforcement learning techniques. DeepSeek R1 offers multiple variants and distilled models optimized for complex problem-solving, multilingual understanding, and production-grade code generation. It provides cost-effective pricing compared to competitors like OpenAI o1, making it an attractive choice for developers and enterprises.
Lyzr AI
Lyzr AI is a full-stack agent framework designed to build GenAI applications faster. It offers a range of AI agents for various tasks such as chatbots, knowledge search, summarization, content generation, and data analysis. The platform provides features like memory management, human-in-loop interaction, toxicity control, reinforcement learning, and custom RAG prompts. Lyzr AI ensures data privacy by running data locally on cloud servers. Enterprises and developers can easily configure, deploy, and manage AI agents using Lyzr's platform.
CHAI AI
CHAI AI is a leading conversational AI platform that focuses on building AI solutions for quant traders. The platform has secured significant funding rounds to expand its computational capabilities and talent acquisition. CHAI AI offers a range of models and techniques, such as reinforcement learning with human feedback, model blending, and direct preference optimization, to enhance user engagement and retention. The platform aims to provide users with the ability to create their own ChatAIs and offers custom GPU orchestration for efficient inference. With a strong focus on user feedback and recognition, CHAI AI continues to innovate and improve its AI models to meet the demands of a growing user base.
VAPA
VAPA is an AI-powered Amazon PPC tool that helps businesses optimize their Amazon advertising campaigns. It leverages deep reinforcement learning algorithms to maximize campaign performance and increase sales. VAPA offers fully automated ad management, strategic growth insights, and expert campaign optimization across multiple Amazon marketplaces. The tool is designed to streamline the advertising process, save time, and improve overall efficiency in managing Amazon ads.
Permar
Permar is an AI-powered website optimization tool that helps businesses increase their conversion rates. It uses reinforcement learning techniques to dynamically adapt website optimization, resulting in an average uplift in conversion rates of 10-12% compared to static A/B tests. Permar also offers a complete toolkit of features to help businesses create high-converting landing pages, including dynamic A/B testing, real-time optimization, and growth experiment ideas.
1 - Open Source Tools

RLHF-Reward-Modeling
This repository contains code for training reward models for Deep Reinforcement Learning-based Reward-modulated Hierarchical Fine-tuning (DRL-based RLHF), Iterative Selection Fine-tuning (Rejection sampling fine-tuning), and iterative Decision Policy Optimization (DPO). The reward models are trained using a Bradley-Terry model based on the Gemma and Mistral language models. The resulting reward models achieve state-of-the-art performance on the RewardBench leaderboard for reward models with base models of up to 13B parameters.
5 - OpenAI Gpts
Multilingual Talent Coach for Interviews with AI
Your go-to coach for career growth 👨👩🎓 Practice questions in multiple languages: The AI can help you build confidence for your next interview by providing you with positive reinforcement and feedback.