Best AI tools for< Model Optimization Engineer >
Infographic
20 - AI tool Sites

Rawbot
Rawbot is an AI model comparison tool that simplifies the process of selecting the best AI models for projects and applications. It allows users to compare various AI models side-by-side, providing insights into their performance, strengths, weaknesses, and suitability. Rawbot helps users make informed decisions by identifying the most suitable AI models based on specific requirements, leading to optimal results in research, development, and business applications.

LM-Kit.NET
LM-Kit.NET is a comprehensive AI toolkit for .NET developers, offering a wide range of features such as AI agent integration, data processing, text analysis, translation, text generation, and model optimization. The toolkit enables developers to create intelligent and adaptable AI applications by providing tools for language models, sentiment analysis, emotion detection, and more. With a focus on performance optimization and security, LM-Kit.NET empowers developers to build cutting-edge AI solutions seamlessly into their C# and VB.NET applications.
Edge Impulse
Edge Impulse is a leading edge AI platform that enables users to build datasets, train models, and optimize libraries to run directly on any edge device. It offers sensor datasets, feature engineering, model optimization, algorithms, and NVIDIA integrations. The platform is designed for product leaders, AI practitioners, embedded engineers, and OEMs across various industries and applications. Edge Impulse helps users unlock sensor data value, build high-quality sensor datasets, advance algorithm development, optimize edge AI models, and achieve measurable results. It allows for future-proofing workflows by generating models and algorithms that perform efficiently on any edge hardware.
Anycores
Anycores is an AI tool designed to optimize the performance of deep neural networks and reduce the cost of running AI models in the cloud. It offers a platform that provides automated solutions for tuning and inference consultation, optimized networks zoo, and platform for reducing AI model cost. Anycores focuses on faster execution, reducing inference time over 10x times, and footprint reduction during model deployment. It is device agnostic, supporting Nvidia, AMD GPUs, Intel, ARM, AMD CPUs, servers, and edge devices. The tool aims to provide highly optimized, low footprint networks tailored to specific deployment scenarios.
Embedl
Embedl is an AI tool that specializes in developing advanced solutions for efficient AI deployment in embedded systems. With a focus on deep learning optimization, Embedl offers a cost-effective solution that reduces energy consumption and accelerates product development cycles. The platform caters to industries such as automotive, aerospace, and IoT, providing cutting-edge AI products that drive innovation and competitive advantage.
Comet ML
Comet ML is an extensible, fully customizable machine learning platform that aims to move ML forward by supporting productivity, reproducibility, and collaboration. It integrates with existing infrastructure and tools to manage, visualize, and optimize models from training runs to production monitoring. Users can track and compare training runs, create a model registry, and monitor models in production all in one platform. Comet's platform can be run on any infrastructure, enabling users to reshape their ML workflow and bring their existing software and data stack.
ONNX Runtime
ONNX Runtime is a production-grade AI engine designed to accelerate machine learning training and inferencing in various technology stacks. It supports multiple languages and platforms, optimizing performance for CPU, GPU, and NPU hardware. ONNX Runtime powers AI in Microsoft products and is widely used in cloud, edge, web, and mobile applications. It also enables large model training and on-device training, offering state-of-the-art models for tasks like image synthesis and text generation.

Caffe
Caffe is a deep learning framework developed by Berkeley AI Research (BAIR) and community contributors. It is designed for speed, modularity, and expressiveness, allowing users to define models and optimization through configuration without hard-coding. Caffe supports both CPU and GPU training, making it suitable for research experiments and industry deployment. The framework is extensible, actively developed, and tracks the state-of-the-art in code and models. Caffe is widely used in academic research, startup prototypes, and large-scale industrial applications in vision, speech, and multimedia.
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.
Intel Gaudi AI Accelerator Developer
The Intel Gaudi AI accelerator developer website provides resources, guidance, tools, and support for building, migrating, and optimizing AI models. It offers software, model references, libraries, containers, and tools for training and deploying Generative AI and Large Language Models. The site focuses on the Intel Gaudi accelerators, including tutorials, documentation, and support for developers to enhance AI model performance.
Industrial Engineer AI
Industrial Engineer AI is an advanced AI tool designed to assist industrial engineers in optimizing processes and improving efficiency in manufacturing environments. The application utilizes machine learning algorithms to analyze data, identify bottlenecks, and suggest solutions for streamlining operations. With its user-friendly interface and powerful capabilities, Industrial Engineer AI is a valuable tool for professionals looking to enhance productivity and reduce costs in industrial settings.
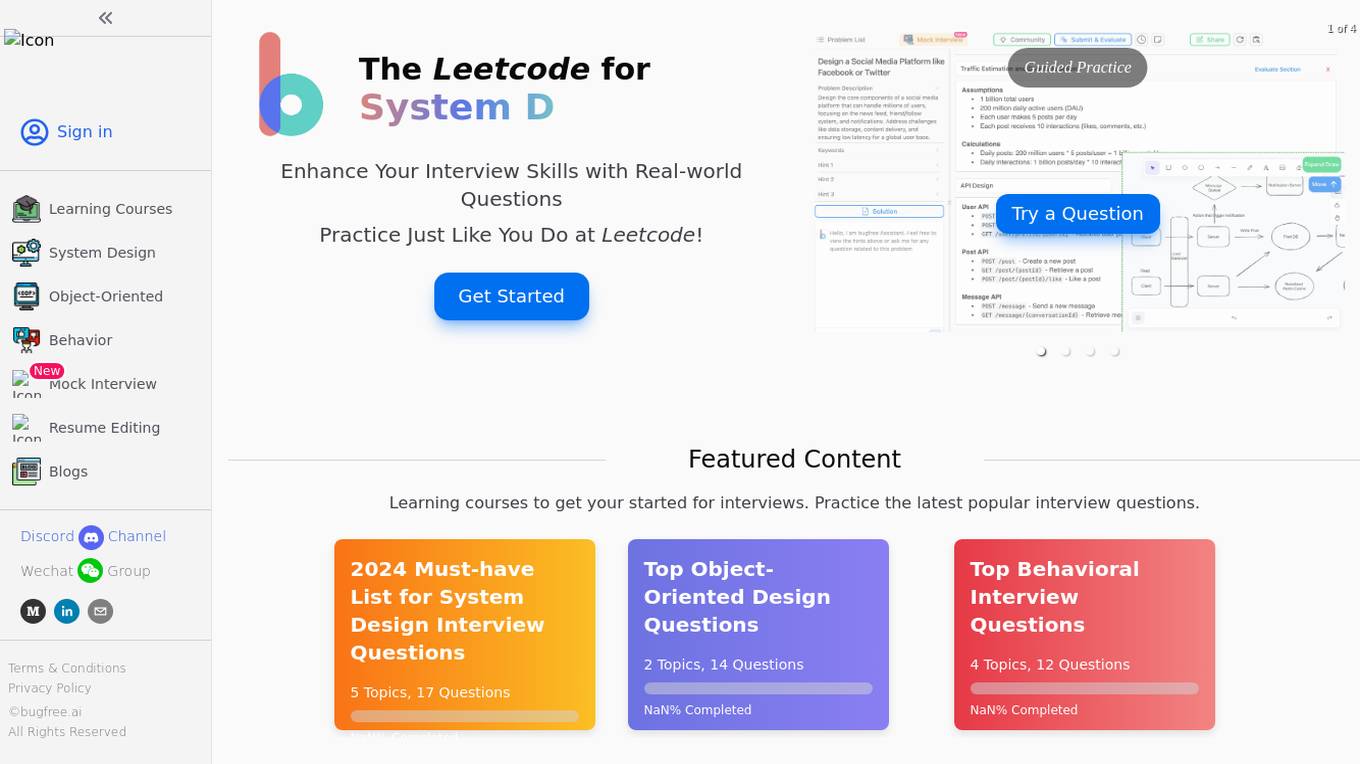
BugFree.ai
BugFree.ai is an AI-powered platform designed to help users practice system design and behavior interviews, similar to Leetcode. The platform offers a range of features to assist users in preparing for technical interviews, including mock interviews, real-time feedback, and personalized study plans. With BugFree.ai, users can improve their problem-solving skills and gain confidence in tackling complex interview questions.

HUAWEI Cloud Pangu Drug Molecule Model
HUAWEI Cloud Pangu is an AI tool designed for accelerating drug discovery by optimizing drug molecules. It offers features such as Molecule Search, Molecule Optimizer, and Pocket Molecule Design. Users can submit molecules for optimization and view historical optimization results. The tool is based on the MindSpore framework and has been visited over 300,000 times since August 23, 2021.
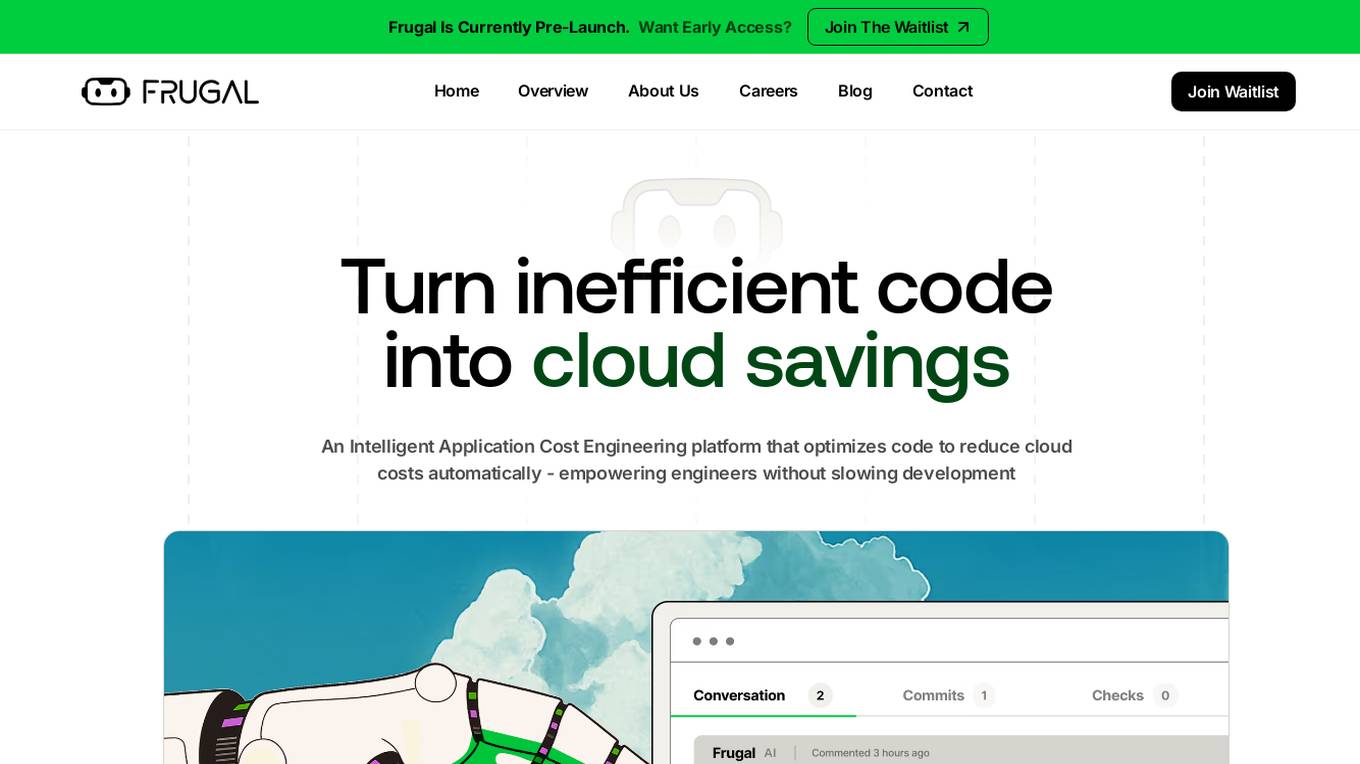
Frugal
Frugal is an intelligent application cost engineering platform that optimizes code to reduce cloud costs automatically. It is the first AI-powered cost optimization platform built for engineers, empowering them to find and fix inefficiencies in code that drain cloud budgets. The platform aims to reinvent cost engineering by enabling developers to reduce application costs and improve cloud efficiency through automated identification and resolution of wasteful practices.
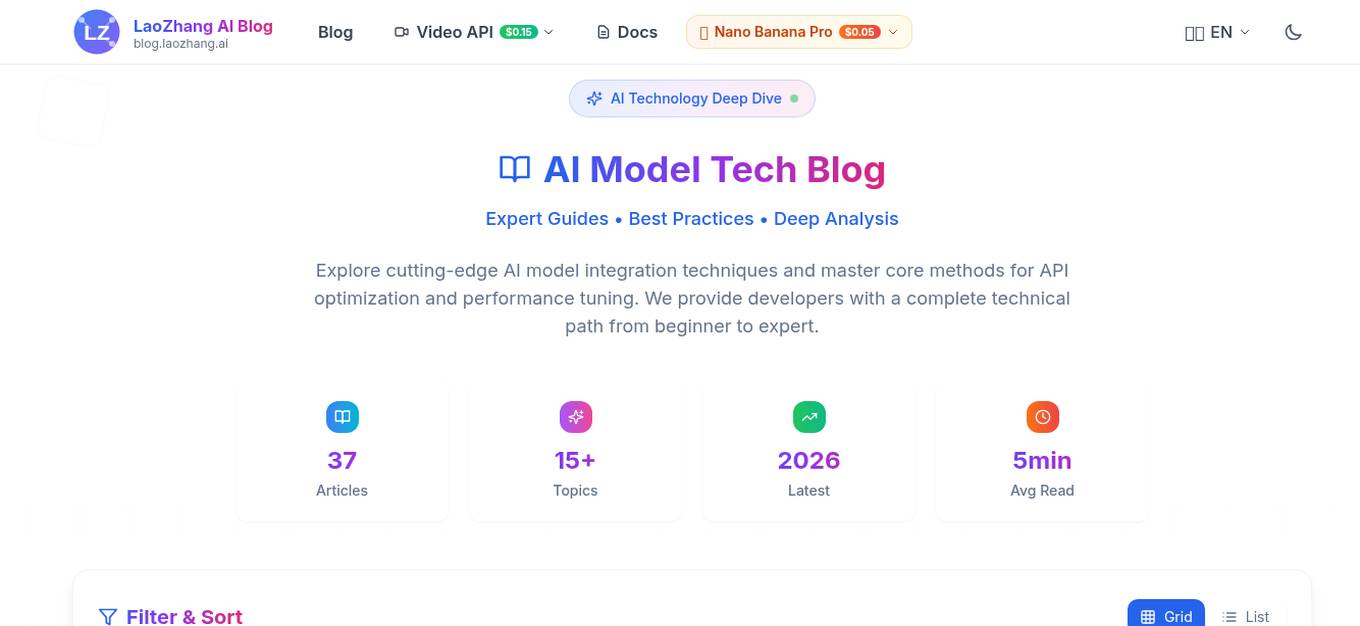
LaoZhang AI Blog
LaoZhang AI Blog is an AI technology blog that offers expert guides, best practices, and deep analysis on cutting-edge AI model integration techniques. Developers can explore and master core methods for API optimization and performance tuning, with a complete technical path from beginner to expert. The blog covers a wide range of topics such as AI video generation, AI tutorials, troubleshooting, API development, and more, providing valuable insights and resources for AI enthusiasts and professionals.
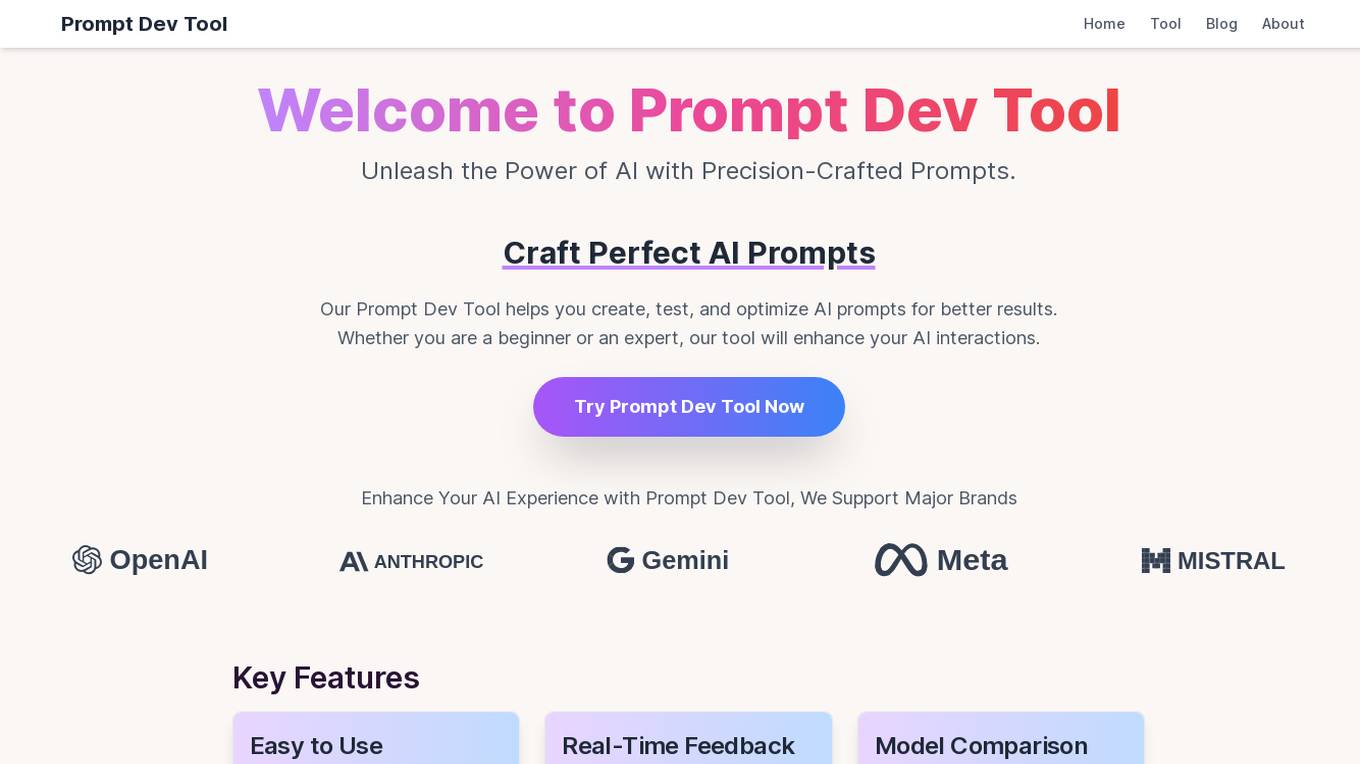
Prompt Dev Tool
Prompt Dev Tool is an AI application designed to boost prompt engineering efficiency by helping users create, test, and optimize AI prompts for better results. It offers an intuitive interface, real-time feedback, model comparison, variable testing, prompt iteration, and advanced analytics. The tool is suitable for both beginners and experts, providing detailed insights to enhance AI interactions and improve outcomes.

Wallaroo.AI
Wallaroo.AI is an AI inference platform that offers production-grade AI inference microservices optimized on OpenVINO for cloud and Edge AI application deployments on CPUs and GPUs. It provides hassle-free AI inferencing for any model, any hardware, anywhere, with ultrafast turnkey inference microservices. The platform enables users to deploy, manage, observe, and scale AI models effortlessly, reducing deployment costs and time-to-value significantly.
Everseen
Everseen is an AI platform that offers a comprehensive suite of tools for data collection, contextualization, insight discovery, process modeling, video translation, AI reasoning, model engineering, continuous learning, governance, and more. It is designed to help businesses in the retail industry prevent losses, accelerate sales, protect inventory, improve product availability, and ensure process integrity. Everseen's Vision AI Factory supports hyper-scaled applications with value assurance and governance at its core, enabling users to combat retail shrink threats effectively.
Narrow AI
Narrow AI is an AI application that autonomously writes, monitors, and optimizes prompts for any model, enabling users to ship AI features 10x faster at a fraction of the cost. It streamlines the workflow by allowing users to test new models in minutes, compare prompt performance, and deploy on the optimal model for their use case. Narrow AI helps users maximize efficiency by generating expert-level prompts, adapting prompts to new models, and optimizing prompts for quality, cost, and speed.
FineTuneAIs.com
FineTuneAIs.com is a platform that specializes in custom AI model fine-tuning. Users can fine-tune their AI models to achieve better performance and accuracy. The platform requires JavaScript to be enabled for optimal functionality.
1 - Open Source Tools
nncf
Neural Network Compression Framework (NNCF) provides a suite of post-training and training-time algorithms for optimizing inference of neural networks in OpenVINO™ with a minimal accuracy drop. It is designed to work with models from PyTorch, TorchFX, TensorFlow, ONNX, and OpenVINO™. NNCF offers samples demonstrating compression algorithms for various use cases and models, with the ability to add different compression algorithms easily. It supports GPU-accelerated layers, distributed training, and seamless combination of pruning, sparsity, and quantization algorithms. NNCF allows exporting compressed models to ONNX or TensorFlow formats for use with OpenVINO™ toolkit, and supports Accuracy-Aware model training pipelines via Adaptive Compression Level Training and Early Exit Training.
20 - OpenAI Gpts
Shell Mentor
An AI GPT model designed to assist with Shell/Bash programming, providing real-time code suggestions, debugging tips, and script optimization for efficient command-line operations.


Data Architect
Database Developer assisting with SQL/NoSQL, architecture, and optimization.
Optimisateur de Performance GPT
Expert en optimisation de performance et traitement de données


Seabiscuit Business Model Master
Discover A More Robust Business: Craft tailored value proposition statements, develop a comprehensive business model canvas, conduct detailed PESTLE analysis, and gain strategic insights on enhancing business model elements like scalability, cost structure, and market competition strategies. (v1.18)

Create A Business Model Canvas For Your Business
Let's get started by telling me about your business: What do you offer? Who do you serve? ------------------------------------------------------- Need help Prompt Engineering? Reach out on LinkedIn: StephenHnilica

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model
BITE Model Analyzer by Dr. Steven Hassan
Discover if your group, relationship or organization uses specific methods to recruit and maintain control over people