Best AI tools for< Llm Data Scientist >
Infographic
20 - AI tool Sites
Ragobble
Ragobble is an audio to LLM data tool that allows you to easily convert audio files into text data that can be used to train large language models (LLMs). With Ragobble, you can quickly and easily create high-quality training data for your LLM projects.
Firecrawl
Firecrawl is an advanced web crawling and data conversion tool designed to transform any website into clean, LLM-ready markdown. It automates the collection, cleaning, and formatting of web data, streamlining the preparation process for Large Language Model (LLM) applications. Firecrawl is best suited for business websites, documentation, and help centers, offering features like crawling all accessible subpages, handling dynamic content, converting data into well-formatted markdown, and more. It is built by LLM engineers for LLM engineers, providing clean data the way users want it.
LlamaIndex
LlamaIndex is a leading data framework designed for building LLM (Large Language Model) applications. It allows enterprises to turn their data into production-ready applications by providing functionalities such as loading data from various sources, indexing data, orchestrating workflows, and evaluating application performance. The platform offers extensive documentation, community-contributed resources, and integration options to support developers in creating innovative LLM applications.

Derwen
Derwen is an open-source integration platform for production machine learning in enterprise, specializing in natural language processing, graph technologies, and decision support. It offers expertise in developing knowledge graph applications and domain-specific authoring. Derwen collaborates closely with Hugging Face and provides strong data privacy guarantees, low carbon footprint, and no cloud vendor involvement. The platform aims to empower AI engineers and domain experts with quality, time-to-value, and ownership since 2017.
Awan LLM
Awan LLM is an AI tool that offers an Unlimited Tokens, Unrestricted, and Cost-Effective LLM Inference API Platform for Power Users and Developers. It allows users to generate unlimited tokens, use LLM models without constraints, and pay per month instead of per token. The platform features an AI Assistant, AI Agents, Roleplay with AI companions, Data Processing, Code Completion, and Applications for profitable AI-powered applications.
LLM Council
LLM Council is an AI platform that combines multiple frontier Large Language Models to provide accurate, reliable, and unbiased answers through a structured 3-stage deliberation process with anonymous peer review. It offers reduced bias, higher accuracy, transparency, and collaborative intelligence in addressing complex questions across various domains.

LLM Clash
LLM Clash is a web-based application that allows users to compare the outputs of different large language models (LLMs) on a given task. Users can input a prompt and select which LLMs they want to compare. The application will then display the outputs of the LLMs side-by-side, allowing users to compare their strengths and weaknesses.
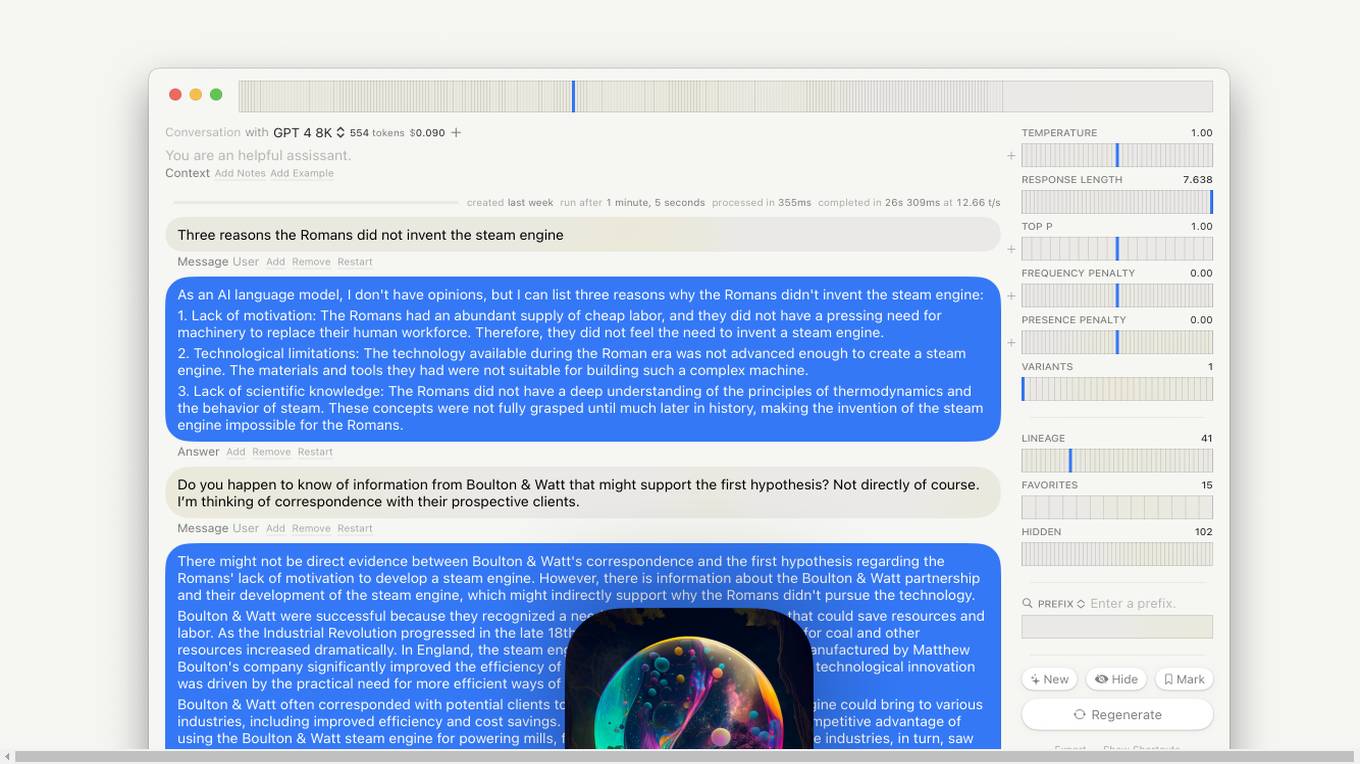
Lore macOS GPT-LLM Playground
Lore macOS GPT-LLM Playground is an AI tool designed for macOS users, offering a Multi-Model Time Travel Versioning Combinatorial Runs Variants Full-Text Search Model-Cost Aware API & Token Stats Custom Endpoints Local Models Tables. It provides a user-friendly interface with features like Syntax, LaTeX Notes Export, Shortcuts, Vim Mode, and Sandbox. The tool is built with Cocoa, SwiftUI, and SQLite, ensuring privacy and offering support & feedback.
LLM Quality Beefer-Upper
LLM Quality Beefer-Upper is an AI tool designed to enhance the quality and productivity of LLM responses by automating critique, reflection, and improvement. Users can generate multi-agent prompt drafts, choose from different quality levels, and upload knowledge text for processing. The application aims to maximize output quality by utilizing the best available LLM models in the market.

LLM Pulse
LLM Pulse is an AI search visibility tracker designed for the AI chatbot world. It provides real-time monitoring of your brand's presence across various AI search engines, allowing you to track key prompts, analyze citations, understand visibility scores, and dive into detailed responses. The platform offers insights effortlessly, suggesting relevant prompts, comparing your brand against competitors, and soon analyzing brand sentiment. With different pricing plans catering to individuals, growing businesses, large organizations, and enterprises, LLM Pulse aims to help users make strategic decisions in the age of AI.
Datasaur
Datasaur is an advanced text and audio data labeling platform that offers customizable solutions for various industries such as LegalTech, Healthcare, Financial, Media, e-Commerce, and Government. It provides features like configurable annotation, quality control automation, and workforce management to enhance the efficiency of NLP and LLM projects. Datasaur prioritizes data security with military-grade practices and offers seamless integrations with AWS and other technologies. The platform aims to streamline the data labeling process, allowing engineers to focus on creating high-quality models.
Dr. Randal S. Olson
Dr. Randal S. Olson is an AI Researcher & Builder known for turning ambitious AI ideas into business wins by bridging the gap between technical promise and real-world impact. His work encompasses data science, AI engineering, and executive strategy. He has worked on various projects in AI, data science, and technology leadership, including the development of the Truesight Expert-grounded AI evaluation platform and the AutoML Tool TPOT. Dr. Olson's focus is on building privacy-first AI solutions that prioritize ethical AI development and user-centric design.

vLLM
vLLM is a fast and easy-to-use library for LLM inference and serving. It offers state-of-the-art serving throughput, efficient management of attention key and value memory, continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and various decoding algorithms. The tool is flexible with seamless integration with popular HuggingFace models, high-throughput serving, tensor parallelism support, and streaming outputs. It supports NVIDIA GPUs and AMD GPUs, Prefix caching, and Multi-lora. vLLM is designed to provide fast and efficient LLM serving for everyone.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.
Allganize
Allganize Inc. is a leading provider of enterprise AI solutions. Their platform enables businesses to build and deploy custom AI applications without the need for coding. Allganize's solutions are used by a variety of industries, including financial services, healthcare, and manufacturing.
LlamaIndex
LlamaIndex is a framework for building context-augmented Large Language Model (LLM) applications. It provides tools to ingest and process data, implement complex query workflows, and build applications like question-answering chatbots, document understanding systems, and autonomous agents. LlamaIndex enables context augmentation by combining LLMs with private or domain-specific data, offering tools for data connectors, data indexes, engines for natural language access, chat engines, agents, and observability/evaluation integrations. It caters to users of all levels, from beginners to advanced developers, and is available in Python and Typescript.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
Picovoice
Picovoice is an on-device Voice AI and local LLM platform designed for enterprises. It offers a range of voice AI and LLM solutions, including speech-to-text, noise suppression, speaker recognition, speech-to-index, wake word detection, and more. Picovoice empowers developers to build virtual assistants and AI-powered products with compliance, reliability, and scalability in mind. The platform allows enterprises to process data locally without relying on third-party remote servers, ensuring data privacy and security. With a focus on cutting-edge AI technology, Picovoice enables users to stay ahead of the curve and adapt quickly to changing customer needs.
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.
Empower
Empower is a serverless fine-tuned LLM hosting platform that offers a developer platform for fine-tuned LLMs. It provides prebuilt task-specific base models with GPT4 level response quality, enabling users to save up to 80% on LLM bills with just 5 lines of code change. Empower allows users to own their models, offers cost-effective serving with no compromise on performance, and charges on a per-token basis. The platform is designed to be user-friendly, efficient, and cost-effective for deploying and serving fine-tuned LLMs.
1 - Open Source Tools
Awesome-Chinese-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, ,'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in less than 3 words,Verb + noun form,in daily spoken language,in lowercase letters).Answer in english languagesname:Awesome-Chinese-LLM readme:# Awesome Chinese LLM   An Awesome Collection for LLM in Chinese 收集和梳理中文LLM相关    自ChatGPT为代表的大语言模型(Large Language Model, LLM)出现以后,由于其惊人的类通用人工智能(AGI)的能力,掀起了新一轮自然语言处理领域的研究和应用的浪潮。尤其是以ChatGLM、LLaMA等平民玩家都能跑起来的较小规模的LLM开源之后,业界涌现了非常多基于LLM的二次微调或应用的案例。本项目旨在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,目前收录的资源已达100+个! 如果本项目能给您带来一点点帮助,麻烦点个⭐️吧~ 同时也欢迎大家贡献本项目未收录的开源模型、应用、数据集等。提供新的仓库信息请发起PR,并按照本项目的格式提供仓库链接、star数,简介等相关信息,感谢~
20 - OpenAI Gpts
DataLearnerAI-GPT
Using OpenLLMLeaderboard data to answer your questions about LLM. For Currently!
PyRefactor
Refactor python code. Python expert with proficiency in data science, machine learning (including LLM apps), and both OOP and functional programming.


Prompt Peerless - Complete Prompt Optimization
Premier AI Prompt Engineer for Advanced LLM Optimization, Enhancing AI-to-AI Interaction and Comprehension. Create -> Optimize -> Revise iteratively
SSLLMs Advisor
Helps you build logic security into your GPTs custom instructions. Documentation: https://github.com/infotrix/SSLLMs---Semantic-Secuirty-for-LLM-GPTs

CISO GPT
Specialized LLM in computer security, acting as a CISO with 20 years of experience, providing precise, data-driven technical responses to enhance organizational security.
![VitalsGPT [V0.0.2.2] Screenshot](/screenshots_gpts/g-cL1rJdm11.jpg)
VitalsGPT [V0.0.2.2]
Simple CustomGPT built on Vitals Inquiry Case in Malta, aimed to help journalists and citizens navigate the inquiry's large dataset in a neutral, informative fashion. Always cross-reference replies to actual data. Do not rely solely on this LLM for verification of facts.
EmotionPrompt(LLM→人間ver.)
EmotionPrompt手法に基づいて作成していますが、本来の理論とは反対に人間に対してLLMがPromptを投げます。本来の手法の詳細:https://ai-data-base.com/archives/58158


Agent Prompt Generator for LLM's
This GPT generates the best possible LLM-agents for your system prompts. You can also specify the model size, like 3B, 33B, 70B, etc.

NEO - Ultimate AI
I imitate GPT-5 LLM, with advanced reasoning, personalization, and higher emotional intelligence