Best AI tools for< Linguistics Researcher >
Infographic
20 - AI tool Sites

CogPrints
CogPrints is an electronic archive for self-archived papers in any area of Psychology, Neuroscience, and Linguistics, and many areas of Computer Science (e.g., artificial intelligence, robotics, vision, learning, speech, neural networks), Philosophy (e.g., mind, language, knowledge, science, logic), Biology (e.g., ethology, behavioral ecology, sociobiology, behavior genetics, evolutionary theory), Medicine (e.g., Psychiatry, Neurology, human genetics, Imaging), Anthropology (e.g., primatology, cognitive ethnology, archeology, paleontology), as well as any other portions of the physical, social and mathematical sciences that are pertinent to the study of cognition.

Austrian Research Institute for Artificial Intelligence
The Austrian Research Institute for Artificial Intelligence (OFAI) is a renowned institute based in Vienna, Austria, with a focus on AI research and development. With over 40 years of excellence in artificial intelligence, OFAI is dedicated to advancing language learning, computational linguistics, and AI applications. The institute collaborates on various projects, software development, and publications, contributing significantly to the field of AI. OFAI's work encompasses a wide range of research areas and resources, aiming to explore the potential of AI in different domains.
Langfuse
Langfuse is an AI tool that offers the Langfuse TypeScript SDK v4 for building and debugging LLM (Large Language Models) applications. It provides features such as tracing, prompt management, evaluation, and metrics to enhance the performance of LLM applications. Langfuse is backed by a team of experts and offers integrations with various platforms and SDKs. The tool aims to simplify the development process of complex LLM applications and improve overall efficiency.

Wolfram|Alpha
Wolfram|Alpha is a computational knowledge engine that answers questions using data, algorithms, and artificial intelligence. It can perform calculations, generate graphs, and provide information on a wide range of topics, including mathematics, science, history, and culture. Wolfram|Alpha is used by students, researchers, and professionals around the world to solve problems, learn new things, and make informed decisions.

Kognitium
Kognitium is an AI assistant designed to provide users with comprehensive and accurate information across various domains. It is equipped with advanced capabilities that enable it to understand the intent behind user inquiries and deliver tailored responses. Kognitium's knowledge base spans a wide range of subjects, including current events, science, history, philosophy, and linguistics. It is designed to be user-friendly and accessible, making it a valuable tool for students, professionals, and anyone seeking to expand their knowledge. Kognitium is committed to providing reliable and actionable insights, empowering users to make informed decisions and enhance their understanding of the world around them.
HumAInism
HumAInism is an AI application that focuses on AI governance, diplomacy, human studies, and the intersection of technology and humanity. It offers tools for explainability, transparency, standards, semantics, probability, aesthetics, and more. The platform aims to explore the ethical, societal, and philosophical implications of AI while providing practical solutions for governance and diplomacy.

NLTK
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike.
Sarvam AI
Sarvam AI is an AI application focused on leading transformative research in AI to develop, deploy, and distribute Generative AI applications in India. The platform aims to build efficient large language models for India's diverse linguistic culture and enable new GenAI applications through bespoke enterprise models. Sarvam AI is also developing an enterprise-grade platform for developing and evaluating GenAI apps, while contributing to open-source models and datasets to accelerate AI innovation.
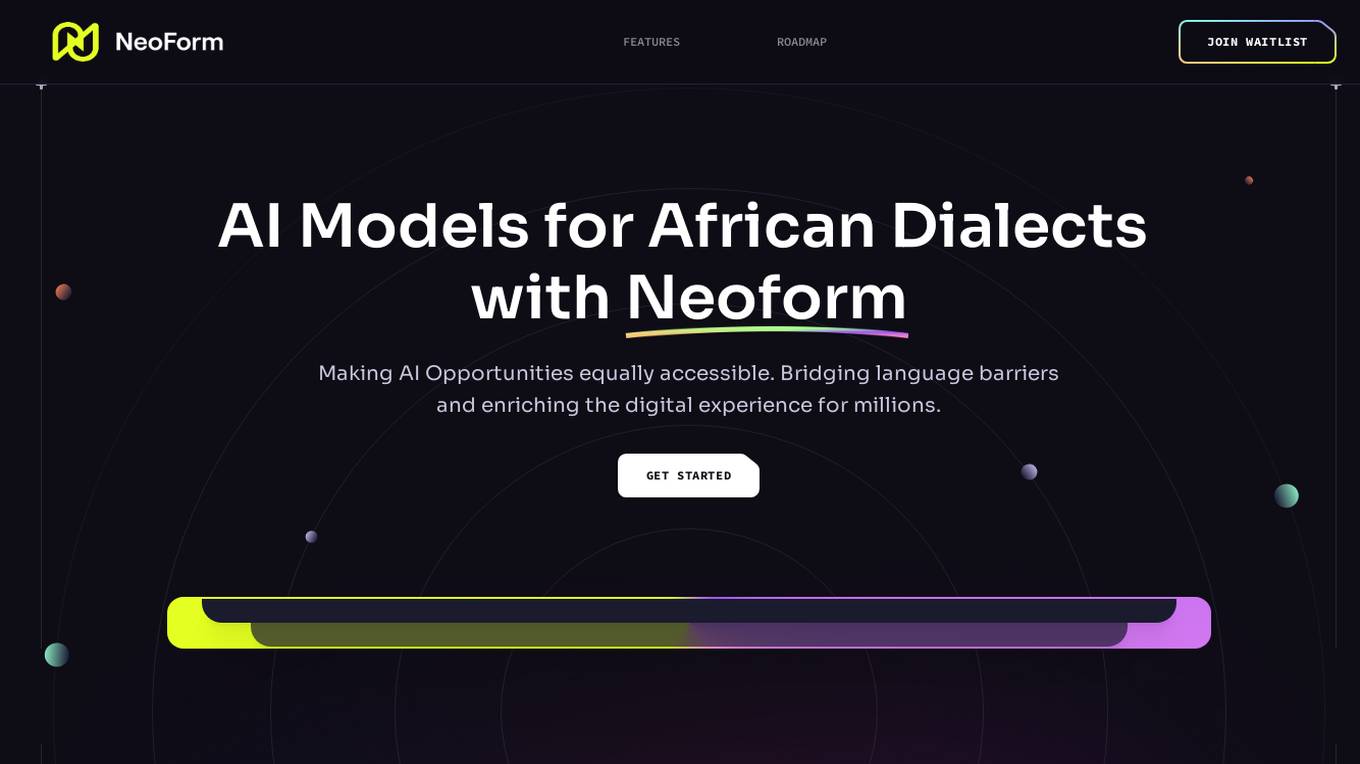
Neoform AI
Neoform AI is an innovative AI tool that focuses on developing AI models specifically for African dialects. The platform aims to bridge the gap in AI technology by providing solutions tailored to the linguistic diversity of Africa. With a commitment to inclusivity and cultural representation, Neoform AI is revolutionizing the field of artificial intelligence by addressing the unique challenges faced by African languages. Through cutting-edge research and development, Neoform AI is paving the way for greater accessibility and accuracy in AI applications across the continent.
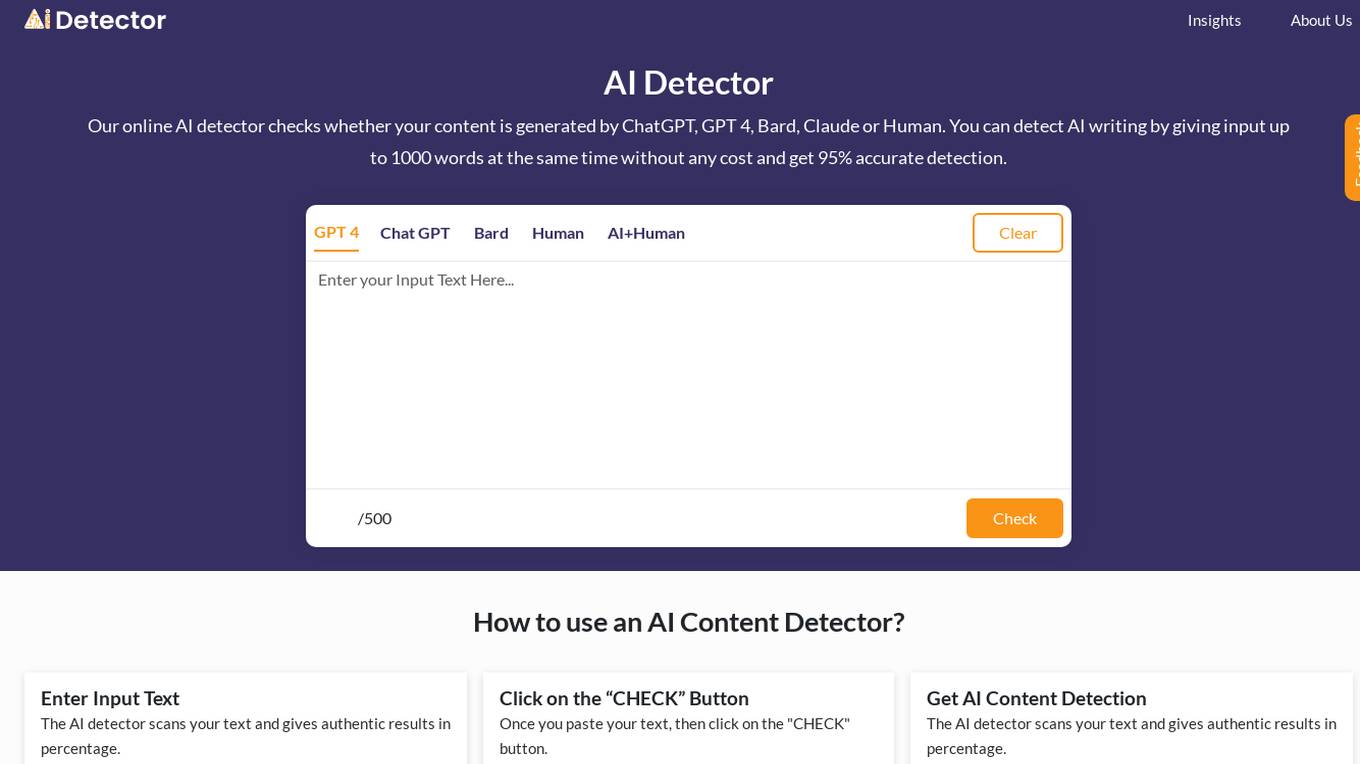
AI Detector
AI Detector is an online tool that uses advanced algorithms and machine learning to check if your written text is generated by AI or a human writer. It analyzes the writing style, sentence structure, and other linguistic patterns to determine the likelihood of AI authorship. The tool provides a percentage score indicating the probability of AI-generated content, helping users identify potential plagiarism or AI-assisted writing.
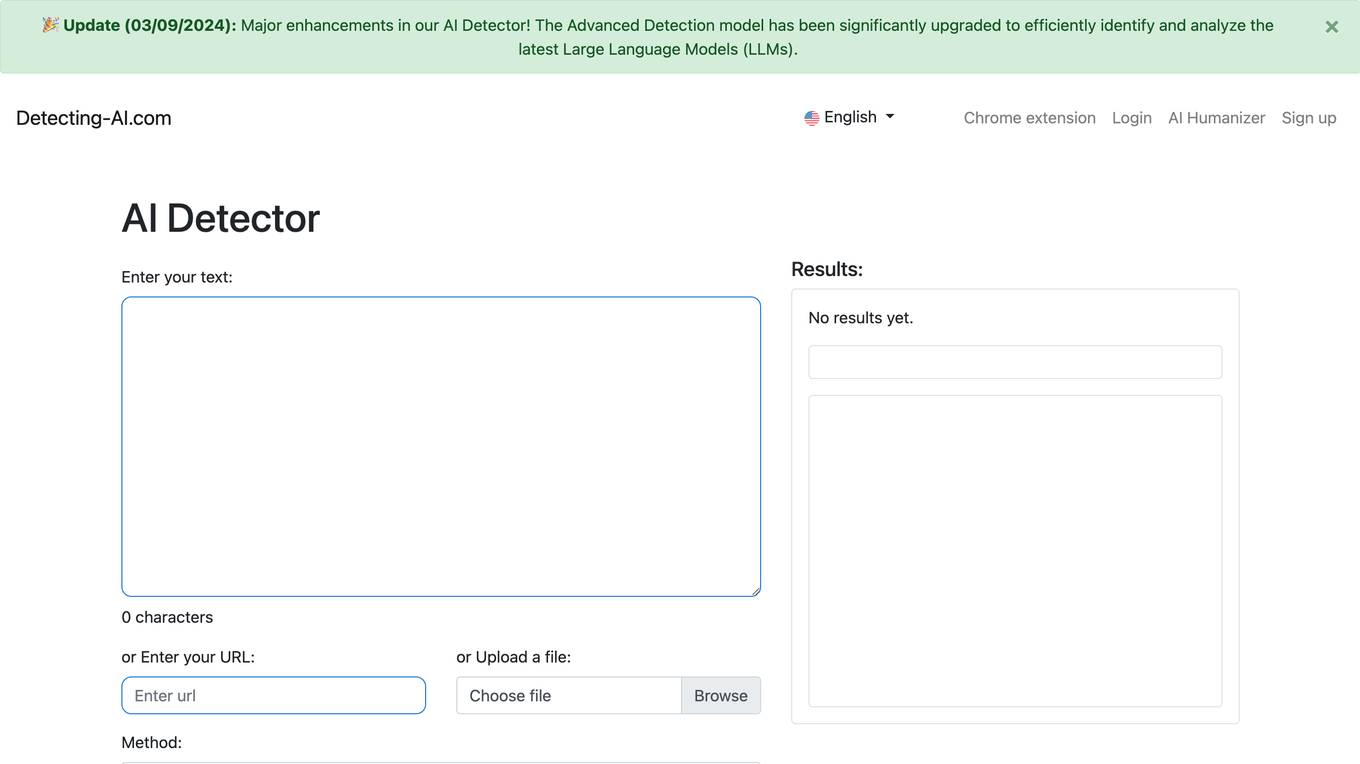
Detecting-AI
Detecting-AI is an advanced AI detection tool that provides accurate identification of AI-generated content in documents. It offers comprehensive insights by analyzing text patterns, sentence structures, and linguistic markers to ensure 99% detection accuracy. The tool is GDPR compliant, ensuring enterprise security for users from 200+ universities across 25+ countries. Detecting-AI is designed to help students, educators, bloggers, researchers, and businesses safeguard their work's integrity and authenticity.
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.
Macgence AI Training Data Services
Macgence is an AI training data services platform that offers high-quality off-the-shelf structured training data for organizations to build effective AI systems at scale. They provide services such as custom data sourcing, data annotation, data validation, content moderation, and localization. Macgence combines global linguistic, cultural, and technological expertise to create high-quality datasets for AI models, enabling faster time-to-market across the entire model value chain. With more than 5 years of experience, they support and scale AI initiatives of leading global innovators by designing custom data collection programs. Macgence specializes in handling AI training data for text, speech, image, and video data, offering cognitive annotation services to unlock the potential of unstructured textual data.
PDF2Quiz
PDF2Quiz is an AI-powered tool that allows users to convert PDF documents into interactive quizzes. Users can upload a PDF, specify the number of questions, select the language, and set the difficulty level to transform the PDF into an engaging quiz. The tool utilizes Optical Character Recognition (OCR) to create quizzes from PDFs with non-selectable text, making it easy for users to assess their knowledge and share quizzes with others. With multilingual quiz conversion capabilities, PDF2Quiz caters to users from various linguistic backgrounds. The tool also offers features such as reviewing scores and answers, challenging users with automatically generated multiple-choice questions, and enabling offline use by saving quizzes and answers as PDFs.
Wolfram
Wolfram is a comprehensive platform that unifies algorithms, data, notebooks, linguistics, and deployment to provide a powerful computation platform. It offers a range of products and services for various industries, including education, engineering, science, and technology. Wolfram is known for its revolutionary knowledge-based programming language, Wolfram Language, and its flagship product Wolfram|Alpha, a computational knowledge engine. The platform also includes Wolfram Cloud for cloud-based services, Wolfram Engine for software implementation, and Wolfram Data Framework for real-world data analysis.
Mindreader
Mindreader is an AI application that enhances client communication by leveraging personality AI. It helps users engage with client personalities better through quizzes, linguistics, and physiognomy. The application ensures success during client research and background analysis by combining psychology, biology, and AI. Mindreader's personality AI minimizes misunderstandings with key decision makers and guarantees effective client communication. It offers a proven profiling framework to identify clients' preferred communication styles, enabling users to build strong relationships effortlessly.

Bay Area AI
Bay Area AI is a technical AI meetup group based in San Francisco, CA, consisting of startup engineers, research scientists, computational linguists, mathematicians, and philosophers. The group focuses on understanding the meaning of text, reasoning, and human intent through technology to build new businesses and enhance the human experience in the modern connected world. They work on building systems with Machine Learning on top of Data Pipelines, exploring open-source solutions, and modeling human behavior in industry for practical results.
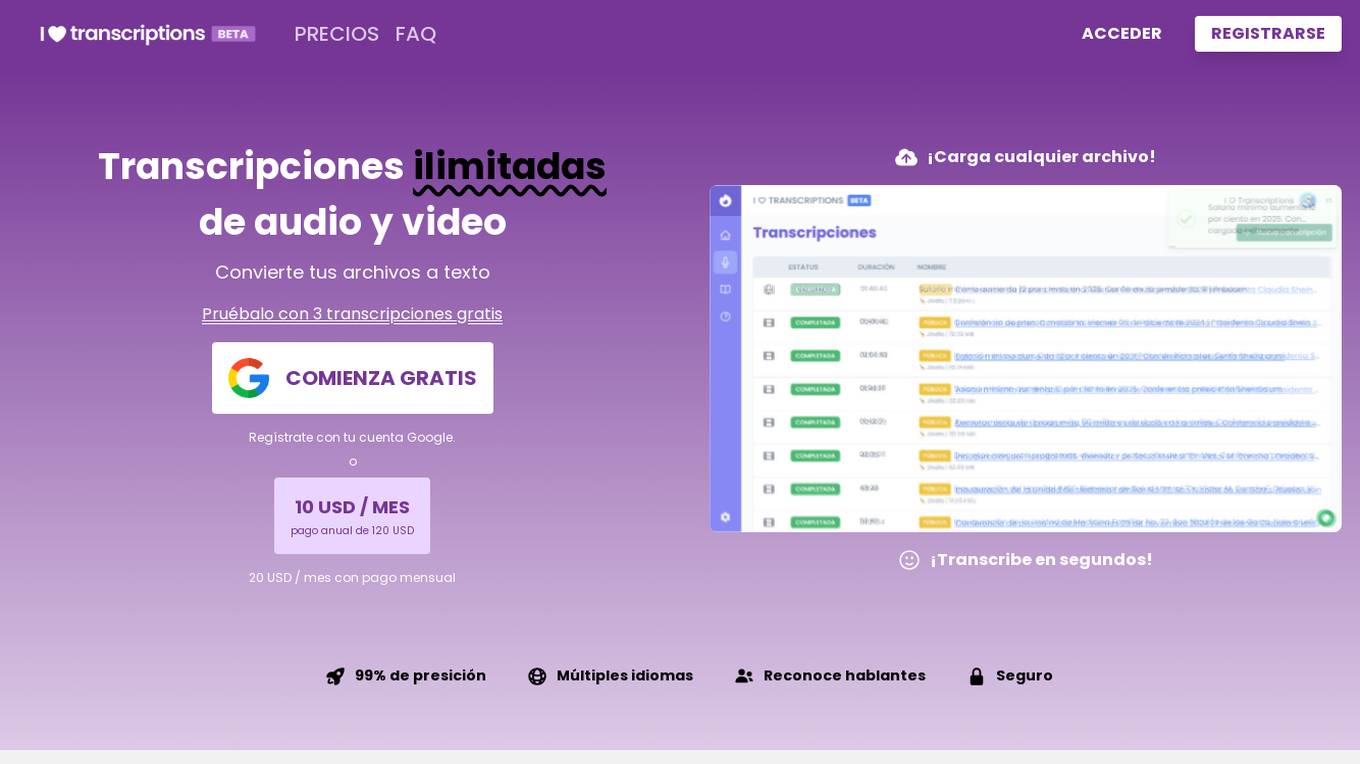
I ♡ Transcriptions
I ♡ Transcriptions is an AI-powered platform that offers unlimited transcription services for audio and video files. It converts files to text in multiple languages with high accuracy. The platform was created to simplify transcription technology and make it accessible and affordable for users who need to transcribe content with high quality. It supports popular file formats, provides secure data handling, and offers features like speaker recognition and translation. The platform is developed by Jose María Campaña, a full-stack developer, and Tania Campaña, a linguistics doctor, with the vision of making transcription technology truly useful for everyone.
NeuroSpell
NeuroSpell is a universal auto-corrector powered by deep learning. It can be used to correct spelling, grammar, and style errors in text. NeuroSpell can be deployed on-premise or in the cloud, and it can be trained on domain-specific vocabulary and sentence structures. NeuroSpell is used by businesses and individuals to improve the quality of their written communication.
ChatGPT Italiano
ChatGPT Italiano is a free, no-registration-required AI chatbot that utilizes the ChatGPT-3.5 and ChatGPT-4 language models. It can comprehend and analyze complex, in-depth issues that humans cannot, along with exceptional capabilities such as: Response speed: This online chatbot impresses with its instant response speed on the browser of many different search engines, including Google, Bing, etc. Content quality: All content information provided is accurate, not exaggerated. The quality of the output content in natural language is presented in a coherent and fluent manner. Language support: Although primarily operating in Italian, this chatbot can still support multilingual users for translation, Q&A.
4 - Open Source Tools

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.
Korean-SAT-LLM-Leaderboard
The Korean SAT LLM Leaderboard is a benchmarking project that allows users to test their fine-tuned Korean language models on a 10-year dataset of the Korean College Scholastic Ability Test (CSAT). The project provides a platform to compare human academic ability with the performance of large language models (LLMs) on various question types to assess reading comprehension, critical thinking, and sentence interpretation skills. It aims to share benchmark data, utilize a reliable evaluation dataset curated by the Korea Institute for Curriculum and Evaluation, provide annual updates to prevent data leakage, and promote open-source LLM advancement for achieving top-tier performance on the Korean CSAT.
wordsea
WordSea is a SvelteKit web application that aims to enhance English vocabulary learning by utilizing mnemonic techniques to associate words with visual representations. It addresses the challenge of memorizing abstract concepts by generating definition-based visualizations using LLMs and Text-to-Image models. The visualizations are combined with word definitions, IPA pronunciation, audio recordings, and derivative information to create comprehensive word cards.
heretic
Heretic is a tool that removes censorship from transformer-based language models without expensive post-training. It combines directional ablation with a TPE-based parameter optimizer to automatically find high-quality abliteration parameters. Users can easily decensor language models without needing to understand transformer internals. Heretic supports most dense models and provides features for research into model semantics. The tool offers flexible ablation weight kernels and separate ablation parameters for different components, improving compliance/quality tradeoff. Heretic was developed from scratch and does not reuse code from other projects.
20 - OpenAI Gpts


Dialect Detective
Expert in distinguishing language dialects like Castilian vs Latin Spanish, and Parisian vs Canadian French.
Evolutionary Muse
Interprets creative, cryptic linguistic styles with a focus on survival and evolutionary concepts.
Word Etymology
Uncover the fascinating journeys of words with Word Etymology, your expert guide to linguistic treasures!

Language Mind Maps
Master language complexities with tailored mind maps that enhance understanding and bolster memory. Explore linguistic patterns in a visually engaging way. 🧠🗺️

이름 해석 마스터 GPT
'이름 해석 마스터 GPT'는 개인 이름이나 지명 등의 언어학적 의미와 기원을 해석해주는 전문 AI입니다. 이 AI는 다양한 문화와 언어 배경에서 온 이름을 분석하여, 그 이름이 가진 의미, 역사적 배경, 문화적 상징성 등을 제공합니다. 사용자가 이름을 입력하면, 해당 이름의 언어학적 특징과 기원, 그리고 가능한 의미를 설명해 줍니다. 이를 통해 사용자는 자신의 이름이나 관심 있는 이름에 대한 더 깊은 이해를 얻을 수 있습니다.
Academic Introduction Writer
Writing tool that combines linguistics and artificial intelligence, who knows how to use it well!
Xenoverse Explorer
Sophisticated AI creating diverse alien worlds with a focus on xenobiology and linguistics.