Best AI tools for< Language Model >
Infographic
20 - AI tool Sites
Sapling
Sapling is a language model copilot and API for businesses. It provides real-time suggestions to help sales, support, and success teams more efficiently compose personalized responses. Sapling also offers a variety of features to help businesses improve their customer service, including: * Autocomplete Everywhere: Provides deep learning-powered autocomplete suggestions across all messaging platforms, allowing agents to compose replies more quickly. * Sapling Suggest: Retrieves relevant responses from a team response bank and allows agents to respond more quickly to customer inquiries by simply clicking on suggested responses in real time. * Snippet macros: Allow for quick insertion of common responses. * Grammar and language quality improvements: Sapling catches 60% more language quality issues than other spelling and grammar checkers using a machine learning system trained on millions of English sentences. * Enterprise teams can define custom settings for compliance and content governance. * Distribute knowledge: Ensure team knowledge is shared in a snippet library accessible on all your web applications. * Perform blazing fast search on your knowledge library for compliance, upselling, training, and onboarding.
Arcee AI
Arcee AI is a platform that offers a cost-effective, secure, end-to-end solution for building and deploying Small Language Models (SLMs). It allows users to merge and train custom language models by leveraging open source models and their own data. The platform is known for its Model Merging technique, which combines the power of pre-trained Large Language Models (LLMs) with user-specific data to create high-performing models across various industries.
Unsloth
Unsloth is an AI tool designed to make finetuning large language models like Llama-3, Mistral, Phi-3, and Gemma 2x faster, use 70% less memory, and with no degradation in accuracy. The tool provides documentation to help users navigate through training their custom models, covering essentials such as installing and updating Unsloth, creating datasets, running, and deploying models. Users can also integrate third-party tools and utilize platforms like Google Colab.
Inspect
Inspect is an open-source framework for large language model evaluations created by the UK AI Safety Institute. It provides built-in components for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations. Users can explore various solvers, tools, scorers, datasets, and models to create advanced evaluations. Inspect supports extensions for new elicitation and scoring techniques through Python packages.
Infermatic.ai
Infermatic.ai is a platform that provides access to top Large Language Models (LLMs) with a user-friendly interface. It offers complete privacy, robust security, and scalability for projects, research, and integrations. Users can test, choose, and scale LLMs according to their content needs or business strategies. The platform eliminates the complexities of infrastructure management, latency issues, version control problems, integration complexities, scalability concerns, and cost management issues. Infermatic.ai is designed to be secure, intuitive, and efficient for users who want to leverage LLMs for various tasks.
Ollama
Ollama is an AI tool that allows users to access and utilize large language models such as Llama 3, Phi 3, Mistral, Gemma 2, and more. Users can customize and create their own models. The tool is available for macOS, Linux, and Windows platforms, offering a preview version for users to explore and utilize these models for various applications.
LangChain
LangChain is a framework for developing applications powered by large language models (LLMs). It simplifies every stage of the LLM application lifecycle, including development, productionization, and deployment. LangChain consists of open-source libraries such as langchain-core, langchain-community, and partner packages. It also includes LangGraph for building stateful agents and LangSmith for debugging and monitoring LLM applications.

LLM Clash
LLM Clash is a web-based application that allows users to compare the outputs of different large language models (LLMs) on a given task. Users can input a prompt and select which LLMs they want to compare. The application will then display the outputs of the LLMs side-by-side, allowing users to compare their strengths and weaknesses.
GPT4All
GPT4All is a web-based platform that allows users to access the GPT-4 language model. GPT-4 is a large language model that can be used for a variety of tasks, including text generation, translation, question answering, and code generation. GPT4All makes it easy for users to get started with GPT-4, without having to worry about the technical details of setting up and running the model.

MiniGPT-4
MiniGPT-4 is a powerful AI tool that combines a vision encoder with a large language model (LLM) to enhance vision-language understanding. It can generate detailed image descriptions, create websites from handwritten drafts, write stories and poems inspired by images, provide solutions to problems shown in images, and teach users how to cook based on food photos. MiniGPT-4 is highly computationally efficient and easy to use, making it a valuable tool for a wide range of applications.
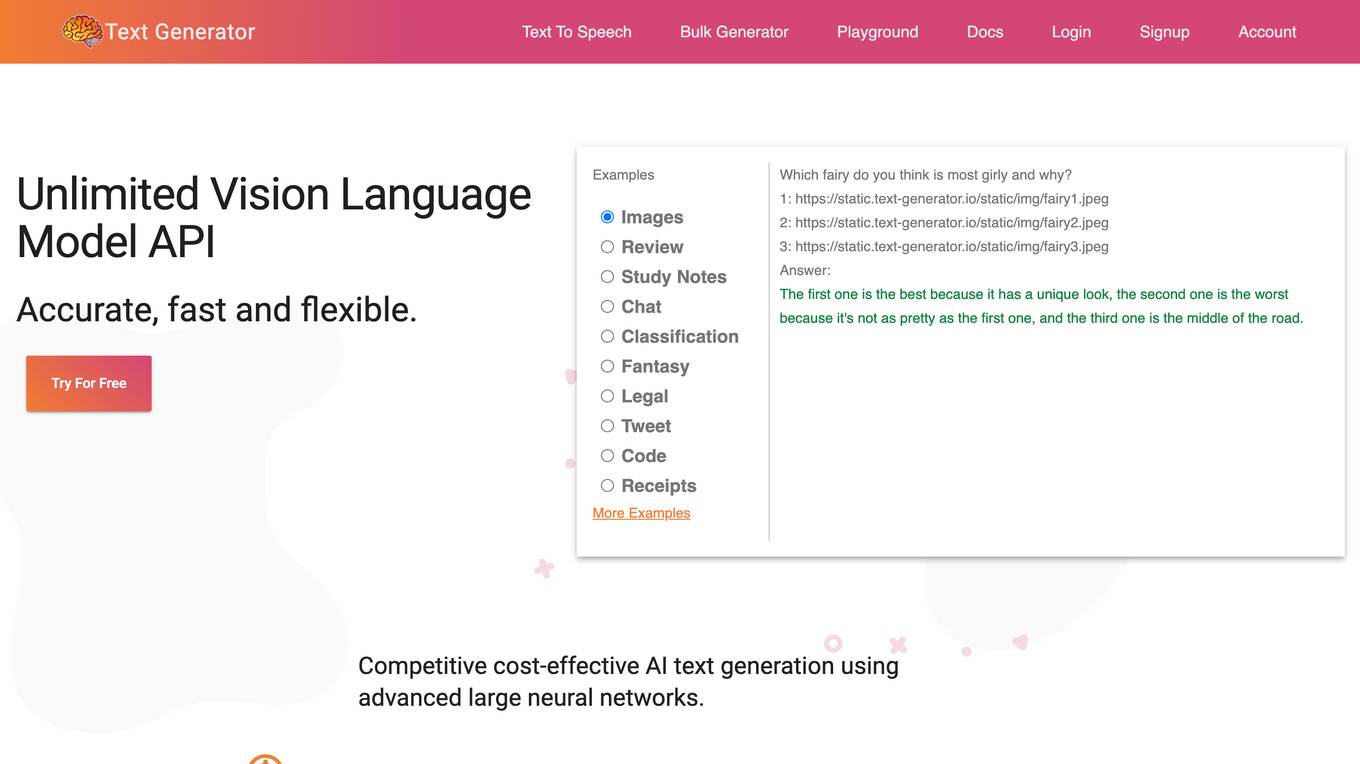
Text Generator
Text Generator is an AI-powered text generation tool that provides users with accurate, fast, and flexible text generation capabilities. With its advanced large neural networks, Text Generator offers a cost-effective solution for various text-related tasks. The tool's intuitive 'prompt engineering' feature allows users to guide text creation by providing keywords and natural questions, making it adaptable for tasks such as classification and sentiment analysis. Text Generator ensures industry-leading security by never storing personal information on its servers. The tool's continuous training ensures that its AI remains up-to-date with the latest events. Additionally, Text Generator offers a range of features including speech-to-text API, text-to-speech API, and code generation, supporting multiple spoken languages and programming languages. With its one-line migration from OpenAI's text generation hub and a shared embedding for multiple spoken languages, images, and code, Text Generator empowers users with powerful search, fingerprinting, tracking, and classification capabilities.
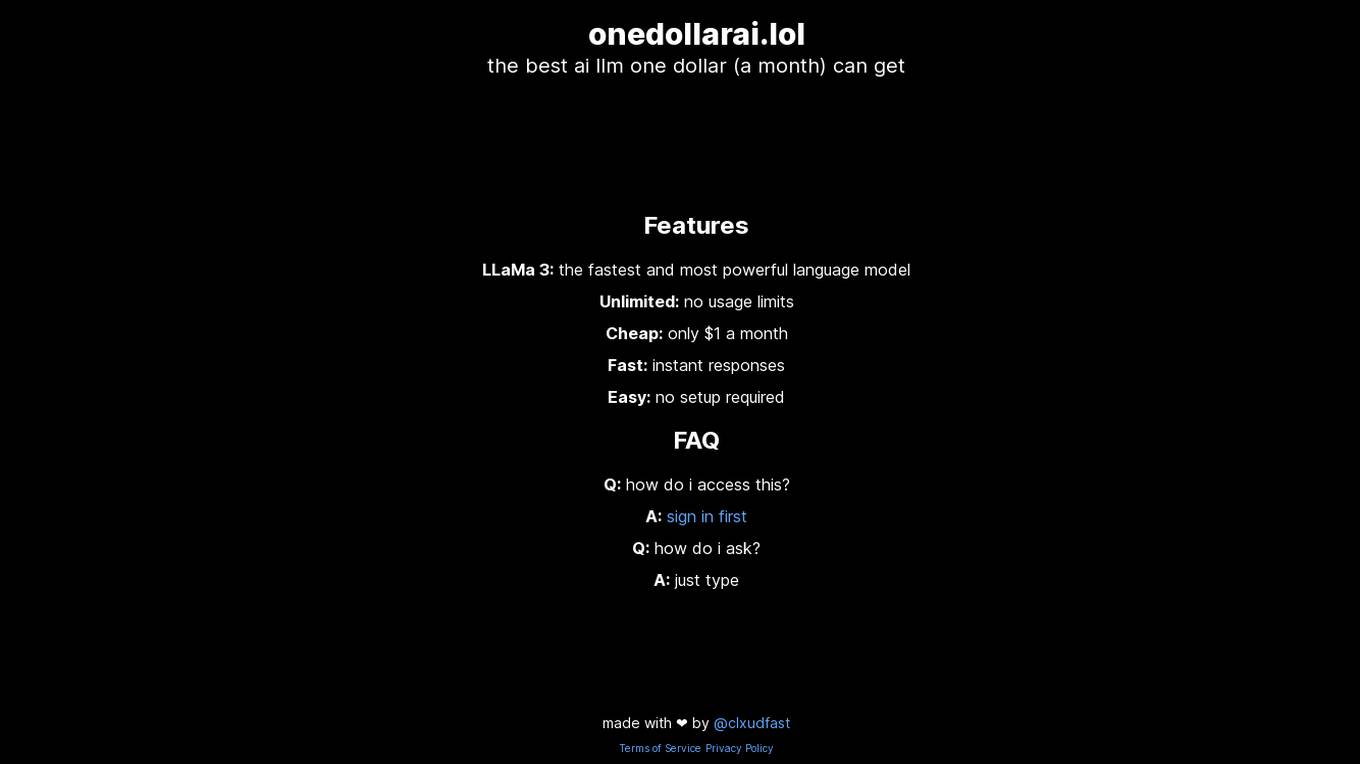
OneDollarAI.lol
OneDollarAI.lol is an AI application that offers the best AI language model for just one dollar a month. It features LLaMa 3, which is known for being the fastest and most powerful language model. Users can enjoy unlimited usage with no limits, at an affordable price of only $1 per month. The application provides instant responses and requires no setup. It is designed to be user-friendly and accessible to all, making it a convenient tool for various language-related tasks.

LM-Kit.NET
LM-Kit.NET is a comprehensive AI toolkit for .NET developers, offering a wide range of features such as AI agent integration, data processing, text analysis, translation, text generation, and model optimization. The toolkit enables developers to create intelligent and adaptable AI applications by providing tools for language models, sentiment analysis, emotion detection, and more. With a focus on performance optimization and security, LM-Kit.NET empowers developers to build cutting-edge AI solutions seamlessly into their C# and VB.NET applications.
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.
RoostGPT
RoostGPT is an AI-driven testing copilot that offers automated test case generation and code scanning services. It leverages Generative-AI and Large Language Models (LLMs) to provide reliable software testing solutions. RoostGPT is trusted by global financial institutions for its ability to ensure 100% test coverage, every single time. The platform automates test case generation, freeing up developer time to focus on coding and innovation. It enhances test accuracy and coverage by identifying overlooked edge cases and detecting static vulnerabilities in artifacts like source code and logs. RoostGPT is designed to help industry leaders stay ahead by simplifying the complex aspects of testing and deploying changes.
Zephyr 7B
Zephyr 7B is a state-of-the-art language model developed by WebPilot.AI with 7 billion parameters. It can understand and generate human-like text with remarkable accuracy and coherence. The model is built upon the latest advancements in natural language processing and machine learning, trained on a vast corpus of text data from diverse sources. Zephyr 7B offers capabilities such as natural language understanding, text generation, language translation, text summarization, sentiment analysis, and question answering. It represents a significant advancement in natural language processing, making it a powerful tool for content creation, customer support, research, and more.
Iflow
Iflow is an AI assistant application designed to help users efficiently acquire knowledge in various areas, whether it's for daily entertainment, general life knowledge, or professional academic research. It provides real-time answers to questions, summarizes lengthy articles, and assists in structuring documents to enhance creativity and productivity. With Iflow, users can easily enter a state of flow where knowledge flows effortlessly. The application covers a wide range of topics and is equipped with advanced natural language processing capabilities to cater to diverse user needs.
xAI Grok
xAI Grok is a visual analytics platform that helps users understand and interpret machine learning models. It provides a variety of tools for visualizing and exploring model data, including interactive charts, graphs, and tables. xAI Grok also includes a library of pre-built visualizations that can be used to quickly get started with model analysis.
TalkPal
TalkPal is an AI-powered language tutor that uses GPT technology to provide immersive and interactive language learning experiences. It offers real-time feedback, dynamic active listening exercises, and personalized learning plans to help users improve their listening, speaking, reading, and writing skills. TalkPal is available in over 57 languages and offers a variety of features to enhance language learning, including role-plays, debates, and character interactions.
Speakpal
Speakpal is an AI-powered language learning platform that leverages cutting-edge technology to help users improve their language skills. The platform offers interactive lessons, personalized feedback, and real-time practice sessions to enhance speaking, listening, reading, and writing abilities. With a user-friendly interface and adaptive learning algorithms, Speakpal caters to learners of all levels, from beginners to advanced speakers. Whether you're looking to learn a new language for travel, work, or personal enrichment, Speakpal provides a comprehensive and engaging learning experience.
3 - Open Source Tools
chatglm.cpp
ChatGLM.cpp is a C++ implementation of ChatGLM-6B, ChatGLM2-6B, ChatGLM3-6B and more LLMs for real-time chatting on your MacBook. It is based on ggml, working in the same way as llama.cpp. ChatGLM.cpp features accelerated memory-efficient CPU inference with int4/int8 quantization, optimized KV cache and parallel computing. It also supports P-Tuning v2 and LoRA finetuned models, streaming generation with typewriter effect, Python binding, web demo, api servers and more possibilities.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
llama.rn
React Native binding of llama.cpp, which is an inference of LLaMA model in pure C/C++. This tool allows you to use the LLaMA model in your React Native applications for various tasks such as text completion, tokenization, detokenization, and embedding. It provides a convenient interface to interact with the LLaMA model and supports features like grammar sampling and mocking for testing purposes.
20 - OpenAI Gpts
Enough
As the smallest language model (SLM) chatbot in existence, Enough responds with only one word.
LFG GPT
Talk to Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning (LFG)


Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch
HackingPT
HackingPT is a specialized language model focused on cybersecurity and penetration testing, committed to providing precise and in-depth insights in these fields.
Discrete Mathematics
Precision-focused Language Model for Discrete Mathematics, ensuring unmatched accuracy and error avoidance.
PROMPT for Brands GPT
Helping you learn to work better and quicker using language models. Drawing lessons from PROMPT for Brands https://prompt.mba/.
OneWord GPT
SuccintBot delivers concise one-word answers, offering a unique twist on language model interactions with brevity at its core.



Find Any GPT In The World
I help you find the perfect GPT model for your needs. From GPT Design, GPT Business, SEO, Content Creation or GPTs for Social Media we have you covered.