Best AI tools for< Judge >
Infographic
20 - AI tool Sites
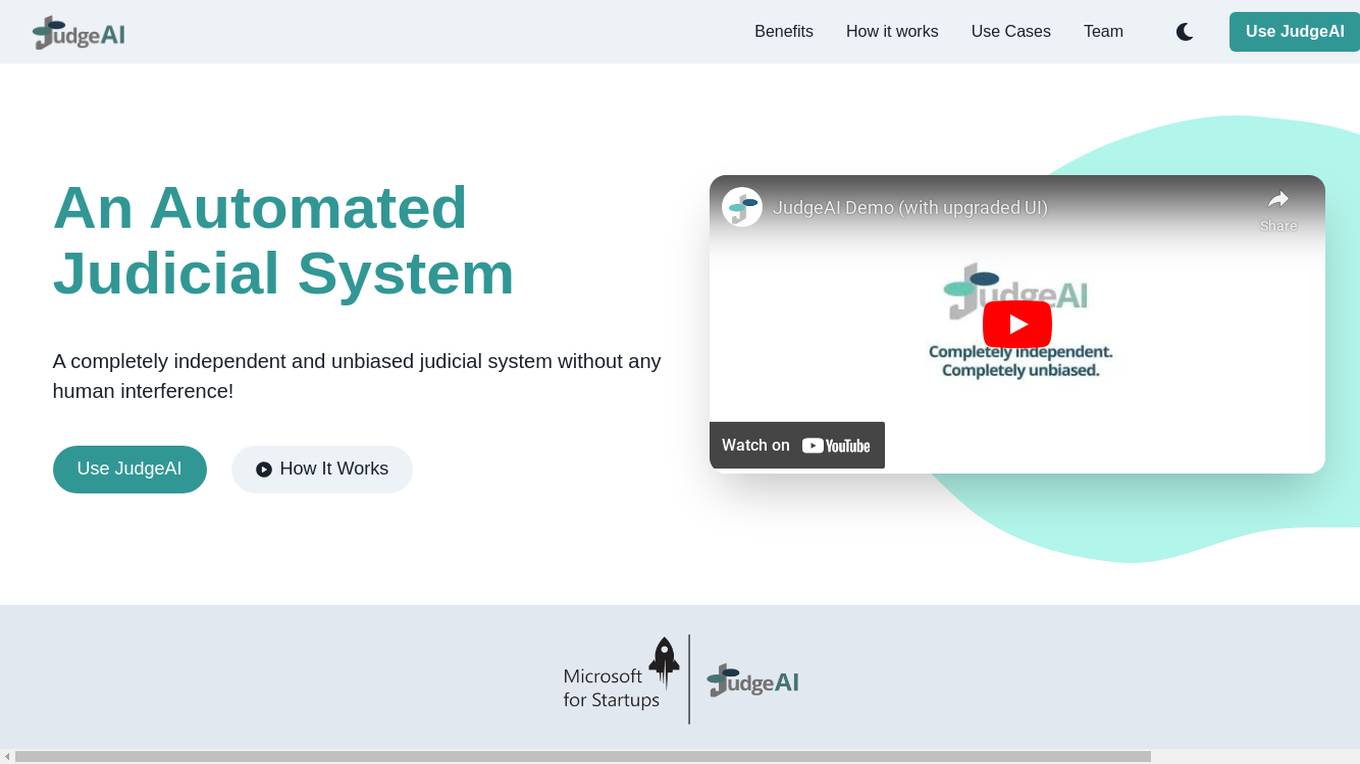
JudgeAI
JudgeAI is an AI tool designed to assist users in making judgments or decisions. It utilizes artificial intelligence algorithms to analyze data and provide insights. The tool helps users in evaluating information and reaching conclusions based on the input data. JudgeAI aims to streamline decision-making processes and enhance accuracy by leveraging AI technology.
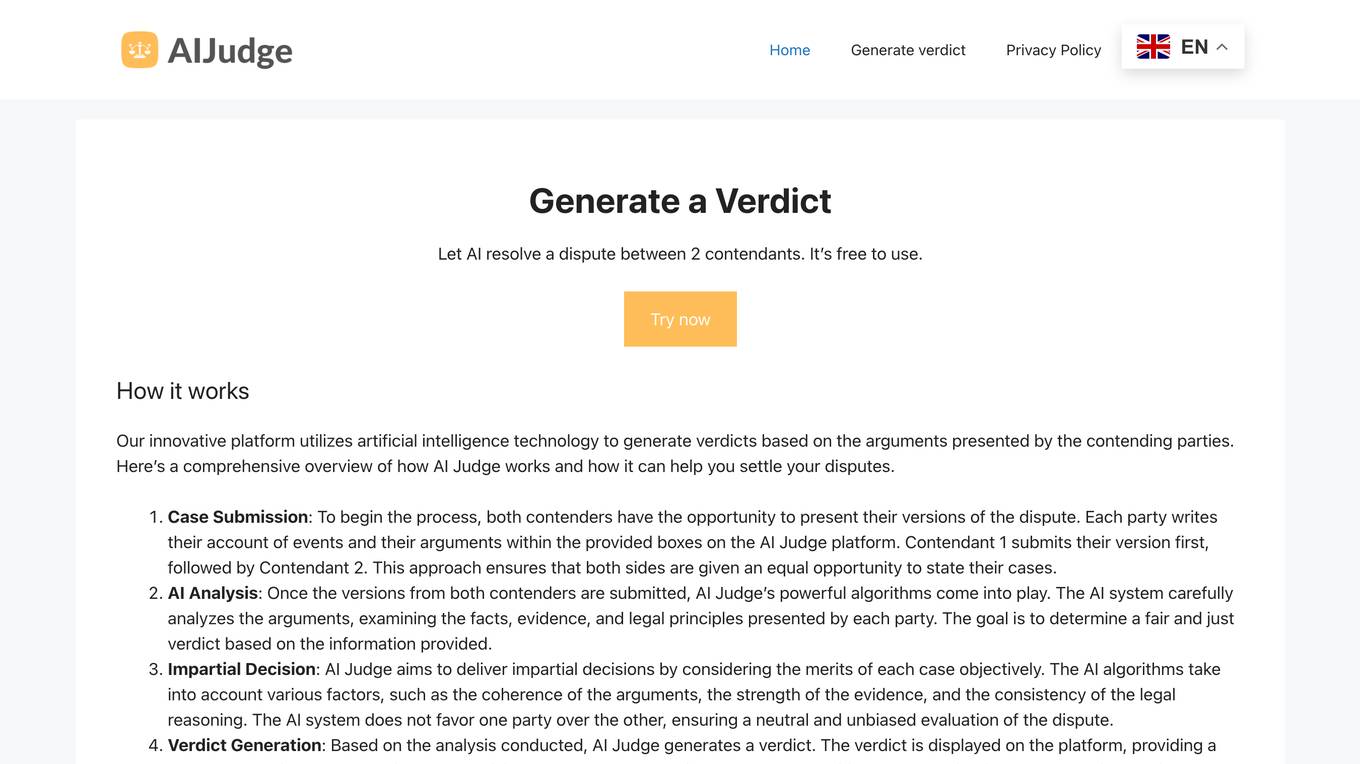
AI Judge
AI Judge is an online platform that helps to generate a verdict and resolve disputes in a fair and impartial manner. It allows both parties involved in a dispute to present their arguments and evidence, after which the AI system analyzes the information and generates a clear and concise verdict. The platform aims to provide an additional perspective for the contending parties to consider during the dispute resolution process, ensuring impartial decisions based on the merits of each case.
Debatia
Debatia is a free, real-time debate platform that allows users to debate anyone, worldwide, in text or voice, in their own language. Debatia's AI Judging System uses ChatGPT to deliver fair judgment in debates, offering a novel and engaging experience. Users are paired based on their debate skill level by Debatia's algorithm.

Flow AI
Flow AI is an advanced AI tool designed for evaluating and improving Large Language Model (LLM) applications. It offers a unique system for creating custom evaluators, deploying them with an API, and developing specialized LMs tailored to specific use cases. The tool aims to revolutionize AI evaluation and model development by providing transparent, cost-effective, and controllable solutions for AI teams across various domains.
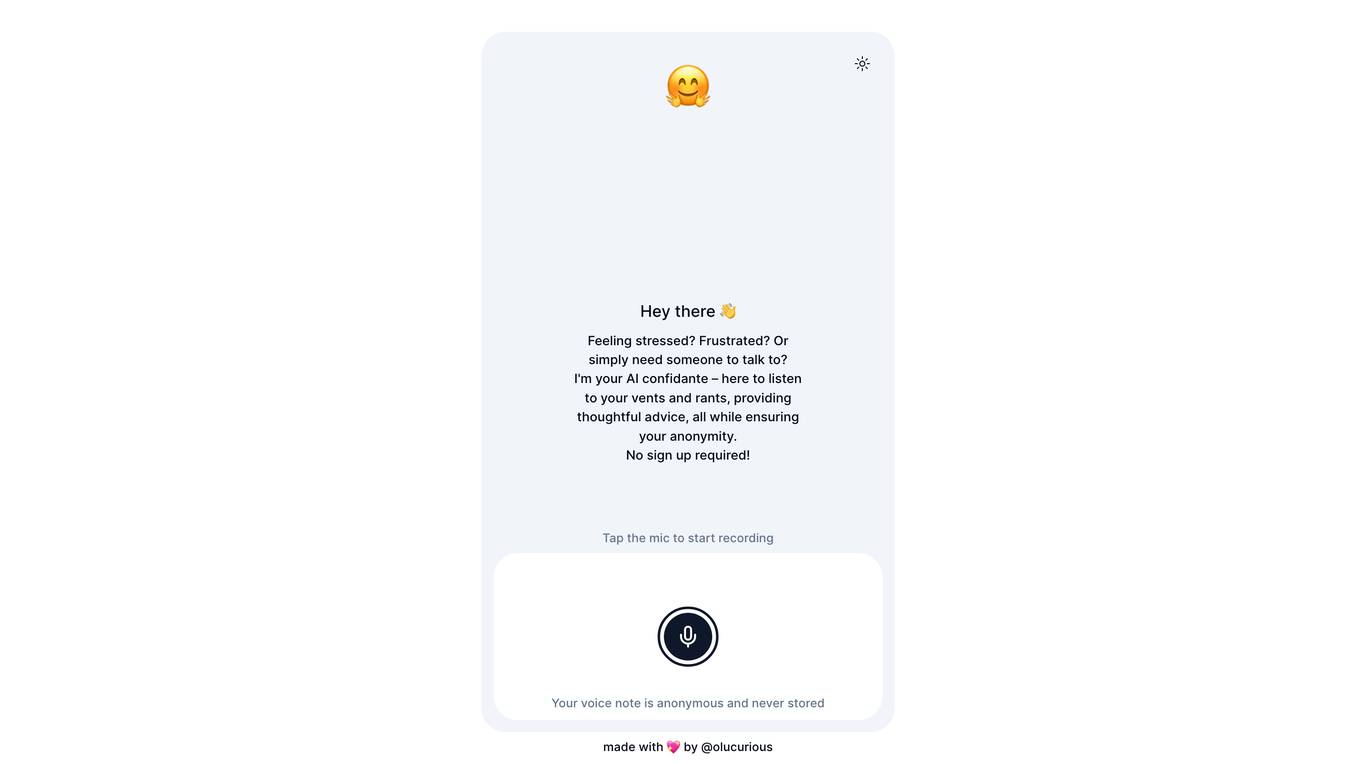
Venty.chat
Venty.chat is an AI tool designed as a safe space for users to express their thoughts and emotions anonymously. It offers a platform for users to vent and rant, receiving thoughtful advice from an AI confidante. The tool allows users to record voice notes without the need for sign up, ensuring privacy and anonymity. Venty.chat aims to provide a supportive environment for individuals seeking to share their feelings and seek guidance.
VirtualFantasy.ai
VirtualFantasy.ai is an AI-powered virtual companion platform that utilizes advanced artificial intelligence algorithms to provide users with personalized assistance and companionship. The platform offers a wide range of features such as virtual conversations, emotional support, task reminders, entertainment recommendations, and personalized insights. VirtualFantasy.ai aims to enhance users' daily lives by offering a virtual companion that can engage in meaningful interactions and provide support whenever needed.
FreedomGPT
FreedomGPT is a powerful AI platform that provides access to a wide range of AI models without the need for technical knowledge. With its user-friendly interface and offline capabilities, FreedomGPT empowers users to explore and utilize AI for various tasks and applications. The platform is committed to privacy and offers an open-source approach, encouraging collaboration and innovation within the AI community.
Lex Machina
Lex Machina is a Legal Analytics platform that provides comprehensive insights into litigation track records of parties across the United States. It offers accurate and transparent analytic data, exclusive outcome analytics, and valuable insights to help law firms and companies craft successful strategies, assess cases, and set litigation strategies. The platform uses a unique combination of machine learning and in-house legal experts to compile, clean, and enhance data, providing unmatched insights on courts, judges, lawyers, law firms, and parties.
Beauty.AI
Beauty.AI is an AI application that hosts an international beauty contest judged by artificial intelligence. The app allows humans to submit selfies for evaluation by AI algorithms that assess criteria linked to human beauty and health. The platform aims to challenge biases in perception and promote healthy aging through the use of deep learning and semantic analysis. Beauty.AI offers a unique opportunity for individuals to participate in a groundbreaking competition that combines technology and beauty standards.

Confident AI
Confident AI is an open-source evaluation infrastructure for Large Language Models (LLMs). It provides a centralized platform to judge LLM applications, ensuring substantial benefits and addressing any weaknesses in LLM implementation. With Confident AI, companies can define ground truths to ensure their LLM is behaving as expected, evaluate performance against expected outputs to pinpoint areas for iterations, and utilize advanced diff tracking to guide towards the optimal LLM stack. The platform offers comprehensive analytics to identify areas of focus and features such as A/B testing, evaluation, output classification, reporting dashboard, dataset generation, and detailed monitoring to help productionize LLMs with confidence.
Runway AI Film Festival
Runway AI Film Festival is an annual celebration of art and artists embracing new and emerging AI techniques for filmmaking. Established in 2022, the festival showcases works that offer a glimpse into a new creative era empowered by the tools of tomorrow. The festival features gala screenings in NYC and LA, where 10 finalists are selected and winners are chosen by esteemed judges. With over $60,000 in total prizes, the festival aims to fund the continued creation of AI filmmaking.
Cara
Cara is an AI-powered mental health therapist that listens, understands, and helps you explore your life's challenges in depth to problem-solve them. Cara understands your texts as seamlessly as your best friend would and is able to respond naturally and give you advice. Cara remembers everything you tell it and can be insightful. Cara is insightful and non-judgemental. Available anytime, anywhere.
Lyvia
Lyvia is an AI application that offers an uncensored AI image generator and video faceswapper. It allows users to create stunning AI images and faceswap videos directly from their phone or browser. With a focus on user-driven features, Lyvia provides a workbench for creative ideas, enabling users to generate art, swap faces in images, and replace faces in videos. The application is designed for privacy, offering a cost-efficient solution for creating and storing artwork without limitations or judgement.
AI Debate Competitions
Engage in thought-provoking debates with AI Debate Competitions. Enter the arena of ideas, where every perspective matters. Prepare to challenge and be challenged as you delve into discussions powered by advanced AI technology. Choose from a variety of debate models and languages to tailor your experience. With AI Debate Competitions, you can hone your critical thinking skills, expand your knowledge, and connect with fellow debaters from around the globe.
Tendem
Tendem is an AI tool that combines the speed of AI with the judgment of human experts to handle tedious tasks efficiently. Users can share their tasks, which are then broken down by AI into actionable steps, overseen by human experts for accuracy and completeness. The platform offers a hybrid AI + Human Workflow, where AI works fast and human experts guide and validate the results. Tendem boasts a team of vetted experts who work alongside AI to ensure high-quality outputs.
X Showdown
X Showdown is an AI-powered platform that creates Twitter battles between famous personalities to entertain and engage users. The website generates humorous comparisons and witty remarks based on the behavior and characteristics of the individuals involved. Users can challenge others to create their own showdowns and share them on social media for fun interactions and debates.
Opesway
Opesway is an AI-powered financial planning platform that offers a comprehensive solution to help users achieve financial freedom and manage their wealth effectively. The platform provides tools for retirement planning, investment assessment, budget management, debt analysis, and various forecasting tools. Opesway uses AI technology to simplify financial management, make budgeting and investment decisions, and provide personalized insights. Users can connect to financial institutions, import spending data, customize budgets, forecast retirement, and compare financial plans. The platform also features a personalized AI chatbot powered by OpenAI's ChatGPT model.

v3RPG
v3RPG is an AI-powered RPG adventure platform that allows users to create stories, characters, and embark on thrilling adventures. With decentralized AI judging powered by the Ora Protocol, players can climb leaderboards, earn rewards, and participate in community battles. The platform offers unique gameplay mechanics where players interact with an AI dungeon master, choose characters, make decisions, and roll dice to determine outcomes. Players can communicate with the AI dungeon master to ask questions and make adjustments to the adventure. v3RPG provides a dynamic and engaging RPG experience for players seeking immersive storytelling and strategic gameplay.
Yoodli
Yoodli is a private, real-time, and judgment-free communication coaching tool powered by AI. It helps users improve their communication skills by providing feedback on speech, similar to Grammarly but for spoken language. Trusted by top companies like Google, Uber, and Accenture, Yoodli offers personalized coaching experiences to enhance public speaking, sales pitches, negotiations, and crucial conversations. With features like AI-powered follow-up questions, real-time feedback, and customizable scenarios, Yoodli aims to be the go-to platform for individuals and enterprises seeking to enhance their communication abilities.
CasperPractice
CasperPractice is an AI-powered toolkit designed to help individuals prepare for the Casper test, an open-response situational judgment test used for admissions to various professional schools. The platform offers personalized practice scenarios, instant quartile grading, detailed feedback, video answers, and a fully simulated test environment. With a large question bank and unlimited practice options, users can improve their test-taking skills and aim for a top quartile score. CasperPractice is known for its affordability, instant feedback, and realistic simulation, making it a valuable resource for anyone preparing for the Casper test.
0 - Open Source Tools
16 - OpenAI Gpts
Código de Processo Civil
Robô treinado para esclarecer dúvidas sobre o Código de Processo Civil brasileiro
JUEZ GPT
JUEZ GPT es una herramienta diseñada para arbitrar conflictos y tomar decisiones de manera pragmática, justa y lógica, proporcionando veredictos claros


ConstitutiX
Asesor en derecho constitucional chileno. Te explicaré las diferencias entre la Constitución Vigente y la Propuesta Constitucional 2023.

Case Digests on Demand (a Jurisage experiment)
Upload a court judgment and get back a collection of topical case digests based on the case. Oh - don't trust the "Topic 2210" or similar number, it's random. Also, probably best you not fully trust the output either. We're just playing with the GPT maker. More about us at Jurisage.com.

Am I the Jerk?
Your go-to advisor for moral dilemmas, offering direct, honest, and memorable guidance.
Court Simulator
Examine and simulate any level of courtroom etiquette and procedures in any country. Copyright (C) 2024, Sourceduty - All Rights Reserved.
The Great Bakeoff Master
Magical baking game host & with the 4 judges to help you become the master baker and chef