Best AI tools for< Gpu Engineer >
Infographic
20 - AI tool Sites
Nscale
Nscale is a full-stack, scalable, and sustainable AI cloud platform that offers a wide range of AI services and solutions. It provides services for developing, training, tuning, and deploying AI models using on-demand services. Nscale also offers serverless inference API endpoints, fine-tuning capabilities, private cloud solutions, and various GPU clusters engineered for AI. The platform aims to simplify the journey from AI model development to production, offering a marketplace for AI/ML tools and resources. Nscale's infrastructure includes data centers powered by renewable energy, high-performance GPU nodes, and optimized networking and storage solutions.
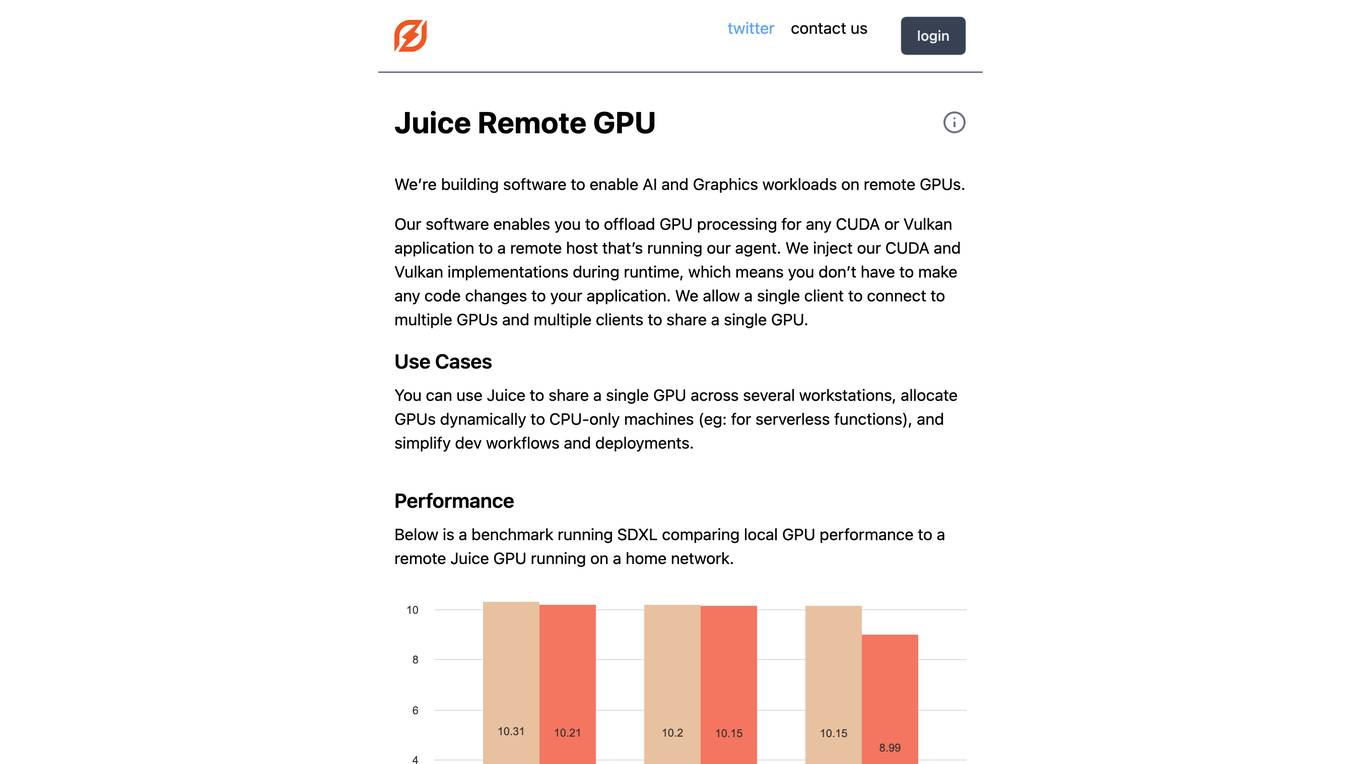
Juice Remote GPU
Juice Remote GPU is a software that enables AI and Graphics workloads on remote GPUs. It allows users to offload GPU processing for any CUDA or Vulkan application to a remote host running the Juice agent. The software injects CUDA and Vulkan implementations during runtime, eliminating the need for code changes in the application. Juice supports multiple clients connecting to multiple GPUs and multiple clients sharing a single GPU. It is useful for sharing a single GPU across multiple workstations, allocating GPUs dynamically to CPU-only machines, and simplifying development workflows and deployments. Juice Remote GPU performs within 5% of a local GPU when running in the same datacenter. It supports various APIs, including CUDA, Vulkan, DirectX, and OpenGL, and is compatible with PyTorch and TensorFlow. The team behind Juice Remote GPU consists of engineers from Meta, Intel, and the gaming industry.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing, providing hardware and software solutions for gaming, entertainment, data centers, edge computing, and more. Their platforms like Jetson and Isaac enable the development and deployment of AI-powered autonomous machines. NVIDIA's AI applications span various industries, from healthcare to manufacturing, and their technology is transforming the world's largest industries and impacting society profoundly.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing. The company's products and services are used by businesses and governments around the world to develop and deploy AI applications. NVIDIA's AI platform includes hardware, software, and tools that make it easy to build and train AI models. The company also offers a range of cloud-based AI services that make it easy to deploy and manage AI applications. NVIDIA's AI platform is used in a wide variety of industries, including healthcare, manufacturing, retail, and transportation. The company's AI technology is helping to improve the efficiency and accuracy of a wide range of tasks, from medical diagnosis to product design.
Cirrascale Cloud Services
Cirrascale Cloud Services is an AI tool that offers cloud solutions for Artificial Intelligence applications. The platform provides a range of cloud services and products tailored for AI innovation, including NVIDIA GPU Cloud, AMD Instinct Series Cloud, Qualcomm Cloud, Graphcore, Cerebras, and SambaNova. Cirrascale's AI Innovation Cloud enables users to test and deploy on leading AI accelerators in one cloud, democratizing AI by delivering high-performance AI compute and scalable deep learning solutions. The platform also offers professional and managed services, tailored multi-GPU server options, and high-throughput storage and networking solutions to accelerate development, training, and inference workloads.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing, providing solutions for cloud services, data center, embedded systems, gaming, and creating graphics cards and GPUs. They offer a wide range of products and services, including AI-driven platforms for life sciences research, end-to-end AI platforms, generative AI deployment, advanced simulation integration, and more. NVIDIA focuses on modernizing data centers with AI and accelerated computing, offering enterprise AI platforms, supercomputers, advanced networking solutions, and professional workstations. They also provide software tools for AI development, data center management, GPU monitoring, and more.
Novita AI
Novita AI is an AI cloud platform offering Model APIs, Serverless, and GPU Instance services in a cost-effective and integrated manner to accelerate AI businesses. It provides optimized models for high-quality dialogue use cases, full spectrum AI APIs for image, video, audio, and LLM applications, serverless auto-scaling based on demand, and customizable GPU solutions for complex AI tasks. The platform also includes a Startup Program, 24/7 service support, and has received positive feedback for its reasonable pricing and stable services.
Nebius AI
Nebius AI is an AI-centric cloud platform designed to handle intensive workloads efficiently. It offers a range of advanced features to support various AI applications and projects. The platform ensures high performance and security for users, enabling them to leverage AI technology effectively in their work. With Nebius AI, users can access cutting-edge AI tools and resources to enhance their projects and streamline their workflows.
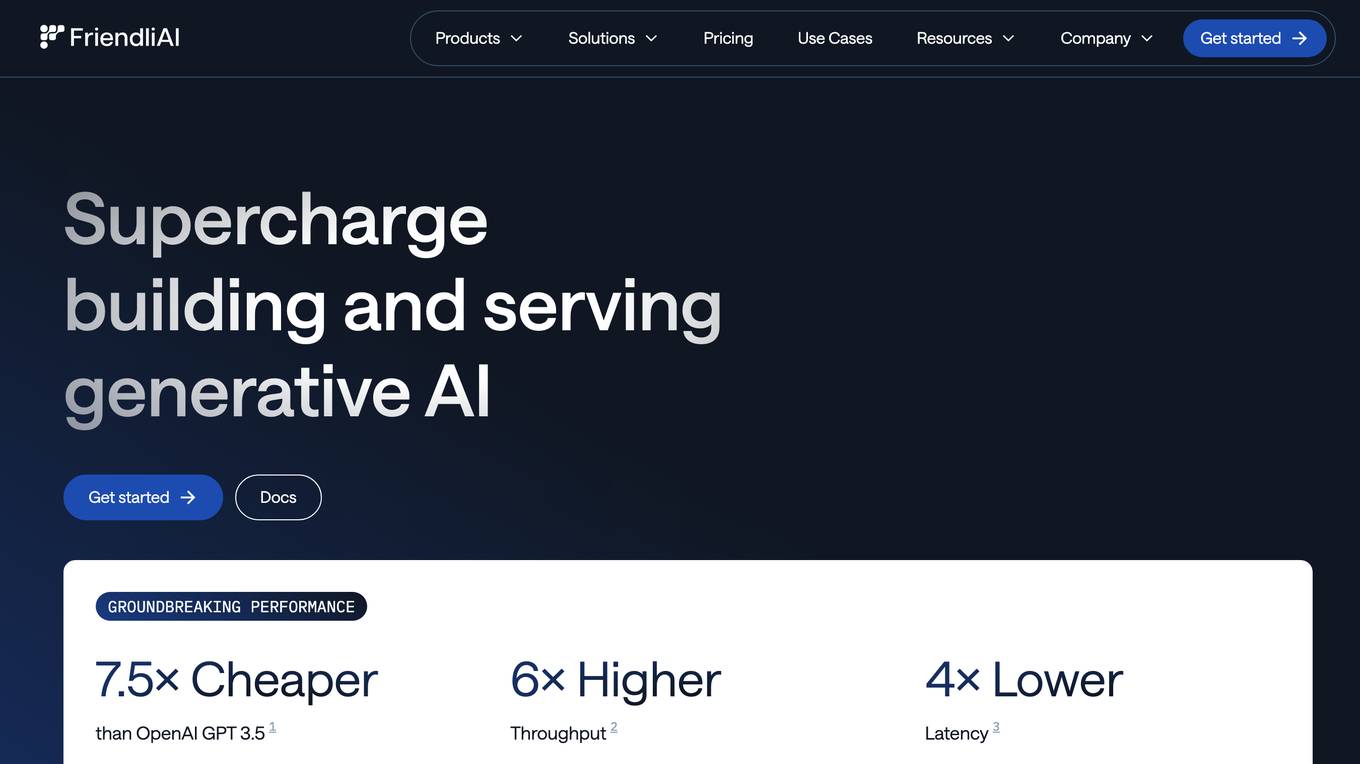
FriendliAI
FriendliAI is a generative AI infrastructure company that offers efficient, fast, and reliable generative AI inference solutions for production. Their cutting-edge technologies enable groundbreaking performance improvements, cost savings, and lower latency. FriendliAI provides a platform for building and serving compound AI systems, deploying custom models effortlessly, and monitoring and debugging model performance. The application guarantees consistent results regardless of the model used and offers seamless data integration for real-time knowledge enhancement. With a focus on security, scalability, and performance optimization, FriendliAI empowers businesses to scale with ease.
NVIDIA Run:ai
NVIDIA Run:ai is an enterprise platform for AI workloads and GPU orchestration. It accelerates AI and machine learning operations by addressing key infrastructure challenges through dynamic resource allocation, comprehensive AI life-cycle support, and strategic resource management. The platform significantly enhances GPU efficiency and workload capacity by pooling resources across environments and utilizing advanced orchestration. NVIDIA Run:ai provides unparalleled flexibility and adaptability, supporting public clouds, private clouds, hybrid environments, or on-premises data centers.

Lambda Docs
Lambda Docs is an AI tool that provides cloud and hardware solutions for individuals, teams, and organizations. It offers services such as Managed Kubernetes, Preinstalled Kubernetes, Slurm, and access to GPU clusters. The platform also provides educational resources and tutorials for machine learning engineers and researchers to fine-tune models and deploy AI solutions.
GPUDeploy
GPUDeploy is an AI tool that offers low-cost on-demand GPUs for machine learning and AI tasks. Users can easily connect their GPUs and launch GPU instances that are preconfigured for machine learning tasks. The platform provides various GPU configurations with different specifications to cater to diverse computing needs. GPUDeploy also allows users to earn by renting out idle GPUs, making it a versatile solution for both individuals and AI companies.
RunPod
RunPod is a cloud platform specifically designed for AI development and deployment. It offers a range of features to streamline the process of developing, training, and scaling AI models, including a library of pre-built templates, efficient training pipelines, and scalable deployment options. RunPod also provides access to a wide selection of GPUs, allowing users to choose the optimal hardware for their specific AI workloads.

GrapixAI
GrapixAI is a leading provider of low-cost cloud GPU rental services and AI server solutions. The company's focus on flexibility, scalability, and cutting-edge technology enables a variety of AI applications in both local and cloud environments. GrapixAI offers the lowest prices for on-demand GPUs such as RTX4090, RTX 3090, RTX A6000, RTX A5000, and A40. The platform provides Docker-based container ecosystem for quick software setup, powerful GPU search console, customizable pricing options, various security levels, GUI and CLI interfaces, real-time bidding system, and personalized customer support.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.
VeroCloud
VeroCloud is a platform offering tailored solutions for AI, HPC, and scalable growth. It provides cost-effective cloud solutions with guaranteed uptime, performance efficiency, and cost-saving models. Users can deploy HPC workloads seamlessly, configure environments as needed, and access optimized environments for GPU Cloud, HPC Compute, and Tally on Cloud. VeroCloud supports globally distributed endpoints, public and private image repos, and deployment of containers on secure cloud. The platform also allows users to create and customize templates for seamless deployment across computing resources.
Lambda
Lambda is a superintelligence cloud platform that offers on-demand GPU clusters for multi-node training and fine-tuning, private large-scale GPU clusters, seamless management and scaling of AI workloads, inference endpoints and API, and a privacy-first chat app with open source models. It also provides NVIDIA's latest generation infrastructure for enterprise AI. With Lambda, AI teams can access gigawatt-scale AI factories for training and inference, deploy GPU instances, and leverage the latest NVIDIA GPUs for high-performance computing.
Modal
Modal is a high-performance cloud platform designed for developers, AI data, and ML teams. It offers a serverless environment for running generative AI models, large-scale batch jobs, job queues, and more. With Modal, users can bring their own code and leverage the platform's optimized container file system for fast cold boots and seamless autoscaling. The platform is engineered for large-scale workloads, allowing users to scale to hundreds of GPUs, pay only for what they use, and deploy functions to the cloud in seconds without the need for YAML or Dockerfiles. Modal also provides features for job scheduling, web endpoints, observability, and security compliance.
Novita AI
Novita AI is an AI cloud platform that offers Model APIs, Serverless, and GPU Instance solutions integrated into one cost-effective platform. It provides tools for building AI products, scaling with serverless architecture, and deploying with GPU instances. Novita AI caters to startups and businesses looking to leverage AI technologies without the need for extensive machine learning expertise. The platform also offers a Startup Program, 24/7 service support, and has received positive feedback for its reasonable pricing and stable API services.
Rafay
Rafay is an AI-powered platform that accelerates cloud-native and AI/ML initiatives for enterprises. It provides automation for Kubernetes clusters, cloud cost optimization, and AI workbenches as a service. Rafay enables platform teams to focus on innovation by automating self-service cloud infrastructure workflows.
2 - Open Source Tools
ZhiLight
ZhiLight is a highly optimized large language model (LLM) inference engine developed by Zhihu and ModelBest Inc. It accelerates the inference of models like Llama and its variants, especially on PCIe-based GPUs. ZhiLight offers significant performance advantages compared to mainstream open-source inference engines. It supports various features such as custom defined tensor and unified global memory management, optimized fused kernels, support for dynamic batch, flash attention prefill, prefix cache, and different quantization techniques like INT8, SmoothQuant, FP8, AWQ, and GPTQ. ZhiLight is compatible with OpenAI interface and provides high performance on mainstream NVIDIA GPUs with different model sizes and precisions.
env-doctor
Env-Doctor is a tool designed to diagnose and fix mismatched CUDA versions between NVIDIA driver, system toolkit, cuDNN, and Python libraries, providing a quick solution to the common frustration in GPU computing. It offers one-command diagnosis, safe install commands, extension library support, AI model compatibility checks, WSL2 GPU support, deep CUDA analysis, container validation, MCP server integration, and CI/CD readiness. The tool helps users identify and resolve environment issues efficiently, ensuring smooth operation of AI libraries on their GPUs.
2 - OpenAI Gpts


CUDA GPT
Expert in CUDA for configuration, installation, troubleshooting, and programming.