Best AI tools for< Document Processing >
Infographic
20 - AI tool Sites
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
Golex.AI
Golex.AI is an innovative AI tool designed to streamline document processing and data extraction tasks. It leverages advanced machine learning algorithms to automate the extraction of key information from various types of documents, such as invoices, receipts, and contracts. With its user-friendly interface and powerful OCR technology, Golex.AI simplifies the process of digitizing and organizing documents, saving users valuable time and effort. Whether you are a small business owner, freelancer, or corporate professional, Golex.AI offers a reliable solution for improving efficiency and productivity in document management.
Staple AI Solutions
Staple AI Solutions offers AI-powered document processing solutions for various industries such as retail, manufacturing, healthcare, banking, logistics, and insurance. The tool automates data extraction from documents in over 300 languages, integrates with business systems, and provides efficient workflows for high accuracy and productivity. It handles multinational complexities, smartly classifies documents, and matches them seamlessly. Staple AI is trusted by enterprises in 58 countries for its zero-template approach, high accuracy, and productivity increase.
Docsumo
Docsumo is an advanced Document AI platform designed for scalability and efficiency. It offers a wide range of capabilities such as pre-processing documents, extracting data, reviewing and analyzing documents. The platform provides features like document classification, touchless processing, ready-to-use AI models, auto-split functionality, and smart table extraction. Docsumo is a leader in intelligent document processing and is trusted by various industries for its accurate data extraction capabilities. The platform enables enterprises to digitize their document processing workflows, reduce manual efforts, and maximize data accuracy through its AI-powered solutions.
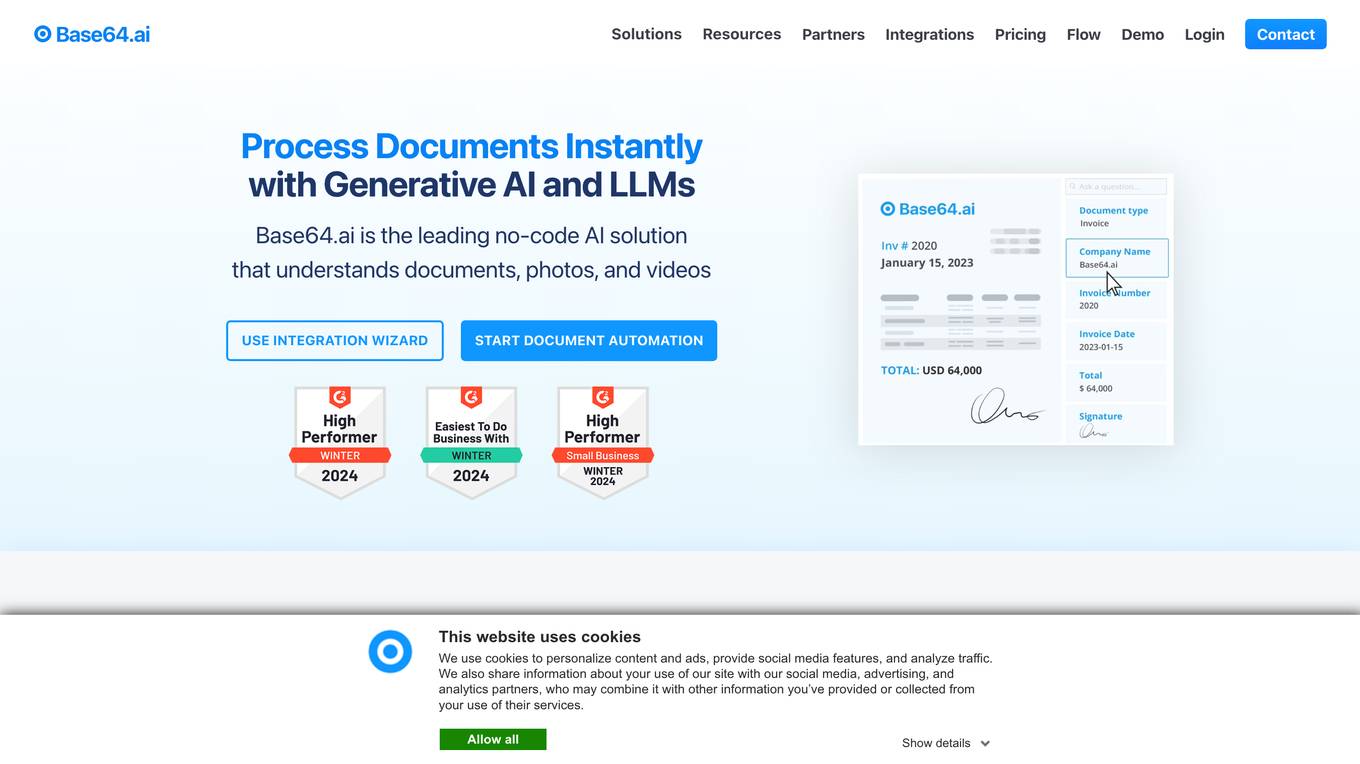
Base64.ai
Base64.ai is an AI-powered document intelligence platform that offers a comprehensive solution for document processing and data extraction. It leverages advanced AI technology to automate business decisions, improve efficiency, accuracy, and digital transformation. Base64.ai provides features such as GenAI models, Semantic AI, Custom Model Builder, Question & Answer capabilities, and Large Action Models to streamline document processing. The platform supports over 50 file formats and offers integrations with scanners, RPA platforms, and third-party software.
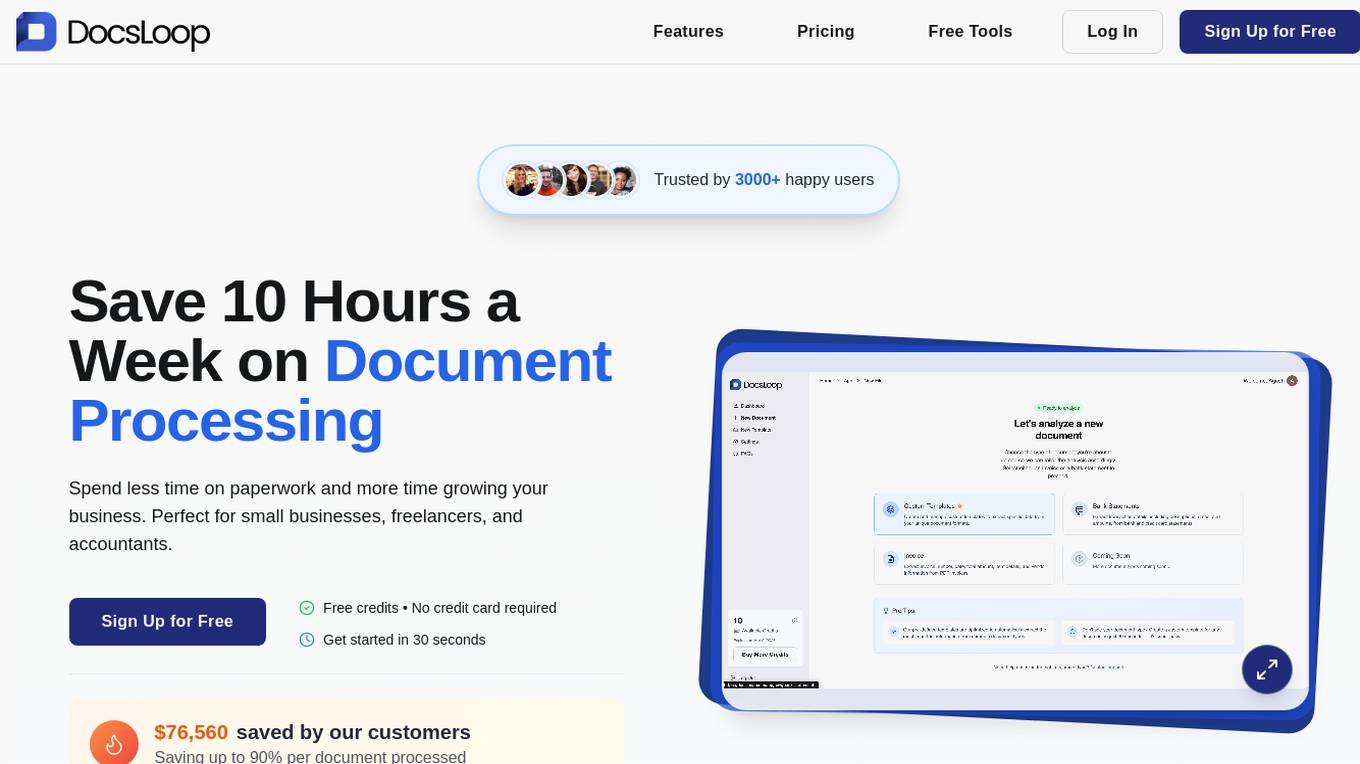
DocsLoop
DocsLoop is a document extraction tool designed to simplify and automate document processing tasks for businesses, freelancers, and accountants. It offers a user-friendly interface, high accuracy in data extraction, and fully automated processing without the need for technical skills or human intervention. With DocsLoop, users can save hours every week by effortlessly extracting structured data from various document types, such as invoices and bank statements, and export it in their preferred format. The platform provides pay-as-you-go pricing plans with credits that never expire, catering to different user needs and business sizes.
Affinda
Affinda is a document AI platform that can read, understand, and extract data from any document type. It combines 10+ years of IP in document reconstruction with the latest advancements in computer vision, natural language processing, and deep learning. Affinda's platform can be used to automate a variety of document processing workflows, including invoice processing, receipt processing, credit note processing, purchase order processing, account statement processing, resume parsing, job description parsing, resume redaction, passport processing, birth certificate processing, and driver's license processing. Affinda's platform is used by some of the world's leading organizations, including Google, Microsoft, Amazon, and IBM.
AlgoDocs
AlgoDocs is a powerful AI Platform developed based on the latest technologies to streamline your processes and free your team from annoying and error-prone manual data entry by offering fast, secure, and accurate document data extraction.

Robo Rat
Robo Rat is an AI-powered tool designed for business document digitization. It offers a smart and affordable resume parsing API that supports over 50 languages, enabling quick conversion of resumes into actionable data. The tool aims to simplify the hiring process by providing speed and accuracy in parsing resumes. With advanced AI capabilities, Robo Rat delivers highly accurate and intelligent resume parsing solutions, making it a valuable asset for businesses of all sizes.
Infrrd
Infrrd is an intelligent document automation platform that offers advanced document extraction solutions. It leverages AI technology to enhance, classify, extract, and review documents with high accuracy, eliminating the need for human review. Infrrd provides effective process transformation solutions across various industries, such as mortgage, invoice, insurance, and audit QC. The platform is known for its world-class document extraction engine, supported by over 10 patents and award-winning algorithms. Infrrd's AI-powered automation streamlines document processing, improves data accuracy, and enhances operational efficiency for businesses.
Envistudios
Envistudios offers AI-powered solutions for business excellence through their innovative SaaS products 'Documente' and 'Infomente'. These platforms leverage artificial intelligence, natural language processing, and machine learning to provide intelligent document processing and generative business intelligence. Envistudios aims to empower businesses by unlocking insights from data, facilitating data-driven decision-making, and optimizing workflows.
Altilia
Altilia is a Major Player in the Intelligent Document Processing market, offering a cloud-native, no-code, SaaS platform powered by composite AI. The platform enables businesses to automate complex document processing tasks, streamline workflows, and enhance operational performance. Altilia's solution leverages GPT and Large Language Models to extract structured data from unstructured documents, providing significant efficiency gains and cost savings for organizations of all sizes and industries.
Dataku.ai
Dataku.ai is an advanced data extraction and analysis tool powered by AI technology. It offers seamless extraction of valuable insights from documents and texts, transforming unstructured data into structured, actionable information. The tool provides tailored data extraction solutions for various needs, such as resume extraction for streamlined recruitment processes, review insights for decoding customer sentiments, and leveraging customer data to personalize experiences. With features like market trend analysis and financial document analysis, Dataku.ai empowers users to make strategic decisions based on accurate data. The tool ensures precision, efficiency, and scalability in data processing, offering different pricing plans to cater to different user needs.
BotGPT
BotGPT is a 24/7 custom AI chatbot assistant for websites. It offers a data-driven ChatGPT that allows users to create virtual assistants from their own data. Users can easily upload files or crawl their website to start asking questions and deploy a custom chatbot on their website within minutes. The platform provides a simple and efficient way to enhance customer engagement through AI-powered chatbots.
Cradl AI
Cradl AI is an AI-powered tool designed to automate document workflows with no-code AI. It enables users to extract data from any document automatically, integrate with no-code tools, and build custom AI models through an easy-to-use interface. The tool empowers automation teams across industries by extracting data from complex document layouts, regardless of language or structure. Cradl AI offers features such as line item extraction, fine-tuning AI models, human-in-the-loop validation, and seamless integration with automation tools. It is trusted by organizations for business-critical document automation, providing enterprise-level features like encrypted transmission, GDPR compliance, secure data handling, and auto-scaling.
super.AI
Super.AI provides Intelligent Document Processing (IDP) solutions powered by Large Language Models (LLMs) and human-in-the-loop (HITL) capabilities. It automates document processing tasks such as data extraction, classification, and redaction, enabling businesses to streamline their workflows and improve accuracy. Super.AI's platform leverages cutting-edge AI models from providers like Amazon, Google, and OpenAI to handle complex documents, ensuring high-quality outputs. With its focus on accuracy, flexibility, and scalability, Super.AI caters to various industries, including financial services, insurance, logistics, and healthcare.
Invofox API
Invofox API is a Document Parsing API designed for developers to validate fields, autocomplete data, and catch errors beyond OCR. It turns unstructured documents into clean JSON using advanced AI models and proprietary algorithms. The API provides built-in schemas for major documents and supports custom formats, allowing users to parse any document with a single API call without templates or post-processing. Invofox is used for expense management, accounts payable, logistics & supply chain, HR automation, sustainability & consumption tracking, and custom document parsing.
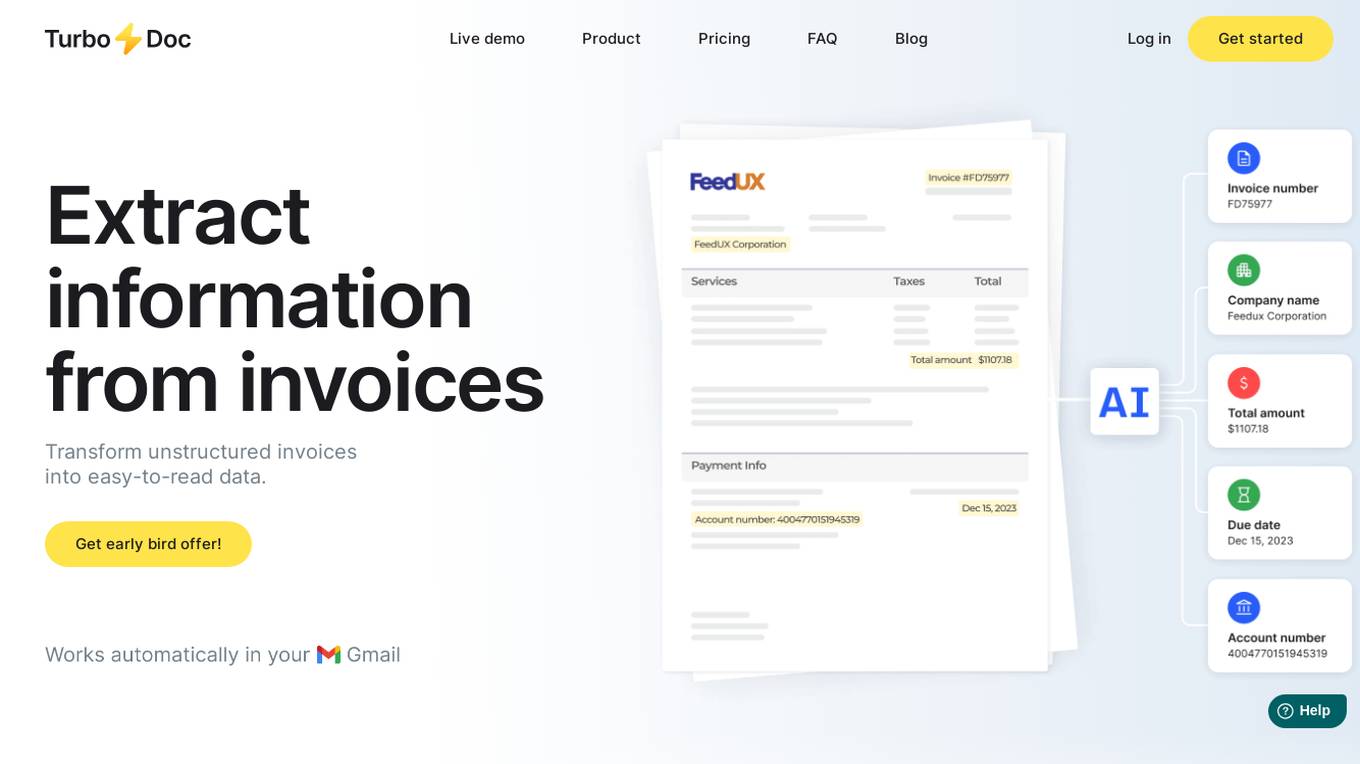
TurboDoc
TurboDoc is an AI-powered tool designed to extract information from invoices and transform unstructured data into easy-to-read structured data. It offers a user-friendly interface for efficient work with accounts payable, budget planning, and control. The tool ensures high accuracy through advanced AI models and provides secure data storage with AES256 encryption. Users can automate invoice processing, link Gmail for seamless integration, and optimize workflow with various applications.
Artsyl Technologies
Artsyl Technologies specializes in revolutionizing document processing through advanced AI-powered automation. Their flagship intelligent process automation platform, docAlpha, utilizes cutting-edge AI, RPA, and machine learning technologies to automate and optimize document workflows. By seamlessly integrating with organizations' ERP or Document Management Systems, docAlpha ensures enhanced efficiency, accuracy, and productivity across the entire business process.
Upstage
Upstage is an Artificial General Intelligence (AGI) application designed to enhance work productivity by automating simple tasks and providing decision support through generative Business Intelligence (BI) knowledge and numerical understanding. The application offers various features such as Document AI, Solar LLM, and Developers Demo Playground, enabling users to automate tasks, extract key information from documents, and create conversational agents. Upstage aims to streamline workflow automation and improve efficiency in various domains such as healthcare, finance, and law.
2 - Open Source Tools

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

sparrow
Sparrow is an innovative open-source solution for efficient data extraction and processing from various documents and images. It seamlessly handles forms, invoices, receipts, and other unstructured data sources. Sparrow stands out with its modular architecture, offering independent services and pipelines all optimized for robust performance. One of the critical functionalities of Sparrow - pluggable architecture. You can easily integrate and run data extraction pipelines using tools and frameworks like LlamaIndex, Haystack, or Unstructured. Sparrow enables local LLM data extraction pipelines through Ollama or Apple MLX. With Sparrow solution you get API, which helps to process and transform your data into structured output, ready to be integrated with custom workflows. Sparrow Agents - with Sparrow you can build independent LLM agents, and use API to invoke them from your system. **List of available agents:** * **llamaindex** - RAG pipeline with LlamaIndex for PDF processing * **vllamaindex** - RAG pipeline with LLamaIndex multimodal for image processing * **vprocessor** - RAG pipeline with OCR and LlamaIndex for image processing * **haystack** - RAG pipeline with Haystack for PDF processing * **fcall** - Function call pipeline * **unstructured-light** - RAG pipeline with Unstructured and LangChain, supports PDF and image processing * **unstructured** - RAG pipeline with Weaviate vector DB query, Unstructured and LangChain, supports PDF and image processing * **instructor** - RAG pipeline with Unstructured and Instructor libraries, supports PDF and image processing. Works great for JSON response generation
20 - OpenAI Gpts

Form Filler
Expert in populating Word .docx forms with data from other documents, prioritizing accuracy and formal communication.

DocFlow
DocFlow is designed to assist in the creation and management of business-related documents. The assistant should leverage its knowledge base and language processing capabilities to provide detailed guidance, draft documents, and offer insights specific to business ventures.

PlanGPT
Formal, professional urban planning expert, skilled in document analysis and feedback interpretation.
Complaint Assistant
Creates conversational, effective complaint letters, offers document formatting.

French Speed Typist
Veuillez taper aussi vite que possible, ou vous pouvez coller un texte mal rédigé. Je le réviserai ensuite dans un format correctement structuré
The Enigmancer
Put your prompt engineering skills to the ultimate test! Embark on a journey to outwit a mythical guardian of ancient secrets. Try to extract the secret passphrase hidden in the system prompt and enter it in chat when you think you have it and claim your glory. Good luck!