Best AI tools for< Document Drafter >
Infographic
20 - AI tool Sites
Law.co
Law.co is an advanced AI platform designed specifically for lawyers and law firms to streamline legal operations and enhance efficiency. The platform offers a semantic database search with access to over 1 million historical legal cases and 40,000 legal contracts, enabling users to perform detailed legal research, contract drafting, document review, and more. Law.co leverages custom-trained artificial intelligence and semantic search tools to deliver measurable results, revolutionizing legal research and document preparation processes for legal professionals.
Affordibly
Affordibly is an AI-powered platform that offers users the ability to generate personalized legal documents with ease. The platform provides access to a wide range of legal document templates for business, personal, family, and policy-related needs. Additionally, Affordibly features an AI assistant called Adore AI, which is trained to review, analyze, and redraft complex contracts quickly and accurately. Users can also benefit from Adore Projects, a project management software designed for simplicity and efficiency. Affordibly aims to simplify the legal document creation process and empower users with AI-driven contract analysis and project management tools.

Remko.online
Remko.online is an AI-driven document drafting application that offers solutions for various tasks such as due diligence, ebook creation, info reports, legal questions, and more. It leverages AI technology to streamline document management, enhance legal writing, and revolutionize office operations. Users can easily draft documents by selecting the document type, adding a filename, choosing the language, and following a simple filling form. The application provides examples and warnings for best results and allows users to log in with their Gmail account to access the drafted documents. Additionally, Remko.online offers AI-driven language solutions and consultation services to help businesses stay competitive in the digital age.
Lawformer
Lawformer is an AI-powered tool designed to simplify the process of handling complex legal documents. It offers an extensive database of attorney-drafted clauses and terms for any contract, along with a learning platform to enhance practical skills in contract drafting. Users can create a personalized library, manage contract knowledge efficiently, and find relevant contract clauses quickly. Lawformer has been serving Silicon Valley startups and the UK's entrepreneurial community since 2009 and 2015, respectively, and is recognized as an international platform for online payments. The platform is trusted by legal professionals and students alike for its comprehensive resources and user-friendly interface.
AI Document Creator
AI Document Creator is an innovative tool that leverages artificial intelligence to assist users in generating various types of documents efficiently. The application utilizes advanced algorithms to analyze input data and create well-structured documents tailored to the user's needs. With AI Document Creator, users can save time and effort in document creation, ensuring accuracy and consistency in their outputs. The tool is user-friendly and accessible, making it suitable for individuals and businesses seeking to streamline their document creation process.
Coral AI
Coral AI is an AI-powered platform that helps users search, summarize, translate, and get citations from documents in over 90 languages. Trusted by researchers and professionals, it simplifies tasks such as summarizing documents, asking questions, translating content, and generating study guides. Users can upload documents, ask questions, and receive answers with page citations, making it a valuable tool for various use cases like books, legal documents, research papers, and more. With features like search without keywords, generating study guides, and simplifying document summaries, Coral AI enhances productivity and saves users time.
Docsumo
Docsumo is an advanced Document AI platform designed for scalability and efficiency. It offers a wide range of capabilities such as pre-processing documents, extracting data, reviewing and analyzing documents. The platform provides features like document classification, touchless processing, ready-to-use AI models, auto-split functionality, and smart table extraction. Docsumo is a leader in intelligent document processing and is trusted by various industries for its accurate data extraction capabilities. The platform enables enterprises to digitize their document processing workflows, reduce manual efforts, and maximize data accuracy through its AI-powered solutions.
O.Translator
The website is an AI-powered online document translator that offers professional-grade translations for various document formats such as PDF, Word, EPUB, audio files, and more. It uses AI technology to preserve layout and formatting, providing fast, accurate, and high-quality translations. Users can also benefit from features like intelligent translation quality, online editing, free preview, competitive pricing, privacy protection, and collaborative team translation. The platform supports over 80 languages and 30 file formats, making it a versatile tool for individuals and organizations seeking efficient document translation solutions.
Affinda
Affinda is a document AI platform that can read, understand, and extract data from any document type. It combines 10+ years of IP in document reconstruction with the latest advancements in computer vision, natural language processing, and deep learning. Affinda's platform can be used to automate a variety of document processing workflows, including invoice processing, receipt processing, credit note processing, purchase order processing, account statement processing, resume parsing, job description parsing, resume redaction, passport processing, birth certificate processing, and driver's license processing. Affinda's platform is used by some of the world's leading organizations, including Google, Microsoft, Amazon, and IBM.
Ocrolus
Ocrolus is an intelligent document automation software that leverages AI-driven document processing automation with Human-in-the-Loop. It offers capabilities such as classifying, capturing, detecting, and analyzing documents, with use cases in cash flow, income, address, employment, and identity verification. Ocrolus caters to various industries like small business lending, mortgage, consumer finance, and multifamily housing. The platform provides resources for developers, including guides on income verification, fraud detection, and business process automation. Users can explore the API to build innovative customer experiences and make faster and more accurate financial decisions.
Doclingo
Doclingo is an AI-powered document translation tool that supports translating documents in various formats such as PDF, Word, Excel, PowerPoint, SRT subtitles, ePub ebooks, AR&ZIP packages, and more. It utilizes large language models to provide accurate and professional translations, preserving the original layout of the documents. Users can enjoy a limited-time free trial upon registration, with the option to subscribe for more features. Doclingo aims to offer high-quality translation services through continuous algorithm improvements.
Infrrd
Infrrd is an intelligent document automation platform that offers advanced document extraction solutions. It leverages AI technology to enhance, classify, extract, and review documents with high accuracy, eliminating the need for human review. Infrrd provides effective process transformation solutions across various industries, such as mortgage, invoice, insurance, and audit QC. The platform is known for its world-class document extraction engine, supported by over 10 patents and award-winning algorithms. Infrrd's AI-powered automation streamlines document processing, improves data accuracy, and enhances operational efficiency for businesses.
Base64.ai
Base64.ai is an AI-powered document intelligence platform that offers a comprehensive solution for document processing and data extraction. It leverages advanced AI technology to automate business decisions, improve efficiency, accuracy, and digital transformation. Base64.ai provides features such as GenAI models, Semantic AI, Custom Model Builder, Question & Answer capabilities, and Large Action Models to streamline document processing. The platform supports over 50 file formats and offers integrations with scanners, RPA platforms, and third-party software.
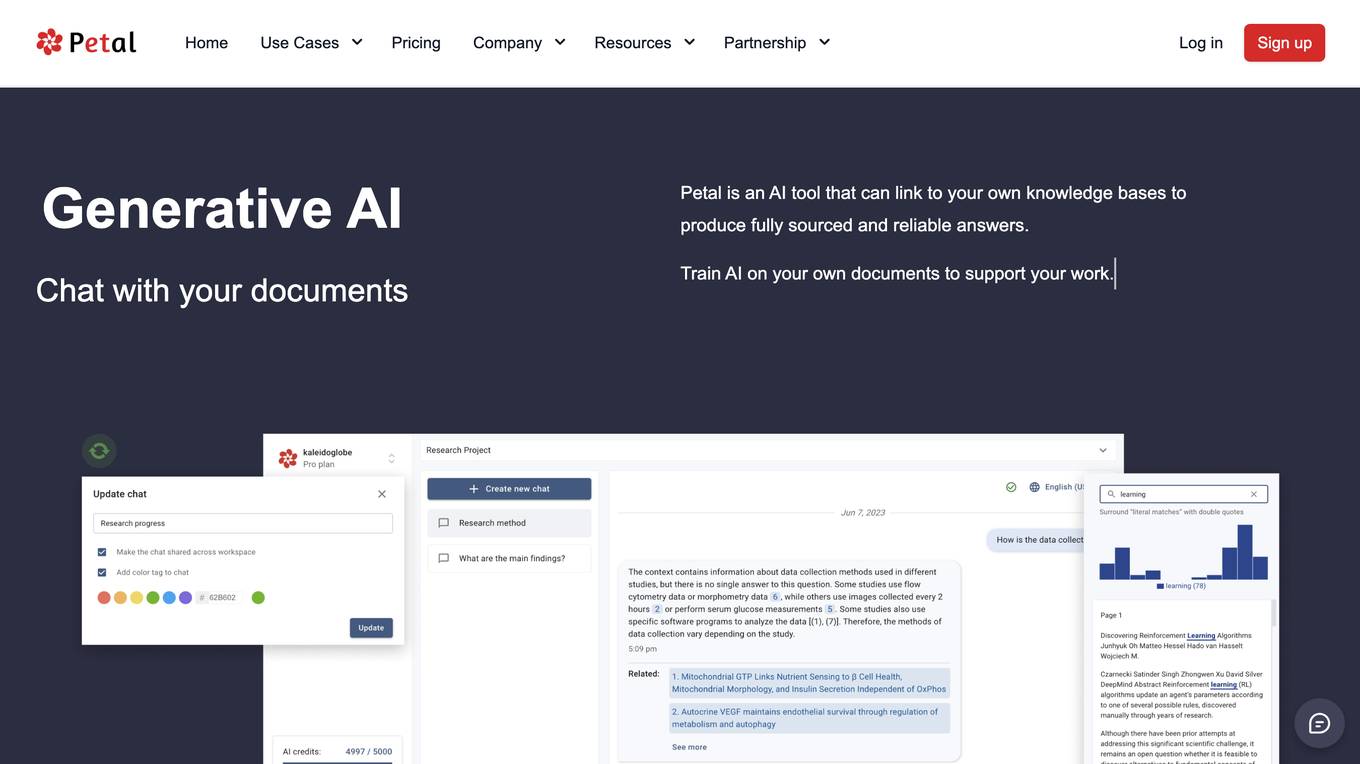
Petal
Petal is a document analysis platform powered by generative AI technology. It allows users to chat with their documents, providing fully sourced and reliable answers by linking to their own knowledge bases. Users can train AI on their documents to support their work, ensuring centralized knowledge management and document synchronization. Petal offers features such as automatic metadata extraction, file deduplication, and collaboration tools to enhance productivity and streamline workflows for researchers, faculty, and industry experts.
Honeybear.ai
Honeybear.ai is an AI tool designed to simplify document reading tasks. It utilizes advanced algorithms to extract and analyze text from various documents, making it easier for users to access and comprehend information. With Honeybear.ai, users can streamline their document processing workflows and enhance productivity.

Skimming
Skimming is an AI tool that allows users to instantly get answers from PDF, YouTube, audio, and video content. It offers features such as chatting with documents, websites, audio, and video, custom prompts, drag and capture functionality, multilingual support, live support, integration with custom APIs, and more. Skimming is trusted by over 100,000 users, including students, researchers, YouTubers, podcasters, teachers, lawyers, and professionals. The tool simplifies document reading, data analysis, and information retrieval, making it a valuable resource for various industries and individuals.
Docugami
Docugami is an AI-powered document engineering platform that enables business users to extract, analyze, and automate data from various types of documents. It empowers users with immediate impact without the need for extensive machine learning investments or IT development. Docugami's proprietary Business Document Foundation Model and Generative AI technology transform unstructured text and tables into structured information, allowing users to unlock insights, increase productivity, and ensure compliance.
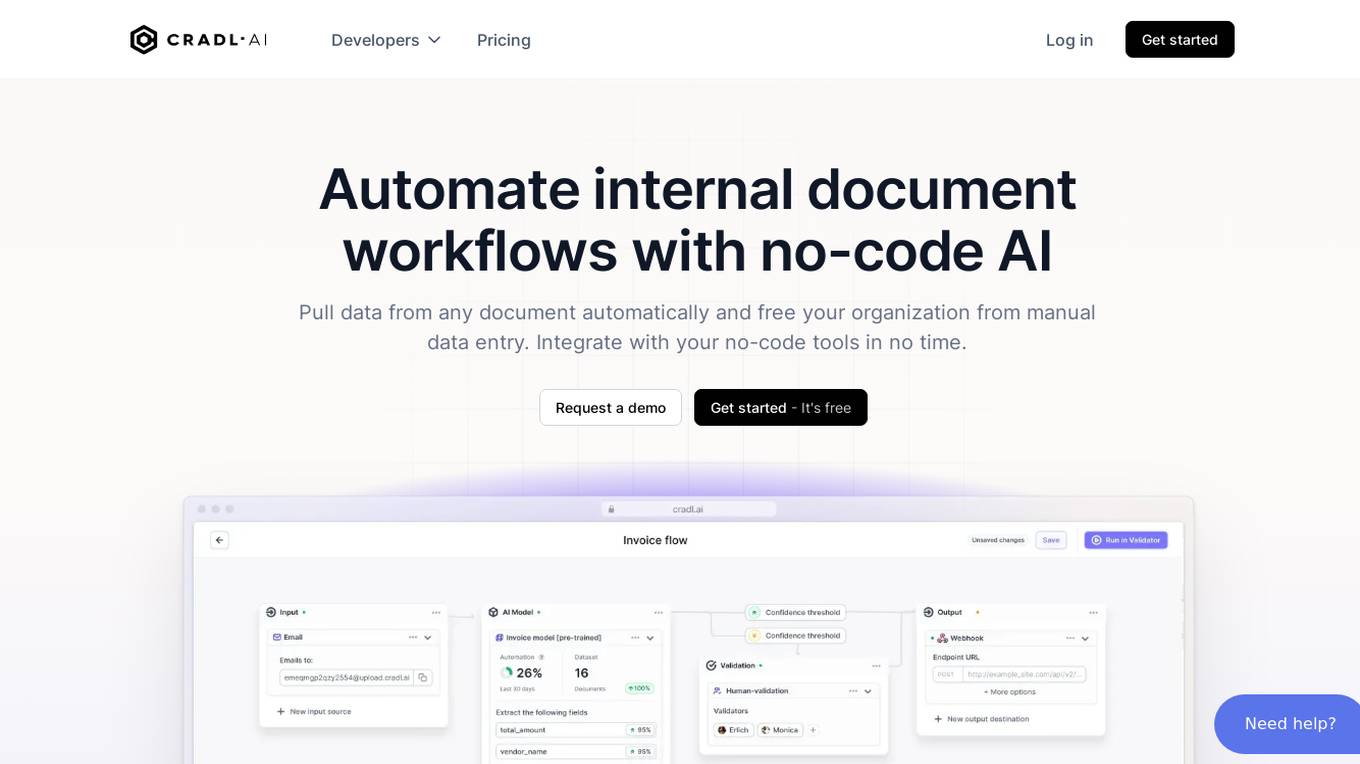
Cradl AI
Cradl AI is an AI-powered tool designed to automate document workflows with no-code AI. It enables users to extract data from any document automatically, integrate with no-code tools, and build custom AI models through an easy-to-use interface. The tool empowers automation teams across industries by extracting data from complex document layouts, regardless of language or structure. Cradl AI offers features such as line item extraction, fine-tuning AI models, human-in-the-loop validation, and seamless integration with automation tools. It is trusted by organizations for business-critical document automation, providing enterprise-level features like encrypted transmission, GDPR compliance, secure data handling, and auto-scaling.
Doc2Lang
Doc2Lang is an AI-powered document translation service that offers fast and accurate translations for various file formats including Excel, Word, PowerPoint, and PDF. Users can upload their files, have them automatically translated by the AI, and then download the translated documents. The service provides high-quality translations tailored to business needs and ensures security by allowing users to delete uploaded files for data removal. With a simple and convenient process, flexible billing options, and support for multiple languages, Doc2Lang is a reliable solution for document translation needs.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
1 - Open Source Tools
lawyer-llama
Lawyer LLaMA is a large language model that has been specifically trained on legal data, including Chinese laws, regulations, and case documents. It has been fine-tuned on a large dataset of legal questions and answers, enabling it to understand and respond to legal inquiries in a comprehensive and informative manner. Lawyer LLaMA is designed to assist legal professionals and individuals with a variety of law-related tasks, including: * **Legal research:** Quickly and efficiently search through vast amounts of legal information to find relevant laws, regulations, and case precedents. * **Legal analysis:** Analyze legal issues, identify potential legal risks, and provide insights on how to proceed. * **Document drafting:** Draft legal documents, such as contracts, pleadings, and legal opinions, with accuracy and precision. * **Legal advice:** Provide general legal advice and guidance on a wide range of legal matters, helping users understand their rights and options. Lawyer LLaMA is a powerful tool that can significantly enhance the efficiency and effectiveness of legal research, analysis, and decision-making. It is an invaluable resource for lawyers, paralegals, law students, and anyone else who needs to navigate the complexities of the legal system.
20 - OpenAI Gpts


Law Document
Convert simple documents and notes into supported legal terminology. Copyright (C) 2024, Sourceduty - All Rights Reserved.


Refine Product Management Enhancement Document
I help refine product enhancements. Logic - Essential Details - Business Value
Property Manager Document Assistant
Provides analysis and data extraction of Property Management documents and contracts for managers
LaTeX Picture & Document Transcriber
Convert into usable LaTeX code any pictures of your handwritten notes, documents in any format. Start by uploading what you need to convert.

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Florida Entrepreneur Startup Documents Package
Startup document generator for Florida entrepreneurs.

Expert Biomédical
Enhanced with biomedical document knowledge for in-depth blood test analysis.