Best AI tools for< Computer Vision Research >
Infographic
20 - AI tool Sites
Joseph Chet Redmon's Computer Vision Platform
The website is a platform maintained by Joseph Chet Redmon, a graduate student working on computer vision. It features information on his projects, publications, talks, and teaching activities. The site also includes details about the Darknet Neural Network Framework, tactics in Coq, and research work. Visitors can learn about computer vision, object recognition, and visual question answering through the resources provided on the site.

Andreas Geiger
Andreas Geiger is a website belonging to the Autonomous Vision Group (AVG) at the University of Tübingen in Germany. The group focuses on developing machine learning models for computer vision, natural language, and robotics with applications in self-driving, VR/AR, and scientific document analysis. The website showcases the research activities, achievements, publications, and projects of the AVG team, led by Prof. Dr.-Ing. Andreas Geiger. It also provides information on the team members, contact details, and links to related resources and platforms.
Rendered.ai
Rendered.ai is a platform that provides unlimited synthetic data for AI and ML applications, specifically focusing on computer vision. It helps in generating low-cost physically-accurate data to overcome bias and power innovation in AI and ML. The platform allows users to capture rare events and edge cases, acquire data that is difficult to obtain, overcome data labeling challenges, and simulate restricted or high-risk scenarios. Rendered.ai aims to revolutionize the use of synthetic data in AI and data analytics projects, with a vision that by 2030, synthetic data will surpass real data in AI models.
DataVLab Solutions
DataVLab Solutions is an AI-powered platform offering comprehensive image annotation and data labeling services for AI applications. They provide high-quality, scalable, and ethical data labeling solutions to enhance AI and machine learning models. With expertise in image, video, 3D annotation, custom AI projects, NLP, and text annotation, DataVLab Solutions caters to various industries such as energy infrastructure, autonomous vehicles, agriculture, medical, e-commerce, and insurance. Their advanced annotation process accelerates data labeling, ensuring precision and efficiency. Leveraging AI-driven tools, they offer tailor-made annotation workflows for unique AI challenges, delivering high-quality annotations for computer vision models, dynamic data, and spatial AI. The platform also provides training data and fine-tuning support for Large Language Models and generative AI applications.
InsightFace
InsightFace is an open-source deep face analysis library that provides a rich variety of state-of-the-art algorithms for face recognition, detection, and alignment. It is designed to be efficient for both training and deployment, making it suitable for research institutions and industrial organizations. InsightFace has achieved top rankings in various challenges and competitions, including the ECCV 2022 WCPA Challenge, NIST-FRVT 1:1 VISA, and WIDER Face Detection Challenge 2019.

Caffe
Caffe is a deep learning framework developed by Berkeley AI Research (BAIR) and community contributors. It is designed for speed, modularity, and expressiveness, allowing users to define models and optimization through configuration without hard-coding. Caffe supports both CPU and GPU training, making it suitable for research experiments and industry deployment. The framework is extensible, actively developed, and tracks the state-of-the-art in code and models. Caffe is widely used in academic research, startup prototypes, and large-scale industrial applications in vision, speech, and multimedia.
Supertype
Supertype is a full-cycle data science consultancy offering a range of services including computer vision, custom BI development, managed data analytics, programmatic report generation, and more. They specialize in providing tailored solutions for data analytics, business intelligence, and data engineering services. Supertype also offers services for developing custom web dashboards, computer vision research and development, PDF generation, managed analytics services, and LLM development. Their expertise extends to implementing data science in various industries such as e-commerce, mobile apps & games, and financial markets. Additionally, Supertype provides bespoke solutions for enterprises, advisory and consulting services, and an incubator platform for data scientists and engineers to work on real-world projects.

Big Vision
Big Vision provides consulting services in AI, computer vision, and deep learning. They help businesses build specific AI-driven solutions, create intelligent processes, and establish best practices to reduce human effort and enable faster decision-making. Their enterprise-grade solutions are currently serving millions of requests every month, especially in critical production environments.
Roboflow
Roboflow is an AI tool designed for computer vision tasks, offering a platform that allows users to annotate, train, deploy, and perform inference on models. It provides integrations, ecosystem support, and features like notebooks, autodistillation, and supervision. Roboflow caters to various industries such as aerospace, agriculture, healthcare, finance, and more, with a focus on simplifying the development and deployment of computer vision models.
Lexset
Lexset is an AI tool that provides synthetic data generation services for computer vision model training. It offers a no-code interface to create unlimited data with advanced camera controls and lighting options. Users can simulate AI-scale environments, composite objects into images, and create custom 3D scenarios. Lexset also provides access to GPU nodes, dedicated support, and feature development assistance. The tool aims to improve object detection accuracy and optimize generalization on high-quality synthetic data.

CVF Open Access
The Computer Vision Foundation (CVF) is a non-profit organization dedicated to advancing the field of computer vision. CVF organizes several conferences and workshops each year, including the International Conference on Computer Vision (ICCV), the Conference on Computer Vision and Pattern Recognition (CVPR), and the Winter Conference on Applications of Computer Vision (WACV). CVF also publishes the International Journal of Computer Vision (IJCV) and the Computer Vision and Image Understanding (CVIU) journal. The CVF Open Access website provides access to the full text of all CVF-sponsored conference papers. These papers are available for free download in PDF format. The CVF Open Access website also includes links to the arXiv versions of the papers, where available.
Beebzi.AI
Beebzi.AI is an all-in-one AI content creation platform that offers a wide array of tools for generating various types of content such as articles, blogs, emails, images, voiceovers, and more. The platform utilizes advanced AI technology and behavioral science to empower businesses and individuals in their marketing and sales endeavors. With features like AI Article Wizard, AI Room Designer, AI Landing Page Generator, and AI Code Generation, Beebzi.AI revolutionizes content creation by providing customizable templates, multiple language support, and real-time data insights. The platform also offers various subscription plans tailored for individual entrepreneurs, teams, and businesses, with flexible pricing models based on word count allocations. Beebzi.AI aims to streamline content creation processes, enhance productivity, and drive organic traffic through SEO-optimized content.
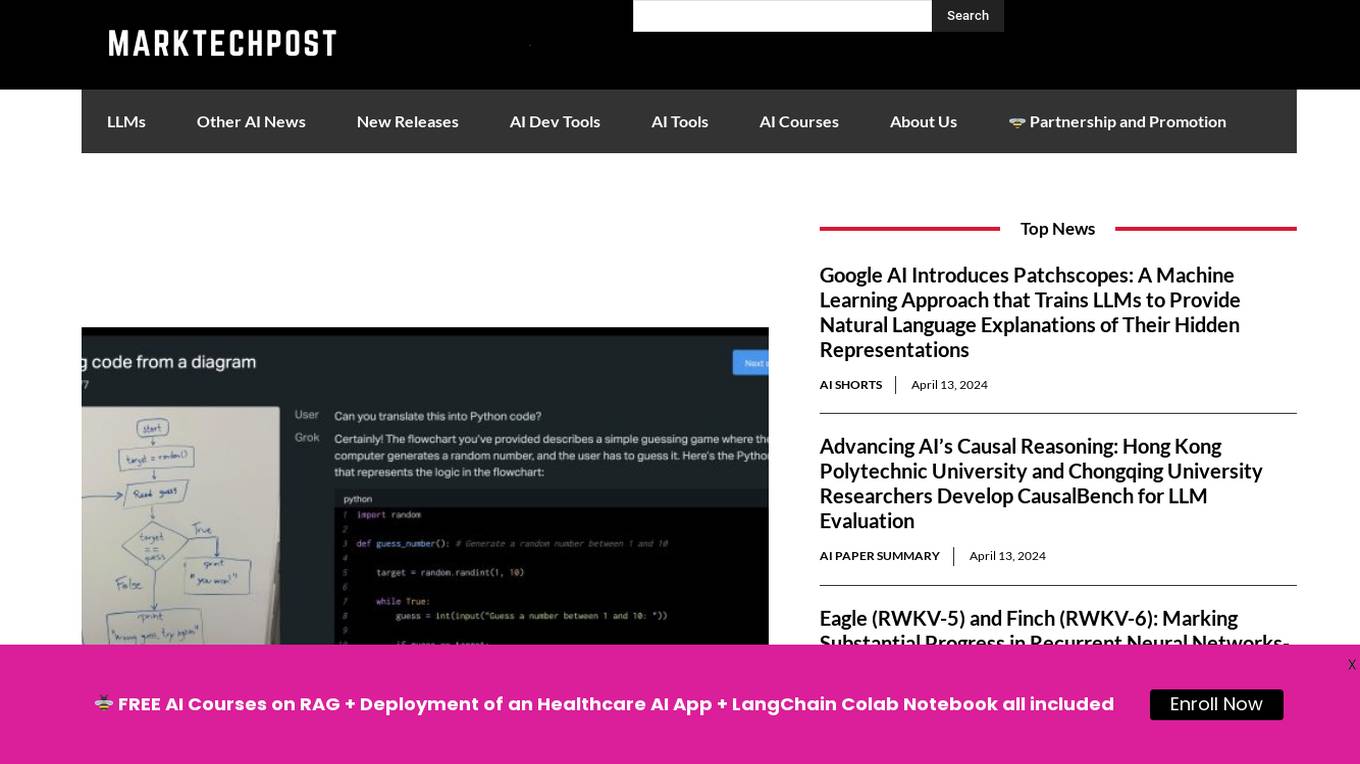
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.

Ultralytics YOLO
Ultralytics YOLO is an advanced real-time object detection and image segmentation model that leverages cutting-edge advancements in deep learning and computer vision. It offers unparalleled performance in terms of speed and accuracy, making it suitable for various applications and easily adaptable to different hardware platforms. The comprehensive Ultralytics Docs provide resources to help users understand and utilize its features and capabilities, catering to both seasoned machine learning practitioners and newcomers to the field.
EyePop.ai
EyePop.ai is a hassle-free AI vision partner designed for innovators to easily create and own custom AI-powered vision models tailored to their visual data needs. The platform simplifies building AI-powered vision models through a fast, intuitive, and fully guided process without the need for coding or technical expertise. Users can define their target, upload data, train their model, deploy and detect, and iterate and improve to ensure effective AI solutions. EyePop.ai offers pre-trained model library, self-service training platform, and future-ready solutions to help users innovate faster, offer unique solutions, and make real-time decisions effortlessly.
syntheticAIdata
syntheticAIdata is a platform that provides synthetic data for training vision AI models. Synthetic data is generated artificially, and it can be used to augment existing real-world datasets or to create new datasets from scratch. syntheticAIdata's platform is easy to use, and it can be integrated with leading cloud platforms. The company's mission is to make synthetic data accessible to everyone, and to help businesses overcome the challenges of acquiring high-quality data for training their vision AI models.
GptDemo.Net
GptDemo.Net is a website that provides a directory of AI tools and resources. The website includes a search engine that allows users to find AI tools based on their needs. GptDemo.Net also provides news and updates on the latest AI developments.
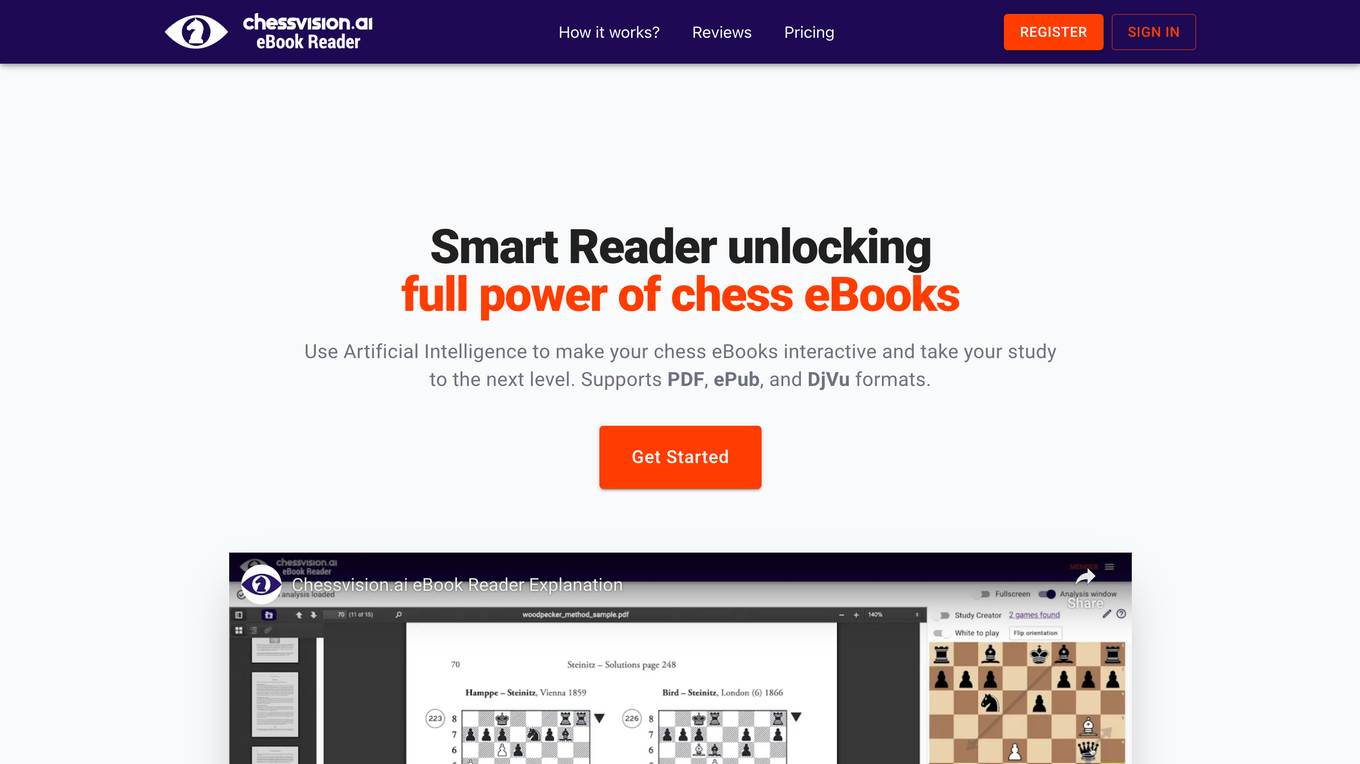
Chessvision.ai
Chessvision.ai is an AI-powered eBook reader that leverages Artificial Intelligence and Computer Vision to make chess eBooks interactive. It supports PDF, ePub, and DjVu formats, allowing users to analyze chess diagrams, add comments, search positions online, watch YouTube videos, and analyze with the engine. The application has gained popularity among chess players of all levels for its ability to enhance the study and learning experience through innovative technology.
GeoInfer
GeoInfer is a professional AI-powered geolocation platform that analyzes photographs to determine where they were taken. It uses visual-only inference technology to examine visual elements like architecture, terrain, vegetation, and environmental markers to identify geographic locations without requiring GPS metadata or EXIF data. The platform offers transparent accuracy levels for different use cases, including a Global Model with 1km-100km accuracy ideal for regional and city-level identification. Additionally, GeoInfer provides custom regional models for organizations requiring higher precision, such as meter-level accuracy for specific geographic areas. The platform is designed for professionals in various industries, including law enforcement, insurance fraud investigation, digital forensics, and security research.
Robovision
Robovision is a central platform to manage vision intelligence inside smart machines. Successfully introduce AI in dynamic environments without the need for AI experts.
1 - Open Source Tools

supervisely
Supervisely is a computer vision platform that provides a range of tools and services for developing and deploying computer vision solutions. It includes a data labeling platform, a model training platform, and a marketplace for computer vision apps. Supervisely is used by a variety of organizations, including Fortune 500 companies, research institutions, and government agencies.
20 - OpenAI Gpts


Jimmy madman
This AI is specifically for Computer Vision usage, specifically realated to PCB component identification
AI-Driven Lab
recommends AI research these days in Japanese using AI-driven's-lab articles
Media AI Visionary
Leading AI & Media Expert: In-depth, Ethical, Insightful, developed on OpenAI



Code & Research ML Engineer
ML Engineer who codes & researches for you! created by Meysam
Identify movies, dramas, and animations by image
Just send us an image of a scene from a video work and i will guess the name of the work!
AI Tools Guru
Find the best AI tools. Want to add your tool? Fill the form: https://forms.gle/uqMaC2EFZzh3Y4yT6
Gary Marcus AI Critic Simulator
Humorous AI critic known for skepticism, contradictory arguments, and combining Animal and Machine Learning related Terms.