Best AI tools for< Audio Model Developer >
Infographic
20 - AI tool Sites
Moshi AI
Moshi AI by Kyutai is an advanced native speech AI model that enables natural, expressive conversations. It can be installed locally and run offline, making it suitable for integration into smart home appliances and other local applications. The model, named Helium, has 7 billion parameters and is trained on text and audio codecs. Moshi AI supports native speech input and output, allowing for smooth communication with the AI. The application is community-supported, with plans for continuous improvement and adaptation.
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
Open GPT 4o
Open GPT 4o is an advanced large multimodal language model developed by OpenAI, offering real-time audiovisual responses, emotion recognition, and superior visual capabilities. It can handle text, audio, and image inputs, providing a rich and interactive user experience. GPT 4o is free for all users and features faster response times, advanced interactivity, and the ability to recognize and output emotions. It is designed to be more powerful and comprehensive than its predecessor, GPT 4, making it suitable for applications requiring voice interaction and multimodal processing.
GPT-4o
GPT-4o is a state-of-the-art AI model developed by OpenAI, capable of processing and generating text, audio, and image outputs. It offers enhanced emotion recognition, real-time interaction, multimodal capabilities, improved accessibility, and advanced language capabilities. GPT-4o provides cost-effective and efficient AI solutions with superior vision and audio understanding. It aims to revolutionize human-computer interaction and empower users worldwide with cutting-edge AI technology.
Mixpeek Solutions
Mixpeek Solutions offers a Multimodal Data Warehouse for Developers, providing a Developer-First API for AI-native Content Understanding. The platform allows users to search, monitor, classify, and cluster unstructured data like video, audio, images, and documents. Mixpeek Solutions offers a range of features including Unified Search, Automated Classification, Unsupervised Clustering, Feature Extractors for Every Data Type, and various specialized extraction models for different data types. The platform caters to a wide range of industries and provides seamless model upgrades, cross-model compatibility, A/B testing infrastructure, and simplified model management.
ChatTTS
ChatTTS is an open-source text-to-speech model designed for dialogue scenarios, supporting both English and Chinese speech generation. Trained on approximately 100,000 hours of Chinese and English data, it delivers speech quality comparable to human dialogue. The tool is particularly suitable for tasks involving large language model assistants and creating dialogue-based audio and video introductions. It provides developers with a powerful and easy-to-use tool based on open-source natural language processing and speech synthesis technologies.
VoiceGen
VoiceGen is an AI audio platform that enables users to create realistic speech using the best technology from leading providers like OpenAI, Google, AWS, and Azure. It offers natural, high-quality voices with support for multiple languages and unrestricted commercial use. VoiceGen prioritizes simplicity, transparency, and innovation, providing an accessible and affordable solution for voice generation needs. The platform ensures security and privacy of user data, offering a pay-as-you-go pricing model with fair and transparent costs.
ModelsLab
ModelsLab is an AI tool that offers Text to Image and AI Voice Generator online. It provides resources for models, pricing, and enterprise solutions. Developers can access the API documentation and join the Discord community. ModelsLab enables users to build smart AI products for various applications, with features like Imagen AI Image Generation, Video Fusion, AudioGen, 3D Verse, Auto AI, and LLMaster. The platform has advantages such as easy image generation, enhanced audio and music creation, 3D model designing, productivity boost with AI, and language model integration. However, some disadvantages include limited features for certain tasks, potential learning curve, and availability of certain tools. The FAQ section covers common queries about image editing APIs, resolution quality, importance of image editing APIs, and applications of FaceGen API. ModelsLab is suitable for jobs like developers, game developers, instructional designers, digital marketing managers, and artists. Users can find the application using keywords like AI Image Generator, AI Voice Generator, Text to Image, Voice Cloning, and Language Model. Tasks that can be performed using ModelsLab include Generate Image, Create Video, Generate Audio, Design 3D Models, and Enhance Productivity.
Clarifai
Clarifai is a full-stack AI developer platform that provides a range of tools and services for building and deploying AI applications. The platform includes a variety of computer vision, natural language processing, and generative AI models, as well as tools for data preparation, model training, and model deployment. Clarifai is used by a variety of businesses and organizations, including Fortune 500 companies, startups, and government agencies.
Clarifai
Clarifai is a full-stack AI platform that provides developers and ML engineers with the fastest, production-grade deep learning platform. It offers a wide range of features, including data preparation, model building, model operationalization, and AI workflows. Clarifai is used by a variety of companies, including Fortune 500 companies and startups, to build AI applications in a variety of industries, including retail, manufacturing, and healthcare.
Robo Translator
Robo Translator is an AI-powered translation tool that enables users to easily localize their content into multiple languages. With the latest OpenAI models and Azure-powered text-to-speech technology, it offers accurate translation, audio transcription, and closed caption localization services. Users can translate audio, video, and text documents, auto-translate YouTube video captions, and localize software files effortlessly. The tool provides encrypted file uploads for enhanced privacy and offers a pay-as-you-go pricing model. Robo Translator simplifies the localization process, making content more accessible to a global audience.
Novita AI
Novita AI is an AI cloud platform offering Model APIs, Serverless, and GPU Instance services in a cost-effective and integrated manner to accelerate AI businesses. It provides optimized models for high-quality dialogue use cases, full spectrum AI APIs for image, video, audio, and LLM applications, serverless auto-scaling based on demand, and customizable GPU solutions for complex AI tasks. The platform also includes a Startup Program, 24/7 service support, and has received positive feedback for its reasonable pricing and stable services.

LLMStack
LLMStack is an open-source platform that allows users to build AI Agents, workflows, and applications using their own data. It is a no-code AI app builder that supports model chaining from major providers like OpenAI, Cohere, Stability AI, and Hugging Face. Users can import various data sources such as Web URLs, PDFs, audio files, and more to enhance generative AI applications and chatbots. With a focus on collaboration, LLMStack enables users to share apps publicly or restrict access, with viewer and collaborator roles for multiple users to work together. Powered by React, LLMStack provides an easy-to-use interface for building AI applications.
Infrabase.ai
Infrabase.ai is a directory of AI infrastructure products that helps users discover and explore a wide range of tools for building world-class AI products. The platform offers a comprehensive directory of products in categories such as Vector databases, Prompt engineering, Observability & Analytics, Inference APIs, Frameworks & Stacks, Fine-tuning, Audio, and Agents. Users can find tools for tasks like data storage, model development, performance monitoring, and more, making it a valuable resource for AI projects.
Stable Audio
Stable Audio is a generative AI tool that allows users to create high-quality music and sound effects. It is powered by the latest audio diffusion models and offers a range of features that make it easy to create custom music. With Stable Audio, users can generate music of any length, style, or genre, and they can even use their own voice or instruments to create unique tracks. The generated audio can be downloaded in 44.1 kHz stereo and used in commercial projects.
Audiobox
Audiobox is an AI tool developed by Meta for audio generation. It allows users to create custom audio content by generating voices and sound effects using voice inputs and natural language text prompts. The tool includes various models such as Audiobox Speech and Audiobox Sound, all built upon the shared self-supervised model Audiobox SSL. Audiobox aims to make AI safe and accessible for everyone by providing a platform for creative audio storytelling and research in the field of audio generation.
Music AI
Music AI is an AI audio platform that offers state-of-the-art ethical AI solutions for audio and music applications. It provides a wide range of tools and modules for tasks such as stem separation, transcription, mixing, mastering, content generation, effects, utilities, classification, enhancement, style transfer, and more. The platform aims to streamline audio processing workflows, enhance creativity, improve accuracy, increase engagement, and save time for music professionals and businesses. Music AI prioritizes data security, privacy, and customization, allowing users to build custom workflows with over 50 AI modules.
AssemblyAI
AssemblyAI is an industry-leading Speech AI tool that offers powerful SpeechAI models for accurate transcription and understanding of speech. It provides breakthrough speech-to-text models, real-time captioning, and advanced speech understanding capabilities. AssemblyAI is designed to help developers build world-class products with unmatched accuracy and transformative audio intelligence.
pyannote AI Speaker Intelligence Platform
The pyannote AI Speaker Intelligence Platform is an advanced AI tool designed for developers to detect, segment, label, and separate speakers in any language. It offers state-of-the-art speaker diarization models that accurately identify speakers in audio recordings, providing valuable insights and improving productivity. With optimized AI models, the platform saves time, effort, and money by delivering top-tier performance. The tool is language agnostic and offers advanced features such as speaker partitioning, identification, overlapping speech detection, voice activity detection, speaker separation, and confidence scoring.
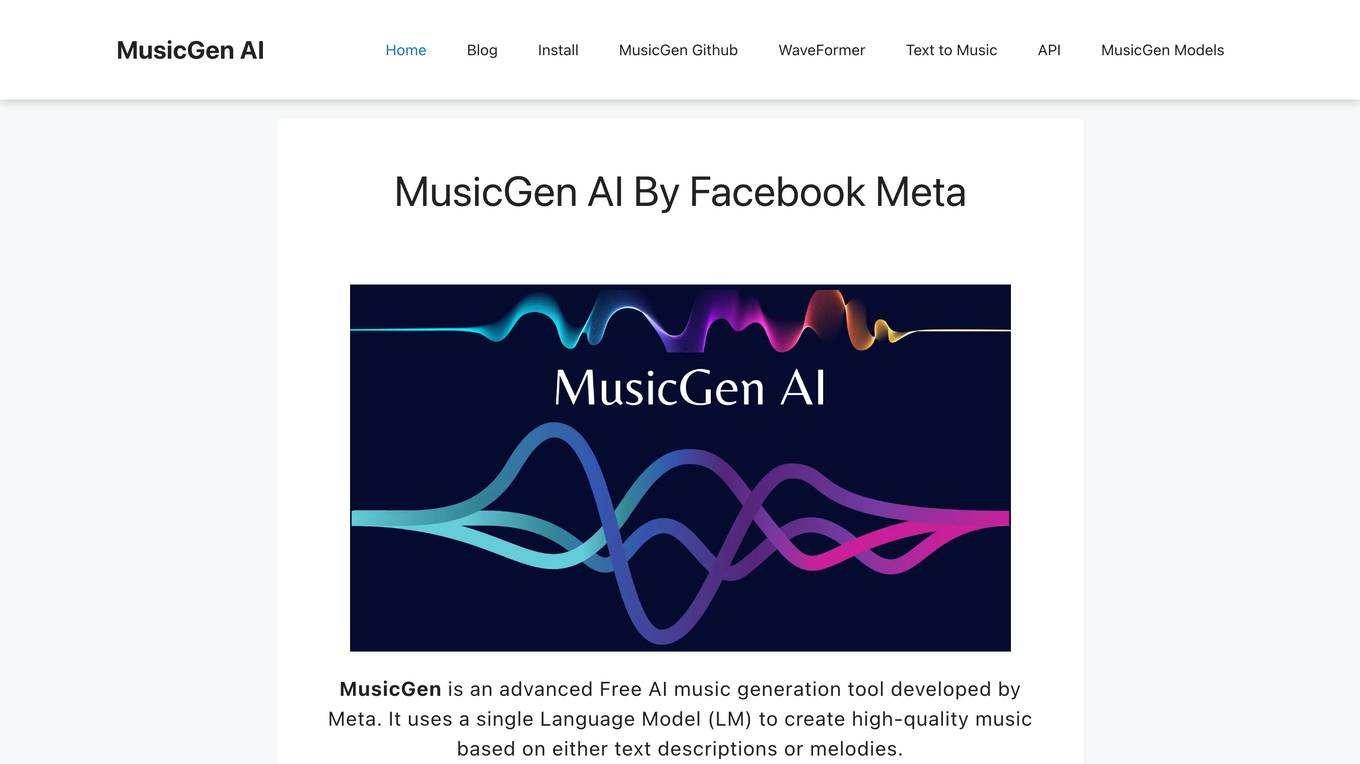
MusicGen AI
MusicGen AI is a free and advanced AI music generation tool developed by Meta. It utilizes a single Language Model (LM) to create high-quality music based on text descriptions, melodies, or audio prompts. MusicGen operates by encoding music into compressed tokens, which are then used to generate the music samples. It can produce music in various formats, including mono and stereo. MusicGen AI offers a range of features, including melody conditioning, text-conditional generation, audio-prompted generation, advanced model architecture, flexible generation modes, unconditional generation, extensive training dataset, and customizable generation process.
1 - Open Source Tools
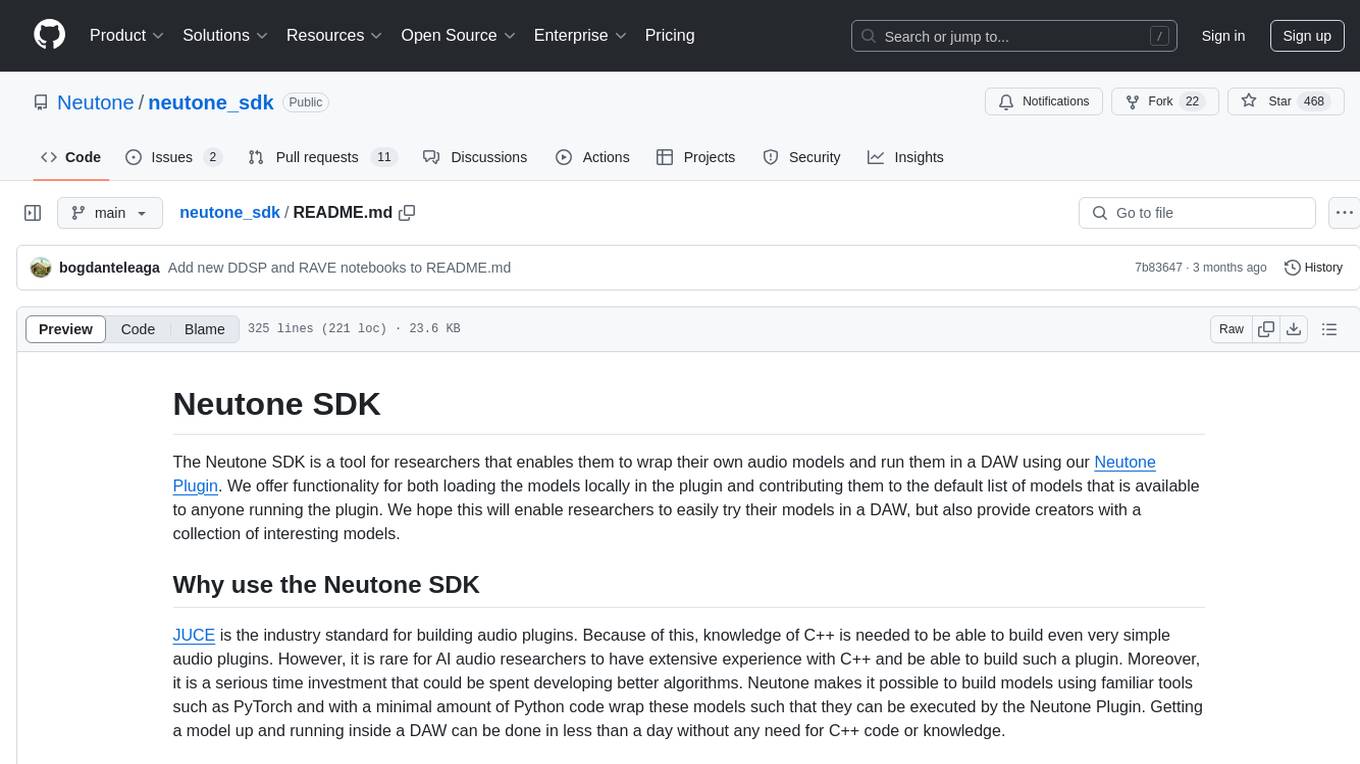
neutone_sdk
The Neutone SDK is a tool designed for researchers to wrap their own audio models and run them in a DAW using the Neutone Plugin. It simplifies the process by allowing models to be built using PyTorch and minimal Python code, eliminating the need for extensive C++ knowledge. The SDK provides support for buffering inputs and outputs, sample rate conversion, and profiling tools for model performance testing. It also offers examples, notebooks, and a submission process for sharing models with the community.
20 - OpenAI Gpts
![[AUDIO] Chinese Pronunciation Tutor Screenshot](/screenshots_gpts/g-Dr5b43UUk.jpg)
All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.
DIY Audio Guru
An assistant to help audio DIY'ers of any level, and anyone curios about audio to identify issues, find information, and general assistance in their journey.

MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!
Sound Sage
Top-level audio expert in audio engineering for music, and film, with advanced knowledge of recording history, acoustics, gear, and plugins, with a sarcastic touch.
Able-Nature's Echo.
Guides users through beautiful landscapes with spatial audio for immersion.

ReaperGPT
Expert for the Reaper DAW with extensive knowledge on Reapack Packages, ReaScript, EEL, Lua, Python, general commands, and audio workflows.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.