AI tools for lip sync ai
Related Tools:
Lip Sync AI
Lip Sync AI is a cutting-edge online AI tool that transforms audio into synchronized video content. It offers advanced capabilities to create lifelike talking avatars from text descriptions, videos, and images. With features like precise mouth animation, multi-language support, emotion preservation, and high-definition output, Lip Sync AI revolutionizes the way presentations, marketing materials, and educational content are produced. The platform is user-friendly, allowing users to easily upload their audio and visual assets to generate professional-quality videos with perfectly synchronized lip movements.
sync.labs
sync.labs is an AI lipsync tool designed for video content creators. It offers an API for realtime lip-sync to animate people to speak any language in any video. The tool allows users to create, modify, and animate humans in video content, making it versatile for various applications such as movies, podcasts, games, and animations. sync.labs aims to simplify the process of syncing audio with video content, providing a seamless experience for content creators.
MadLipz
MadLipz is an AI-powered application that allows users to create hilarious voiceover videos by dubbing their own voice or choosing from a variety of funny voices. With a simple and user-friendly interface, MadLipz provides a platform for users to unleash their creativity and share entertaining content with friends and followers. The app uses advanced AI technology to synchronize the lip movements with the audio, resulting in seamless and engaging videos that are sure to bring laughter to everyone who watches them.

Lipsyncer.ai
Lipsyncer.ai is an AI application that allows users to create AI lip-sync videos automatically. Users can upload videos, images, or audio files to synchronize lip movements with any audio. The application saves time by eliminating the need for manual video editing, making it ideal for businesses, advertising agencies, YouTubers, influencers, and marketing agencies. Lipsyncer.ai offers high-quality lip-syncing, multilingual text-to-speech presenters, and a pay-as-you-go pricing model. The application is integrated into popular design programs and e-commerce systems, providing digital efficiency to users' workflows.

LipDub AI
LipDub AI is an advanced AI tool that offers the most realistic AI lip sync and video translation capabilities. It allows users to add new audio to any video and perfectly lip syncs to match, delivering high-quality results. The tool is developed by an experienced in-house research team, led by Chief Scientist Daniel Cohen-Or, ensuring unmatched realism and quality in video content production. LipDub AI also enables users to localize video content into any language, replace dialogue effortlessly, and personalize content for various audiences, making it a versatile and powerful tool for creators and marketers alike.

Verbalate
Verbalate™ is a cutting-edge Video & Audio Translation, Voice Clone, and Lip Sync Software that empowers creators and businesses to translate their content into multiple languages effortlessly. With advanced technology, Verbalate offers voice cloning and lip-sync options to enhance engagement and break down language barriers. The platform supports over 230 languages and more than 800 language pairs, making it accessible to a global audience. Whether you are an individual creator or a company looking to expand internationally, Verbalate is your partner in reaching a diverse audience and increasing engagement.

Vozo
Vozo is an AI video generator application that allows users to rewrite, redub, and lip-sync their videos using prompts. It offers a range of tools to transform viral videos into new stories effortlessly. With Vozo, users can easily modify educational videos, create endless variants of ads, and translate videos into multiple languages. The application provides AI-driven prompts for rewriting scripts, redubbing with cloned voices, and editing voiceovers at the sentence level. Vozo also offers one-click multi-speaker lip-sync and video translation services with high precision. Users can repurpose their videos for different social platforms with just one click, ensuring maximum engagement across various platforms.

AdMaker.ai
AdMaker.ai is an AI-powered platform that allows users to create professional video ads, image ads, and various other advertising materials with the help of artificial intelligence technology. The platform offers a wide range of features such as AI image ad cloning, video ad transformation, AI avatar creation, lip sync technology, and a comprehensive ad library. Users can easily generate ads optimized for popular social media platforms like Facebook, Instagram, TikTok, and more. AdMaker.ai aims to simplify the ad creation process, providing users with fast, cost-effective, and high-quality solutions for their advertising needs.

VMEG
VMEG is an AI-powered video localization platform that offers a comprehensive suite of translation features to help users translate, localize, and dub videos in over 170 languages and 7000 voices. The platform includes tools for video translation, voice cloning, subtitle generation, voice generation, and lip sync, all powered by advanced AI technology. VMEG aims to break language barriers and make videos accessible to global audiences, providing users with efficient and high-quality solutions for content creation and translation.
AI LipSync Studio
AI LipSync Studio is a professional video lip synchronization and audio matching tool that utilizes cutting-edge artificial intelligence technology to transform videos with seamless audio-visual matching. It is perfect for video localization, dubbing, and comic content creation, offering features such as instant language translation with natural lip movements, multi-language support, and professional quality output for corporate communications. The application eliminates lip sync mismatches and ensures perfect audio-visual matching for all content creation needs, making it a preferred choice for content creators worldwide.

TranslateTracks
TranslateTracks is a premium AI dubbing and video translation service that provides cost-effective solutions for businesses looking to globalize their content. With its proprietary AI models and expert localization team, TranslateTracks offers accurate lip sync, superior quality, and a seamless process for multilingual video content. The platform empowers creators to reach a global audience by translating and dubbing their videos into multiple languages, making their content accessible to a wider range of viewers.

TranslateTracks
TranslateTracks is a premium AI dubbing and video translation service that provides cost-effective solutions for businesses looking to globalize their content. With its proprietary AI models and expert localization team, TranslateTracks offers accurate lip sync, superior quality, and a seamless process for multilingual video content. The platform empowers creators to reach a global audience by translating and dubbing their videos in over 50 languages, making their content accessible to viewers worldwide.


MyFaceSwap
MyFaceSwap is a free online AI tool that specializes in face swapping and lip syncing for videos and shorts. Users can easily upload images and videos to swap faces, create lip sync videos, and generate entertaining content. The platform ensures privacy and data security by deleting uploaded photos after video creation. MyFaceSwap enables users to unleash their creativity, make stunning videos, and become the star of any movie or music video.
Latent Sync
Latent Sync is an advanced AI-powered lip synchronization tool that revolutionizes the creation of high-quality, dynamic lip-sync videos. By harnessing stable diffusion and TREPA technology, Latent Sync delivers precise and realistic lip synchronization for various applications, such as film dubbing, virtual avatars, and advertising. The tool offers an end-to-end workflow integration, versatile application support, and dynamic effects, empowering creators to generate lifelike speaking animations effortlessly.

Deepshot
Deepshot is a dialogue generation and replacement software that allows users to create professional-looking videos with ease. It is fully customizable, allowing users to create unique content that will leave an everlasting impression on viewers. Deepshot is also cost-effective and time-saving, making it a great option for businesses and individuals who want to create high-quality videos without breaking the bank. With Deepshot, you can:
Gan.AI
Gan.AI is an AI-powered video creation platform that allows users to instantly create AI videos for business products. It offers features like creating videos from scripts, video personalization, text to speech, AI video generation, and screen recording. The platform is used by businesses across various industries to transform their operations and engage with customers through personalized video content. Gan.AI leverages advanced technologies like AI avatars, lip sync, and voice cloning to simplify the video creation process and deliver high-quality, customized videos at scale.

Duzo AI Translation
Duzo AI Translation is an AI-powered platform that enables users to break language barriers and reach a global audience by providing natural translations, voice cloning, lip-syncing, script editing, and subtitle services. Users can translate content to and from over 29 different languages, enhance their content, and grow their audience worldwide. The platform also offers text-to-speech capabilities in 32 languages, making content more accessible and engaging. With Duzo AI Translation, users can create multilingual videos with subtitles and lip-sync technology, expanding their reach and making their content available to a wider audience.
InfiniteTalk AI
InfiniteTalk AI is an advanced AI tool for audio-driven video generation, offering features such as sparse-frame dubbing and infinite-length video creation. It provides razor-accurate lip sync, expressive full-body motion, and rock-solid identity preservation powered by next-gen technology. Users can upload videos or images and dub them with speech or dialogue, generating lip-synced animated videos with smooth motion. The application supports both video-to-video dubbing and image-to-video generation, maintaining consistency in face, posture, lighting, and background throughout the video. InfiniteTalk AI offers stability, realism, and various resolution options for exporting videos.

Lip Care Guide
Master the art of lip care with expert tips for everlasting hydration and health. Discover the secrets to soft, supple lips with tailored advice and natural remedies. 💋🌿
talking-avatar-with-ai
The 'talking-avatar-with-ai' project is a digital human system that utilizes OpenAI's GPT-3 for generating responses, Whisper for audio transcription, Eleven Labs for voice generation, and Rhubarb Lip Sync for lip synchronization. The system allows users to interact with a digital avatar that responds with text, facial expressions, and animations, creating a realistic conversational experience. The project includes setup for environment variables, chat prompt templates, chat model configuration, and structured output parsing to enhance the interaction with the digital human.
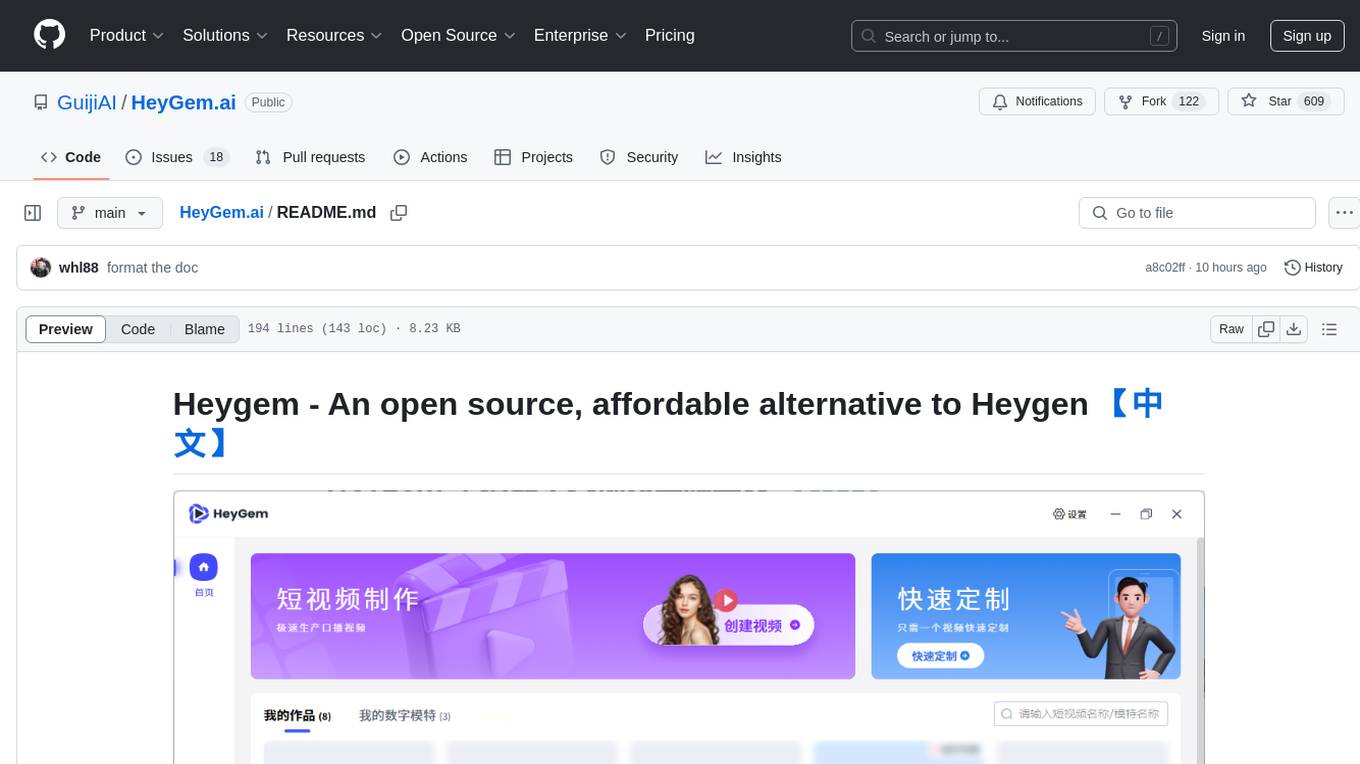
HeyGem.ai
Heygem is an open-source, affordable alternative to Heygen, offering a fully offline video synthesis tool for Windows systems. It enables precise appearance and voice cloning, allowing users to digitalize their image and drive virtual avatars through text and voice for video production. With core features like efficient video synthesis and multi-language support, Heygem ensures a user-friendly experience with fully offline operation and support for multiple models. The tool leverages advanced AI algorithms for voice cloning, automatic speech recognition, and computer vision technology to enhance the virtual avatar's performance and synchronization.
ai-game-development-tools
Here we will keep track of the AI Game Development Tools, including LLM, Agent, Code, Writer, Image, Texture, Shader, 3D Model, Animation, Video, Audio, Music, Singing Voice and Analytics. 🔥 * Tool (AI LLM) * Game (Agent) * Code * Framework * Writer * Image * Texture * Shader * 3D Model * Avatar * Animation * Video * Audio * Music * Singing Voice * Speech * Analytics * Video Tool

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
AITreasureBox
AITreasureBox is a comprehensive collection of AI tools and resources designed to simplify and accelerate the development of AI projects. It provides a wide range of pre-trained models, datasets, and utilities that can be easily integrated into various AI applications. With AITreasureBox, developers can quickly prototype, test, and deploy AI solutions without having to build everything from scratch. Whether you are working on computer vision, natural language processing, or reinforcement learning projects, AITreasureBox has something to offer for everyone. The repository is regularly updated with new tools and resources to keep up with the latest advancements in the field of artificial intelligence.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.
GMTalker
GMTalker is an interactive digital human rendered by Unreal Engine, developed by the Media Intelligence Team at Bright Laboratory. The system integrates speech recognition, speech synthesis, natural language understanding, and lip-sync animation driving. It supports rapid deployment on Windows with only 2GB of VRAM required. The project showcases two 3D cartoon digital human avatars suitable for presentations, expansions, and commercial integration.

MITSUHA
OneReality is a virtual waifu/assistant that you can speak to through your mic and it'll speak back to you! It has many features such as: * You can speak to her with a mic * It can speak back to you * Has short-term memory and long-term memory * Can open apps * Smarter than you * Fluent in English, Japanese, Korean, and Chinese * Can control your smart home like Alexa if you set up Tuya (more info in Prerequisites) It is built with Python, Llama-cpp-python, Whisper, SpeechRecognition, PocketSphinx, VITS-fast-fine-tuning, VITS-simple-api, HyperDB, Sentence Transformers, and Tuya Cloud IoT.

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.
Linly-Talker
Linly-Talker is an innovative digital human conversation system that integrates the latest artificial intelligence technologies, including Large Language Models (LLM) 🤖, Automatic Speech Recognition (ASR) 🎙️, Text-to-Speech (TTS) 🗣️, and voice cloning technology 🎤. This system offers an interactive web interface through the Gradio platform 🌐, allowing users to upload images 📷 and engage in personalized dialogues with AI 💬.
NeuroSandboxWebUI
A simple and convenient interface for using various neural network models. Users can interact with LLM using text, voice, and image input to generate images, videos, 3D objects, music, and audio. The tool supports a wide range of models for different tasks such as image generation, video generation, audio file separation, voice conversion, and more. Users can also view files from the outputs directory in a gallery, download models, change application settings, and check system sensors. The goal of the project is to create an easy-to-use application for utilizing neural network models.
VideoChat
VideoChat is a real-time voice interaction digital human tool that supports end-to-end voice solutions (GLM-4-Voice - THG) and cascade solutions (ASR-LLM-TTS-THG). Users can customize appearance and voice, support voice cloning, and achieve low first-packet delay of 3s. The tool offers various modules such as ASR, LLM, MLLM, TTS, and THG for different functionalities. It requires specific hardware and software configurations for local deployment, and provides options for weight downloads and customization of digital human appearance and voice. The tool also addresses known issues related to resource availability, video streaming optimization, and model loading.
facefusion
FaceFusion is a next-generation face swapper and enhancer that allows users to seamlessly swap faces in images and videos, as well as enhance facial features for a more polished and refined look. With its advanced deep learning models, FaceFusion provides users with a wide range of options for customizing their face swaps and enhancements, making it an ideal tool for content creators, artists, and anyone looking to explore their creativity with facial manipulation.
facefusion-docker
FaceFusion Docker is an industry leading face manipulation platform that provides a seamless way to manipulate faces in images and videos. The repository offers Docker containers for CPU, CUDA, TensorRT, and ROCm environments, allowing users to easily set up and run the platform. Users can access different containers through specific ports to browse and interact with the face manipulation features. The platform is designed to be user-friendly and efficient for various face manipulation tasks.
facefusion-pinokio
FaceFusion Pinokio is an industry leading face manipulation platform. It provides advanced tools for manipulating and blending faces in images and videos. The platform offers a user-friendly interface and powerful features to create stunning visual effects. With FaceFusion Pinokio, users can seamlessly blend faces, swap facial features, and create unique and creative compositions. Whether you are a professional graphic designer, a social media influencer, or just someone looking to have fun with face manipulation, FaceFusion Pinokio has everything you need to bring your ideas to life.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.
VASA-1-hack
VASA-1-hack is a repository containing the VASA implementation separated from EMOPortraits, with all components properly configured for standalone training. It provides detailed setup instructions, prerequisites, project structure, configuration details, running training modes, troubleshooting tips, monitoring training progress, development information, and acknowledgments. The repository aims to facilitate training volumetric avatar models with configurable parameters and logging levels for efficient debugging and testing.