Best AI tools for< Understand Images >
20 - AI tool Sites
Qwen
Qwen is an AI tool that focuses on developing and releasing various language models, including dense models, coding models, mathematical models, and vision language models. The Qwen family offers open-source models with different parameter ranges to cater to various user needs, such as production use, mobile applications, coding assistance, mathematical problem-solving, and visual understanding of images and videos. Qwen aims to enhance intelligence and provide smarter and more knowledgeable models for developers and users.

Molmo AI
Molmo AI is a powerful, open-source multimodal AI model revolutionizing visual understanding. It helps developers easily build tools that can understand images and interact with the world in useful ways. Molmo AI offers exceptional image understanding, efficient data usage, open and accessible features, on-device compatibility, and a new era in multimodal AI development. It closes the gap between open and closed AI models, empowers the AI community with open access, and efficiently utilizes data for superior performance.

88stacks
88stacks is a website that provides resources and tools for mastering Generative AI and Stable Diffusion. It offers a variety of software tools, tutorials, and databases to help users create and understand generative AI images. The website also publishes free designs and concepts created using generative AI.

ToolsIT
ToolsIT is an AI-powered tool that helps users generate high-quality content, including blog posts, articles, social media posts, and more. It offers a variety of templates and features to help users create engaging and effective content quickly and easily.
Hive AI
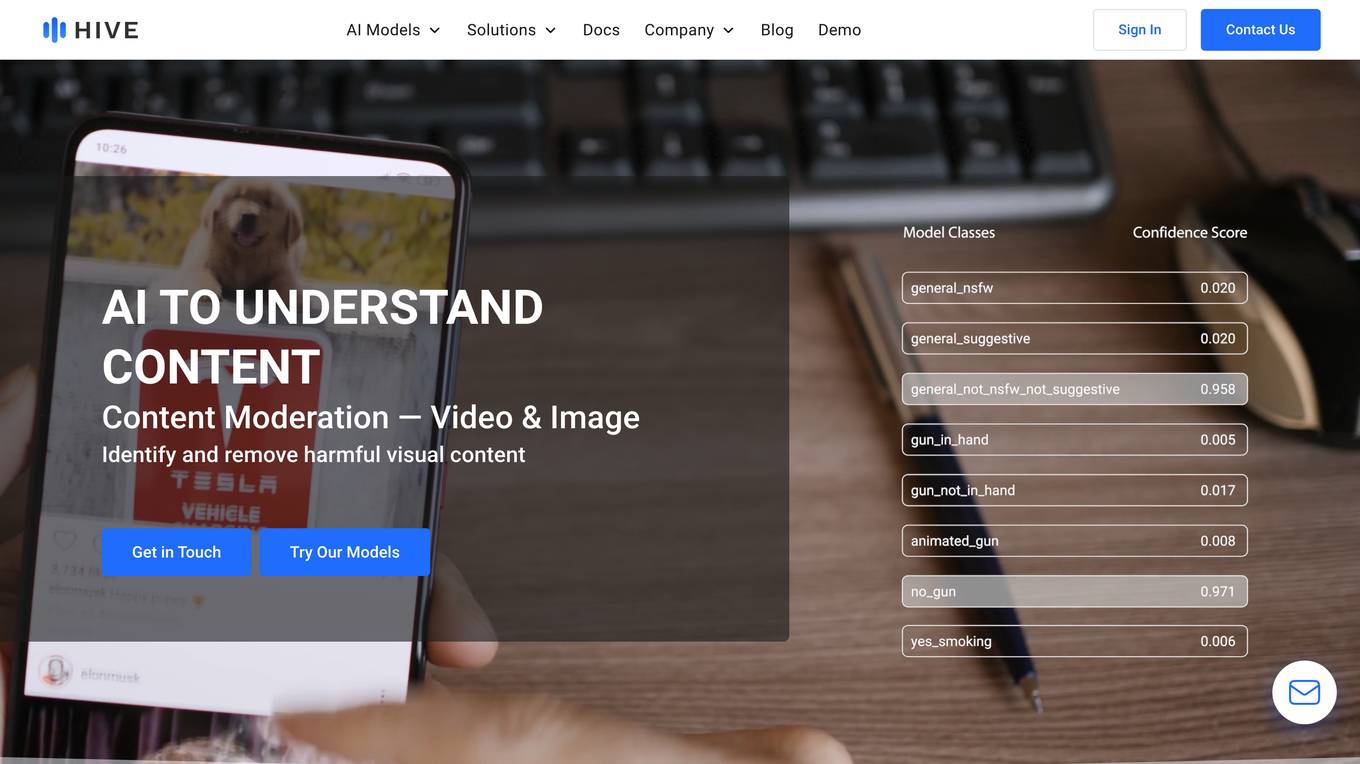
Hive AI provides a suite of AI models and solutions for understanding, searching, and generating content. Their AI models can be integrated into applications via APIs, enabling developers to add advanced content understanding capabilities to their products. Hive AI's solutions are used by businesses in various industries, including digital platforms, sports, media, and marketing, to streamline content moderation, automate image search and authentication, measure sponsorships, and monetize ad inventory.
CLIP Interrogator
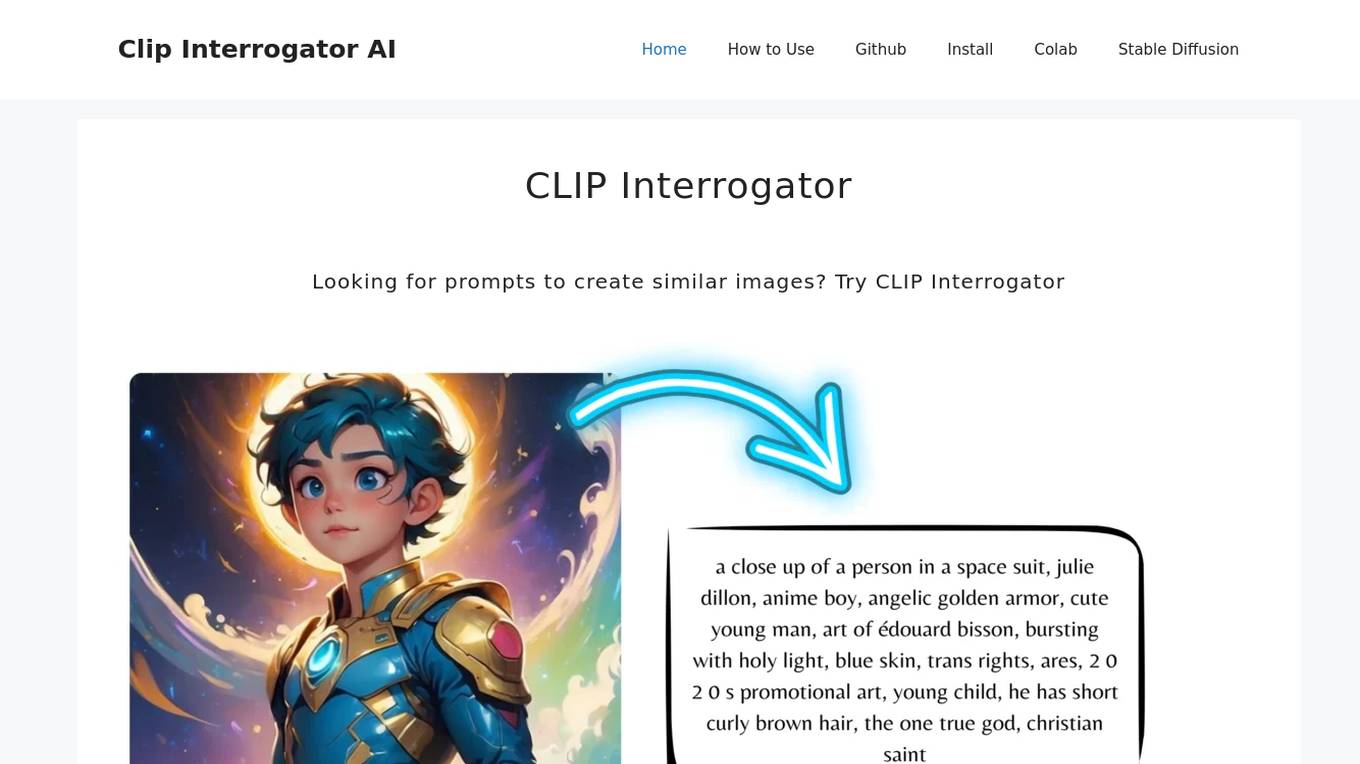
CLIP Interrogator is a tool that uses the CLIP (Contrastive Language–Image Pre-training) model to analyze images and generate descriptive text or tags. It effectively bridges the gap between visual content and language by interpreting the contents of images through natural language descriptions. The tool is particularly useful for understanding or replicating the style and content of existing images, as it helps in identifying key elements and suggesting prompts for creating similar imagery.

AI Image Generator FUNSHOW
AI Image Generator FUNSHOW is an online tool that allows users to generate AI-powered images based on their preferences. Users can choose different styles, sizes, and counts for the images they want to create. The tool provides a simple and user-friendly interface for generating images quickly and easily. With a focus on fun and creativity, AI Image Generator FUNSHOW aims to make image generation an enjoyable experience for users of all skill levels.
Image Narrate
This free AI image description generator tool allows users to upload an image and receive a detailed description of its contents. The tool utilizes advanced AI algorithms to analyze the image's elements, including color, shape, and texture, to generate a comprehensive description that captures the hidden meanings and emotions conveyed by the image. The tool is particularly useful for artists, designers, and anyone interested in gaining a deeper understanding of their own creations or exploring the hidden narratives within images.

Cut The SaaS
Cut The SaaS is an AI tool that empowers users to harness the power of AI and automation for various aspects of their professional and personal life. The platform offers a wide range of AI tools, content, and resources to help users stay updated on AI trends, enhance their content creation, and optimize their workflows.

Midjourney
Midjourney is a free online AI image generator that allows users to create high-quality images from simple text prompts. It is powered by advanced machine learning algorithms that can understand the meaning of words and convert them into realistic and visually appealing images. Midjourney is easy to use and does not require any special hardware or software. Users simply need to enter a text description of the image they want to generate and Midjourney will create it in a matter of seconds.

Siwalu
Siwalu is an AI-based image recognition application that specializes in identifying animals. The app helps pet owners learn more about their pets by providing specific information about their breed and characteristics. It offers a quick and reliable way to determine the breed of dogs, cats, and horses, including mixed breeds, without the need for costly DNA analysis. Siwalu aims to increase knowledge about global biodiversity by developing a universal animal recognition system.
Objective
Objective is an AI-native search platform designed for developers to build modern search experiences for web and mobile applications. It offers a multimodal search API that understands human language, images, and text relationships. The platform integrates various search techniques to provide natural and relevant search results, even with inconsistent data. Objective is trusted by great companies and accelerates data science roadmaps through its efficient search capabilities.

Totoy
Totoy is a Document AI tool that redefines the way documents are processed. Its API allows users to explain, classify, and create knowledge bases from documents without the need for training. The tool supports 19 languages and works with plain text, images, and PDFs. Totoy is ideal for automating workflows, complying with accessibility laws, and creating custom AI assistants for employees or customers.
AltTextGenerate
AltTextGenerate is a free online tool for generating alt text for images, enhancing SEO and accessibility. It uses AI-powered descriptions to provide suitable alt text for visuals. The tool leverages Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) to understand image content and generate descriptive text. AltTextGenerate offers a comprehensive solution for generating alt text across various platforms, including WordPress, Shopify, and CMSs. Users can benefit from SEO advantages, improved website ranking, and enhanced user experience through descriptive alt text.

Arting AI
Arting AI is an AI creation platform that allows users to turn their ideas into images and videos. It offers a versatile AI-driven creativity platform for both professional workflows and personal lifestyles, delivering a 500% efficiency boost. The platform is powered by extensive data training, enabling it to understand and adapt to various prompts, delivering exceptional creative content tailored to the user's needs. Arting AI is ideal for e-commerce, advertising, entertainment, education, interior design, and more, providing rapid generation of creative resources with a maximum response time of less than 3 seconds.
AIby.email
AIby.email is an AI-powered email assistant that helps you write better emails, faster. It uses natural language processing to understand your intent and generate personalized email responses. AIby.email also offers a variety of other features, such as email scheduling, tracking, and analytics.
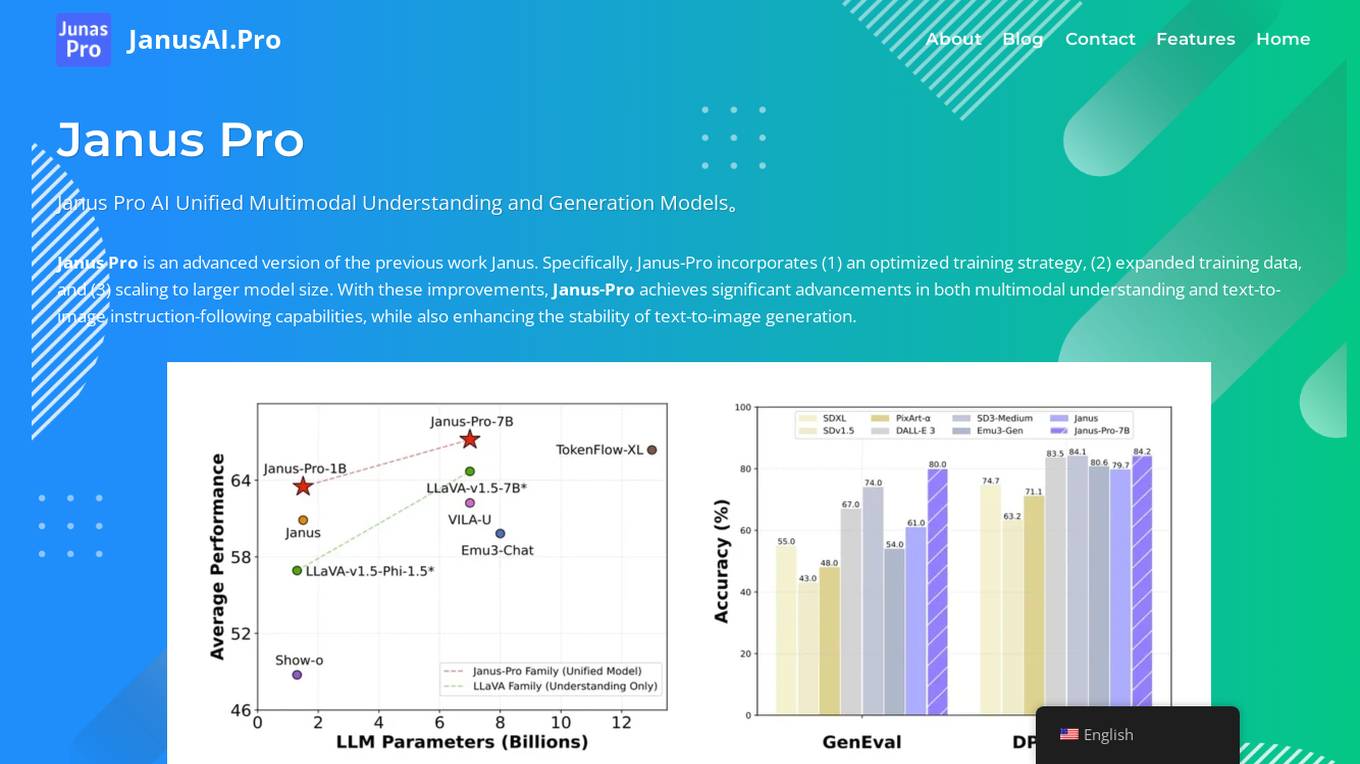
Janus Pro AI
Janus Pro AI is an advanced unified multimodal AI model that combines image understanding and generation capabilities. It incorporates optimized training strategies, expanded training data, and larger model scaling to achieve significant advancements in both multimodal understanding and text-to-image generation tasks. Janus Pro features a decoupled visual encoding system, outperforming leading models like DALL-E 3 and Stable Diffusion in benchmark tests. It offers open-source compatibility, vision processing specifications, cost-effective scalability, and an optimized training framework.

Visual Computing & Artificial Intelligence Lab at TUM
The Visual Computing & Artificial Intelligence Lab at TUM is a group of research enthusiasts advancing cutting-edge research at the intersection of computer vision, computer graphics, and artificial intelligence. Our research mission is to obtain highly-realistic digital replica of the real world, which include representations of detailed 3D geometries, surface textures, and material definitions of both static and dynamic scene environments. In our research, we heavily build on advances in modern machine learning, and develop novel methods that enable us to learn strong priors to fuel 3D reconstruction techniques. Ultimately, we aim to obtain holographic representations that are visually indistinguishable from the real world, ideally captured from a simple webcam or mobile phone. We believe this is a critical component in facilitating immersive augmented and virtual reality applications, and will have a substantial positive impact in modern digital societies.

Vizit
Vizit is a Visual AI & Content Effectiveness Analytics Platform that helps businesses optimize their visual content for better engagement and sales. Using AI technology, Vizit analyzes images and designs to understand consumer preferences, improve visuals, and monitor content effectiveness. The platform empowers brands to create high-impact visuals that drive conversions and boost online sales.

Pet Mind Reader
Pet Mind Reader is an AI-powered platform that revolutionizes how pet owners understand their furry companions. Using advanced artificial intelligence and computer vision technology, the platform analyzes pet images to generate creative and insightful interpretations of what pets might be thinking. It bridges scientific innovation with creative entertainment, offering imaginative insights based on AI analysis and animal behavior research. The goal is to spark imagination, encourage empathy towards pets, provide a fun, engaging experience, and potentially offer insights into pet behavior.
20 - Open Source AI Tools
llm_illustrated
llm_illustrated is an electronic book that visually explains various technical aspects of large language models using clear and easy-to-understand images. The book covers topics such as self-attention structure and code, absolute position encoding, KV cache visualization, transformers composition, and a relationship graph of participants in the Dartmouth Conference. The progress of the book is less than 10%, and readers can stay updated by following the WeChat official account and replying 'learn large models through images'. The PDF layout and Latex formatting are still being adjusted.
awesome-generative-ai-apis
Awesome Generative AI & LLM APIs is a curated list of useful APIs that allow developers to integrate generative models into their applications without building the models from scratch. These APIs provide an interface for generating text, images, or other content, and include pre-trained language models for various tasks. The goal of this project is to create a hub for developers to create innovative applications, enhance user experiences, and drive progress in the AI field.
SirChatalot
A Telegram bot that proves you don't need a body to have a personality. It can use various text and image generation APIs to generate responses to user messages. For text generation, the bot can use: * OpenAI's ChatGPT API (or other compatible API). Vision capabilities can be used with GPT-4 models. Function calling can be used with Function calling. * Anthropic's Claude API. Vision capabilities can be used with Claude 3 models. Function calling can be used with tool use. * YandexGPT API Bot can also generate images with: * OpenAI's DALL-E * Stability AI * Yandex ART This bot can also be used to generate responses to voice messages. Bot will convert the voice message to text and will then generate a response. Speech recognition can be done using the OpenAI's Whisper model. To use this feature, you need to install the ffmpeg library. This bot is also support working with files, see Files section for more details. If function calling is enabled, bot can generate images and search the web (limited).
swift-chat
SwiftChat is a fast and responsive AI chat application developed with React Native and powered by Amazon Bedrock. It offers real-time streaming conversations, AI image generation, multimodal support, conversation history management, and cross-platform compatibility across Android, iOS, and macOS. The app supports multiple AI models like Amazon Bedrock, Ollama, DeepSeek, and OpenAI, and features a customizable system prompt assistant. With a minimalist design philosophy and robust privacy protection, SwiftChat delivers a seamless chat experience with various features like rich Markdown support, comprehensive multimodal analysis, creative image suite, and quick access tools. The app prioritizes speed in launch, request, render, and storage, ensuring a fast and efficient user experience. SwiftChat also emphasizes app privacy and security by encrypting API key storage, minimal permission requirements, local-only data storage, and a privacy-first approach.

TalkWithGemini
Talk With Gemini is a web application that allows users to deploy their private Gemini application for free with one click. It supports Gemini Pro and Gemini Pro Vision models. The application features talk mode for direct communication with Gemini, visual recognition for understanding picture content, full Markdown support, automatic compression of chat records, privacy and security with local data storage, well-designed UI with responsive design, fast loading speed, and multi-language support. The tool is designed to be user-friendly and versatile for various deployment options and language preferences.

phidata
Phidata is a framework for building AI Assistants with memory, knowledge, and tools. It enables LLMs to have long-term conversations by storing chat history in a database, provides them with business context by storing information in a vector database, and enables them to take actions like pulling data from an API, sending emails, or querying a database. Memory and knowledge make LLMs smarter, while tools make them autonomous.

dora
Dataflow-oriented robotic application (dora-rs) is a framework that makes creation of robotic applications fast and simple. Building a robotic application can be summed up as bringing together hardwares, algorithms, and AI models, and make them communicate with each others. At dora-rs, we try to: make integration of hardware and software easy by supporting Python, C, C++, and also ROS2. make communication low latency by using zero-copy Arrow messages. dora-rs is still experimental and you might experience bugs, but we're working very hard to make it stable as possible.
gemini-next-chat
Gemini Next Chat is an open-source, extensible high-performance Gemini chatbot framework that supports one-click free deployment of private Gemini web applications. It provides a simple interface with image recognition and voice conversation, supports multi-modal models, talk mode, visual recognition, assistant market, support plugins, conversation list, full Markdown support, privacy and security, PWA support, well-designed UI, fast loading speed, static deployment, and multi-language support.
ComfyUI-fal-API
ComfyUI-fal-API is a repository containing custom nodes for using Flux models with fal API in ComfyUI. It provides nodes for image generation, video generation, language models, and vision language models. Users can easily install and configure the repository to access various nodes for different tasks such as generating images, creating videos, processing text, and understanding images. The repository also includes troubleshooting steps and is licensed under the Apache License 2.0.

EAGLE
Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.
aws-genai-llm-chatbot
This repository provides code to deploy a chatbot powered by Multi-Model and Multi-RAG using AWS CDK on AWS. Users can experiment with various Large Language Models and Multimodal Language Models from different providers. The solution supports Amazon Bedrock, Amazon SageMaker self-hosted models, and third-party providers via API. It also offers additional resources like AWS Generative AI CDK Constructs and Project Lakechain for building generative AI solutions and document processing. The roadmap and authors are listed, along with contributors. The library is licensed under the MIT-0 License with information on changelog, code of conduct, and contributing guidelines. A legal disclaimer advises users to conduct their own assessment before using the content for production purposes.

Awesome-Tabular-LLMs
This repository is a collection of papers on Tabular Large Language Models (LLMs) specialized for processing tabular data. It includes surveys, models, and applications related to table understanding tasks such as Table Question Answering, Table-to-Text, Text-to-SQL, and more. The repository categorizes the papers based on key ideas and provides insights into the advancements in using LLMs for processing diverse tables and fulfilling various tabular tasks based on natural language instructions.
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.
tiny-ai-client
Tiny AI Client is a lightweight tool designed for easy usage and switching of Language Model Models (LLMs) with support for vision and tool usage. It aims to provide a simple and intuitive interface for interacting with various LLMs, allowing users to easily set, change models, send messages, use tools, and handle vision tasks. The core logic of the tool is kept minimal and easy to understand, with separate modules for vision and tool usage utilities. Users can interact with the tool through simple Python scripts, passing model names, messages, tools, and images as required.

oreilly-hands-on-gpt-llm
This repository contains code for the O'Reilly Live Online Training for Deploying GPT & LLMs. Learn how to use GPT-4, ChatGPT, OpenAI embeddings, and other large language models to build applications for experimenting and production. Gain practical experience in building applications like text generation, summarization, question answering, and more. Explore alternative generative models such as Cohere and GPT-J. Understand prompt engineering, context stuffing, and few-shot learning to maximize the potential of GPT-like models. Focus on deploying models in production with best practices and debugging techniques. By the end of the training, you will have the skills to start building applications with GPT and other large language models.

aiid
The Artificial Intelligence Incident Database (AIID) is a collection of incidents involving the development and use of artificial intelligence (AI). The database is designed to help researchers, policymakers, and the public understand the potential risks and benefits of AI, and to inform the development of policies and practices to mitigate the risks and promote the benefits of AI. The AIID is a collaborative project involving researchers from the University of California, Berkeley, the University of Washington, and the University of Toronto.

easydiffusion
Easy Diffusion 3.0 is a user-friendly tool for installing and using Stable Diffusion on your computer. It offers hassle-free installation, clutter-free UI, task queue, intelligent model detection, live preview, image modifiers, multiple prompts file, saving generated images, UI themes, searchable models dropdown, and supports various image generation tasks like 'Text to Image', 'Image to Image', and 'InPainting'. The tool also provides advanced features such as custom models, merge models, custom VAE models, multi-GPU support, auto-updater, developer console, and more. It is designed for both new users and advanced users looking for powerful AI image generation capabilities.

ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.
20 - OpenAI Gpts

Praise Master
Our aim is to understand your unique needs intimately, providing customized commendations that sincerely convey your appreciation and recognition. Moreover, we will design and match the most suitable images to accompany the sentiment of your praise, enhancing the impact visually.
Ultimate Translator
Speak, snap, and understand the world. Your pocket-sized translator deciphers docs, images, and speech in a heartbeat with pronunciation guides and motivational boosts!
OpenGL 3.3 Graphics Programming Helper
Helps beginners understand OpenGL 3.3 concepts and terminology



Image Translator(→日本語)
画像中の文章を日本語に翻訳します。(使い方:画像をアップロードするだけ。プロンプトの文章は不要です。) 2023/12/29 より自然な日本語になるように修正



PhiloSongify
Ever wonder what your favorite tunes are really saying? Meet Philosongify, the AI that turns song lyrics into philosophical gems. It’s simple, insightful, and a bit cheeky. Plus, you get a cool DALL-E image for each song. Let's unravel music's mysteries together



Data Interpretation
Upload an image of a statistical analysis and we'll interpret the results: linear regression, logistic regression, ANOVA, cluster analysis, MDS, factor analysis, and many more


Reading Buddy
Catalytic questions for your readings. Upload an image of a page or send me a text, and reflect through inquiry...
How's it made?
I find videos on how items are made from your photos and describe the process.