Best AI tools for< Train Video Understanding >
20 - AI tool Sites
Globose Technology Solutions
Globose Technology Solutions Pvt Ltd (GTS) is an AI data collection company that provides various datasets such as image datasets, video datasets, text datasets, speech datasets, etc., to train machine learning models. They offer premium data collection services with a human touch, aiming to refine AI vision and propel AI forward. With over 25+ years of experience, they specialize in data management, annotation, and effective data collection techniques for AI/ML. The company focuses on unlocking high-quality data, understanding AI's transformative impact, and ensuring data accuracy as the backbone of reliable AI.

OneTake AI
OneTake AI is an autonomous video editor that uses artificial intelligence to edit videos with a single click. It can transcribe speech, add titles and transitions, and even translate videos into multiple languages. OneTake AI is designed to help businesses and individuals create professional-quality videos quickly and easily.

AiVANTA
AiVANTA is a scalable AI SaaS solution that offers Integrated Content Automation and Delivery (ICAD) for enterprises, enabling seamless AI video adoption. The platform provides a single-window solution to simplify all AI video needs, reducing video production costs by 80%. AiVANTA features a rich virtual avatar library, managed services for refining AI output, and tailored AI videos for various business needs. Its advantages include cost reduction, multi-lingual content, customization, quick turnaround, and trusted by brands. However, the disadvantages include the need for oversight in managed services, limited customization options, and potential language barriers. The application is suitable for BFSI, Healthcare, E-Commerce, and corporate training. Users can utilize AiVANTA for tasks like creating product information videos, training content, engaging with customers, and producing podcasts and explainer videos.
StoryFile
StoryFile is an AI application that pioneers Conversational Video AI, offering an interactive medium called a storyfile. The platform focuses on making authentic AI to enable users to have engaging conversations. StoryFile's technology utilizes AI principles and ethics to provide businesses with solutions through artificial intelligence. The application aims to revolutionize the way people interact with AI technology, emphasizing the importance of authenticity and meaningful conversations.

Tavus
Tavus is an AI tool that offers digital twin APIs for video generation and conversational video interfaces. It provides developers with cutting-edge AI technology to create immersive video experiences using AI-generated digital twins. Tavus' Phoenix model enables the generation of realistic digital replicas with natural face movements and expressions. The platform also supports rapid training, instant inference, and multi-language capabilities. With a developer-first approach, Tavus focuses on security, trust, and user experience, offering features like dubbing APIs and automated content moderation. The tool is praised for its speed of development cycles, high-quality AI video, and exceptional customer service.
404 Error Page
The website displays a '404 - Page not found' error message, indicating that the requested page does not exist or has been moved. It seems to be a standard error page that users encounter when they try to access a non-existent or relocated webpage.
VideoAsk by Typeform
VideoAsk by Typeform is an interactive video platform that helps streamline conversations and build business relationships at scale. It offers features such as asynchronous interviews, easy scheduling, tagging, gathering contact info, capturing leads, research and feedback, training, customer support, and more. Users can create interactive video forms, conduct async interviews, and engage with their audience through AI-powered video chatbots. The platform is user-friendly, code-free, and integrates with over 1,500 applications through Zapier.
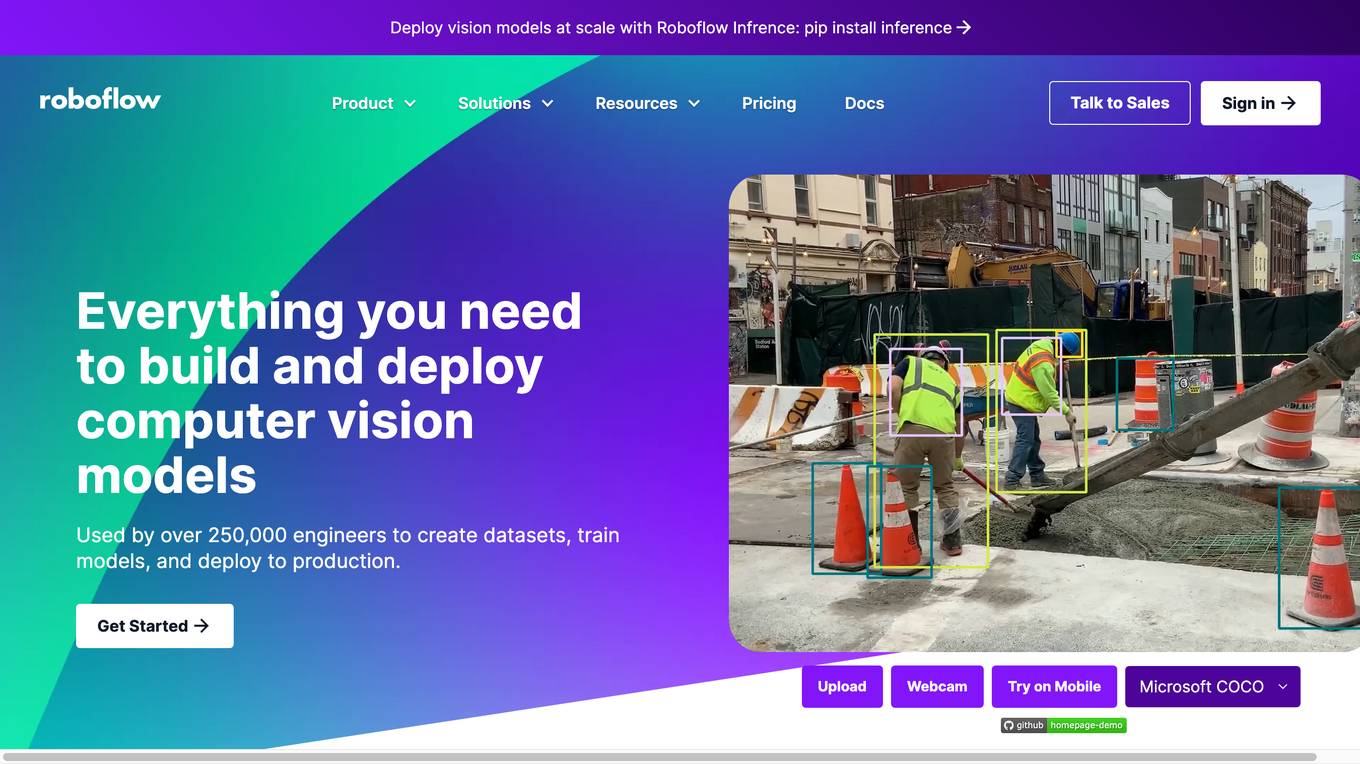
Roboflow
Roboflow is a platform that provides tools for building and deploying computer vision models. It offers a range of features, including data annotation, model training, and deployment. Roboflow is used by over 250,000 engineers to create datasets, train models, and deploy to production.
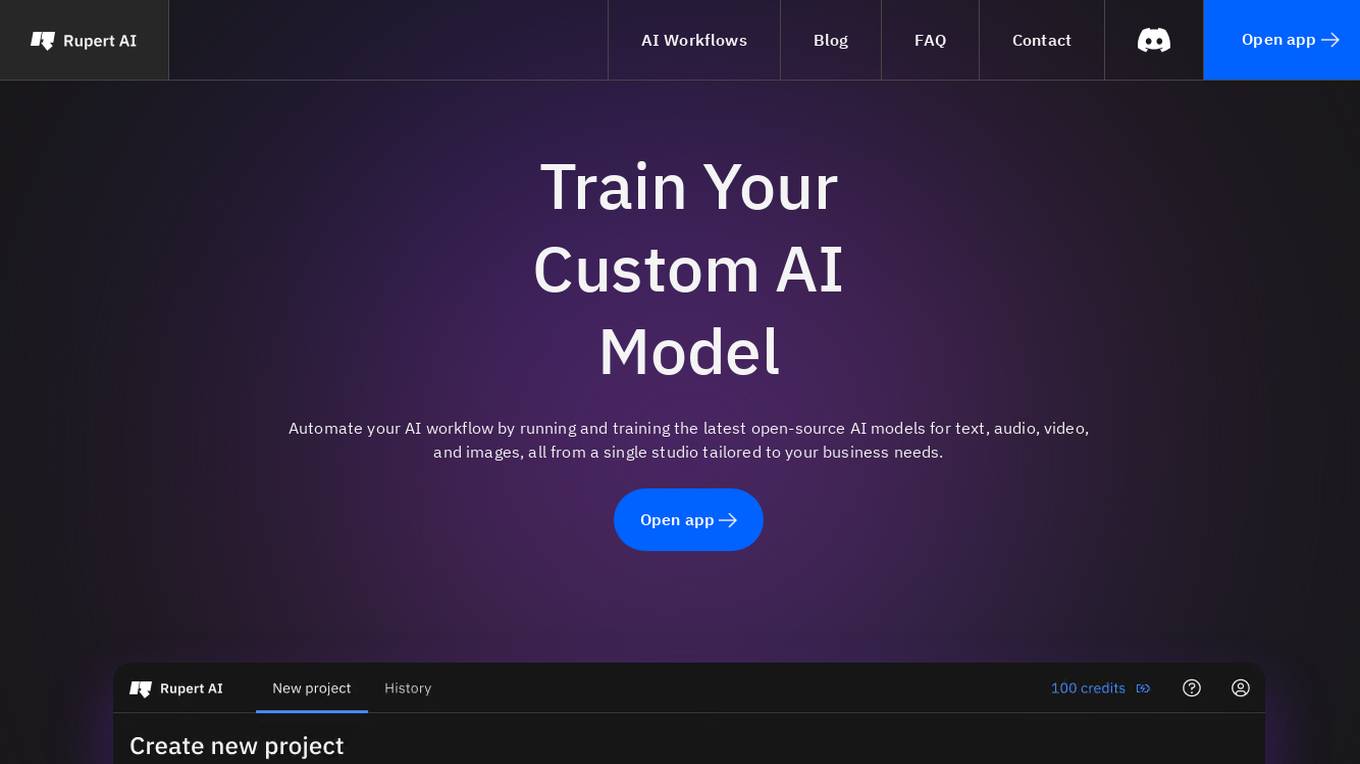
Rupert AI
Rupert AI is an all-in-one AI platform that allows users to train custom AI models for text, audio, video, and images. The platform streamlines AI workflows by providing access to the latest open-source AI models and tools in a single studio tailored to business needs. Users can automate their AI workflow, generate high-quality AI product photography, and utilize popular AI workflows like the AI Fashion Model Generator and Facebook Ad Testing Tool. Rupert AI aims to revolutionize the way businesses leverage AI technology to enhance marketing visuals, streamline operations, and make informed decisions.
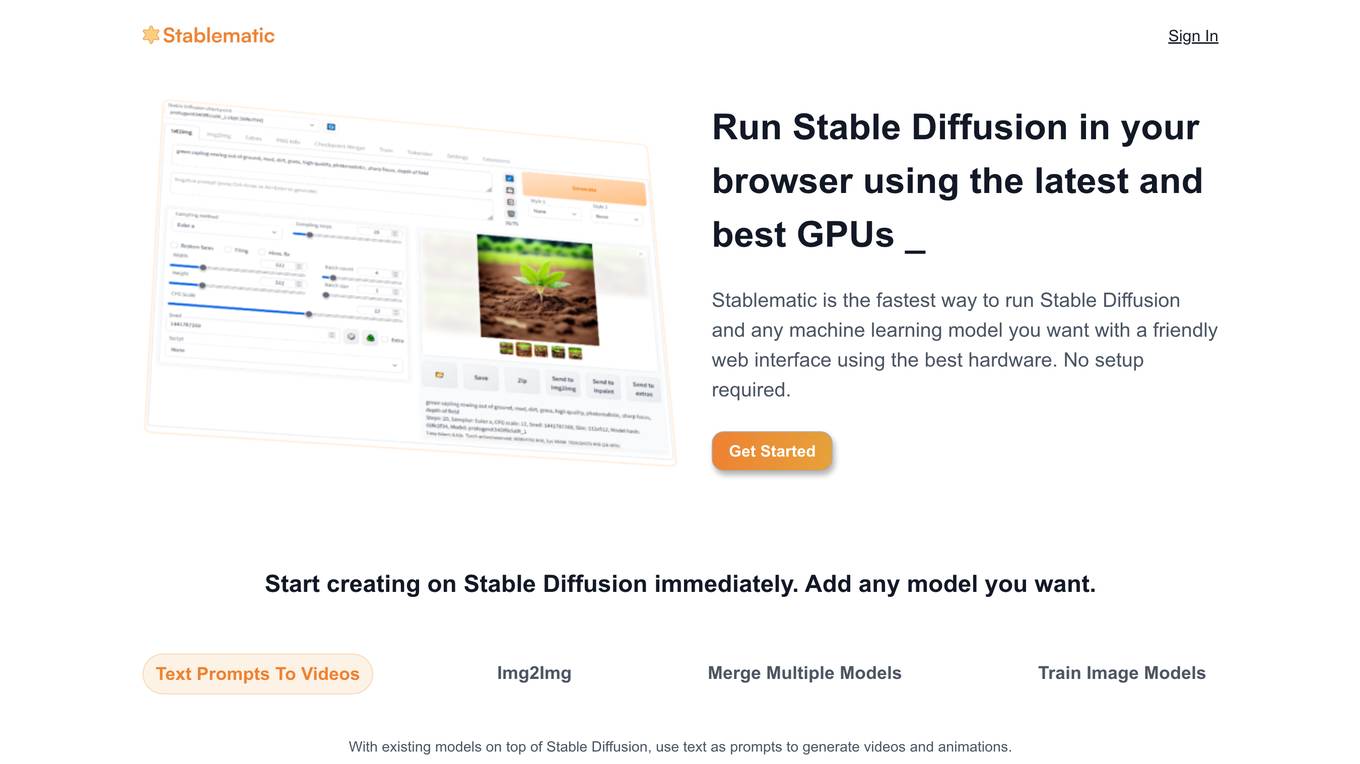
Stablematic
Stablematic is a web-based platform that allows users to run Stable Diffusion and other machine learning models without the need for local setup or hardware limitations. It provides a user-friendly interface, pre-installed plugins, and dedicated GPU resources for a seamless and efficient workflow. Users can generate images and videos from text prompts, merge multiple models, train custom models, and access a range of pre-trained models, including Dreambooth and CivitAi models. Stablematic also offers API access for developers and dedicated support for users to explore and utilize the capabilities of Stable Diffusion and other machine learning models.
Runway
Runway is an applied AI research company shaping the next era of art, entertainment, and human creativity. With a suite of creative tools designed to turn ideas into reality, Runway empowers users to explore the possibilities of AI-generated worlds. Founded in 2018, Runway has been pushing creativity forward with cutting-edge research in artificial intelligence and machine learning, collaborating with leading institutes worldwide.

Genice
Genice is an online face swap tool that allows users to effortlessly swap faces in videos or images. With its advanced technology, Genice can generate realistic results by incorporating multiple face images, delivering superior quality compared to the method of using just a single face image. Users can train their custom model with just about 10 images and endlessly generate their dream photos or videos. Genice also offers a variety of features such as changing faces in any video or image effortlessly, generating images through style selection, and providing free credits to new sign-up users.
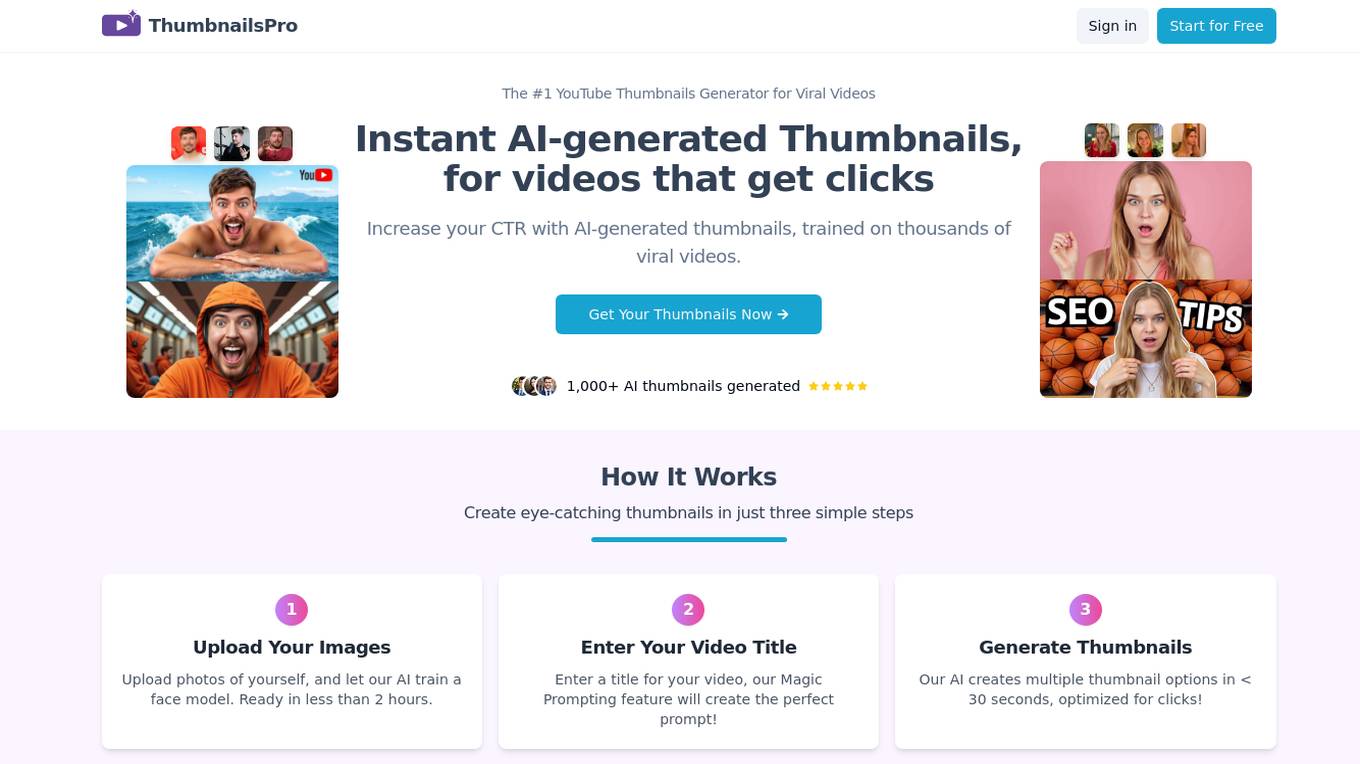
ThumbnailsPro
ThumbnailsPro is the #1 YouTube Thumbnails Generator for Viral Videos, offering instant AI-generated thumbnails to increase click-through rates. The AI is trained on thousands of viral videos to ensure optimized thumbnail creation. Users can upload images, enter video titles, and generate multiple thumbnail options in under 30 seconds. With affordable subscription plans, full ownership rights, and a user-friendly interface, ThumbnailsPro is designed for YouTube success.

Runway
Runway is a platform that provides tools and resources for artists and researchers to create and explore artificial intelligence-powered creative applications. The platform includes a library of pre-trained models, a set of tools for building and training custom models, and a community of users who share their work and collaborate on projects. Runway's mission is to make AI more accessible and understandable, and to empower artists and researchers to create new and innovative forms of creative expression.
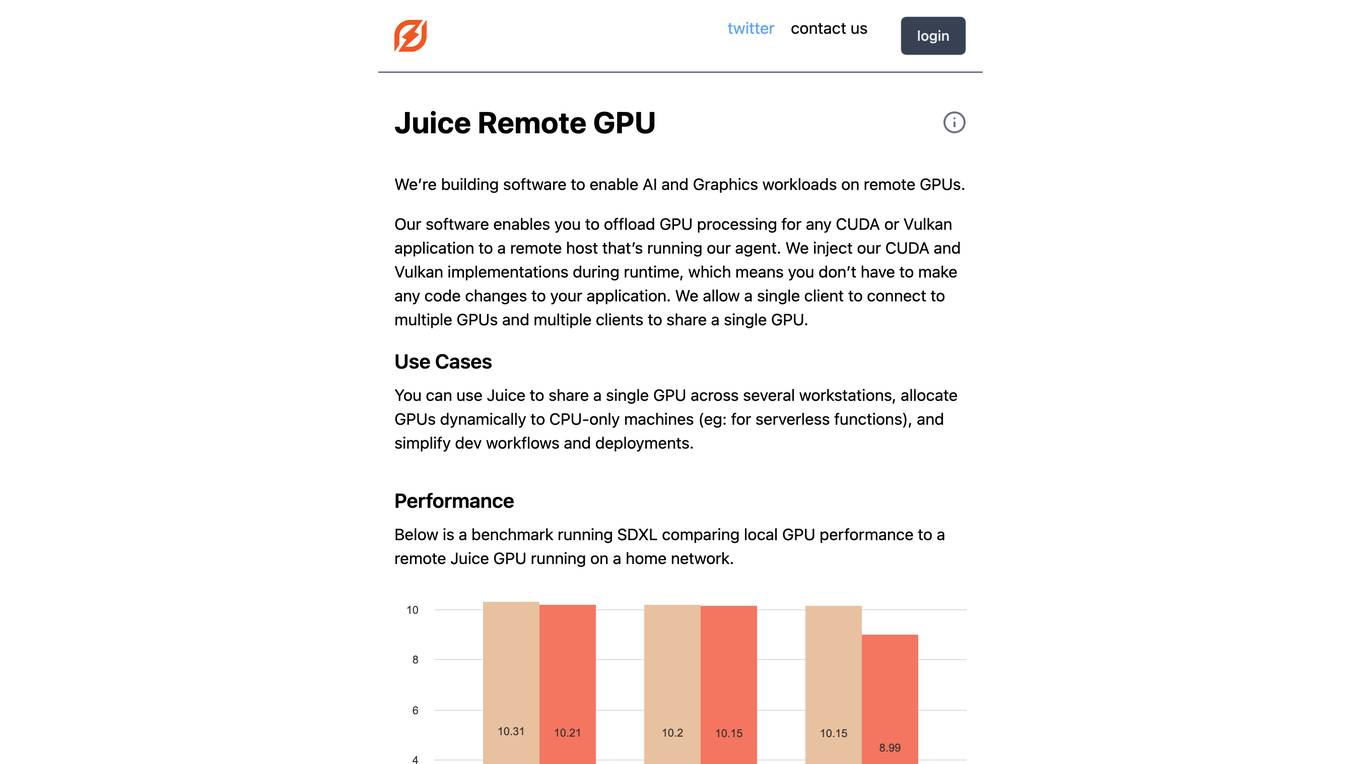
Juice Remote GPU
Juice Remote GPU is a software that enables AI and Graphics workloads on remote GPUs. It allows users to offload GPU processing for any CUDA or Vulkan application to a remote host running the Juice agent. The software injects CUDA and Vulkan implementations during runtime, eliminating the need for code changes in the application. Juice supports multiple clients connecting to multiple GPUs and multiple clients sharing a single GPU. It is useful for sharing a single GPU across multiple workstations, allocating GPUs dynamically to CPU-only machines, and simplifying development workflows and deployments. Juice Remote GPU performs within 5% of a local GPU when running in the same datacenter. It supports various APIs, including CUDA, Vulkan, DirectX, and OpenGL, and is compatible with PyTorch and TensorFlow. The team behind Juice Remote GPU consists of engineers from Meta, Intel, and the gaming industry.

Neural Frames
Neural Frames is an AI-powered video animation generator that allows users to create videos from text prompts. It is designed to be easy to use, even for those with no prior experience in video editing. Neural Frames offers a variety of features, including the ability to create videos in any style, control the camera, and add music. It is also possible to train custom AI models to achieve specific styles or character consistency.
BotB9
BotB9 is an AI chatbot application that is trained with your business data to provide personalized and programmable video guides. It serves as the missing link between businesses and their customers, offering features such as lead capture, order checkout, and customizable templates for various use cases. Users can interact with the chatbot to get answers to sales and support questions, create custom trained chatbots, and embed the chatbot on their websites and mobile apps. BotB9 aims to streamline customer interactions and improve user engagement through AI technology.

FeelMe AI
FeelMe AI is a patented technology that offers a unique interactive experience in the world of adult entertainment. By combining AI and interactive sex tech, FeelMe AI allows users to physically feel the content they are watching in real time. The platform supports a variety of interactive toys and works seamlessly with over 200 popular porn sites. With machine-learning video recognition software, FeelMe AI provides a next-gen, low-cost alternative to manually scripted content, offering users infinite pleasure and immersive experiences.
Kopyst
Kopyst is an AI-powered documentation tool that revolutionizes the process of creating engaging video and documents. It helps users streamline workflows, create user manuals, SOPs, and training documents with unmatched accuracy and efficiency. Kopyst offers features like instant documentation, versatile application for various document types, AI-powered intelligence, easy sharing and collaboration, and seamless integration with existing tools. The application empowers users to save time, reduce errors, optimize resources, and enhance productivity in documentation tasks.
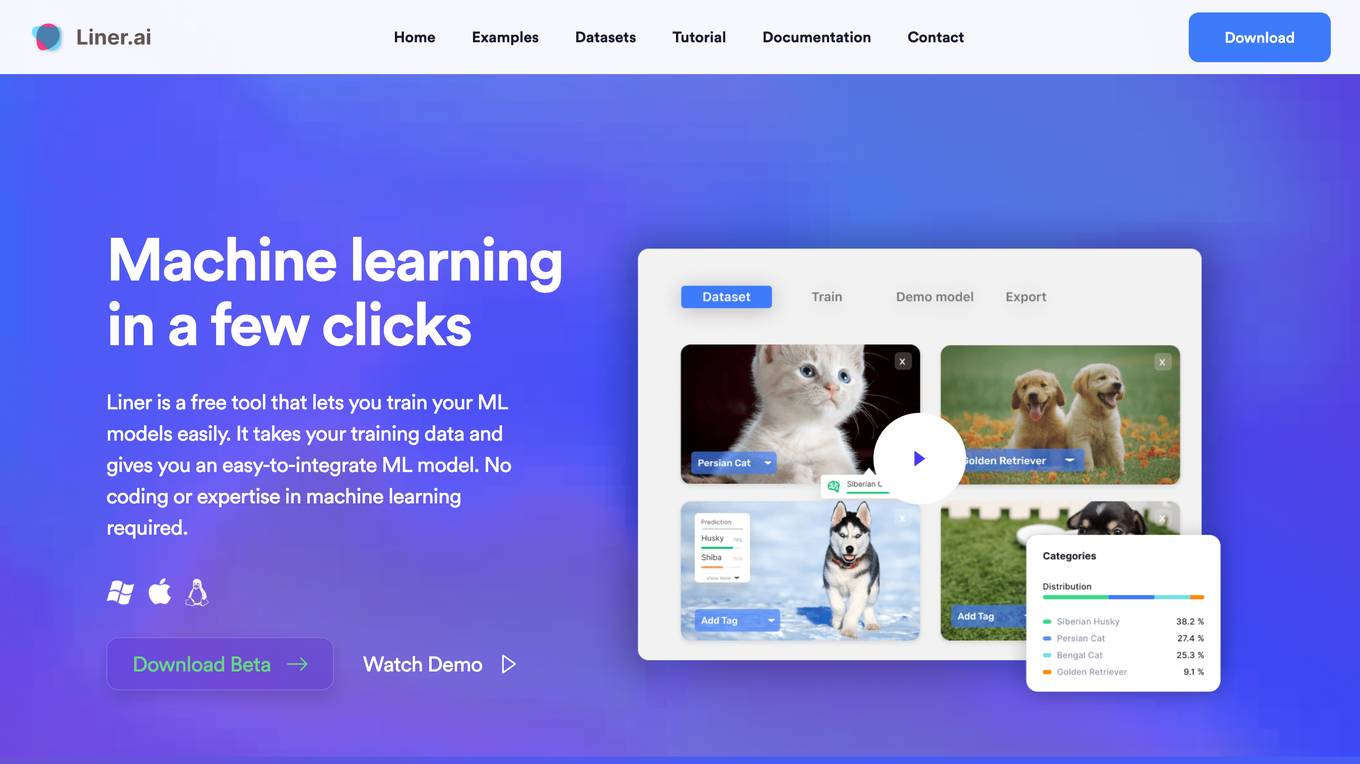
Liner.ai
Liner is a free and easy-to-use tool that allows users to train machine learning models without writing any code. It provides a user-friendly interface that guides users through the process of importing data, selecting a model, and training the model. Liner also offers a variety of pre-trained models that can be used for common tasks such as image classification, text classification, and object detection. With Liner, users can quickly and easily create and deploy machine learning applications without the need for specialized knowledge or expertise.
20 - Open Source AI Tools
Grounded-Video-LLM
Grounded-VideoLLM is a Video Large Language Model specialized in fine-grained temporal grounding. It excels in tasks such as temporal sentence grounding, dense video captioning, and grounded VideoQA. The model incorporates an additional temporal stream, discrete temporal tokens with specific time knowledge, and a multi-stage training scheme. It shows potential as a versatile video assistant for general video understanding. The repository provides pretrained weights, inference scripts, and datasets for training. Users can run inference queries to get temporal information from videos and train the model from scratch.

VideoRefer
VideoRefer Suite is a tool designed to enhance the fine-grained spatial-temporal understanding capabilities of Video Large Language Models (Video LLMs). It consists of three primary components: Model (VideoRefer) for perceiving, reasoning, and retrieval for user-defined regions at any specified timestamps, Dataset (VideoRefer-700K) for high-quality object-level video instruction data, and Benchmark (VideoRefer-Bench) to evaluate object-level video understanding capabilities. The tool can understand any object within a video.

VILA
VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.

VideoLLaMA2
VideoLLaMA 2 is a project focused on advancing spatial-temporal modeling and audio understanding in video-LLMs. It provides tools for multi-choice video QA, open-ended video QA, and video captioning. The project offers model zoo with different configurations for visual encoder and language decoder. It includes training and evaluation guides, as well as inference capabilities for video and image processing. The project also features a demo setup for running a video-based Large Language Model web demonstration.

Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.
ST-LLM
ST-LLM is a temporal-sensitive video large language model that incorporates joint spatial-temporal modeling, dynamic masking strategy, and global-local input module for effective video understanding. It has achieved state-of-the-art results on various video benchmarks. The repository provides code and weights for the model, along with demo scripts for easy usage. Users can train, validate, and use the model for tasks like video description, action identification, and reasoning.

TRACE
TRACE is a temporal grounding video model that utilizes causal event modeling to capture videos' inherent structure. It presents a task-interleaved video LLM model tailored for sequential encoding/decoding of timestamps, salient scores, and textual captions. The project includes various model checkpoints for different stages and fine-tuning on specific datasets. It provides evaluation codes for different tasks like VTG, MVBench, and VideoMME. The repository also offers annotation files and links to raw videos preparation projects. Users can train the model on different tasks and evaluate the performance based on metrics like CIDER, METEOR, SODA_c, F1, mAP, Hit@1, etc. TRACE has been enhanced with trace-retrieval and trace-uni models, showing improved performance on dense video captioning and general video understanding tasks.

Awesome-LLMs-for-Video-Understanding
Awesome-LLMs-for-Video-Understanding is a repository dedicated to exploring Video Understanding with Large Language Models. It provides a comprehensive survey of the field, covering models, pretraining, instruction tuning, and hybrid methods. The repository also includes information on tasks, datasets, and benchmarks related to video understanding. Contributors are encouraged to add new papers, projects, and materials to enhance the repository.

MM-RLHF
MM-RLHF is a comprehensive project for aligning Multimodal Large Language Models (MLLMs) with human preferences. It includes a high-quality MLLM alignment dataset, a Critique-Based MLLM reward model, a novel alignment algorithm MM-DPO, and benchmarks for reward models and multimodal safety. The dataset covers image understanding, video understanding, and safety-related tasks with model-generated responses and human-annotated scores. The reward model generates critiques of candidate texts before assigning scores for enhanced interpretability. MM-DPO is an alignment algorithm that achieves performance gains with simple adjustments to the DPO framework. The project enables consistent performance improvements across 10 dimensions and 27 benchmarks for open-source MLLMs.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.
VideoTuna
VideoTuna is a codebase for text-to-video applications that integrates multiple AI video generation models for text-to-video, image-to-video, and text-to-image generation. It provides comprehensive pipelines in video generation, including pre-training, continuous training, post-training, and fine-tuning. The models in VideoTuna include U-Net and DiT architectures for visual generation tasks, with upcoming releases of a new 3D video VAE and a controllable facial video generation model.
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
fairseq
Fairseq is a sequence modeling toolkit that enables researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. It provides reference implementations of various sequence modeling papers covering CNN, LSTM networks, Transformer networks, LightConv, DynamicConv models, Non-autoregressive Transformers, Finetuning, and more. The toolkit supports multi-GPU training, fast generation on CPU and GPU, mixed precision training, extensibility, flexible configuration based on Hydra, and full parameter and optimizer state sharding. Pre-trained models are available for translation and language modeling with a torch.hub interface. Fairseq also offers pre-trained models and examples for tasks like XLS-R, cross-lingual retrieval, wav2vec 2.0, unsupervised quality estimation, and more.

Macaw-LLM
Macaw-LLM is a pioneering multi-modal language modeling tool that seamlessly integrates image, audio, video, and text data. It builds upon CLIP, Whisper, and LLaMA models to process and analyze multi-modal information effectively. The tool boasts features like simple and fast alignment, one-stage instruction fine-tuning, and a new multi-modal instruction dataset. It enables users to align multi-modal features efficiently, encode instructions, and generate responses across different data types.

data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.
Gemini
Gemini is an open-source model designed to handle multiple modalities such as text, audio, images, and videos. It utilizes a transformer architecture with special decoders for text and image generation. The model processes input sequences by transforming them into tokens and then decoding them to generate image outputs. Gemini differs from other models by directly feeding image embeddings into the transformer instead of using a visual transformer encoder. The model also includes a component called Codi for conditional generation. Gemini aims to effectively integrate image, audio, and video embeddings to enhance its performance.
ABigSurveyOfLLMs
ABigSurveyOfLLMs is a repository that compiles surveys on Large Language Models (LLMs) to provide a comprehensive overview of the field. It includes surveys on various aspects of LLMs such as transformers, alignment, prompt learning, data management, evaluation, societal issues, safety, misinformation, attributes of LLMs, efficient LLMs, learning methods for LLMs, multimodal LLMs, knowledge-based LLMs, extension of LLMs, LLMs applications, and more. The repository aims to help individuals quickly understand the advancements and challenges in the field of LLMs through a collection of recent surveys and research papers.
Awesome-LLM-Long-Context-Modeling
This repository includes papers and blogs about Efficient Transformers, Length Extrapolation, Long Term Memory, Retrieval Augmented Generation(RAG), and Evaluation for Long Context Modeling.
20 - OpenAI Gpts
How to Train a Chessie
Comprehensive training and wellness guide for Chesapeake Bay Retrievers.
The Train Traveler
Friendly train travel guide focusing on the best routes, essential travel information, and personalized travel insights, for both experienced and novice travelers.
How to Train Your Dog (or Cat, or Dragon, or...)
Expert in pet training advice, friendly and engaging.
TrainTalk
Your personal advisor for eco-friendly train travel. Let's plan your next journey together!
Monster Battle - RPG Game
Train monsters, travel the world, earn Arena Tokens and become the ultimate monster battling champion of earth!
Hero Master AI: Superhero Training
Train to become a superhero or a supervillain. Master your powers, make pivotal choices. Each decision you make in this action-packed game not only shapes your abilities but also your moral alignment in the battle between good and evil. Another GPT Simulator by Dave Lalande

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch

Design Recruiter
Job interview coach for product designers. Train interviews and say stop when you need a feedback. You got this!!
Pocket Training Activity Expert
Expert in engaging, interactive training methods and activities.

RailwayGPT
Technical expert on locomotives, trains, signalling, and railway technology. Can answer questions and draw designs specific to transportation domain.