Best AI tools for< Train Documents >
20 - AI tool Sites
DocsAI
DocsAI is an AI-powered document companion that helps you organize, search, and chat with your documents. It integrates with various sources, including websites, text files, PDFs, Docx, Notion, and Confluence. You can customize the companion's appearance to match your brand and suggest better answers to improve its accuracy. DocsAI also offers a chat widget that can be embedded on any website, allowing you to chat with your documents and get summaries, insights, and leads. It is mobile and tablet-friendly, and you can export chats and analyze data to identify trends and improve customer satisfaction. DocsAI is open source and offers custom prompts and multi-language support.

Bothatch
Bothatch is a platform that allows users to create custom chatbots powered by OpenAI's GPT technology. With Bothatch, users can upload their own data and documents to train their chatbots, which can then be used to engage in meaningful and productive conversations. Bothatch is designed to be easy to use, with no coding or technical skills required. It is also affordable, with pricing plans starting at $0 per month.
UnravelX
UnravelX is an AI-powered platform that transforms documents into 3D interactive virtual scenarios for training purposes. It automates training processes by using generative AI to create immersive learning experiences. The platform caters to various industries such as F&B, Retail, Sales, and Hospitality, offering a cost-effective and efficient solution for upskilling employees. With over 60 years of combined AI and training expertise, UnravelX leads the innovation in scenario-based learning, providing a seamless onboarding experience for organizations.
Monkt
Monkt is a powerful document processing platform that transforms various document formats into AI-ready Markdown or structured JSON. It offers features like instant conversion of PDF, Word, PowerPoint, Excel, CSV, web pages, and raw HTML into clean markdown format optimized for AI/LLM systems. Monkt enables users to create intelligent applications, custom AI chatbots, knowledge bases, and training datasets. It supports batch processing, image understanding, LLM optimization, and API integration for seamless document processing. The platform is designed to handle document transformation at scale, with support for multiple file formats and custom JSON schemas.
DocsChat
DocsChat is an AI-powered document conversation tool that revolutionizes the way users interact with various types of documents. It leverages OCR-powered AI technology to streamline document interactions, making it easier to comprehend, exchange knowledge, troubleshoot, and navigate through different document types. With a focus on enhancing user experiences across reading, research, business, legal, and training domains, DocsChat offers a versatile platform for effortless and personalized document engagement.

Whismer
Whismer is an AI application that allows users to build custom AI chatbots using their own data. The platform enables users to train their own ChatGPT by uploading documents, adding links, and writing notes. With Whismer, users can customize resources to help the AI system better adapt to specific fields or tasks, improving accuracy and efficiency. The AI proactively learns from user resources to solve various problems. Users can create a professional AI knowledge base in minutes, allowing the AI to learn and provide accurate answers. Whismer also enables users to share their customized AI projects with others, making AI accessible to more people.
Artiko.ai
Artiko.ai is a multi-model AI chat platform that integrates advanced AI models such as ChatGPT, Claude 3, Gemini 1.5, and Mistral AI. It offers a convenient and cost-effective solution for work, business, or study by providing a single chat interface to harness the power of multi-model AI. Users can save time and money while achieving better results through features like text rewriting, data conversation, AI assistants, website chatbot, PDF and document chat, translation, brainstorming, and integration with various tools like Woocommerce, Amazon, Salesforce, and more.
Scribe
Scribe is a tool that allows users to create step-by-step guides for any process. It uses AI to automatically generate instructions and screenshots, and it can be used to document processes, train employees, and answer questions. Scribe is available as a Chrome extension and a desktop app.
H2O.ai
H2O.ai is a leading platform that offers a convergence of the world's best predictive and generative AI solutions for private and protected data. The platform provides a wide range of AI agents, digital assistants, business insights, predictive AI tools, and solutions for model builders, data scientists, and enterprise developers. H2O.ai is known for its innovative AI technologies that empower organizations to accelerate model development, train custom models, and manage the full ML lifecycle. With a focus on privacy and security, H2O.ai is trusted by banks, telcos, and government agencies worldwide.
Cody
Cody is an intelligent AI assistant designed to boost team productivity by providing instant answers, support, troubleshooting, and idea generation. It can be trained on your business knowledge base to cater to your specific needs, making it a valuable asset for various departments such as marketing, HR, IT support, business consultancy, creative tasks, sales, training, hiring, customer support, and translation. Cody offers features like prompt manager, focus mode, conversation logs, scratchpad, and source checking, ensuring efficient and tailored assistance. With multilingual capabilities and customizable access controls, Cody prioritizes data security and user experience.
Lamini
Lamini is an enterprise-level LLM platform that offers precise recall with Memory Tuning, enabling teams to achieve over 95% accuracy even with large amounts of specific data. It guarantees JSON output and delivers massive throughput for inference. Lamini is designed to be deployed anywhere, including air-gapped environments, and supports training and inference on Nvidia or AMD GPUs. The platform is known for its factual LLMs and reengineered decoder that ensures 100% schema accuracy in the JSON output.
Kudra
Kudra is an AI-powered data extraction tool that offers dedicated solutions for finance, human resources, logistics, legal, and more. It effortlessly extracts critical data fields, tables, relationships, and summaries from various documents, transforming unstructured data into actionable insights. Kudra provides customizable AI models, seamless integrations, and secure document processing while supporting over 20 languages. With features like custom workflows, model training, API integration, and workflow builder, Kudra aims to streamline document processing for businesses of all sizes.
Docsumo
Docsumo is an advanced Document AI platform designed for scalability and efficiency. It offers a wide range of capabilities such as pre-processing documents, extracting data, reviewing and analyzing documents. The platform provides features like document classification, touchless processing, ready-to-use AI models, auto-split functionality, and smart table extraction. Docsumo is a leader in intelligent document processing and is trusted by various industries for its accurate data extraction capabilities. The platform enables enterprises to digitize their document processing workflows, reduce manual efforts, and maximize data accuracy through its AI-powered solutions.
Kopyst
Kopyst is an AI-powered documentation tool that revolutionizes the process of creating engaging video and documents. It helps users streamline workflows, create user manuals, SOPs, and training documents with unmatched accuracy and efficiency. Kopyst offers features like instant documentation, versatile application for various document types, AI-powered intelligence, easy sharing and collaboration, and seamless integration with existing tools. The application empowers users to save time, reduce errors, optimize resources, and enhance productivity in documentation tasks.
Quivr
Quivr is an open-source chat-powered second brain application that transforms private and enterprise knowledge into a personal AI assistant. It continuously learns and improves at every interaction, offering AI-powered workplace search synced with user data. Quivr allows users to connect with their favorite tools, databases, and applications, and configure their 'second brain' to train on their company's unique context for improved search relevance and knowledge discovery.
Petal
Petal is a document analysis platform powered by generative AI technology. It allows users to chat with their documents, providing fully sourced and reliable answers by linking to their own knowledge bases. Users can train AI on their documents to support their work, ensuring centralized knowledge management and document synchronization. Petal offers features such as automatic metadata extraction, file deduplication, and collaboration tools to enhance productivity and streamline workflows for researchers, faculty, and industry experts.

ResolveAI
ResolveAI is a platform that allows users to create and train AI agents for customer service. These agents can be used to automate tasks such as answering FAQs, scheduling meetings, and collecting leads. ResolveAI's agents are trained using a variety of sources, including documents, website pages, and live data sources. Once trained, agents can be customized to fit the user's brand and integrated with a variety of platforms, including websites, social media, and messaging apps.
DocuHelp
DocuHelp is an AI-powered platform that enables businesses to effortlessly create professional-grade documents, reports, proposals, and sales pitches in a matter of minutes. It facilitates real-time collaboration among team members, eliminating the need for email chains and ensuring accuracy and efficiency. With industry-focused backend prompts, access to backend systems, and the ability to train models on company-specific data, DocuHelp offers a tailored solution for businesses seeking to enhance their document creation process.
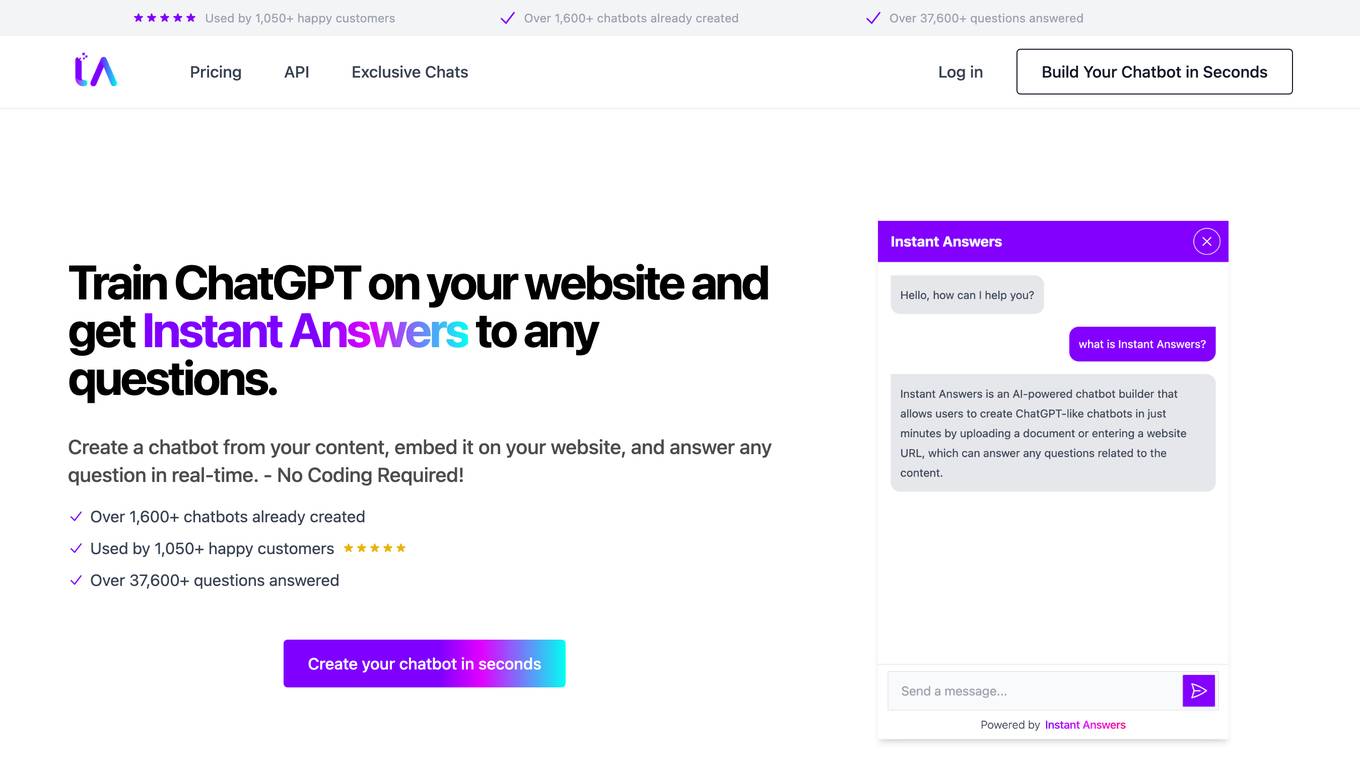
Instant Answers
Instant Answers is an AI-powered chatbot builder that enables users to create customized chatbots for their websites in minutes. The platform allows users to train their chatbots to provide instant answers to a wide range of questions by uploading documents or inputting website URLs. With features like easy customization, effortless integration, conversation analytics, and dynamic learning, Instant Answers offers a user-friendly interface for enhancing customer service and engagement.
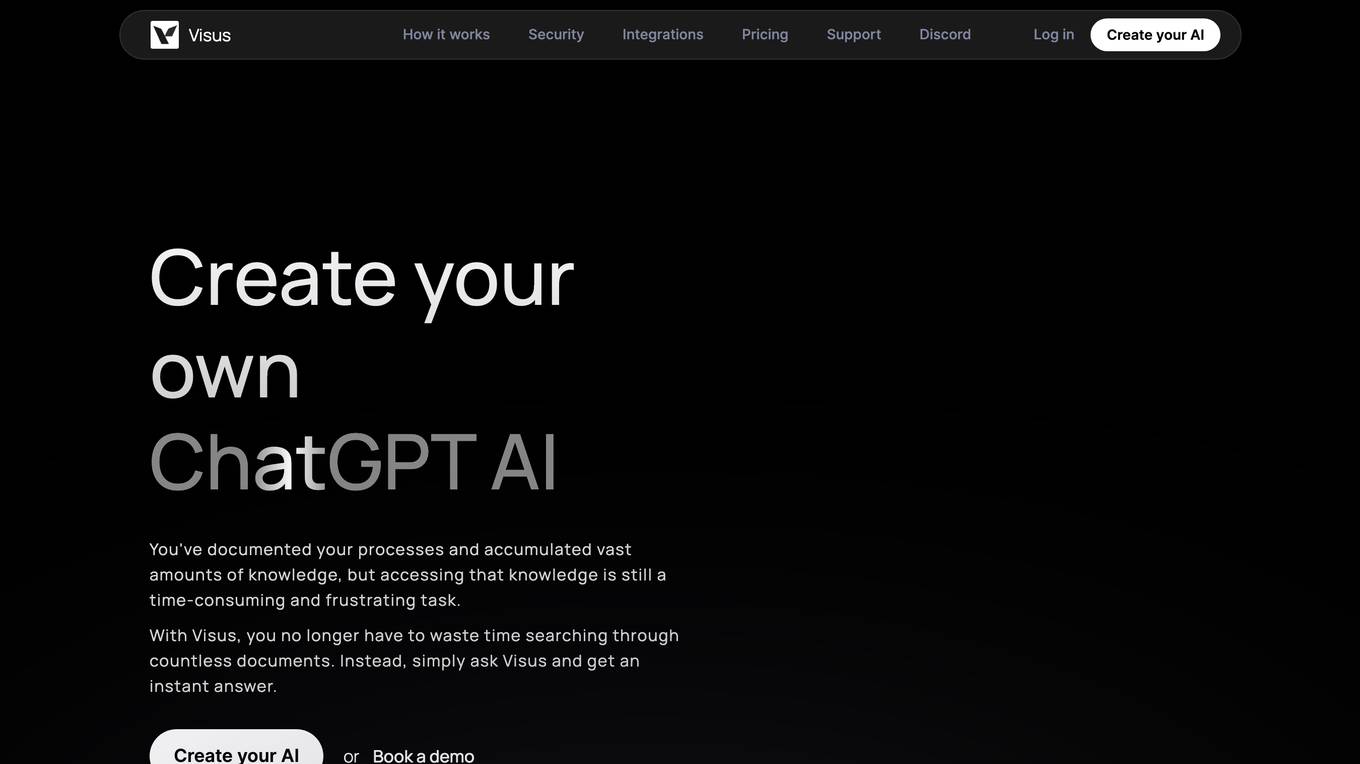
Visus
Visus is a tool that allows you to create your own ChatGPT AI. With Visus, you can train your AI on your own data, ask it questions, and get instant answers. Visus is designed to understand your language and provide quick and accurate responses to any question you may have about your documents. It can help you uncover valuable insights from your data quickly and effortlessly.
1 - Open Source AI Tools
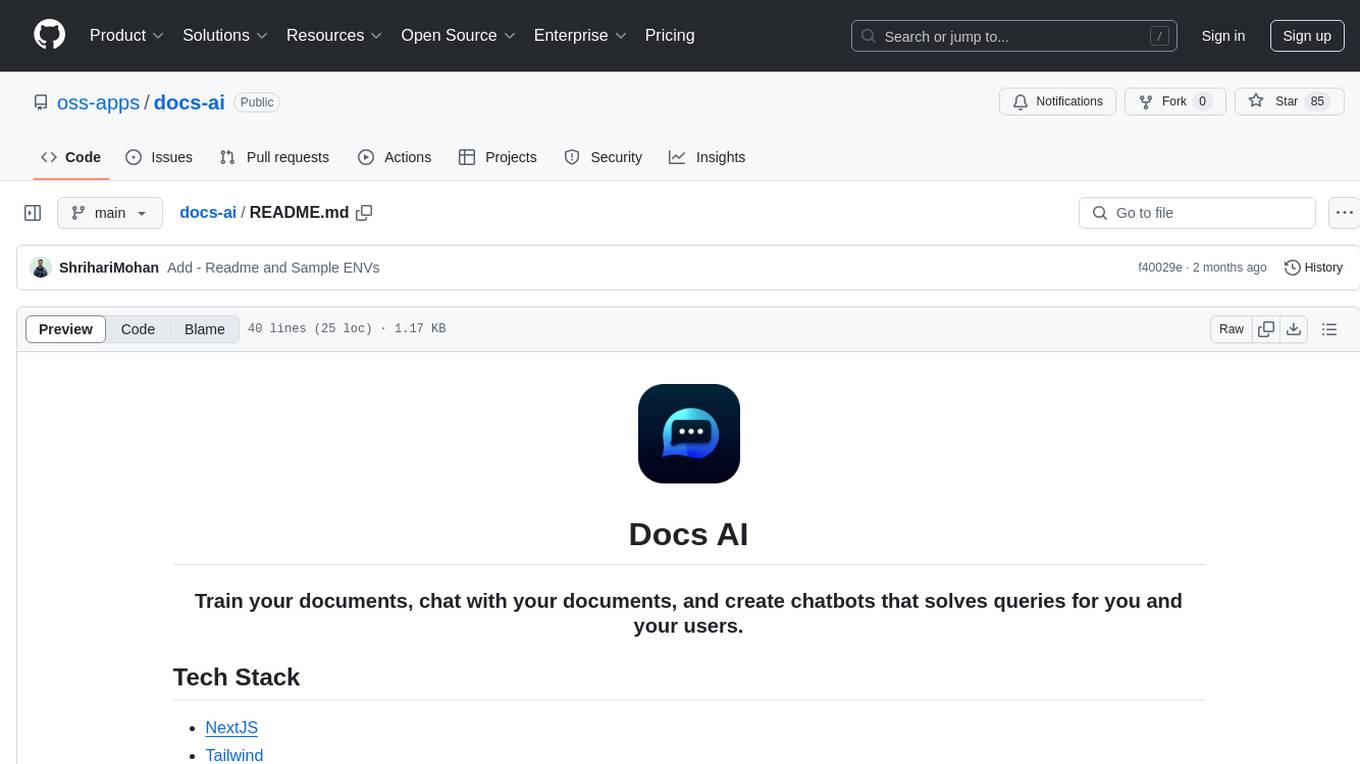
docs-ai
Docs AI is a platform that allows users to train their documents, chat with their documents, and create chatbots to solve queries. It is built using NextJS, Tailwind, tRPC, ShadcnUI, Prisma, Postgres, NextAuth, Pinecone, and Cloudflare R2. The platform requires Node.js (Version: >=18.x), PostgreSQL, and Redis for setup. Users can utilize Docker for development by using the provided `docker-compose.yml` file in the `/app` directory.
20 - OpenAI Gpts




Botpress Helper Español
Asistente experto en Botpress, centrado en brindar respuestas basadas en su documentación oficial.

Explanator
Technical expert blending Kahneman's cognitive insights with Carmack's clarity.

ExplodeView
Enter a product name in ExplodeView to get a three-stage visual transition from intact to fully exploded views.


How to Train a Chessie
Comprehensive training and wellness guide for Chesapeake Bay Retrievers.
The Train Traveler
Friendly train travel guide focusing on the best routes, essential travel information, and personalized travel insights, for both experienced and novice travelers.
How to Train Your Dog (or Cat, or Dragon, or...)
Expert in pet training advice, friendly and engaging.
TrainTalk
Your personal advisor for eco-friendly train travel. Let's plan your next journey together!
Monster Battle - RPG Game
Train monsters, travel the world, earn Arena Tokens and become the ultimate monster battling champion of earth!
Hero Master AI: Superhero Training
Train to become a superhero or a supervillain. Master your powers, make pivotal choices. Each decision you make in this action-packed game not only shapes your abilities but also your moral alignment in the battle between good and evil. Another GPT Simulator by Dave Lalande

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch