AI tools for voice cloning free
Related Tools:
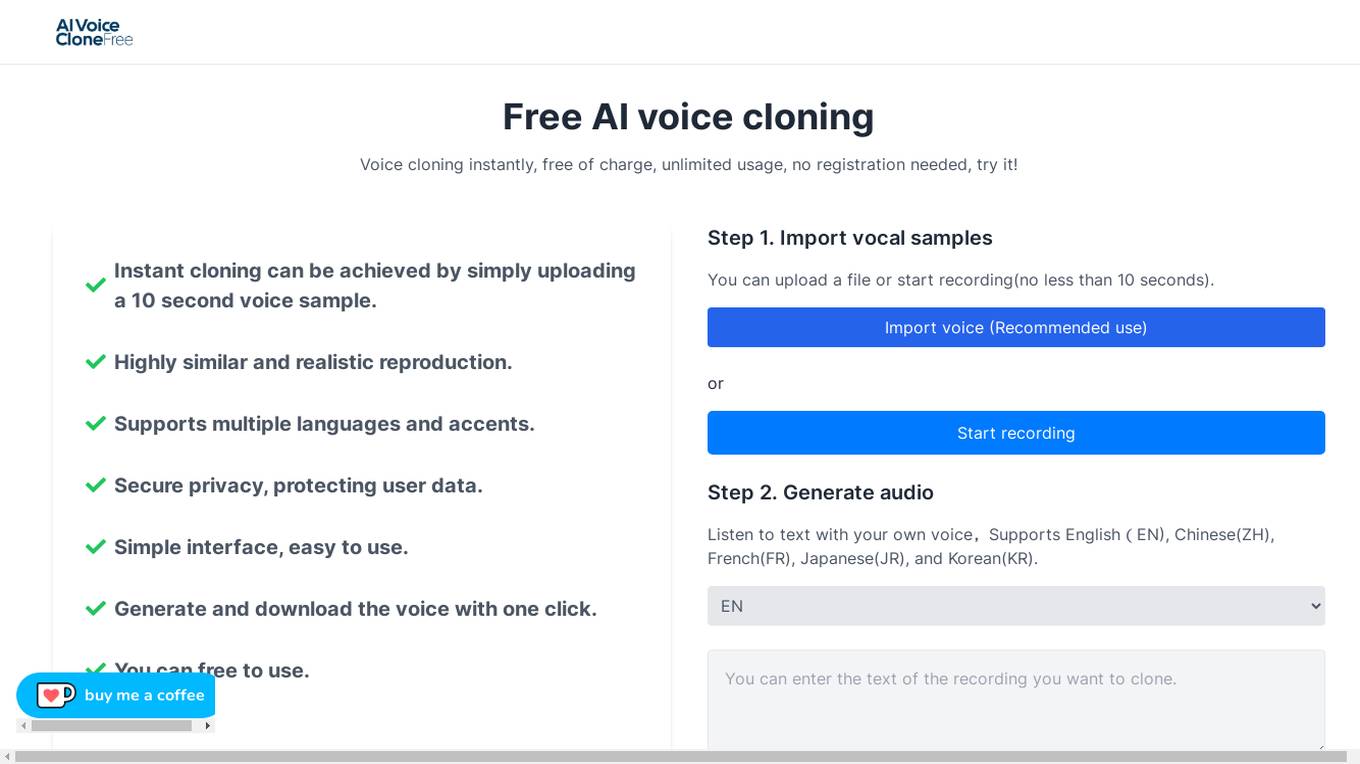
Woy AI Tools
Woy AI Tools is a free AI voice cloning application that allows users to instantly clone voices with high similarity and realism. Users can upload a 10-second voice sample to generate and download cloned voices in multiple languages and accents. The tool ensures secure privacy and offers a simple interface for easy usage.
Unify
Unify is an AI tool that offers a suite of generators including AI Video Generator, AI Image Generator, AI Music Generator, and AI Chat. It leverages artificial intelligence to create various types of content such as videos, images, music, and chat interactions. Unify simplifies the content creation process by providing automated tools powered by AI technology, enabling users to generate high-quality multimedia content effortlessly.
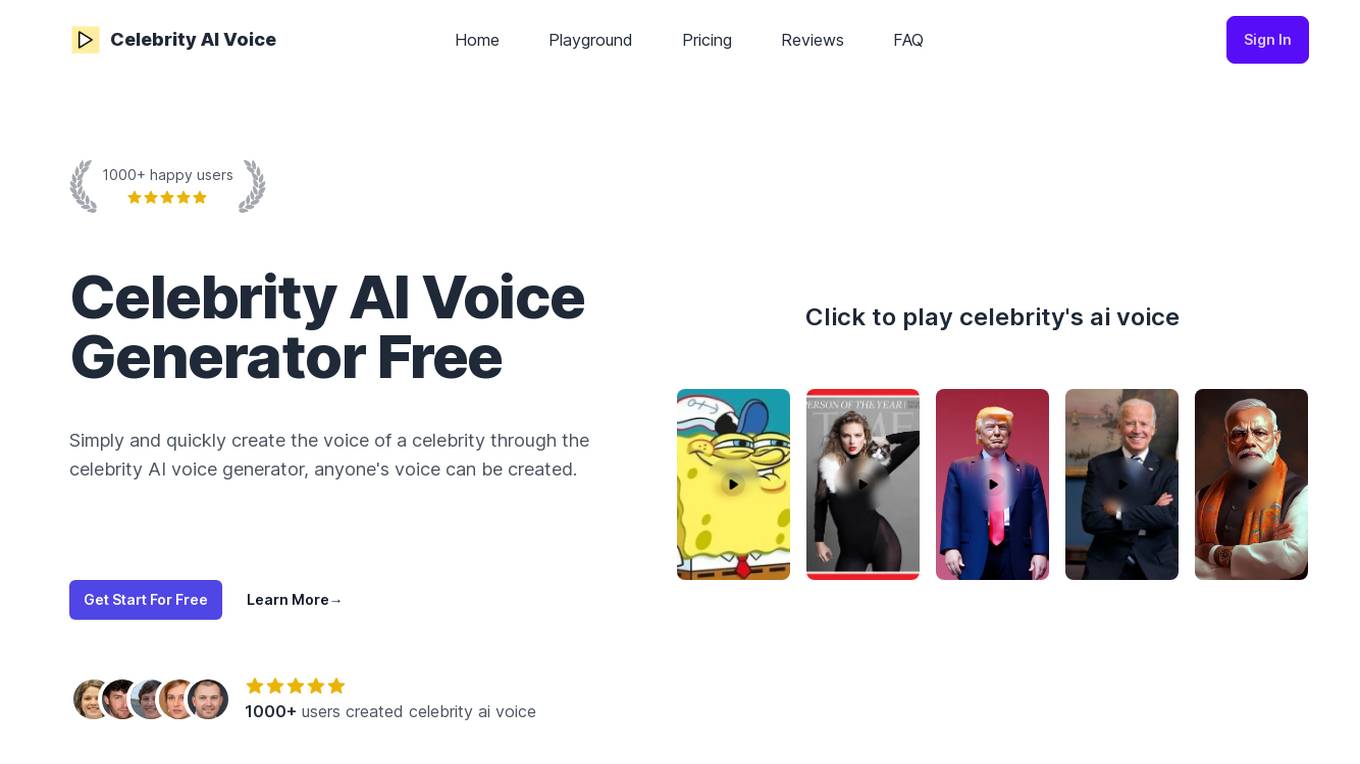
Celebrity AI Voice Generator
Celebrity AI Voice Generator is a free online tool that allows you to create realistic AI-generated voices of celebrities. With just a short audio clip of the person you want to replicate, you can generate voices that sound incredibly real. The tool is easy to use and offers a variety of features, including the ability to control voice styles, emotions, and accents. You can also use the tool to generate voices in different languages. Celebrity AI Voice Generator is a powerful tool that can be used for a variety of purposes, including creating voiceovers, dubbing videos, and developing video games.
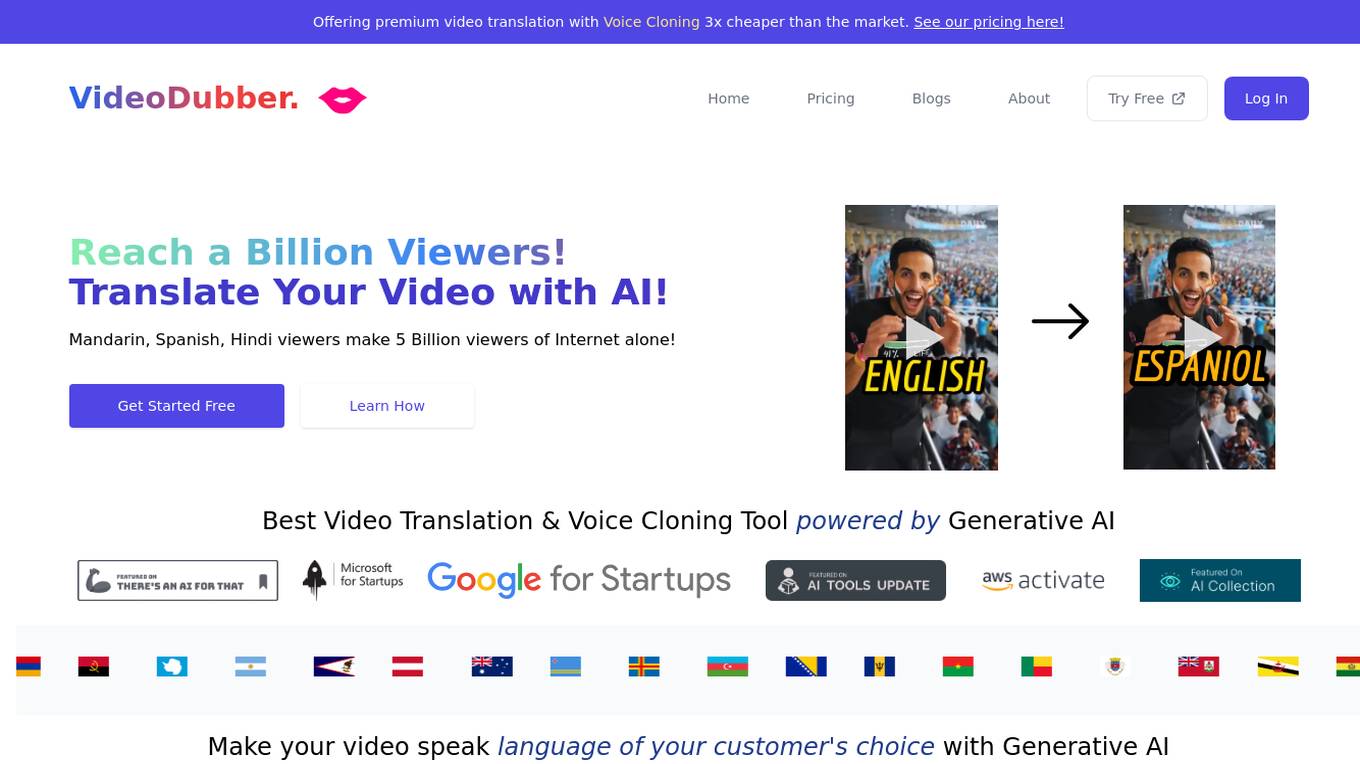
VideoDubber
VideoDubber is an AI-powered video translation and voice cloning tool that allows users to translate videos into over 150 languages with just one click. It also offers features such as voice cloning, text-to-speech, and subtitling. VideoDubber is designed to help businesses and content creators reach a global audience by making their videos accessible to viewers who speak different languages.
VideoDubber
VideoDubber is an AI-powered video translation and voice cloning tool that allows users to translate videos into over 150 languages with just one click. It also offers features such as voice cloning, text-to-speech, and subtitling. VideoDubber is a valuable tool for businesses and content creators who want to reach a global audience with their videos.
VideoDubber
VideoDubber is an AI-powered video translation and text-to-speech tool that offers premium video translation with voice cloning at a fraction of the market price. It enables users to make their videos speak in the language of their audience's choice using Generative AI. The platform supports translation to over 150 languages and accents, providing features like voice cloning, subtitles modification, and dubbing minutes. VideoDubber caters to a wide range of users, including Youtubers, businesses, and content creators, helping them reach a global audience and enhance viewer engagement through multilingual content.
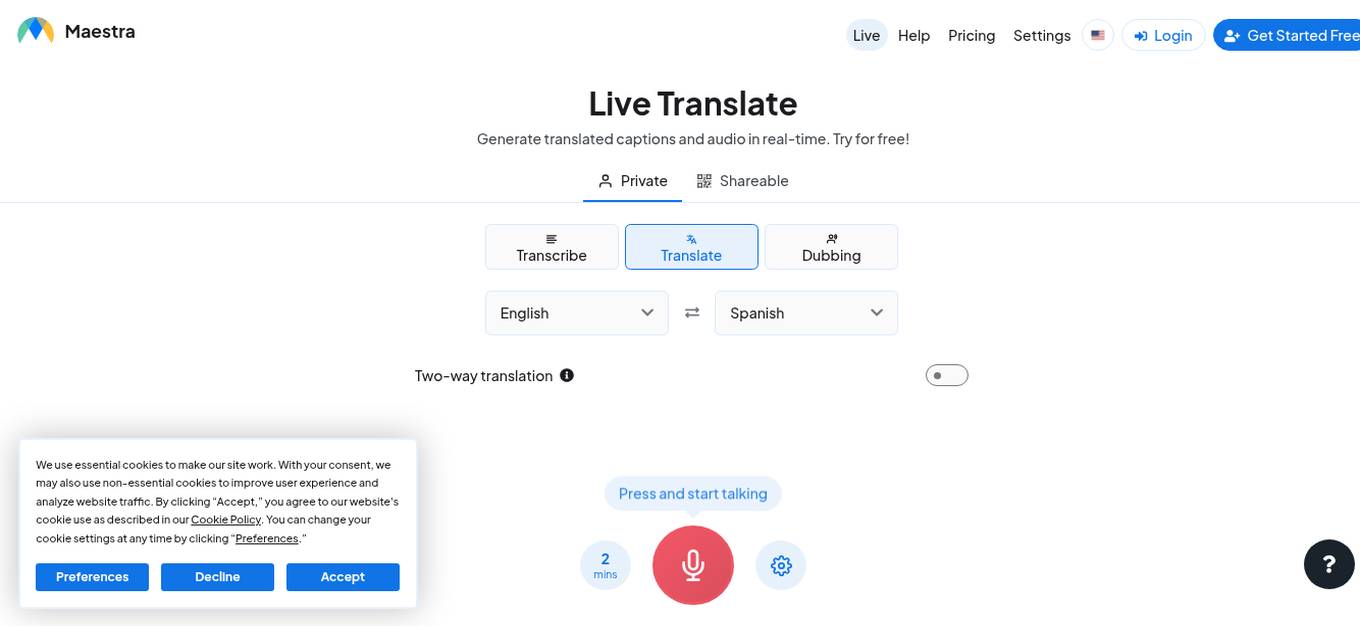
Maestra
Maestra is a real-time online voice translator that generates translated captions and audio instantly. It offers features like private shareable transcriptions, dubbing in multiple languages, two-way translation, and multi-speaker support. Maestra provides various pricing plans catering to different needs, including live event captioning, live support, and custom pricing options. Users can access their accounts from different devices, and the platform ensures secure payments through Stripe. The tool supports automatic language detection, diarization of multiple speakers, and custom dictionary for improved accuracy. Maestra is trusted by individuals and teams for its excellent AI translation services.

Voice.ai
Voice.ai is a free real-time voice changer and the largest ecosystem of free AI voice tools. With Voice.ai, you can change your voice in real-time, clone voices, create soundboards, and more. Voice.ai is perfect for streamers, content creators, gamers, and anyone who wants to have fun with their voice.
BlipCut AI Video Translator
BlipCut is a free AI Video Translator with Voice Cloning application that offers advanced features for video translation and voice manipulation. It supports over 95 languages and provides tools like AI Subtitle Translator, AI Audio Translator, YouTube Transcript Generator, AI Voice Cloning, and more. With BlipCut, users can effortlessly translate videos, generate subtitles, change voices, and dub videos with human-like AI voices. The application aims to break language barriers and enhance content creation by providing innovative solutions for video localization and voice manipulation.
Resemble AI
Resemble AI is an advanced AI tool offering a range of features such as AI Voice Generator, Deepfake Detection, Voice Cloning, Text-to-Speech, Speech-to-Speech, Multilingual support, Audio Editing, and more. It provides state-of-the-art AI models for voice generation and detection, helping users create realistic voices and detect deepfakes across various media types. The platform is trusted by millions of users worldwide, including Fortune 500 companies and government agencies, for its innovative solutions in generative AI and security.
PlayAI
PlayAI is a leading AI voice generator and text-to-speech platform that offers a wide range of features to create high-quality audio content. With over 206 natural-sounding voices in 30+ languages, users can generate multi-speaker AI voices indistinguishable from humans. The platform allows users to enhance audio with speech styles, pronunciations, and SSML tags, making it ideal for audiobooks, YouTube videos, podcasts, and more. PlayAI's AI voice generator works by converting written text into natural-sounding speech through advanced text-to-speech technology, with real-time conversion and customizability options. The platform also supports voice cloning, API integration, and industry-leading AI voice products for various applications.
VoiSpark
VoiSpark is an AI voice generator platform that offers text-to-speech, voice cloning, and voice changer services. It provides creators with expressive, authentic voices that perform like real people, with features such as a massive voice library, human-like voices with emotion, realistic voice cloning, and support for long-form content narration. VoiSpark aims to cater to creators who seek to sound like real humans and offers a user-friendly interface for easy voice creation and customization.
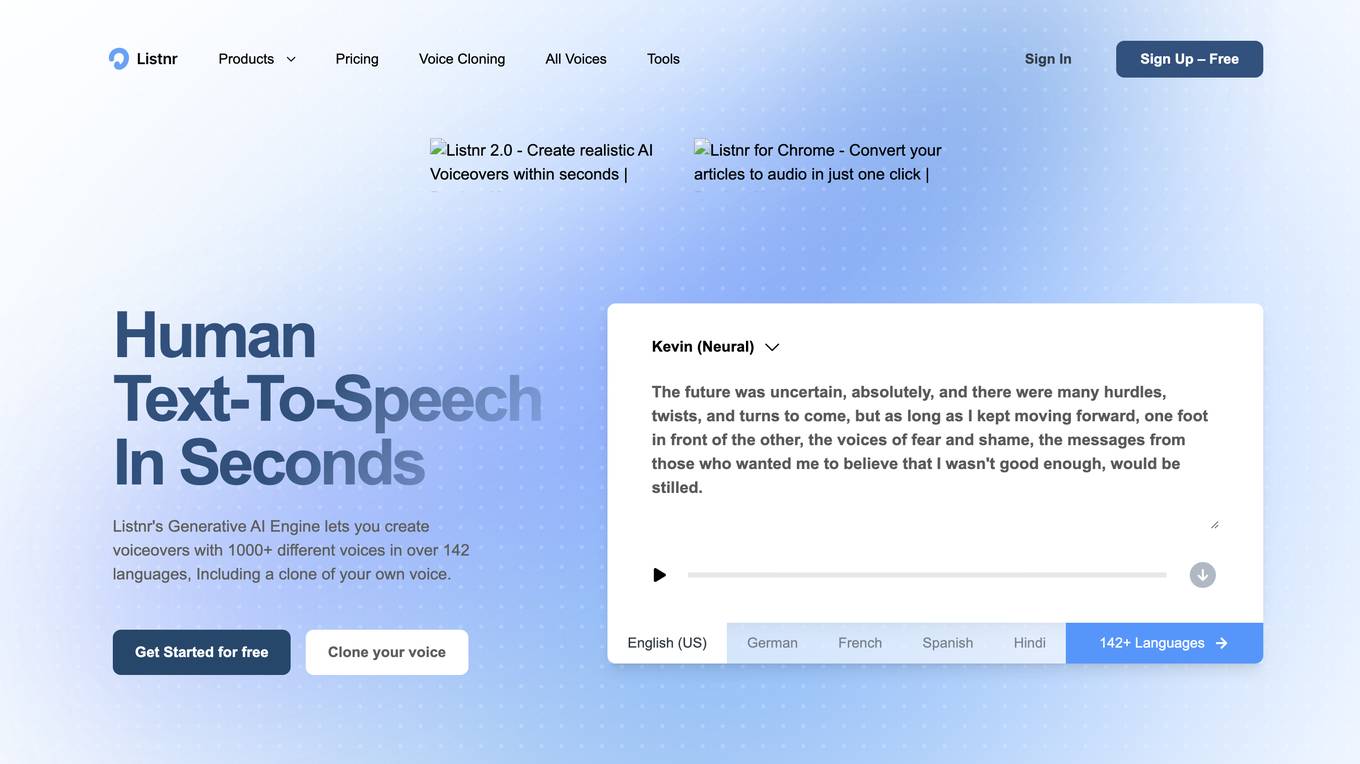
Listnr AI
Listnr AI is a leading AI voice generator tool that offers ultra-realistic AI voices indistinguishable from humans. With over 1000 different voices in more than 142 languages, including voice cloning capabilities, Listnr AI is trusted by 2,500,000+ users worldwide. The tool allows users to create voiceovers for various content types such as shorts, TikToks, YouTube videos, gaming, podcasts, sales, social media, and audiobooks. Listnr AI's state-of-the-art generative AI technology ensures that the voiceovers sound extremely natural, providing a seamless experience for content creators. Additionally, Listnr AI offers features like emotion fine-tuning, punctuations, pauses, and a wide range of multi-lingual voices to cater to diverse content needs.
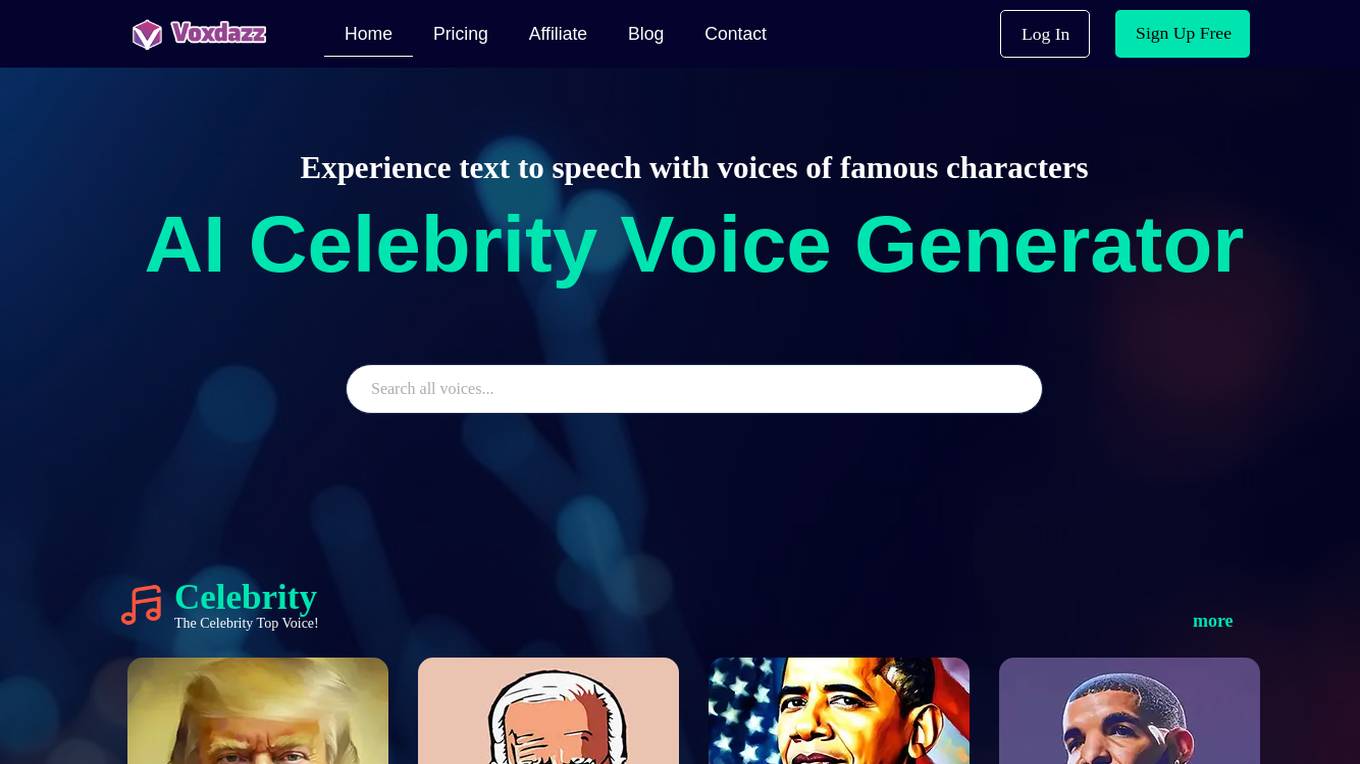
Voxdazz
Voxdazz is a celebrity AI voice generator website that allows users to select a celebrity template, input text, and generate a video with lifelike voices. With famous characters like Donald Trump, Joe Biden, and more, Voxdazz offers a fun and entertaining way to bring words to life through AI-generated voices. The service provides realistic voice cloning technology for creating humorous content, skits, and parodies with friends and family.
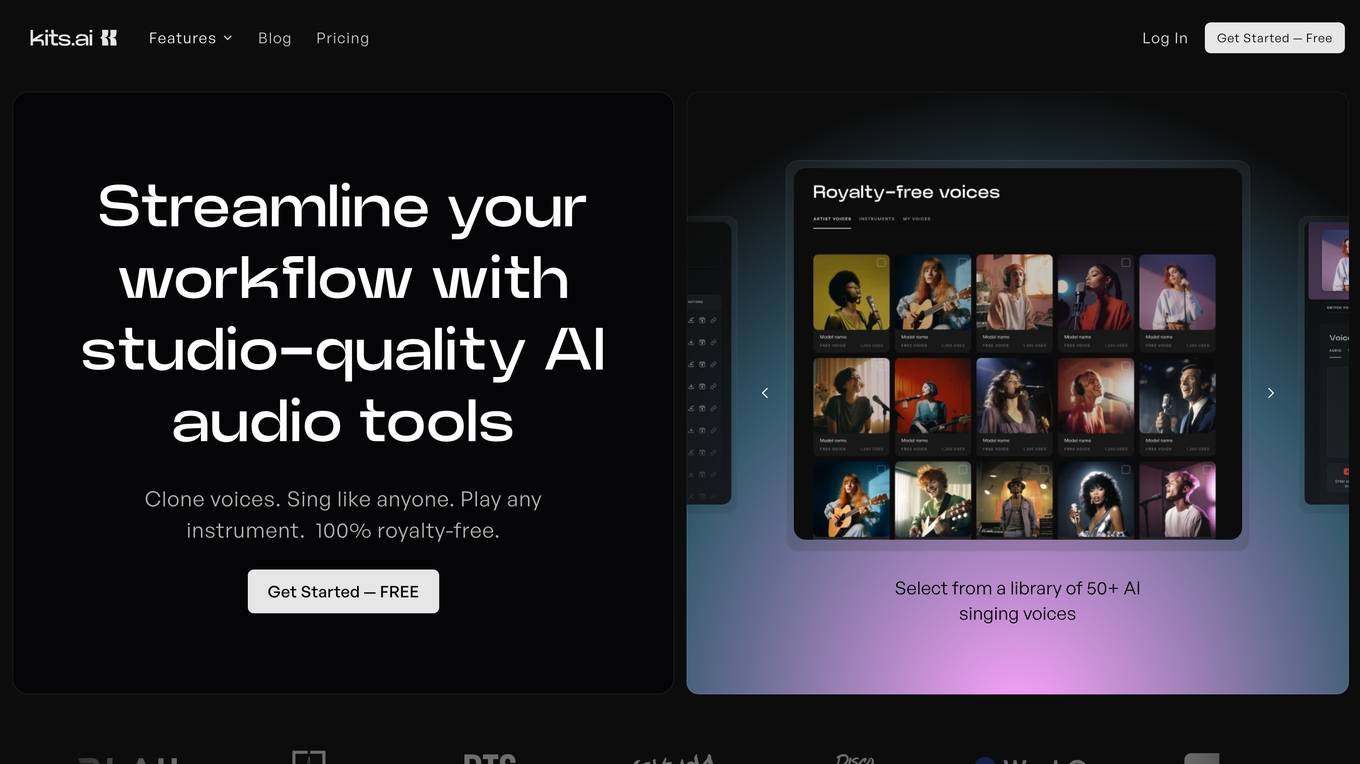
Kits AI
Kits AI is a studio-quality AI music tool that offers a range of features to streamline music production workflows. It provides tools for voice cloning, singing like anyone, playing any instrument, isolating vocals, and more. With 100% Royalty Free content, Kits AI allows users to create their own AI singing clones and collaborate without the need for recording sessions. The application is designed to enhance creativity, save time, and offer new revenue streams for vocalists and producers.
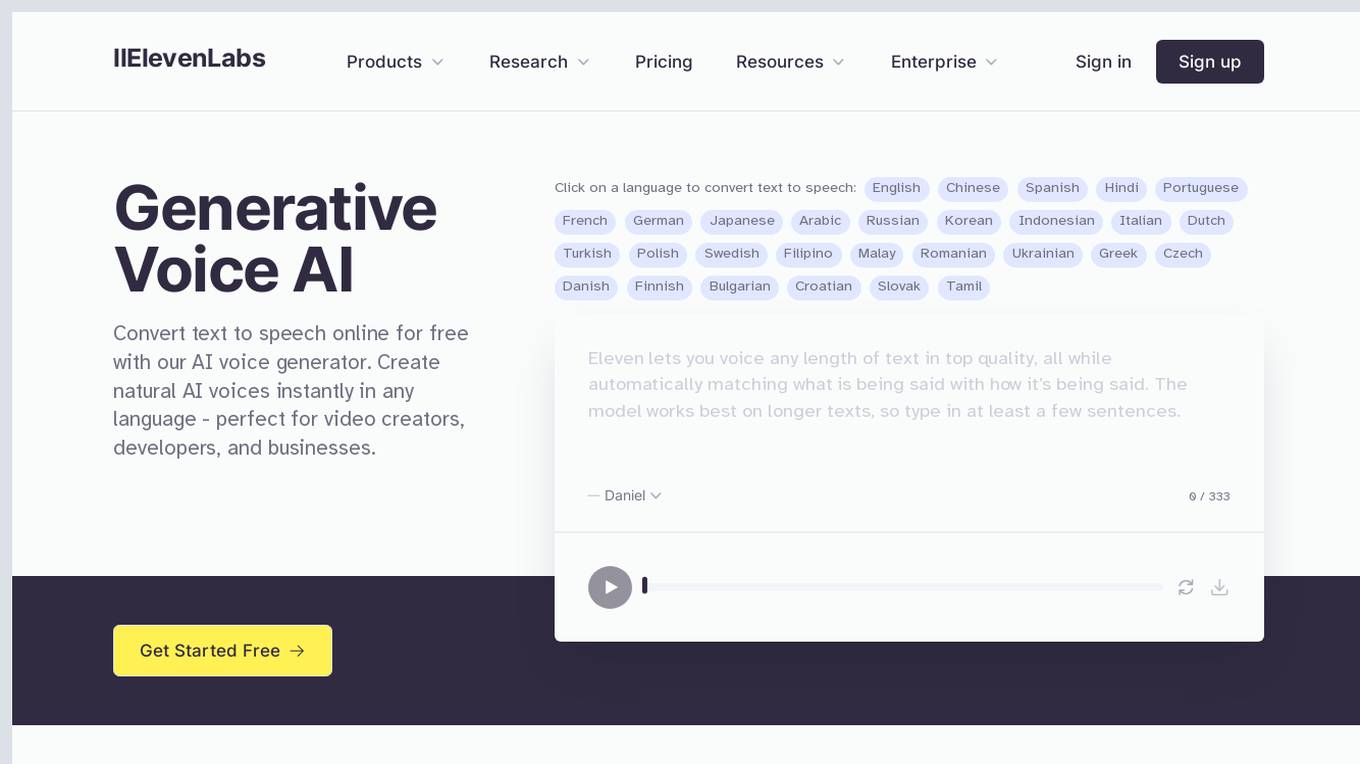
ElevenLabs
ElevenLabs is an AI voice generator and text-to-speech application that allows users to convert text into natural-sounding AI voices in various languages. The platform offers high-quality spoken audio with human intonation and inflections, suitable for video creators, developers, and businesses. Users can create lifelike voices for videos, gaming, audiobooks, chatbots, and more. ElevenLabs supports 29 languages and diverse accents, providing advanced AI text-to-speech technology for generating audio content.
Perso AI
Perso AI is a leading AI video translator, localization, and dubbing tool that offers natural dubbing and precise lip-sync capabilities to make videos feel native in any language. Trusted for AI dubbing that sounds human, Perso AI powers interactive AI experiences across screens and physical spaces. With features like AI Lip-Sync, Script Editing, Video Localization, Voice Cloning, and Multi-Speaker support, Perso AI transforms content strategy with powerful AI technology wrapped in a simple interface. The platform allows users to upload videos, select languages, and let the AI handle the rest, enabling quick translation and publishing without the need for human translators. Perso AI is designed to help creators, businesses, and enterprises reach global audiences with cost-effective, efficient, and engaging video content.
HeyFish.ai
HeyFish.ai is an AI-powered video ad platform that enables businesses to create hyper-realistic digital human videos without hiring actors, renting studios, or managing video production crews. Founded in 2024, HeyFish.ai has quickly become one of the leading AI UGC (User-Generated Content) video generators, serving over 3,000 businesses and producing more than 100,000 videos. The platform offers 300+ realistic AI digital human actors across diverse ages, ethnicities, and styles, with support for 35+ languages including English, Chinese, Spanish, French, German, Japanese, Korean, and Arabic. Each video features accurate lip-sync, natural facial expressions, and realistic body movements, making them virtually indistinguishable from videos filmed with real actors. HeyFish.ai stands out from competitors with several exclusive features: dual-person dialogue avatars, AI actors that can hold and showcase real products, voice cloning, and free AI-generated images per day included with every plan. The platform offers the best value starting at just $1 for a 3-day trial, with plans including 4K video export, commercial licensing, and no watermarks. HeyFish.ai videos are optimized for major advertising platforms like TikTok, Meta, YouTube Shorts, Snapchat, and Amazon Ads, supporting various video formats and ensuring enterprise-level security with SOC 2 compliance and API access.
VidAU
VidAU is an AI-driven video and audio generation platform that simplifies the content creation process from conception to production. It offers a range of tools such as AI Video Face Swap, AI Video Translator, AI Avatar Video, Subtitles Translate, and Subtitles Removal. Users can generate engaging videos in batches within minutes by entering product URLs or descriptions. The platform caters to marketing content, multi-language video production, instructional videos, and TikTok videos, with features like AI-generated avatars, voice cloning, and subtitles translation. VidAU has been endorsed by various users for its ability to enhance video content, boost engagement, and drive sales across different industries.
VoiceSona
VoiceSona is an AI-powered voice changer application that allows users to transform their voice to sound like anyone they want. With a lag-free experience, users can change their voice across various platforms such as Roblox, phone calls, OBS, VRChat, and Discord. The application offers thousands of voices including singers, villains, rappers, presidents, and actors, providing a new level of voice-changing technology.
Anime Voice Match
Anime Voice Match, identifies anime characters similar to the user's voice.
Voice/Style/Tone AI Prompt Snippet Generator
Analyzes your writing and produces a prompt snippet you can use in any other prompt to guide AI in replicating your voice, style, and tone. Just provide the text in the prompt box or in a document (don't use a link or image). You don't need to write any additional prompt language with your text.


Voice Memo
Record your thoughts with ChatGPT Voice Conversations 💡. Get started by clicking the 🎧 icon right to the chat input. Available on mobile only. Ask 'how do you work?' to learn more.
Vedic Voice
A scholar in Hindu literature providing positive, brief insights against negativity.

Skillful Voice
Premier expert in household management, offering unparalleled advice and guidance.


Earth Conscious Voice
Hi ;) Ask me for data & insights gathered from an environmentally aware global community
Bring Your Writing Voice to Every Task
This GPT will help you recreate your writing voice across multiple tasks. All you need is a prior writing sample (email, blog, article, tweet) and a new task.
Passive to Active Voice Text Converter AI
I convert and rewrite passive voice text into active voice tone and language. Simply put your passive voice text below! Perfect for sentences, paragraphs, daily emails, and longer texts.