AI tools for tts monster test
Related Tools:
TTS.Monster
TTS.Monster is an AI text-to-speech tool designed specifically for Twitch users. It utilizes advanced AI technology to convert text into natural-sounding speech, enhancing the streaming experience for content creators and viewers alike. With TTS.Monster, users can easily generate high-quality voiceovers for their Twitch streams, chat interactions, and more. The tool offers a user-friendly interface and a wide range of customization options to tailor the voice output to individual preferences. Whether for entertainment or accessibility purposes, TTS.Monster provides a seamless and engaging audio solution for Twitch broadcasters.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
Kokoro TTS Online
Kokoro TTS Online is a professional cloud service powered by the Kokoro 82M open-source model. It offers text-to-speech conversion with natural speech synthesis using advanced AI technology. Users can transform text into natural-sounding speech in seconds, choose from multiple voices, and experience superior audio quality. Kokoro TTS is user-friendly, supports American and British English, and is suitable for various applications such as creating voiceovers, podcasts, and learning materials.
Zonos TTS
Zonos TTS is an advanced multilingual text-to-speech tool that utilizes high-quality AI technology to deliver natural and expressive voice generation. With features like zero-shot voice cloning, multilingual support, and emotion control, Zonos TTS offers users the ability to create lifelike speech with customizable settings. The tool is suitable for various applications, from content creation to virtual assistants, audiobooks, gaming, e-learning, and more. Zonos TTS provides fast real-time processing and a user-friendly interface for seamless speech synthesis.
ttsopen.ai
ttsopen.ai is a free online platform that offers text-to-speech (TTS) services powered by OpenAI. Users can convert text into natural-sounding speech using advanced TTS technology without the need to register or log in. The platform provides a range of AI voices for various scenarios, such as short video creation, e-learning, marketing, podcasting, and more. With an intuitive interface and lightning-fast technology, ttsopen.ai enables users to generate high-quality voiceovers quickly and easily. The service prioritizes data security and privacy, ensuring a safe experience for users.
TTSMaker
TTSMaker is a free online text-to-speech tool that allows users to convert text into natural-sounding speech. It supports multiple languages and voices, and the resulting audio files can be downloaded for free and used for commercial purposes. TTSMaker is a valuable tool for creating audiobooks, dubbing videos, and other projects that require high-quality voiceovers.
Read It
Read It is an AI-powered tool that allows users to convert newsletters and articles into podcasts effortlessly. By utilizing cutting-edge AI text-to-speech technology, users can listen to their favorite written content on the go. The tool provides users with a personal podcast feed URL upon sign-up, enabling them to add articles through email forwarding or using a bookmarklet. With a user-friendly interface and pay-as-you-go model, Read It offers a seamless experience for turning text-based content into audio podcasts.
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
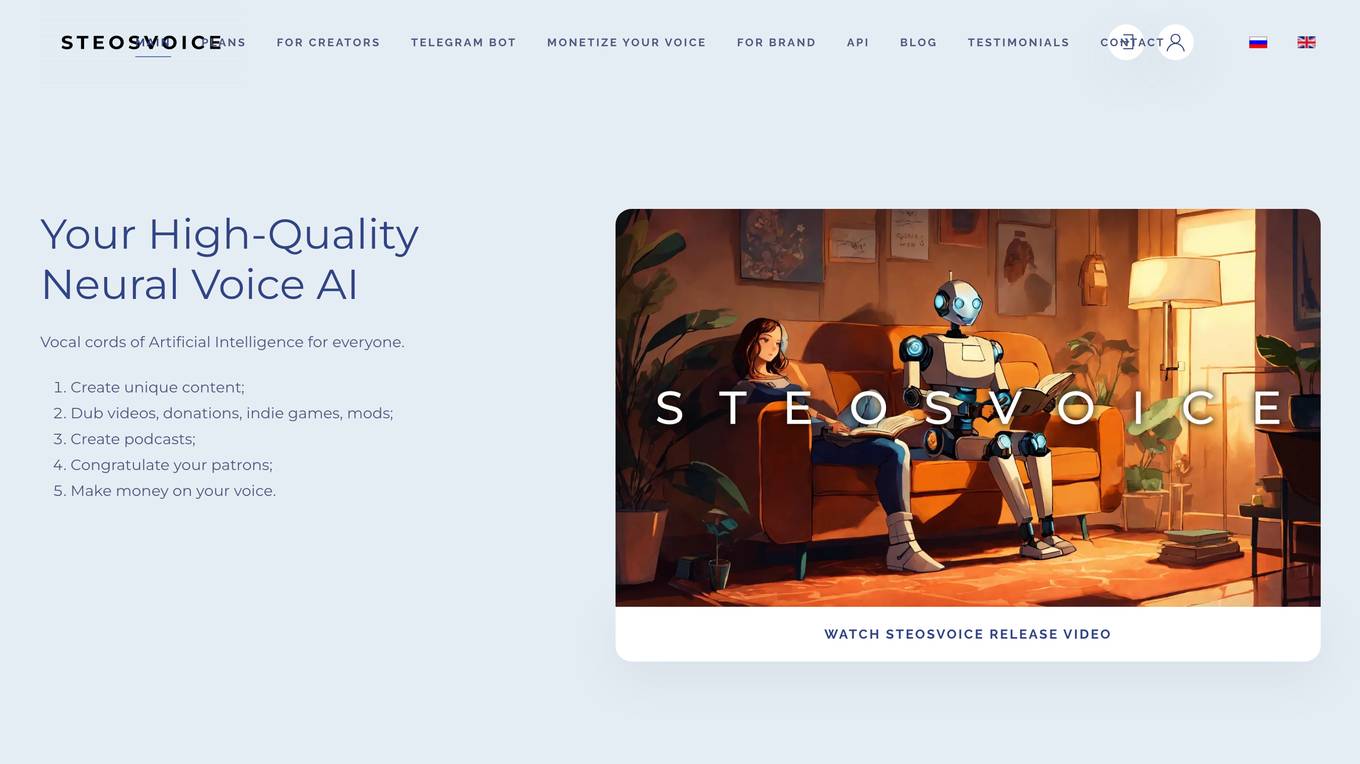
SteosVoice
SteosVoice (formerly CyberVoice) is an AI tool that offers high-quality neural voice AI for everyone. It provides a platform for creating unique content such as dubbing videos, donations, indie games, mods, podcasts, and more. With over 800 voices available and growing, SteosVoice caters to a wide range of users and use cases, generating over 75 hours of audio content daily. The platform also offers a Telegram Bot for speech synthesis, allowing users to convert text messages into voice format conveniently and quickly. SteosVoice is a leader in sound generation quality, thanks to unique AI developments from the Mind Simulation AGI lab.
Genailia
Genailia is an AI platform that offers a range of products and services such as translation, transcription, chatbot, LLM, GPT, TTS, ASR, and social media insights. It harnesses AI to redefine possibilities by providing generative AI, linguistic interfaces, accelerators, and more in a single platform. The platform aims to streamline various tasks through AI technology, making it a valuable tool for businesses and individuals seeking efficient solutions.
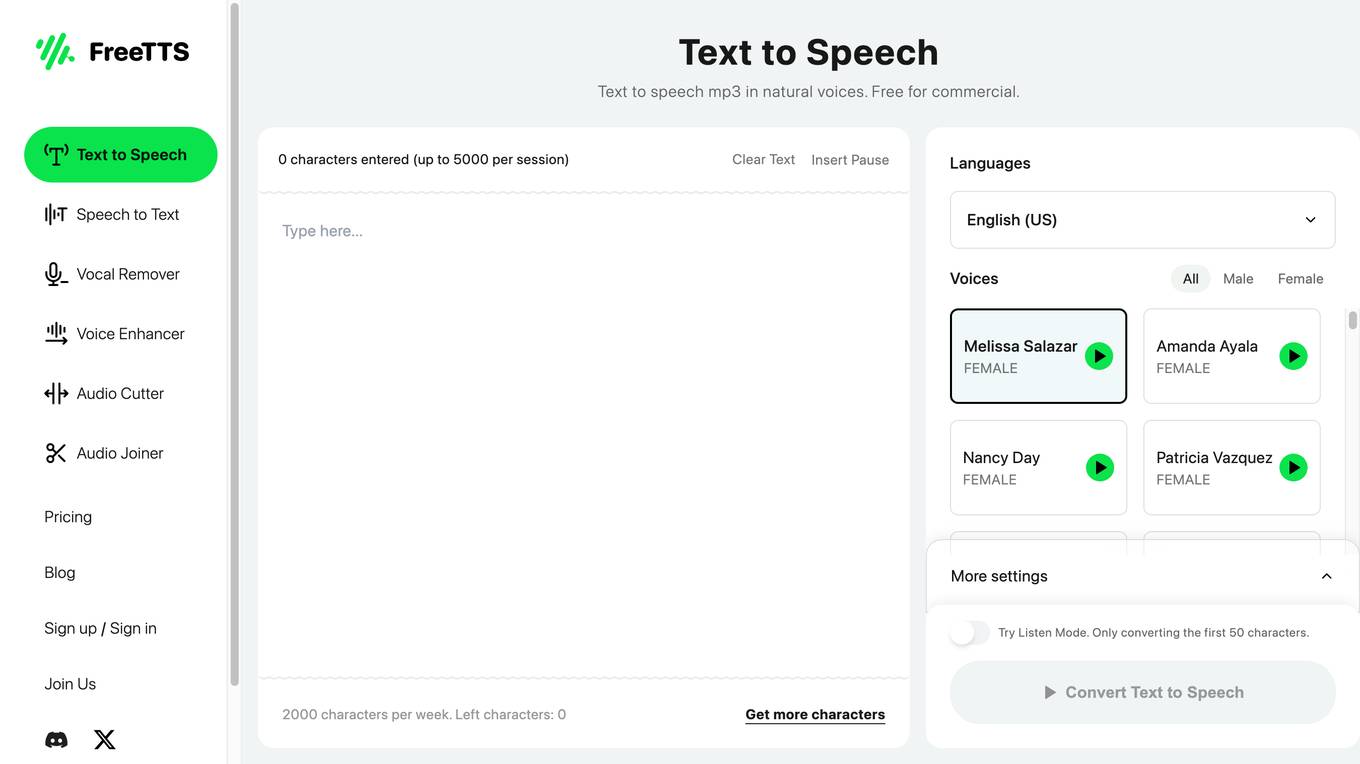
FreeTTS
FreeTTS is a free online text-to-speech tool that allows users to convert text into natural-sounding speech in various languages and voices. It supports a range of features such as text-to-speech conversion, speech-to-text conversion, vocal removal, voice enhancement, audio cutting, and audio joining. FreeTTS is suitable for various applications, including content creation, education, accessibility, and entertainment.
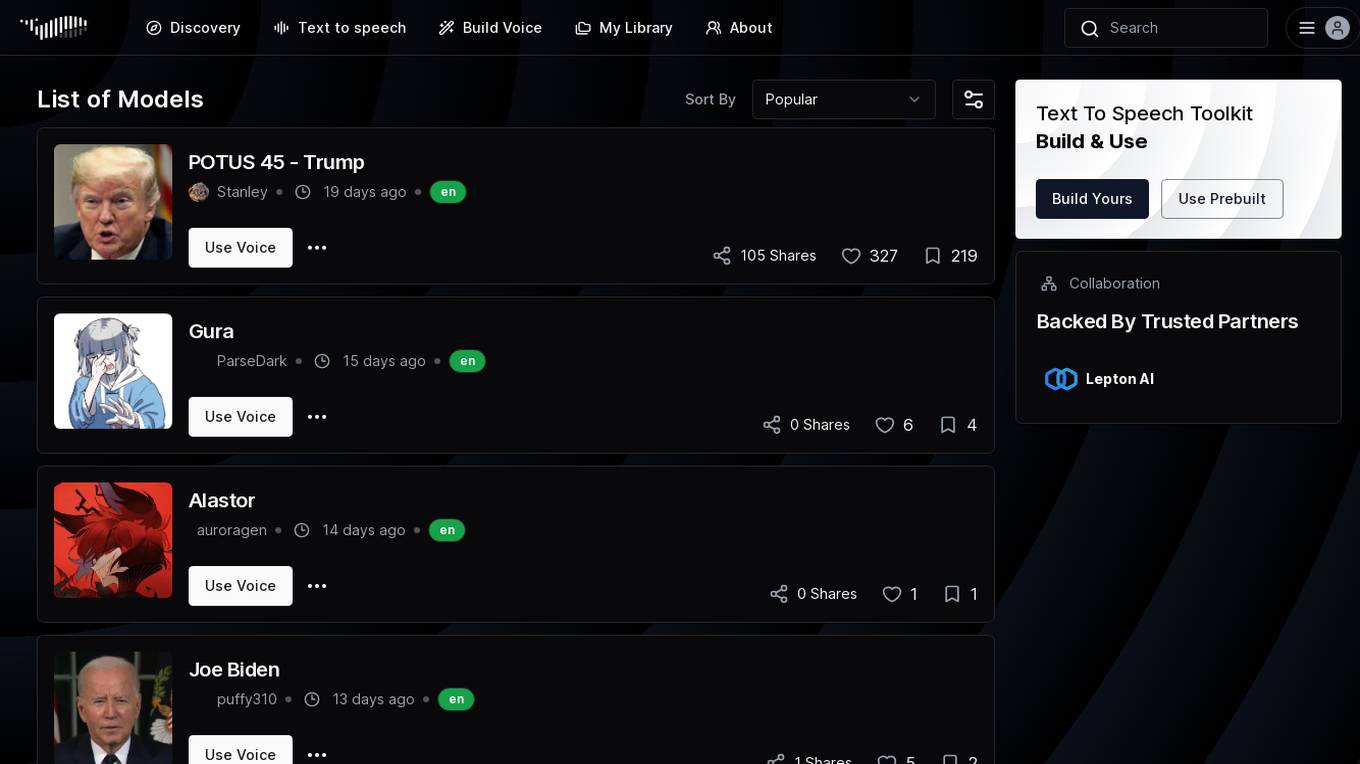
Fish Audio
Fish Audio is an AI-powered audio generation tool that allows users to convert text into speech. With a user-friendly interface, it offers a range of models for generating high-quality voices. Users can build their own voice models or use prebuilt ones, and collaborate with others. Backed by trusted partners, Fish Audio leverages Lepton AI's top models to provide a seamless experience for creating audio content.
Lovevoice AI Voice Generator
Lovevoice is an AI Voice Generator that transforms text into natural-sounding speech using AI technology. It offers over 70 languages and nearly 300 AI voices, customizable voice settings, file transcription support, and MP3 download capabilities. Lovevoice's advanced AI ensures generated voiceovers are human-like, making it ideal for various applications such as videos, podcasts, audiobooks, and personalized audio messages. Users can quickly convert text into high-quality audio files with multilingual global support.

ElevenLabs
ElevenLabs is a text-to-speech (TTS) platform that uses artificial intelligence (AI) to generate realistic human-like voices. With ElevenLabs, you can convert any text into high-quality spoken audio in over 29 languages and 120 voices. The platform is easy to use and offers a variety of features, including the ability to adjust the voice's pitch, speed, and volume. You can also use ElevenLabs to create custom voices and clone your own voice. ElevenLabs is a powerful tool for content creators, businesses, and anyone who wants to create realistic spoken audio.
ElevenLabs
ElevenLabs is an AI voice generator and text-to-speech application that allows users to convert text into natural-sounding AI voices in various languages. The platform offers high-quality spoken audio with human intonation and inflections, suitable for video creators, developers, and businesses. Users can create lifelike voices for videos, gaming, audiobooks, chatbots, and more. ElevenLabs supports 29 languages and diverse accents, providing advanced AI text-to-speech technology for generating audio content.
TikTok Voice
TikTok Voice is a free online AI text-to-speech tool that transforms text into various TikTok voices like the popular lady voice, Siri, Rocket, and Ghostface. Users can generate voices for video editing, text reading, and e-books. The tool offers a convenient way for video editing on PC and provides voices not available in the TikTok app. Users can easily choose the language and voice accent, type the text, generate the voice, and download it. For specific voice requests, users can email [email protected].
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.

Graphlogic.ai
Graphlogic.ai is an AI-powered platform that offers Conversational AI solutions through text and voice bots. It provides partner-enabled services for various industries, including HR, customer support, marketing, and internal task management. The platform features AI-powered chatbots with goal-oriented NLU and rule-based bots, seamless integrations with CRM systems, and 24/7 omnichannel availability. Graphlogic.ai aims to transform and speed up customer service and FAQ conversations by providing instant replies in a human-like manner. It also offers dedicated HR manager bots, hiring assistants for mass recruitment, responsible managers for internal tasks, and outbound marketing coordinators.

CobeAI
CobeAI is an ultimate AI toolkit that offers a comprehensive suite of AI tools for copywriting, image generation, chatbot creation, voiceovers, and more. Powered by advanced AI models like GPT-4o, StabilityAI, Dalle-E, and Google TTS, CobeAI aims to elevate brands by providing customizable AI solutions to boost online presence and productivity. With features such as AI text generator, image generator, chatbot development, voice cloning, and code generation, CobeAI caters to a wide range of users, including freelance writers, startup founders, marketers, e-commerce entrepreneurs, and content creators.
Video GPT
AI Video Maker. Generate videos for social media - YouTube, Instagram, TikTok and more! Free text to video & speech tool with AI Avatars, TTS, music, and stock footage.