Best AI tools for< Visual Benchmarking >
20 - AI tool Sites
Kolors AI
Kolors AI is a cutting-edge text-to-image synthesis tool that offers state-of-the-art photorealistic image generation with advanced comprehension of both English and Chinese texts. It revolutionizes the way images are created from text, setting new benchmarks in visual appeal and detail rendering. The tool is developed by the Kolors Team at Kuaishou Technology and is freely available for use. Kolors AI utilizes a General Language Model (GLM) for bilingual text comprehension and employs an enhanced training strategy to ensure exceptional visual quality. With a focus on high-resolution image generation and category-balanced benchmarking, Kolors AI stands out as a powerful AI image generator.
Microsoft Visual Studio
Microsoft Visual Studio is an integrated development environment (IDE) and code editor designed for software developers and teams. It offers a comprehensive set of tools and features to enhance every stage of software development, including editing, debugging, building code, and publishing applications. Visual Studio Code, a lightweight source code editor, is also available for JavaScript and web developers, with support for various programming languages through extensions. The application aims to improve productivity, collaboration, and efficiency in software development.
Visual Studio Marketplace
The Visual Studio Marketplace is a platform where developers can find and publish extensions for Visual Studio family of products. It offers a wide range of extensions to enhance the functionality and features of Visual Studio, Visual Studio Code, Azure DevOps, and more. Developers can customize their development environment with various tools and integrations available on the marketplace.
Visual Studio
Visual Studio is an integrated development environment (IDE) and code editor designed for software developers and teams. It offers a comprehensive set of tools and features to enhance every stage of software development, including code editing, debugging, building, and publishing applications. Visual Studio also includes compilers, code completion tools, graphical designers, and AI-powered coding assistance through GitHub Copilot integration.
Visual Electric
Visual Electric is an AI image generator that utilizes advanced artificial intelligence algorithms to create stunning and realistic images. The tool is designed to assist users in generating high-quality visuals for various purposes, such as graphic design, digital art, and marketing materials. With its user-friendly interface and powerful AI capabilities, Visual Electric simplifies the image creation process and enables users to unleash their creativity without the need for extensive design skills. Whether you are a professional designer or a hobbyist, Visual Electric offers a versatile and efficient solution for all your image generation needs.

Visual Computing & Artificial Intelligence Lab at TUM
The Visual Computing & Artificial Intelligence Lab at TUM is a group of research enthusiasts advancing cutting-edge research at the intersection of computer vision, computer graphics, and artificial intelligence. Our research mission is to obtain highly-realistic digital replica of the real world, which include representations of detailed 3D geometries, surface textures, and material definitions of both static and dynamic scene environments. In our research, we heavily build on advances in modern machine learning, and develop novel methods that enable us to learn strong priors to fuel 3D reconstruction techniques. Ultimately, we aim to obtain holographic representations that are visually indistinguishable from the real world, ideally captured from a simple webcam or mobile phone. We believe this is a critical component in facilitating immersive augmented and virtual reality applications, and will have a substantial positive impact in modern digital societies.
Visual Computing and Artificial Intelligence Department
The Visual Computing and Artificial Intelligence Department focuses on foundational research problems at the intersection of Computer Graphics, Computer Vision, and Artificial Intelligence. Their long-term vision is to develop new ways to capture, represent, synthesize, and simulate models of the real world with high detail, robustness, and efficiency. By uniting concepts from Computer Graphics, Computer Vision, and Artificial Intelligence, they aim to create advanced methods for perceiving, understanding, and interpreting the complex real world. The department is headed by Prof. Dr. Christian Theobalt at the Saarbruecken Research Center for Visual Computing, Interaction, and Artificial Intelligence.
Ximilar Visual AI for Business
Ximilar Visual AI for Business is an AI tool that offers a comprehensive platform for image recognition and visual search solutions. It provides features such as image classification, regression, object detection, AI model combination, image annotation, and more. Users can easily build custom machine learning models without coding, access ready-to-use visual AI demos, and benefit from features like image upscaling, background removal, and color extraction. The platform caters to various industries including fashion, home decor, stock photos, collectibles, med & biotech, manufacturing, and real estate.
Endless Visual Novel
Endless Visual Novel is an AI storytelling game where all assets — graphics, music, story, and characters — are generated by AI as you play. It offers a unique experience where no two playthroughs will ever be the same. Users can create their own adventures in AI-generated worlds and characters, with the ability to customize and control the outcome of the story. The application is designed to provide an immersive and interactive storytelling experience for players.
Canva Austria GmbH
Canva Austria GmbH, formerly known as Kaleido AI GmbH, is a visual AI tool that offers automatic image and video background removal, as well as designs ready in seconds. The tool is fully integrated into the Canva design platform, allowing users to create outstanding designs effortlessly. The company's mission is to make visual AI accessible to everyone, aligning with Canva's vision of empowering the world to design. The recent legal entity name change to Canva Austria GmbH does not affect the products or services provided by the tool.
Octopus.do
Octopus.do is a lightning-fast visual sitemap builder and website planner that offers a seamless experience for website architecture planning. With the help of AI technology, users can easily generate colorful visual sitemaps and low-fidelity wireframes to visualize website content and layout. The platform allows users to prepare, manage, and collaborate on website content and SEO, making website planning fast, easy, and enjoyable. Octopus.do also provides a variety of sitemap templates for different types of websites, along with features for real-time collaboration, onsite SEO improvement, and integration with Figma designs.
Threekit
Threekit is a visual product configurator tool designed for brands and manufacturers to enhance online product customization and purchasing experiences. It offers differentiated visual experiences for leading brands in various categories such as furniture, jewelry, sporting goods, commercial bath, and custom doors. Threekit enables users to connect with buyers through amazing visual configurations, 3D modeling, virtual photography, space planning, and augmented reality. The platform also provides tools like bill of material, spec sheets, quotes, and integrations with eCommerce, ERP, configurator, PIM, and more to streamline sales processes. With Threekit, businesses can manage product updates, syndicate product experiences across sales channels, and set business rules and automations.
Custom Vision
Custom Vision is a cognitive service provided by Microsoft that offers a user-friendly platform for creating custom computer vision models. Users can easily train the models by providing labeled images, allowing them to tailor the models to their specific needs. The service simplifies the process of implementing visual intelligence into applications, making it accessible even to those without extensive machine learning expertise.
Klipme
Klipme is a powerful visual AI clip maker that can automatically create clips for TikToks, Reels, Shorts, and other social media platforms. It uses AI to process any type of video content, including professionally shot feature films or regular smartphone videos. Klipme can summarize long-form content, generate AI clips, and transform videos into trendy, animated, and stylish content. It also has features like vertical AI autocrop, AI subtitles, and AI Beatpulse clips. With Klipme, you can empower your creativity and streamline your video production process.
Zolak
Zolak is an AI-powered visual commerce platform designed for the furniture industry. It offers immersive experiences through product visualization, virtual try-out experiences, customization, and more. Zolak enables businesses to bridge physical and digital experiences, empowering e-commerce, manufacturing, and distribution sectors. The platform provides tools for creating high-quality visuals, personalized virtual showrooms, product customization, and AI room visualization, enhancing customer engagement and driving sales.
Leela AI
Leela AI is a visual intelligence platform and analytics software designed to help manufacturing companies increase production capacity, reduce wasted time, improve workplace safety, and streamline operations. By leveraging AI technology, Leela AI turns standard cameras into powerful data feeds, enabling real-time monitoring, analysis, and optimization of manufacturing processes. The platform provides actionable insights to enhance performance, quality, and safety, ultimately leading to significant cost savings and operational improvements for manufacturing businesses.
Creaition
Creaition is an AI-powered visual creation tool that allows users to effortlessly create stunning designs in a completely visual workflow. With advanced AI technology, users can explore endless design variations, blend designs seamlessly, and selectively regenerate parts of images while keeping the overall design intact. The tool offers a curated feed of inspirations, a natural design environment, and a personalized palette of ingredients for design freedom. Creaition is revolutionizing the design process by providing a comprehensive overview of the creative journey and enhancing the user experience through cutting-edge AI technology.
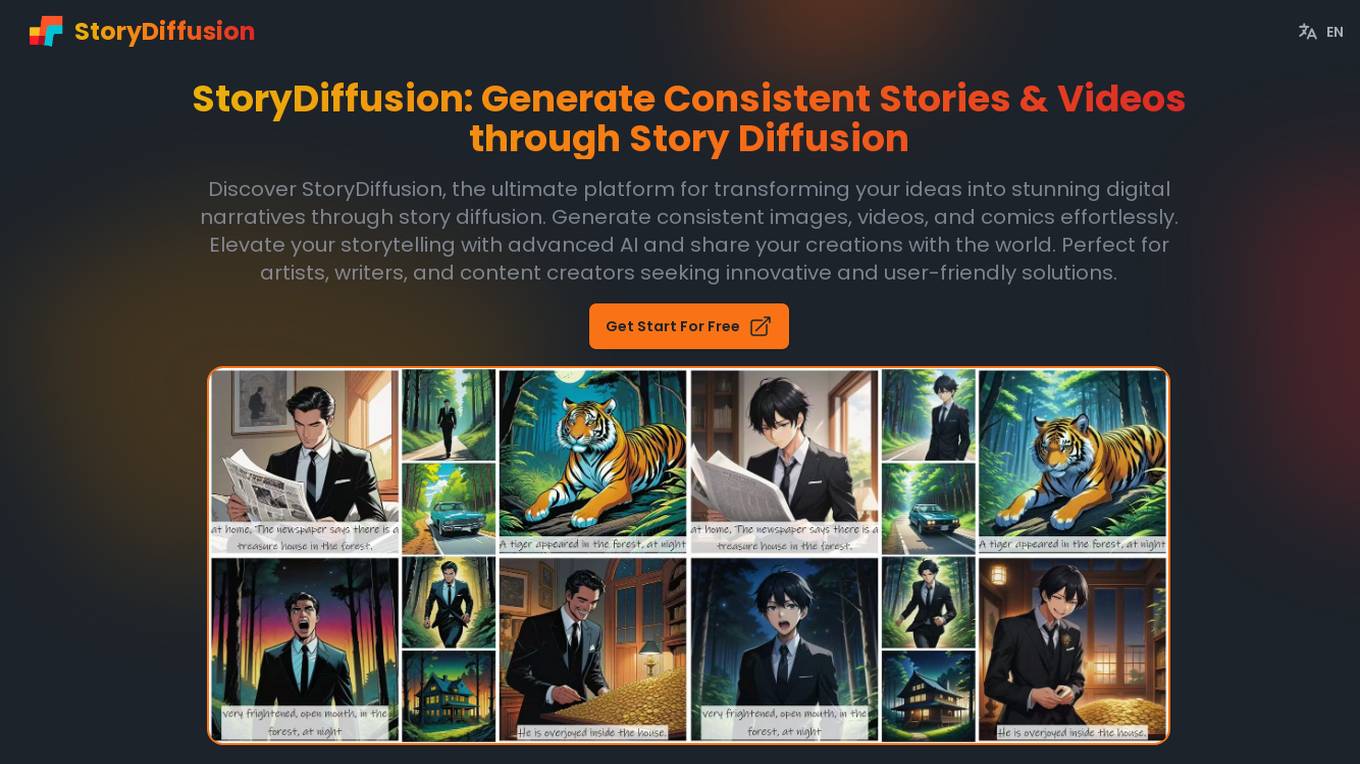
StoryDiffusion
StoryDiffusion is a digital platform that leverages advanced AI to help users generate consistent and high-quality visual content, including images, videos, and comics, based on text prompts. It offers a user-friendly interface and unique features to transform ideas into compelling digital narratives, making it ideal for artists, writers, and content creators seeking innovative solutions.

Vizit
Vizit is a Visual AI & Content Effectiveness Analytics Platform that helps businesses optimize their visual content for better engagement and sales. Using AI technology, Vizit analyzes images and designs to understand consumer preferences, improve visuals, and monitor content effectiveness. The platform empowers brands to create high-impact visuals that drive conversions and boost online sales.
Luxonis
Luxonis is an AI application that offers Visual AI solutions engineered for precision edge inference. The application provides stereo depth cameras with unique features and quality, enabling users to perform advanced vision tasks on-device, reducing latency and bandwidth demands. With open-source DepthAI API, users can create and deploy custom vision solutions that scale with their needs. Luxonis also offers real-world training data for self-improving vision intelligence and operates flawlessly through vibrations, temperature shifts, and extended use. The application integrates advanced sensing capabilities with up to 48MP cameras, wide field of view, IMUs, microphones, ToF, thermal, IR illumination, and active stereo for unparalleled perception.
1 - Open Source AI Tools
vision-llms-are-blind
This repository contains the code and data for the paper 'Vision Language Models Are Blind'. It explores the limitations of large language models with vision capabilities (VLMs) in performing basic visual tasks that are easy for humans. The repository presents benchmark results showcasing the poor performance of state-of-the-art VLMs on tasks like counting line intersections, identifying circles, letters, and shapes, and following color-coded paths. The research highlights the challenges faced by VLMs in understanding visual information accurately, drawing parallels to myopia and blindness in human vision.
20 - OpenAI Gpts

Visual Storyteller
Extract the essence of the novel story according to the quantity requirements and generate corresponding images. The images can be used directly to create novel videos.小说推文图片自动批量生成,可自动生成风格一致性图片
Visual Pedestrian Pathfinder
I create tailored walks, asking detailed preferences and giving distance in km!
Visual Design GPT ✅ ❌
A resource for visual designers, "Principles and Pitfalls" details how to make impactful visual designs and avoid missteps.
Visual Artists Career Guide
A mega-helpful guide for visual artists seeking career and 2024 marketing advice. It includes offering artistic inspiration and balancing creative and business aspects, and it can be trained on and understand your unique journey and aspirations, your challenges, and art forms.
Visual Artist Copilot
This tool is here to help through the creative process generating pictures with DALL.E.
Visual stock analysis
Professional analyzer of stock charts image with factual and concise interpretations.