Best AI tools for< Transcribe Text To Emoji >
20 - AI tool Sites
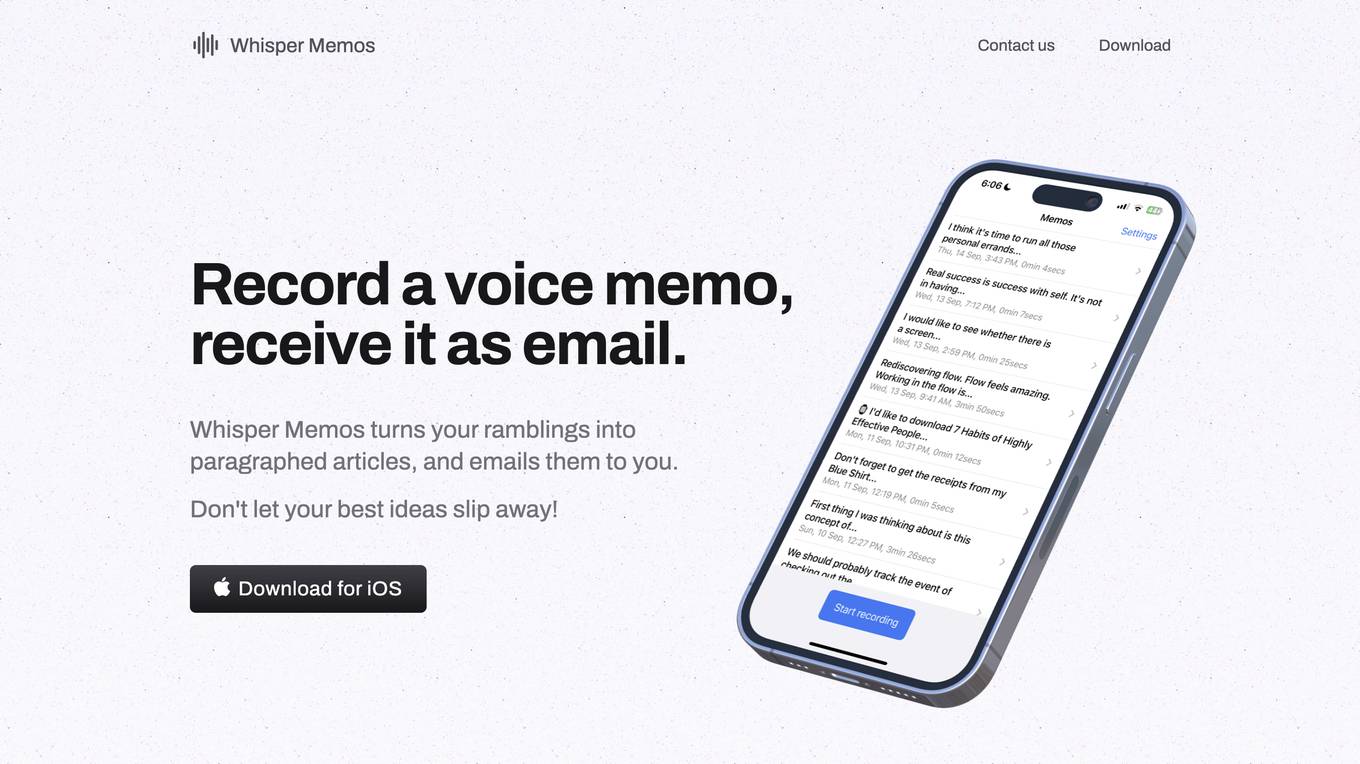
Whisper Memos
Whisper Memos is an application that allows users to record voice memos and have them transcribed into text. The app uses artificial intelligence to generate an emoji or two for the subject of the memo, and to divide the text into paragraphs. Whisper Memos also has a private mode, which allows users to opt-out of storing transcripts in their account.
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.

File Transcribe
File Transcribe is an AI-powered application that offers accurate and effortless transcription of audio and video files. The platform utilizes advanced AI technology, including features like diarization, summaries, speaker identification, and more, to simplify the transcription process. With File Transcribe, users can easily convert spoken words into written text, save time, and work more efficiently. The application provides comprehensive transcription solutions, customizable settings, and expert assistance to ensure a smooth transcription experience for individuals and businesses.

AITransDub
AITransDub is an AI-powered video translation and dubbing tool that breaks language barriers instantly. It offers precise and natural translations while maintaining the warmth and authenticity of the original content. With support for over 50 languages and hundreds of voice options, AITransDub provides smart voice synthesis for a natural pronunciation with authentic emotion. The tool also supports multi-language translation, enabling users to connect with a global audience. AITransDub simplifies the video translation process with its multi-step contextual translation and easy operation, making it a valuable tool for content creators and businesses looking to reach a diverse audience.
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
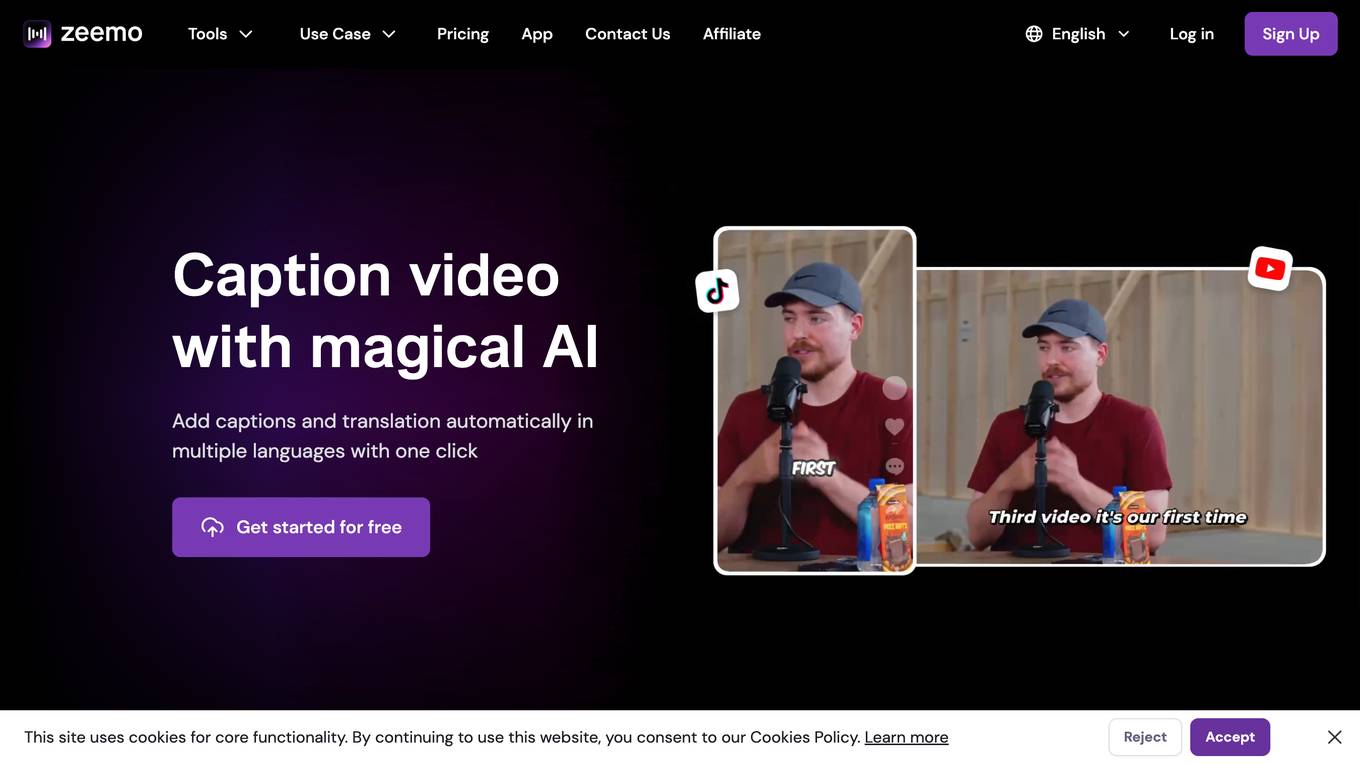
Zeemo AI
Zeemo AI is a powerful caption generator tool that enables users to add subtitles to videos, transcribe video and audio to text, and generate captions using AI technology. It supports multiple languages and provides dynamic visual effects for captions. The tool is designed for content creators, educators, and product sellers to enhance their videos and reach a wider audience across various platforms.
MeduzaAi
MeduzaAi is an all-in-one platform that leverages the power of AI to generate text, images, code, chat, and more with multi-lingual abilities. It offers various tools such as AI Text Generator, AI Image Generator, AI Code Generator, AI Chat Bot, and AI Speech To Text to empower users in content creation and communication. The platform aims to help users unleash their creativity, streamline their coding process, transcribe speech into text, and provide human-like chatbot assistance. MeduzaAi caters to digital agencies, product designers, entrepreneurs, copywriters, digital marketers, and developers, offering a range of features to enhance productivity and creativity.
AiGalaxy
AiGalaxy is an all-in-one AI solution that offers a wide range of user-friendly AI tools in a single app. Users can easily generate images, remove backgrounds, change clothing, create hidden messages, generate QR codes, change ages, extract music and vocals, create voice models, convert images to videos, transcribe speech to text, convert text to speech, turn tunes into music tracks, change voices, unblur images, add sound to videos, create slow-motion videos, restore old images, and more. The app is designed to be easy enough for beginners while also offering powerful features for professionals. AiGalaxy constantly adds new AI tools to its platform, making it a versatile and evolving tool for various tasks.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
Rythmex Converter
Rythmex Converter is an AI-powered audio-to-text converter tool that allows users to easily, quickly, and effectively transcribe audio files into text. With support for over 140 languages, Rythmex offers a seamless transcription experience for various industries such as business, education, journalism, law, and more. Users can upload their audio or video files, choose the language, and receive accurate transcriptions within minutes. The tool is designed to save time and effort by providing automated transcription services using machine learning technology.
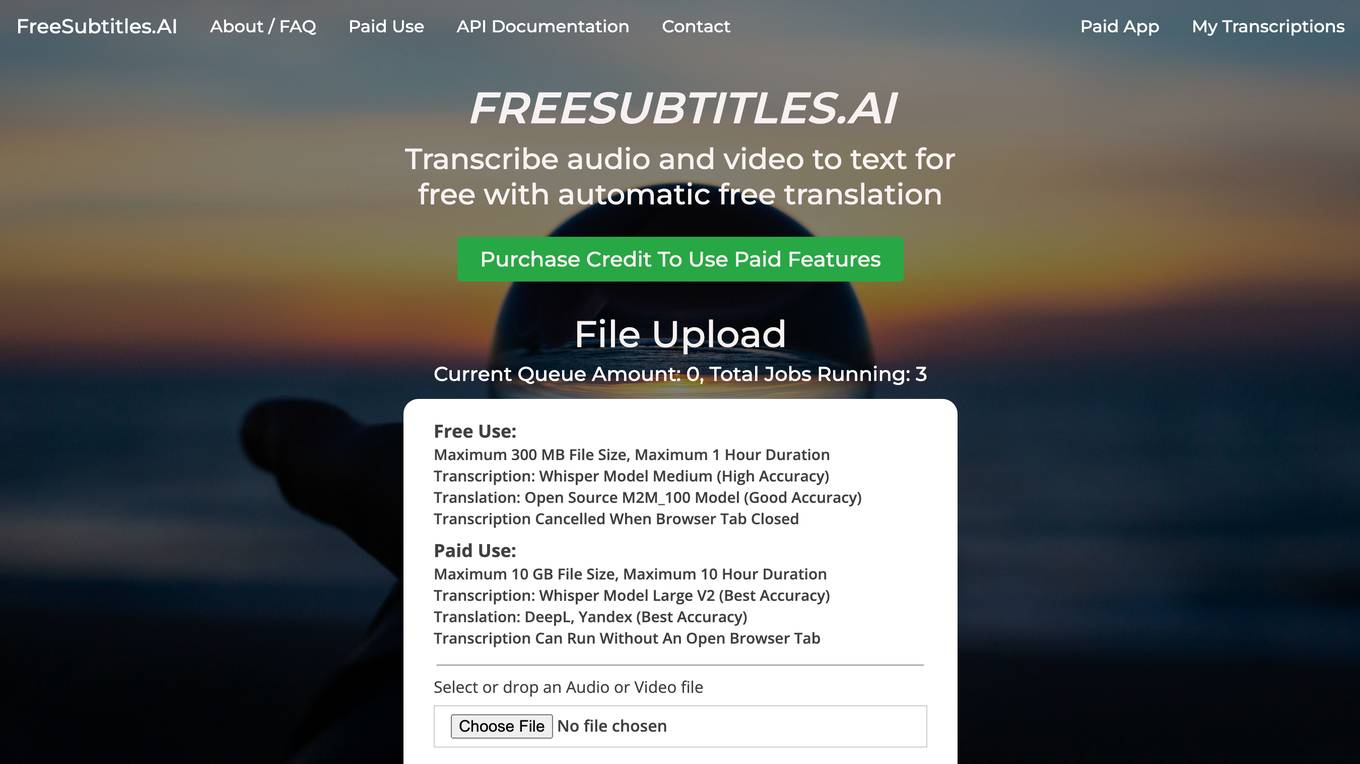
FreeSubtitles.AI
FreeSubtitles.AI is a free online tool that allows users to transcribe audio and video files to text. It supports a wide range of file formats and languages, and offers both free and paid transcription services. The free service allows users to transcribe files up to 300 MB in size and 1 hour in duration, while the paid service offers more advanced features such as larger file size limits, longer transcription durations, and higher accuracy models.
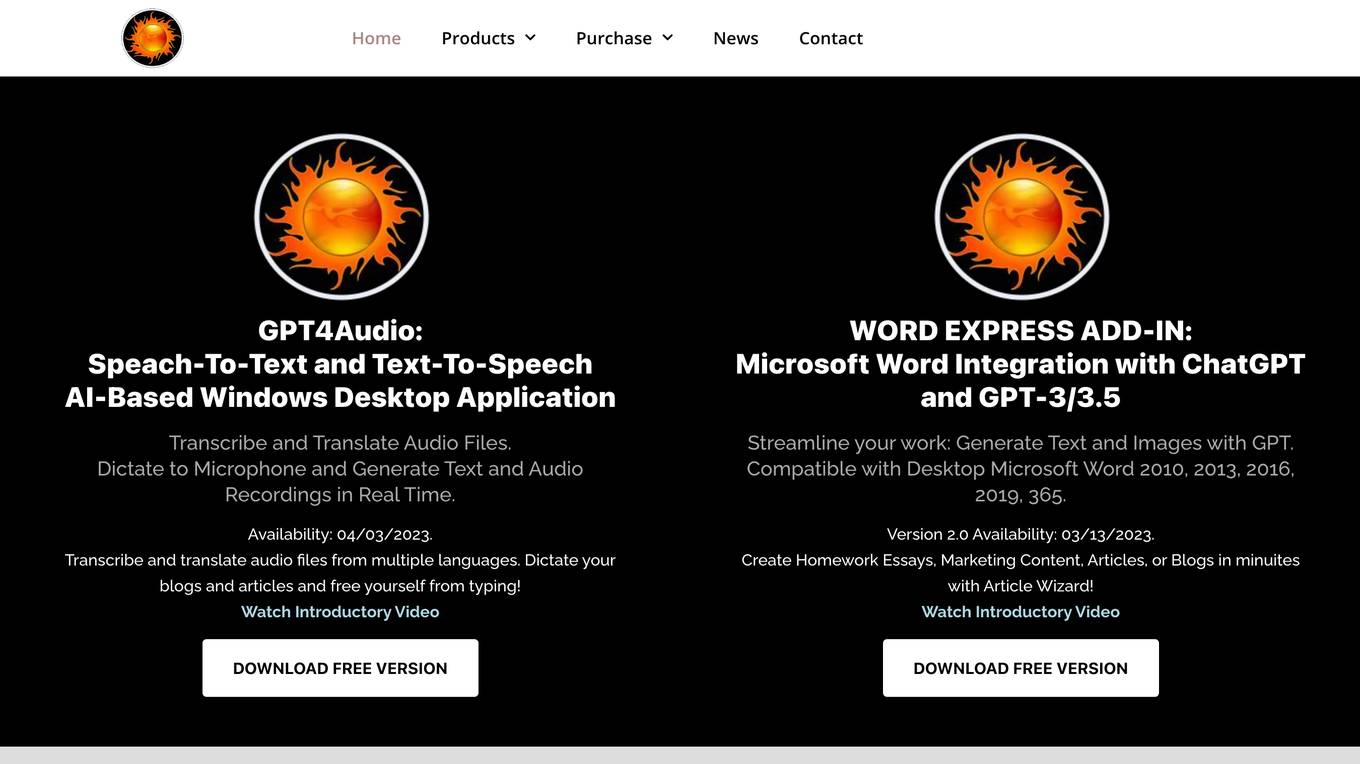
GPT4Audio
GPT4Audio is an AI-based desktop application that offers speech-to-text and text-to-speech capabilities. It allows users to transcribe and translate audio files from multiple languages, as well as dictate text and generate audio recordings in real time. The application also includes an Article Wizard feature that can help users create homework essays, marketing content, articles, or blogs quickly and easily.
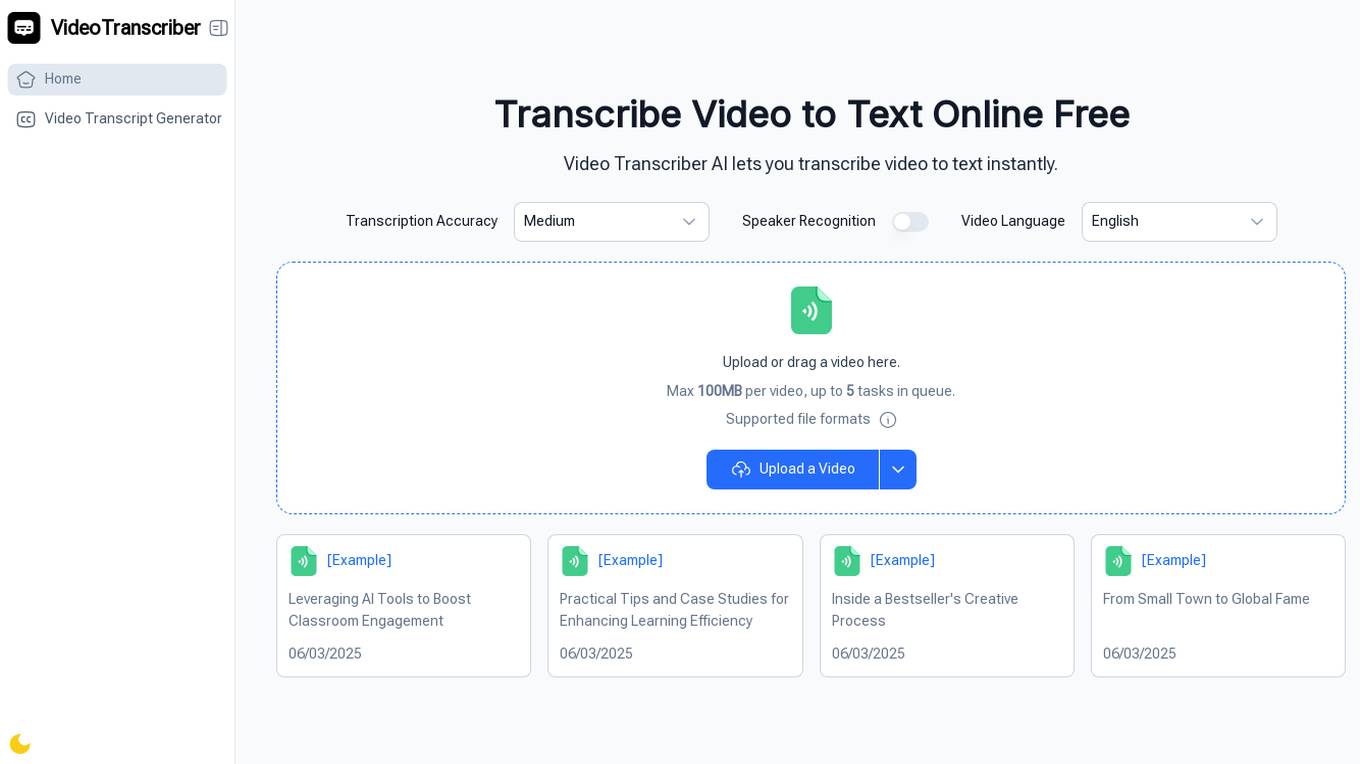
Video Transcriber AI
Video Transcriber AI is an online tool that allows users to transcribe any video into clear, accurate text in seconds. It supports various video formats, speaker recognition, multiple transcription accuracy modes, and works in multiple languages. Users can easily upload videos, let AI transcribe them, and then copy, download, or share the transcripts for study, work, or content creation.
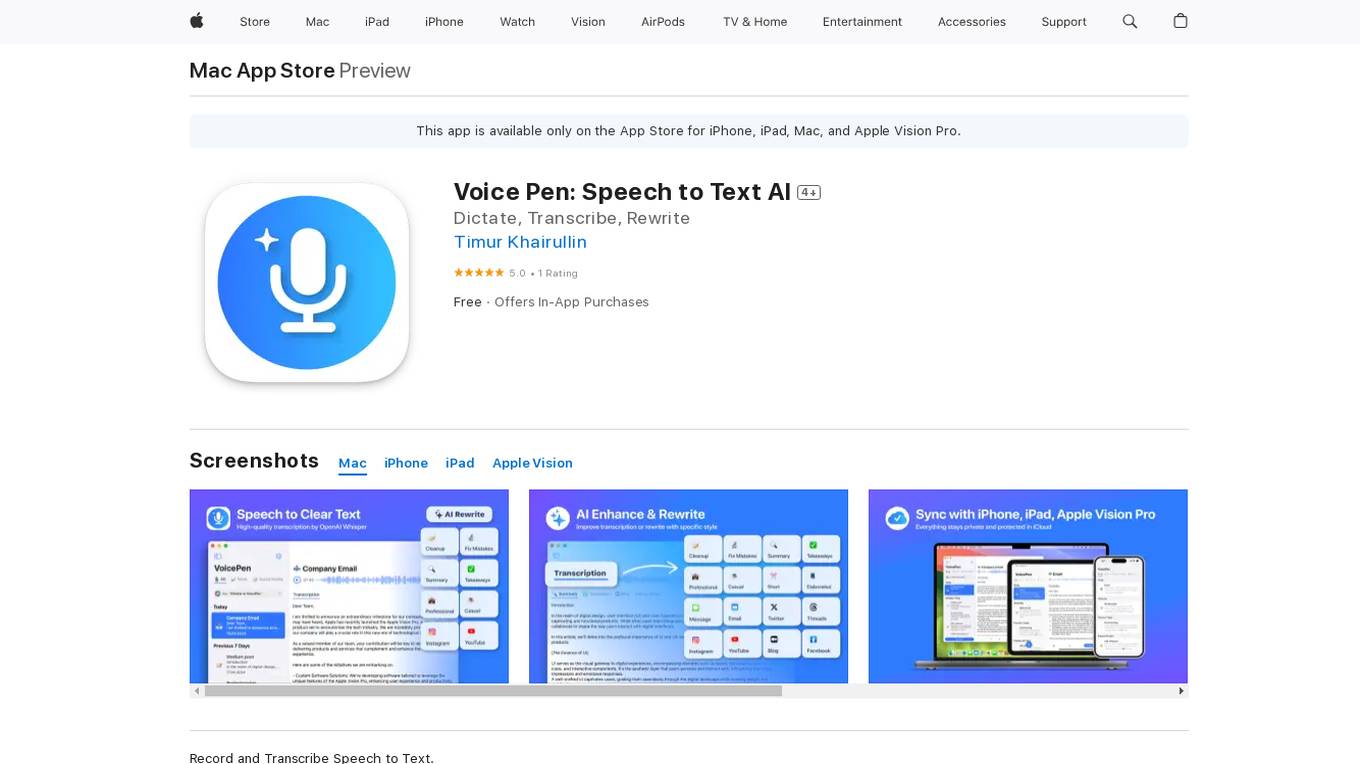
Voice Pen
Voice Pen is a Speech to Text AI application available on the App Store for Apple devices. It allows users to record and transcribe speech into text, which can then be used to create notes, summaries, emails, messages, and blog posts. The app supports more than 50 languages and offers AI options for rewriting and transforming text. Voice Pen enhances productivity by providing features like background audio recording, language autodetection, and the ability to create various types of content. It also prioritizes user privacy by only collecting app usage analytics and not storing any audio or text data on its servers.
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
Vemo AI
Vemo AI is a cutting-edge voice-to-text application that transforms messy voice notes into publish-ready text in a fraction of the time. With the latest AI technologies, Vemo allows users to effortlessly record their thoughts, ideas, or anything else, and then transcribe them into various types of content such as journal entries, cleaned-up transcripts, and blogs. Users can edit and restyle their notes as they wish, enhancing their productivity and creativity. Vemo AI has received rave reviews for its accuracy, ease of use, and ability to streamline note-taking processes, making it a must-have tool for writers, bloggers, students, and professionals.
Vocaldo
Vocaldo is a revolutionary speech-to-text application that utilizes cutting-edge AI technology to transcribe speech into text in over 100 languages. It offers accurate, fast, and easy-to-use transcription services, allowing users to effortlessly convert audio or video files into text with high precision. Vocaldo supports multiple speakers, various accents, and background noise, making it a versatile tool for content creators, journalists, and businesses worldwide.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
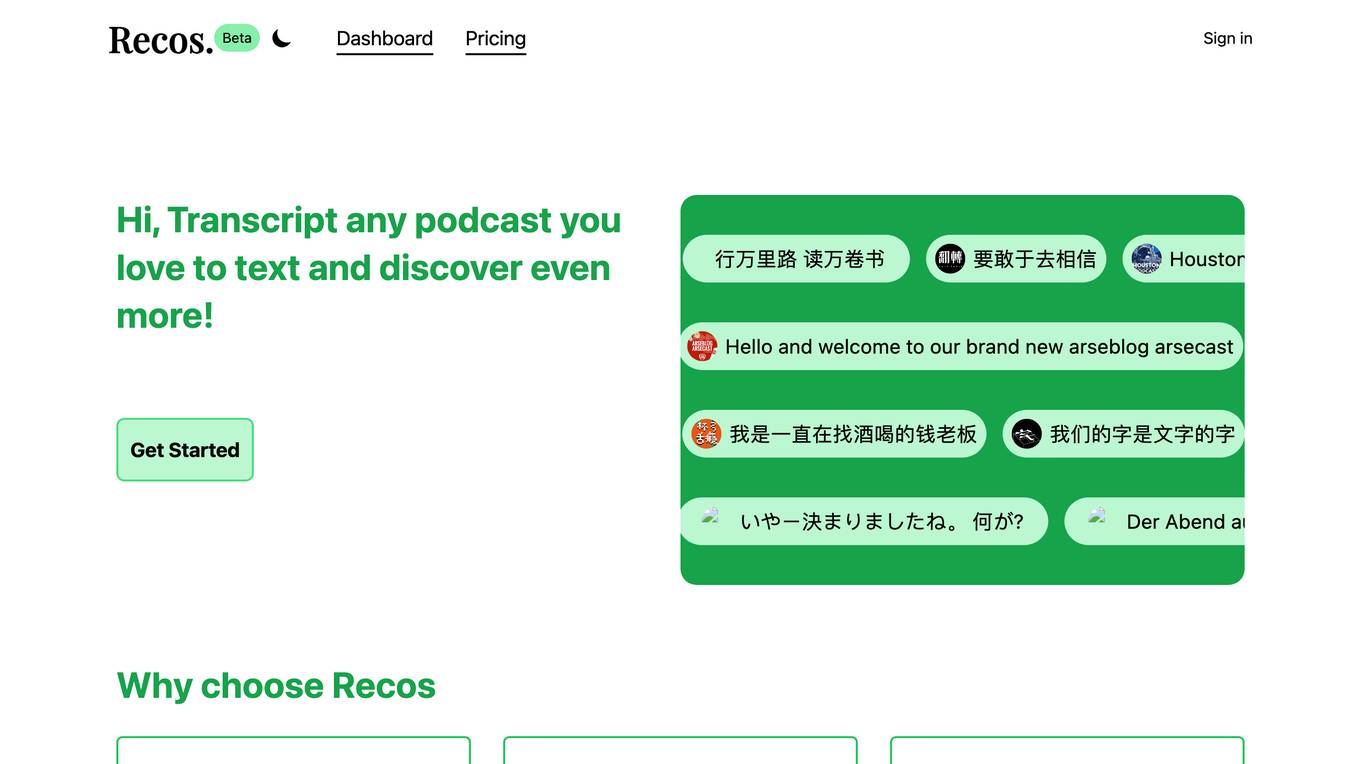
Recos
Recos is a web application that transcribes audio content into text using OpenAI's Whisper API. It offers stability, scalability, and privacy features. Recos supports various audio file formats and provides accurate transcriptions. Users can generate one minute of audio transcription per credit.
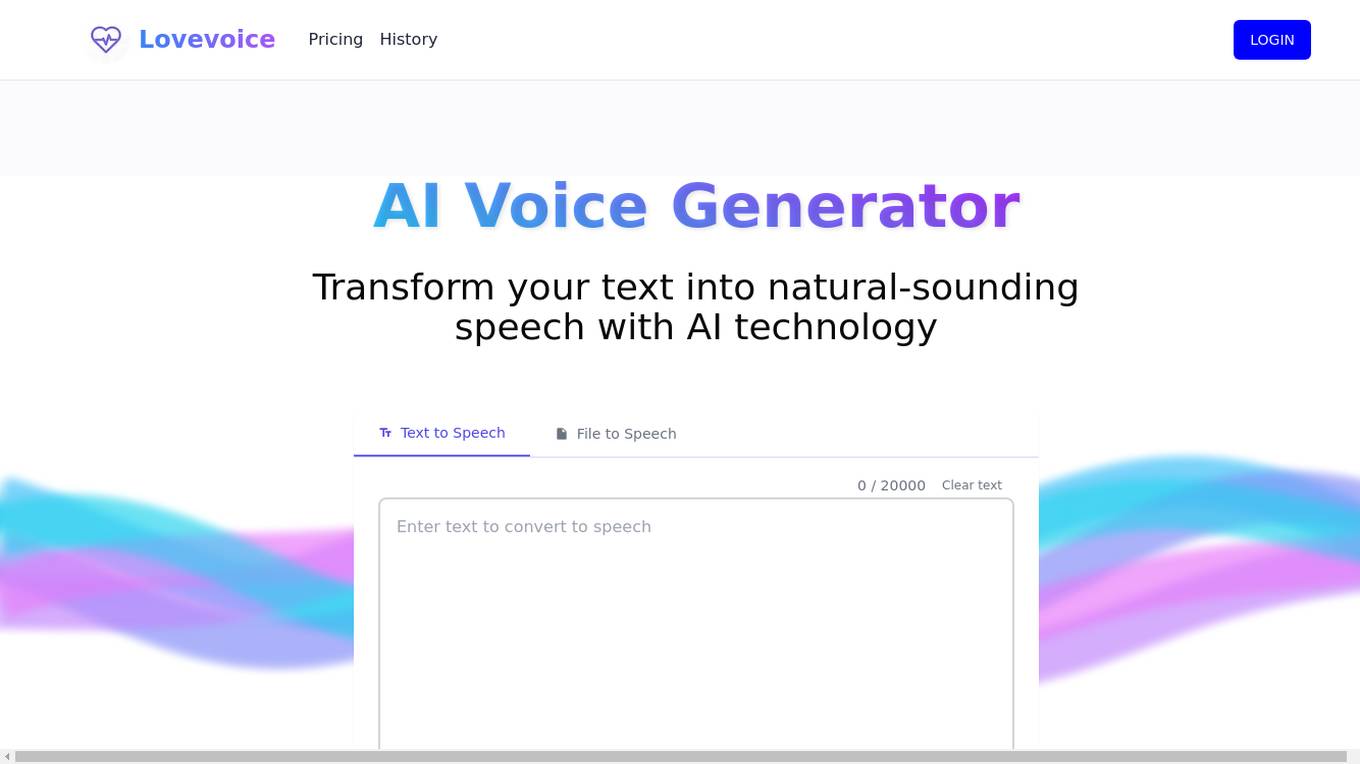
Lovevoice AI Voice Generator
Lovevoice is an AI Voice Generator that transforms text into natural-sounding speech using AI technology. It offers over 70 languages and nearly 300 AI voices, customizable voice settings, file transcription support, and MP3 download capabilities. Lovevoice's advanced AI ensures generated voiceovers are human-like, making it ideal for various applications such as videos, podcasts, audiobooks, and personalized audio messages. Users can quickly convert text into high-quality audio files with multilingual global support.
0 - Open Source AI Tools
20 - OpenAI Gpts

Pic2Text
Friendly GPT for converting images to text, focusing on user-friendly interactions.



CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Journal Recognizer OCR
Optimized OCR for Handwritten Notebooks, up to 10 image transcript copy w/1-click. No text prompt necessary. Reads journals, reports, notes. All handwriting transcribed verbatim, then text summarized, graphic image features described. Ask to change any behavior.

Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.

SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.



Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
Transcript to Social Post
Transforms transcripts (from Whatsapp voice memos) into engaging social media content.