Best AI tools for< Transcribe Audios >
20 - AI tool Sites
UniScribe
UniScribe is an AI-powered tool that allows users to transcribe and translate audio and video files quickly and efficiently. It supports 98 languages and offers features such as fast transcription, smart summaries, mind mapping, key Q&A extraction, and various export formats. UniScribe is designed to help users easily convert audio and video content into text, making information retrieval faster and more convenient.

Audioscribe
Audioscribe is an AI-powered Record-to-Text tool developed by Wordware. It allows users to easily convert spoken words into well-structured notes. The tool is designed to help individuals clean up their thoughts by recording and transforming them into organized text. Audioscribe is part of Wordware's suite of applications that aim to streamline various tasks through AI technology, catering to both technical and non-technical users.
BlogMyVideo
BlogMyVideo is a web-based application that converts videos and audio files into written blog posts using artificial intelligence (AI) technology. It allows users to easily transform their video content into engaging and search engine optimized blog posts, making it more accessible to a wider audience and improving discoverability. The application features seamless YouTube integration, allowing users to sync their YouTube videos for automatic conversion. Additionally, it supports uploading audio files and podcasts for conversion, providing a versatile solution for content creators. BlogMyVideo offers editing capabilities, enabling users to customize the generated text to match their style and preferences. The platform also includes SEO optimization features such as optimized meta tags, canonical links, and structured Schema markup to enhance search engine visibility and performance.
TranscribeMe
TranscribeMe is an application that allows users to convert voice notes from WhatsApp and Telegram into text. It is a free-to-use bot that does not require any downloads or additional information. TranscribeMe also offers a paid subscription service called TranscribeGo, which allows users to transcribe an unlimited number of audios and perform precise audio analysis. TranscribeMe is a valuable tool for anyone who wants to save time and effort by converting voice notes into text.
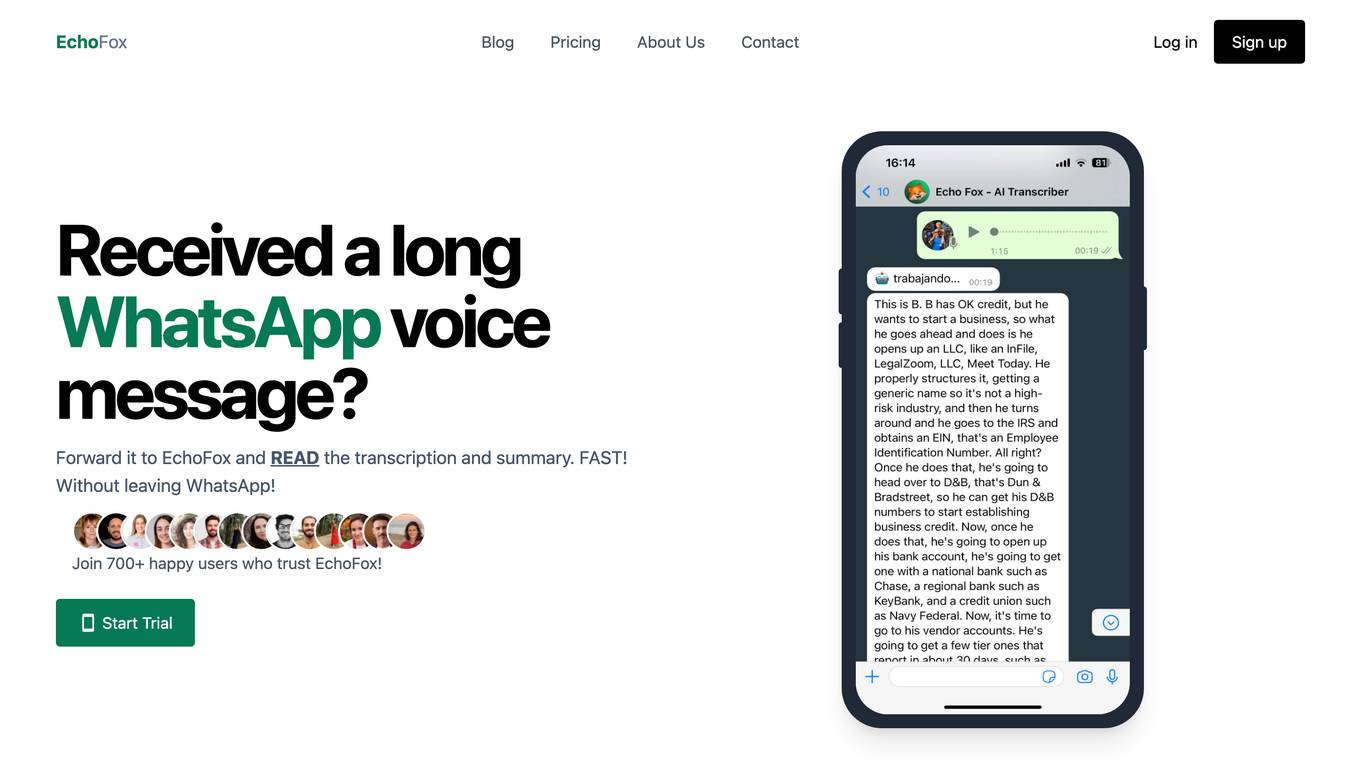
EchoFox
EchoFox is an AI-powered personal transcriber tool designed for WhatsApp users. It offers rapid transcriptions and summaries of voice messages, allowing users to read and comprehend content quickly without leaving the WhatsApp platform. With features like instant transcriptions, on-the-go access, effortless searchability, enhanced productivity, and multilingual support, EchoFox aims to streamline communication and improve efficiency for individuals across various professions. The tool prioritizes privacy by using advanced encryption to secure transcriptions and deleting voice messages after 24 hours. EchoFox is user-friendly, accurate, and efficient, making it a valuable assistant for managing voice messages effectively.

ScriptMe
ScriptMe is a web-based platform that provides automated transcription and subtitling services. It uses artificial intelligence (AI) to convert audio and video files into text, and then allows users to edit and export the transcripts in a variety of formats. ScriptMe is designed to be fast, accurate, and easy to use, and it can be used for a variety of purposes, including: * Transcribing interviews, lectures, and meetings * Creating subtitles for videos * Generating transcripts for podcasts and webinars * Providing closed captions for videos * Translating audio and video files into different languages
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
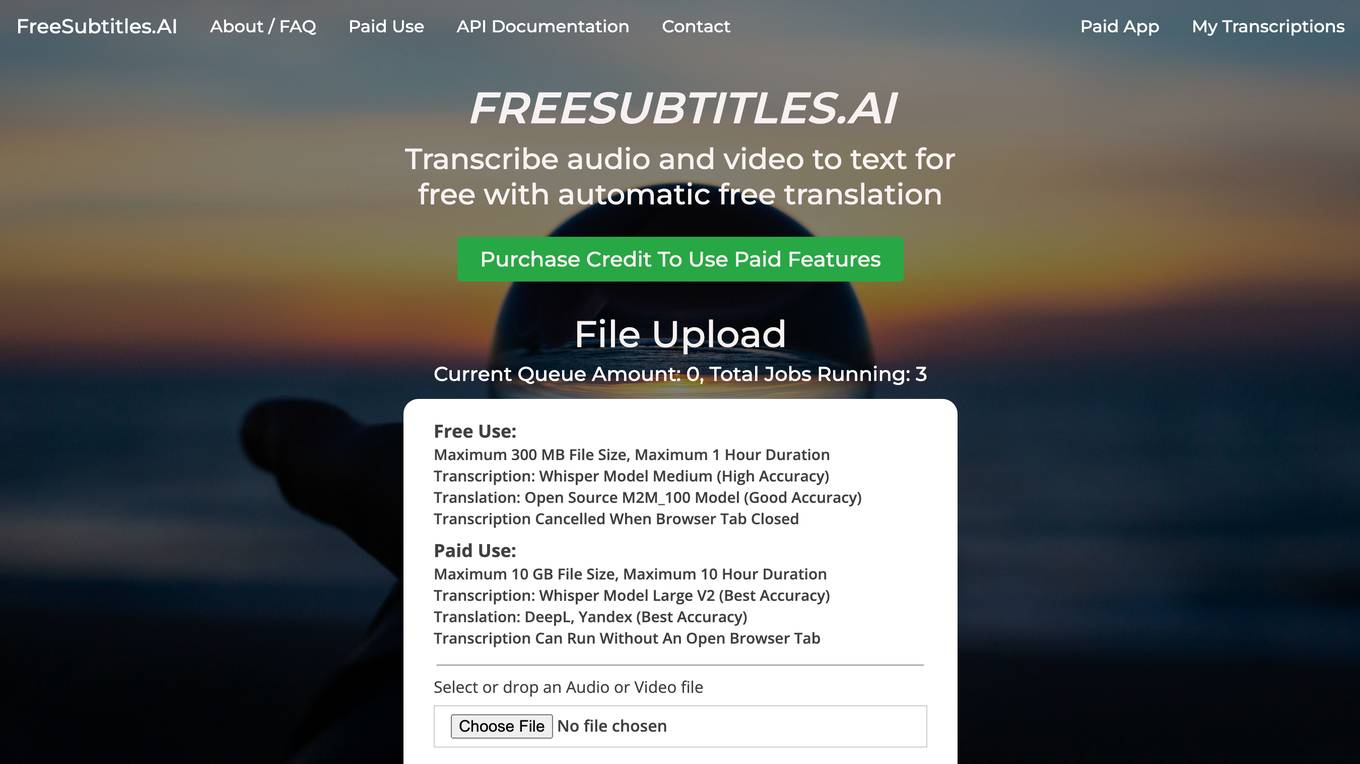
FreeSubtitles.AI
FreeSubtitles.AI is a free online tool that allows users to transcribe audio and video files to text. It supports a wide range of file formats and languages, and offers both free and paid transcription services. The free service allows users to transcribe files up to 300 MB in size and 1 hour in duration, while the paid service offers more advanced features such as larger file size limits, longer transcription durations, and higher accuracy models.
AudioTranscription.ai
AudioTranscription.ai is a fast, secure, and accurate AI-powered transcription tool for audio and video files. It offers lightning-speed transcriptions, accurate language transcriptions in over 70 languages, speaker identification, and a user-friendly dashboard for easy management. The tool also provides API access for seamless integration and hassle-free transcription services.
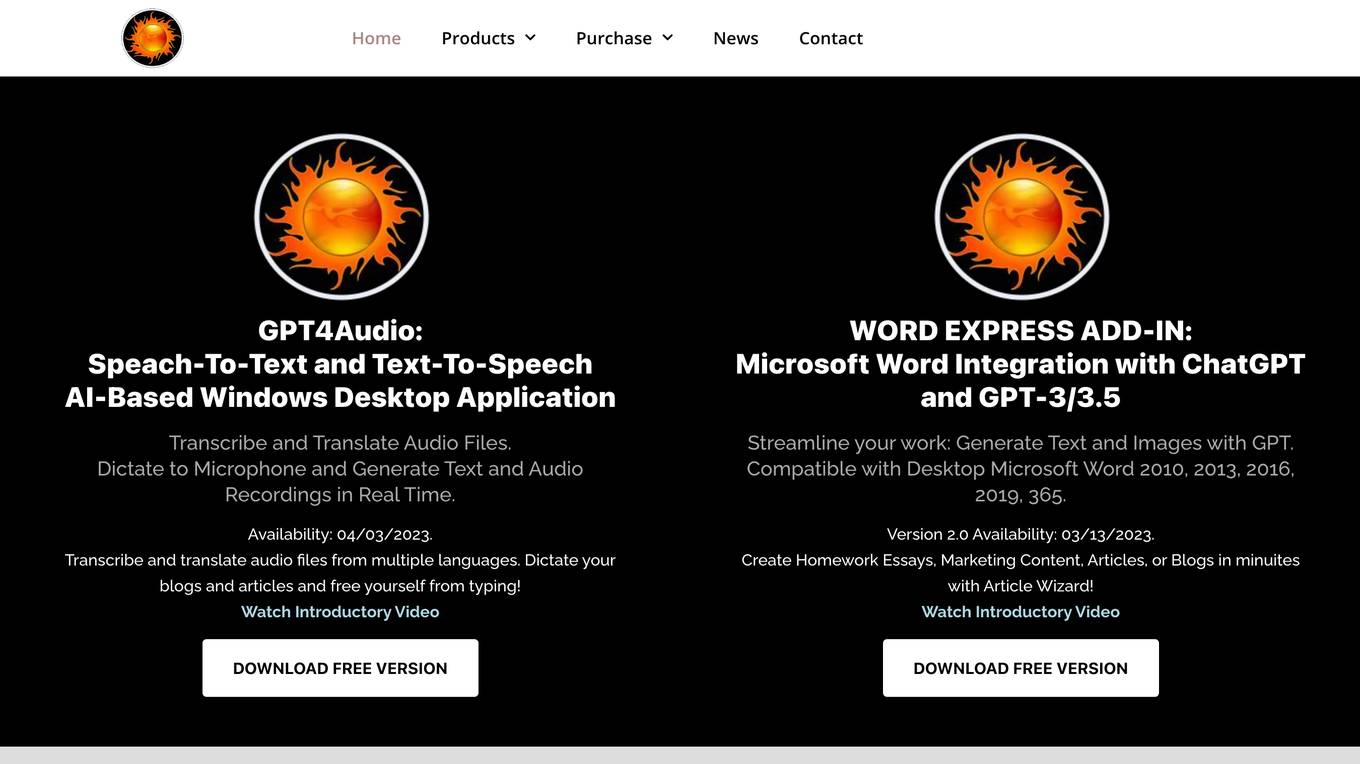
GPT4Audio
GPT4Audio is an AI-based desktop application that offers speech-to-text and text-to-speech capabilities. It allows users to transcribe and translate audio files from multiple languages, as well as dictate text and generate audio recordings in real time. The application also includes an Article Wizard feature that can help users create homework essays, marketing content, articles, or blogs quickly and easily.
Rythmex Converter
Rythmex Converter is an AI-powered audio-to-text converter tool that allows users to easily, quickly, and effectively transcribe audio files into text. With support for over 140 languages, Rythmex offers a seamless transcription experience for various industries such as business, education, journalism, law, and more. Users can upload their audio or video files, choose the language, and receive accurate transcriptions within minutes. The tool is designed to save time and effort by providing automated transcription services using machine learning technology.
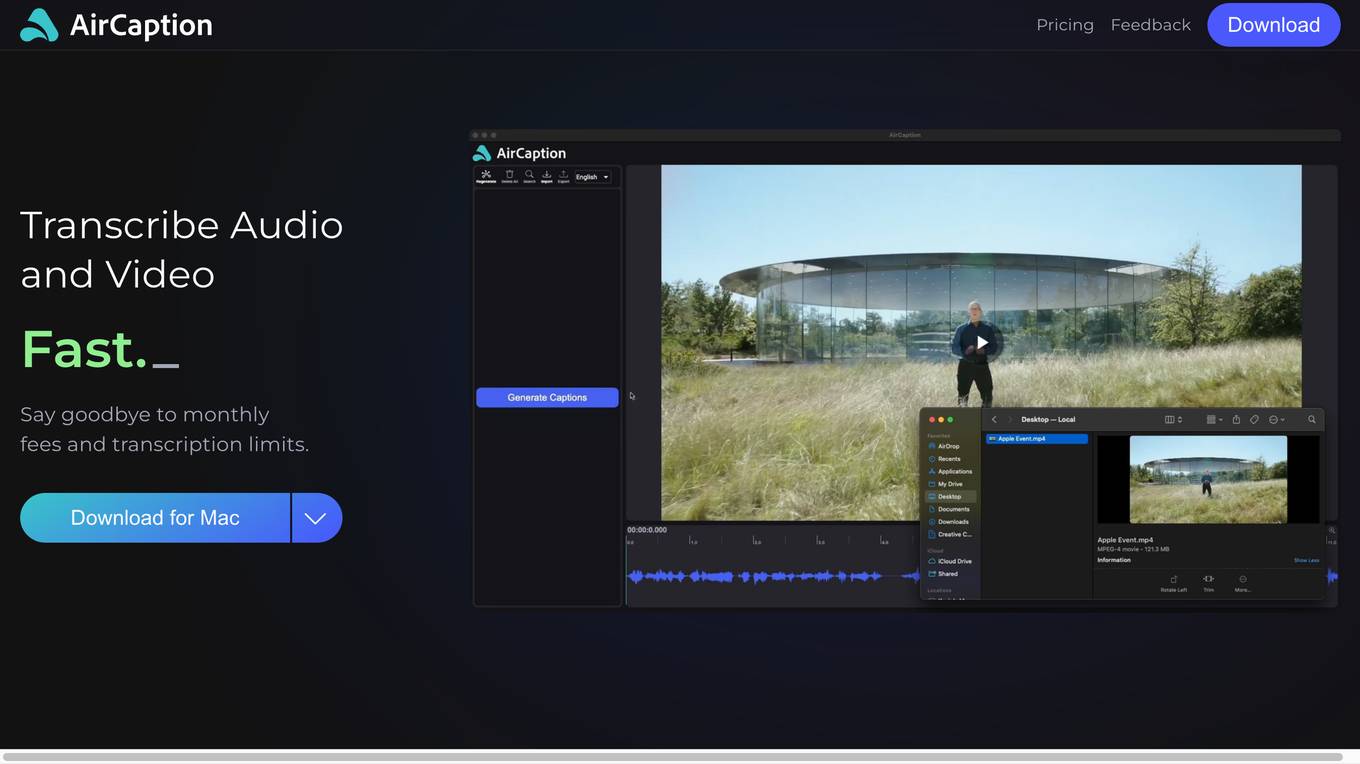
AirCaption
AirCaption is an AI-powered speech to text transcription tool that enables users to transcribe audio and video content quickly and efficiently. It offers the ability to generate AI captions, review and edit them, and export caption files in up to 60 languages. The application works offline, ensuring privacy by keeping media and captions on the user's computer. AirCaption is suitable for various professionals such as video editors, podcasters, language learners, legal professionals, marketers, researchers, event organizers, online course creators, and journalists.
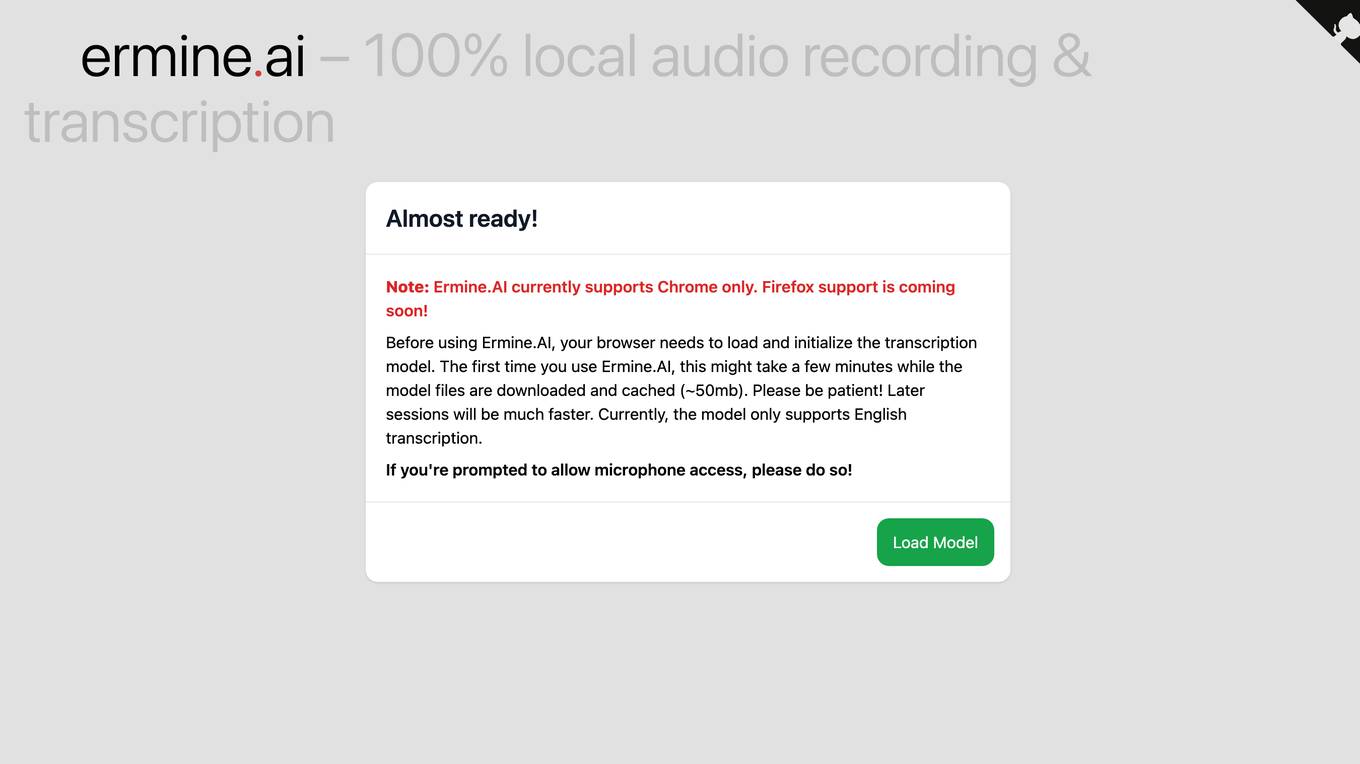
Ermine.ai
Ermine.ai is an AI-powered tool for local audio recording and transcription. It allows users to transcribe audio files into text with high accuracy and efficiency. The tool is designed to work seamlessly with Chrome browser, with Firefox support coming soon. Users can easily transcribe audio files in English by allowing microphone access and initializing the transcription model. Ermine.ai provides a convenient solution for transcribing audio content for various purposes, such as meetings, interviews, lectures, and more.
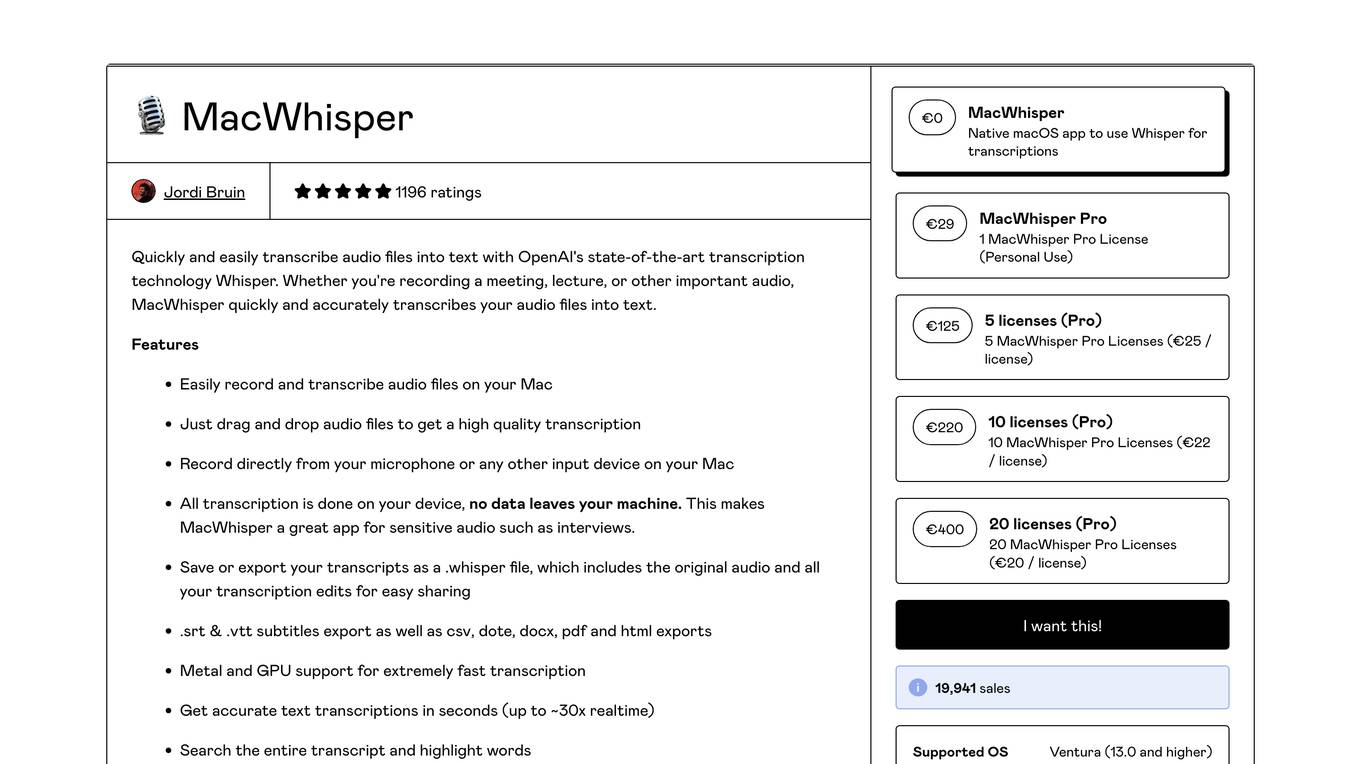
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
VideoToWords.ai
VideoToWords.ai is an AI-powered transcription tool that converts audio and video files into accurate written text. It utilizes advanced machine learning algorithms to transcribe files quickly and efficiently, catering to a wide range of users such as journalists, students, researchers, podcast hosts, filmmakers, content creators, marketers, and professionals from various industries. The platform supports multiple languages, offers convenient text editing and export options, and ensures data security and privacy for users.
SpeechFlow
SpeechFlow is a powerful speech-to-text API that transcribes audio and video files into text with high accuracy. It supports 14 languages and offers features such as punctuation, easy deployment, scalability, and fast processing. SpeechFlow is ideal for businesses and individuals who need accurate and timely transcription services.
Trint
Trint is an AI transcription software that converts video, audio, and speech to text in over 40 languages with up to 99% accuracy. It allows users to transcribe, translate, edit, and collaborate seamlessly in a single workflow. Trint is trusted by professionals in various industries for its efficiency and accuracy in transcription tasks.
WavoAI
WavoAI is an AI-powered transcription and summarization tool that helps users transcribe audio recordings quickly and accurately. It offers features such as speaker identification, annotations, and interactive AI insights, making it a valuable tool for a wide range of professionals, including academics, filmmakers, podcasters, and journalists.
Audio Writer
Audio Writer is a voice-to-text transcription app that uses AI to refine and rewrite transcripts. It can also be used for journaling, content creation, and more. The app is available for iOS and macOS, and it offers a one-time payment option with no subscription required.
Scribewave
Scribewave is an AI-powered online transcription tool that allows users to automatically transcribe audio and video files into text. It supports over 90 languages and dialects, offers accurate transcription with speaker recognition, and provides features like subtitles generation, audio-to-video conversion, and translations to multiple languages. Scribewave is designed to simplify content conversion, saving users time and enabling them to focus on more critical tasks.
1 - Open Source AI Tools
Chenyme-AAVT
Chenyme-AAVT is a user-friendly tool that provides automatic video and audio recognition and translation. It leverages the capabilities of Whisper, a powerful speech recognition model, to accurately identify speech in videos and audios. The recognized speech is then translated using ChatGPT or KIMI, ensuring high-quality translations. With Chenyme-AAVT, you can quickly generate字幕 files and merge them with the original video, making video translation a breeze. The tool supports various languages, allowing you to translate videos and audios into your desired language. Additionally, Chenyme-AAVT offers features such as VAD (Voice Activity Detection) to enhance recognition accuracy, GPU acceleration for faster processing, and support for multiple字幕 formats. Whether you're a content creator, translator, or anyone looking to make video translation more efficient, Chenyme-AAVT is an invaluable tool.
20 - OpenAI Gpts

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.

Transcript to Social Post
Transforms transcripts (from Whatsapp voice memos) into engaging social media content.


DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.
Multilingual Subtitle Assistant
Subtitles in multiple languages with dialect and colloquial options





Journal Recognizer OCR
Optimized OCR for Handwritten Notebooks, up to 10 image transcript copy w/1-click. No text prompt necessary. Reads journals, reports, notes. All handwriting transcribed verbatim, then text summarized, graphic image features described. Ask to change any behavior.