Best AI tools for< Train A Poop Detection Model >
20 - AI tool Sites
Wonderchat
Wonderchat is an AI chatbot builder that allows you to create a custom chatbot using your business data. You can build a chatbot in 5 minutes that can answer customer support queries, provide information about your products or services, and more. Wonderchat is easy to use, even if you don't have any coding experience. You can embed your chatbot on your website or use it on messaging platforms like Facebook Messenger and WhatsApp.

Teachable Machine
Teachable Machine is a web-based tool that makes it easy to create custom machine learning models, even if you don't have any coding experience. With Teachable Machine, you can train models to recognize images, sounds, and poses. Once you've trained a model, you can export it to use in your own projects.
Full Stack AI
Full Stack AI is a tool that allows users to generate a full-stack Next.js app using an AI CLI. The app will be built with TypeScript, Tailwind, Prisma, Postgres, tRPC, authentication, Stripe, and Resend.
ChatBob
ChatBob is an AI-powered chatbot application designed for businesses to automate customer interactions on their websites. With just a few clicks, users can create a multilingual chatbot that can respond in over 95 languages, catering to a global audience. ChatBob helps businesses collect leads, customize chatbot settings, and remove branding. It offers different pricing plans to suit varying needs, from a free plan with limited features to premium plans with advanced functionalities.
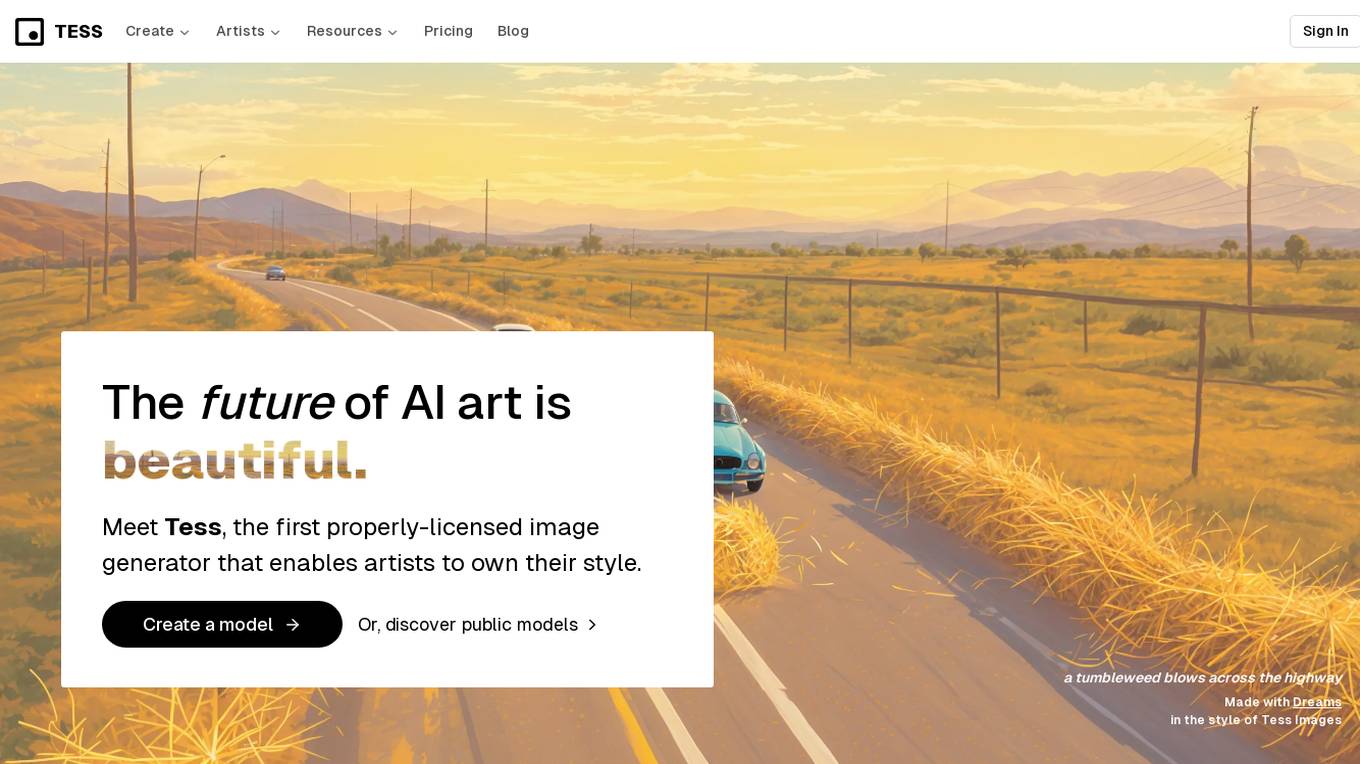
Tess
Tess is the first AI image generator that empowers artists to own their style by creating properly-licensed images. It offers a world-class image editor designed for AI, allowing users to generate art in a consistent visual style. Tess enables artists to create models, edit and customize their generations, and discover how AI can enhance their artistic style. With Tess, users can access copyright-safe generations created by real artists, ensuring ethical AI art practices.
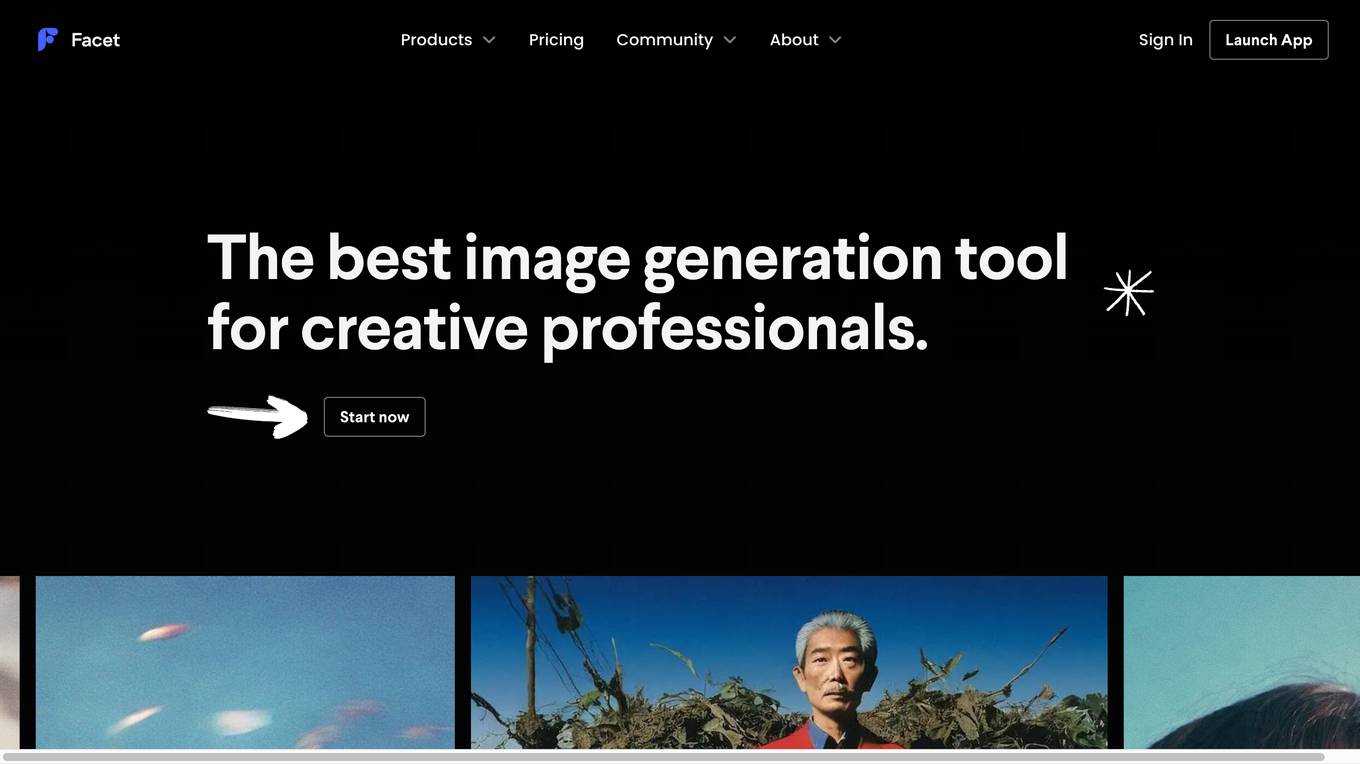
Facet
Facet is a cutting-edge generative imagery tool that helps creative professionals focus on what matters. It provides creative assistance without trading off artistic control. Facet helps overcome time and resource constraints that prevent trying out ideas. It offers an intuitive image generation experience with more than just text prompts, including image references, automatic prompt variations, and even custom models trained on the user's exact aesthetic. Facet allows users to train a custom model using their own images in minutes, generating endless assets in their exact vision. Users can add image references to any prompt, instantly getting images that adhere to their subject or style. Facet provides a collaborative canvas for users to riff with teammates and build off of each other's prompts and ideas.
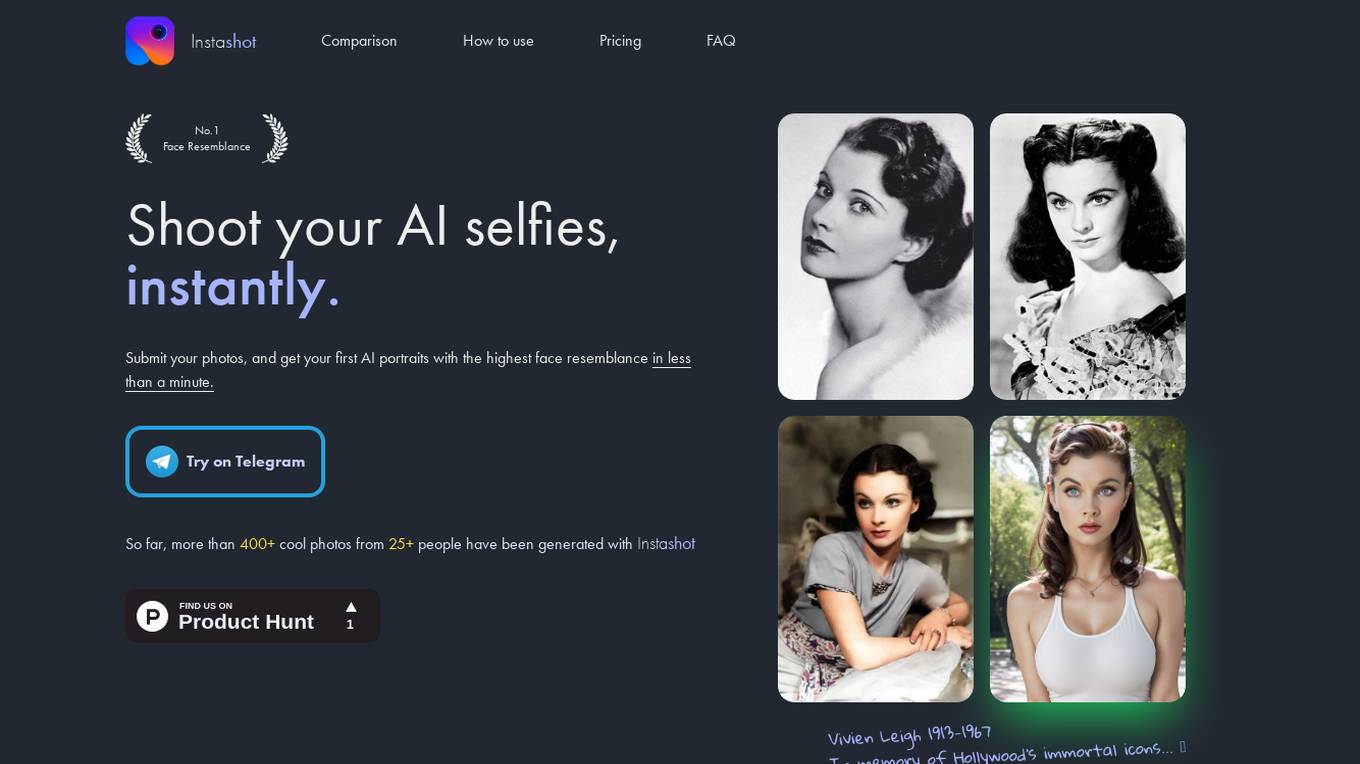
Instashot
Instashot is an AI application that allows users to generate AI portraits with the highest face resemblance in less than a minute. Users can submit their photos to train a custom AI model, which can then be used to generate portraits with unique prompts. The application offers different pricing tiers with varying features and benefits, making it accessible to a wide range of users. Instashot utilizes Stable Diffusion AI technologies to create portraits that best describe the user, ensuring high-quality results. The application is user-friendly, efficient, and provides a fun way to explore AI-generated art.
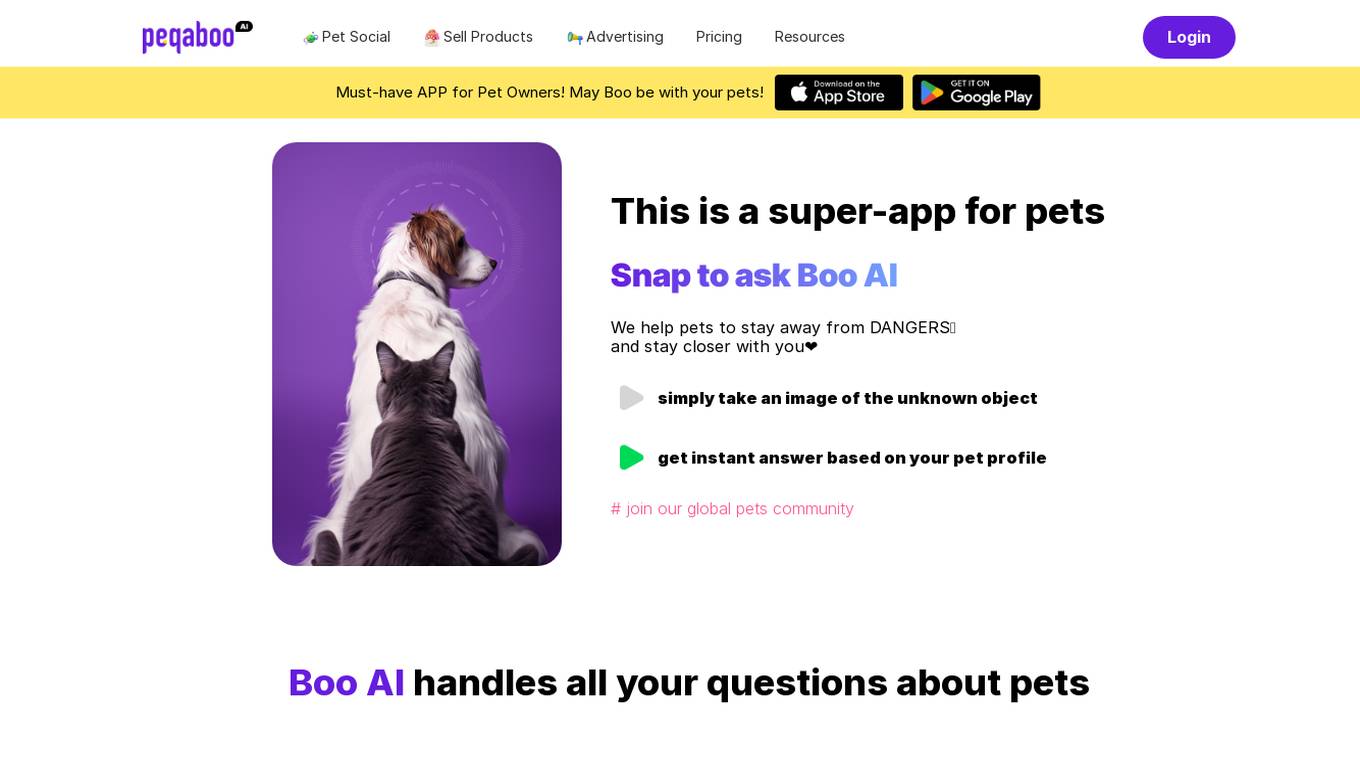
Peqaboo
Peqaboo is an AI-powered pet social app designed to help pet owners with various aspects of pet care. The app allows users to ask Boo AI questions about their pets, identify toxic plants or foods, and receive instant answers based on their pet's profile. Peqaboo also offers a feature to train a new Boo AI, enabling users to transform their knowledge into AI tools. The app aims to make pet life easier and more enjoyable by providing personalized pet care advice and fostering a global pet community.
SnapShotAI
SnapShotAI is an AI-powered platform that allows users to create unique and personalized profile pictures, avatars, and headshots. With SnapShotAI, users can upload their photos and train a custom AI model that generates hundreds of profile pictures in various styles, including artistic, realistic, and cartoonish. The platform offers both standard and high-quality images, suitable for both online use and printing. SnapShotAI also provides gift vouchers for those who want to share the experience with loved ones.

AnythingYou.AI
AnythingYou.AI is an AI tool that generates beautiful profile pictures using AI avatars. Users can create custom AI avatars by uploading 10-20 selfies, and the tool will train a custom model for them immediately. The generated avatar images are high-quality and realistic, created using innovative technologies like Stable Diffusion and DreamBooth. Users can easily create avatars without the need for subscriptions or app installs, and get their avatar images in just 2 hours. The tool ensures user privacy by using images only for model training and deleting them immediately after avatar generation.

Railway Station Error Page
The website page displays a '404 Not Found' error message, indicating that the requested page or resource is not available. It suggests checking network settings and domain provisioning. The message humorously likens the situation to a train not arriving at a station, prompting visitors to inform the site owner of the issue. The page includes a unique Request ID: AIor7PNUR7mzicZ08Zg6wQ_98031763 and a link to 'Go to Railway'.
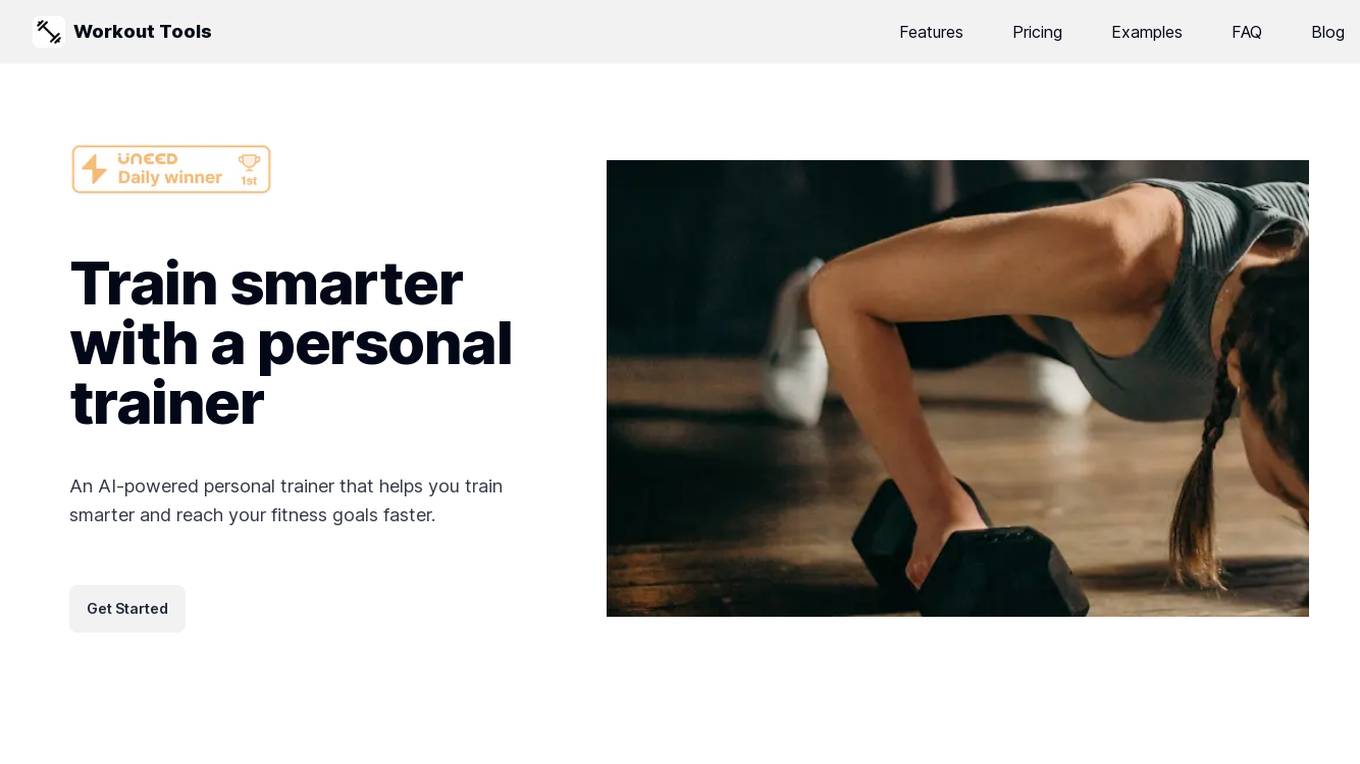
Workout Tools
Workout Tools is an AI-powered personal trainer that helps you train smarter and reach your fitness goals faster. It takes into account different parameters, such as your physics, the type of workout you're interested in, your available equipment, and comes up with a suggested workout. Don't like the workout? Just generate another one. It's that simple.
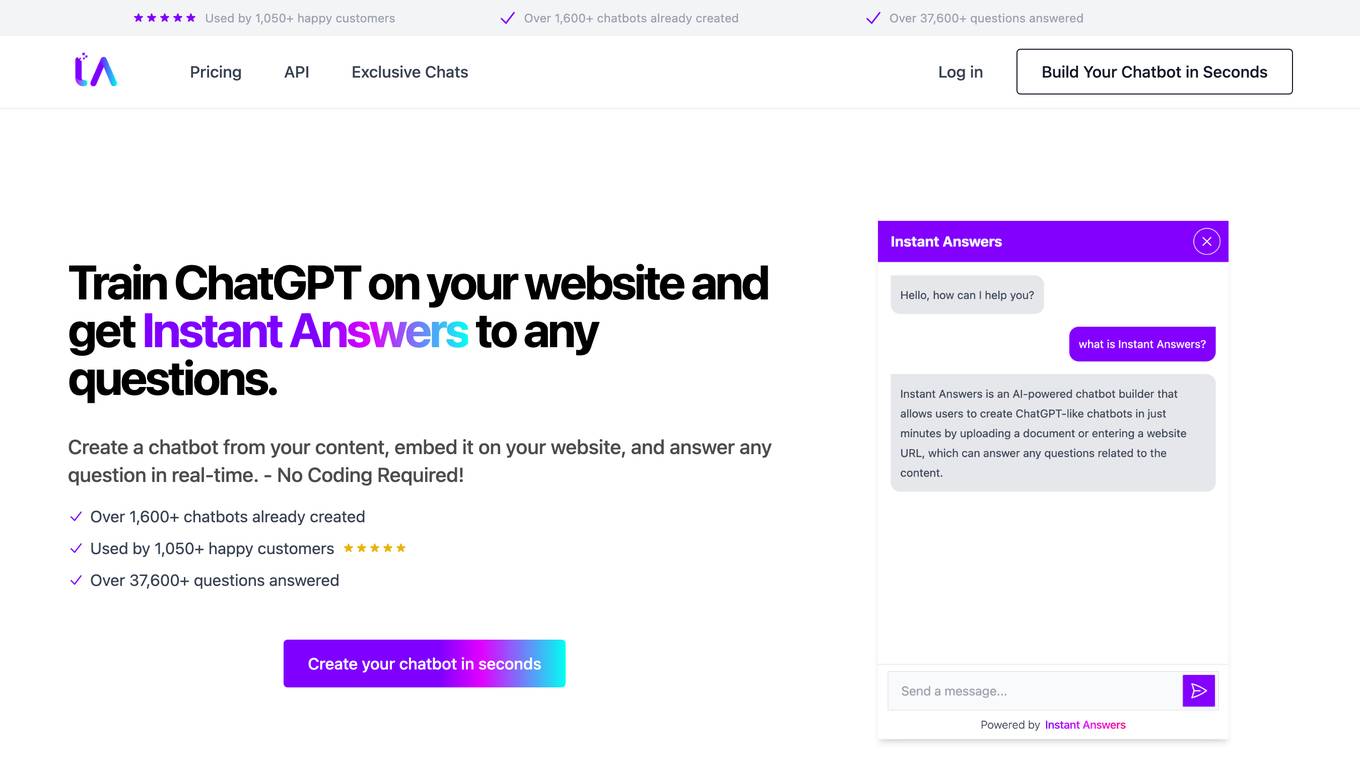
Instant Answers
Instant Answers is an AI-powered chatbot builder that enables users to create customized chatbots for their websites in minutes. The platform allows users to train their chatbots to provide instant answers to a wide range of questions by uploading documents or inputting website URLs. With features like easy customization, effortless integration, conversation analytics, and dynamic learning, Instant Answers offers a user-friendly interface for enhancing customer service and engagement.
Distillery
Distillery is an AI text-to-image generator that empowers users to transform their imagination into visual reality. It offers unparalleled flexibility and control, allowing users to create stunning, high-quality images by simply describing their vision in words. With features like 10 free daily image generations, open-source platform, control over image generation with 25+ parameters, and the ability to train AI with a single image, Distillery is a user-friendly tool suitable for artists, designers, students, and professionals alike.
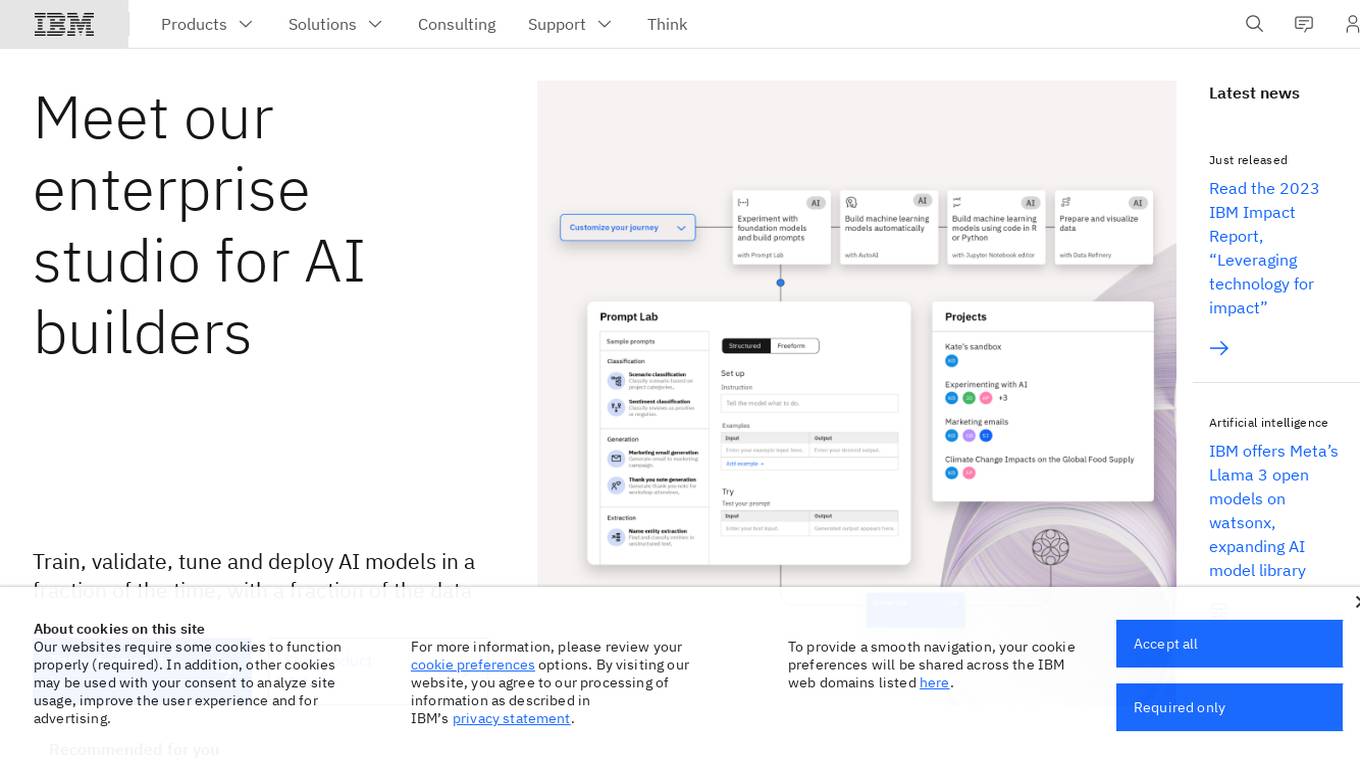
IBM Watsonx
IBM Watsonx is an enterprise studio for AI builders. It provides a platform to train, validate, tune, and deploy AI models quickly and efficiently. With Watsonx, users can access a library of pre-trained AI models, build their own models, and deploy them to the cloud or on-premises. Watsonx also offers a range of tools and services to help users manage and monitor their AI models.
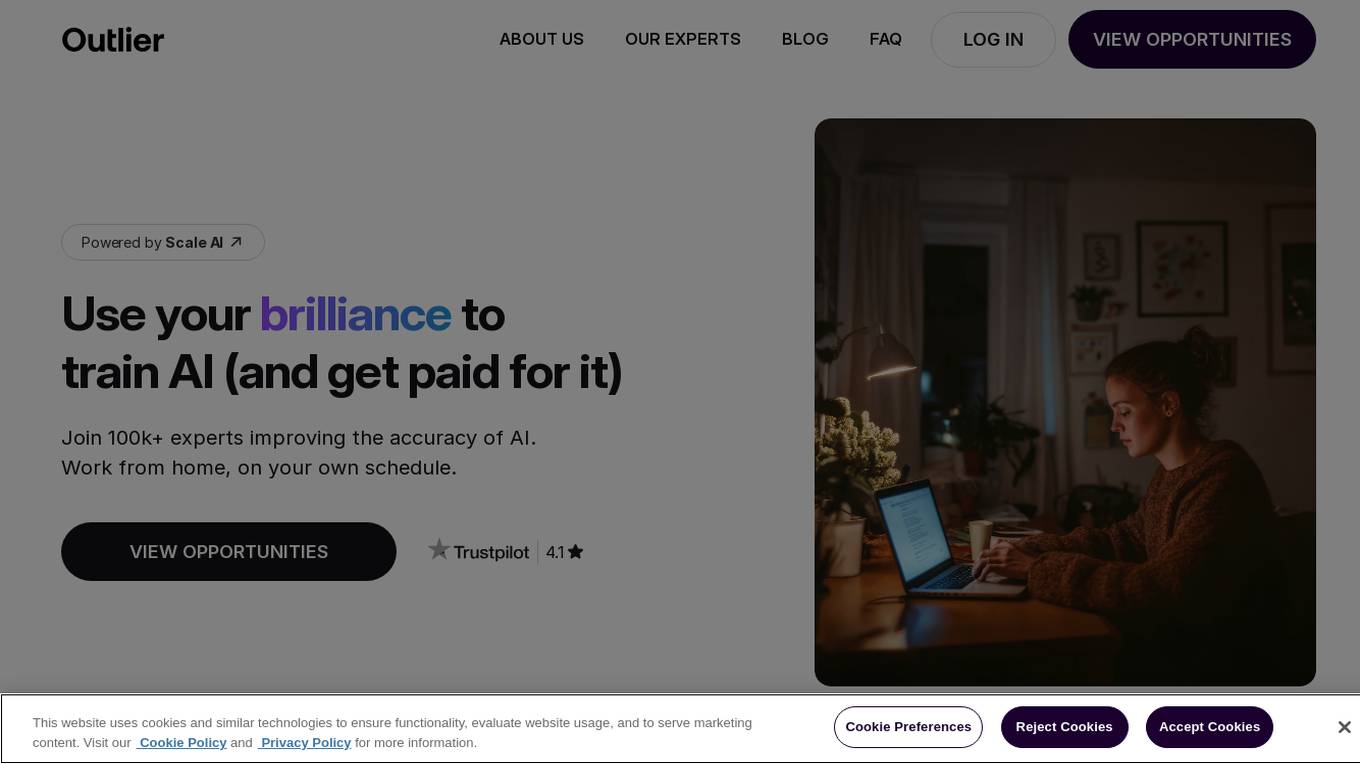
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.

N/A
The website is currently experiencing a temporary service outage, indicated by the error message '503 Service Temporarily Unavailable'. This error is typically displayed when the server is unable to handle the request due to temporary overloading or maintenance. The message 'nginx' suggests that the website is using the Nginx web server software. Users encountering this error are advised to wait for the service to be restored or contact the website administrator for further assistance.

Artificial Intelligence: A Modern Approach, 4th US ed.
Artificial Intelligence: A Modern Approach, 4th US ed. is the authoritative, most-used AI textbook, adopted by over 1500 schools. It covers the entire spectrum of AI, from the fundamentals to the latest advances. The book is written in a clear and concise style, with a wealth of examples and exercises. It is suitable for both undergraduate and graduate students, as well as professionals in the field of AI.
404 Error Page
The website displays a '404 - Page not found' error message, indicating that the requested page does not exist or has been moved. It seems to be a standard error page that users encounter when they try to access a non-existent or relocated webpage.
Lightning AI
I apologize, but the provided website page text does not contain sufficient information to generate a detailed description of the website. The text only mentions the name of the application, "Lightning AI", and indicates that JavaScript is required to run the app. Without further context or content from the website, I cannot provide a comprehensive description.
1 - Open Source AI Tools
shitspotter
The 'ShitSpotter' repository is dedicated to developing a poop-detection algorithm and dataset for creating a phone app that helps locate dog poop in outdoor environments. The project involves training a PyTorch network to detect poop in images and provides scripts for detecting poop in unseen images using a pretrained model. The dataset consists of mostly outdoor images taken with a phone, with a process involving before and after pictures of the poop. The project aims to enable various applications, such as AR glasses for poop detection and efficient cleaning of public areas by city governments. The code, dataset, and pretrained models are open source with permissive licensing and distributed via IPFS, BitTorrent, and centralized mechanisms.
20 - OpenAI Gpts
How to Train a Chessie
Comprehensive training and wellness guide for Chesapeake Bay Retrievers.
Poke Competitive Pro Guide
A Pokémon competitive build expert, sourcing data from Smogon for single and double battles.
Strategic Business Advisor
Expert in IT, entrepreneurship, and AI with tailored business advice

Breed Explorer
Identifies each animal's breed in pictures, focusing on pets and livestock, excluding humans, with care tips.
Solution to Any Problem
I will help you prepare and deal with any crisis now and in the future
Hero Master AI: Superhero Training
Train to become a superhero or a supervillain. Master your powers, make pivotal choices. Each decision you make in this action-packed game not only shapes your abilities but also your moral alignment in the battle between good and evil. Another GPT Simulator by Dave Lalande
Design Recruiter
Job interview coach for product designers. Train interviews and say stop when you need a feedback. You got this!!

Railroad Conductors and Yardmasters Roadmap
Don’t know where to even begin? Let me help create a roadmap towards the career of your dreams! Type "help" for More Information

HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub