Best AI tools for< Token Classification >
20 - AI tool Sites
Token Metrics
Token Metrics is an AI-powered crypto trading and research platform that provides users with real-time market trends, live trade alerts, and AI grades to help make informed investment decisions. With features like AI ratings, personalized research, and trading signals, Token Metrics aims to empower users to navigate the cryptocurrency markets effectively. Trusted by over 70,000 crypto investors, Token Metrics offers a comprehensive suite of tools and resources to enhance crypto investment strategies.
Token Counter
Token Counter is an AI tool designed to convert text input into tokens for various AI models. It helps users accurately determine the token count and associated costs when working with AI models. By providing insights into tokenization strategies and cost structures, Token Counter streamlines the process of utilizing advanced technologies.
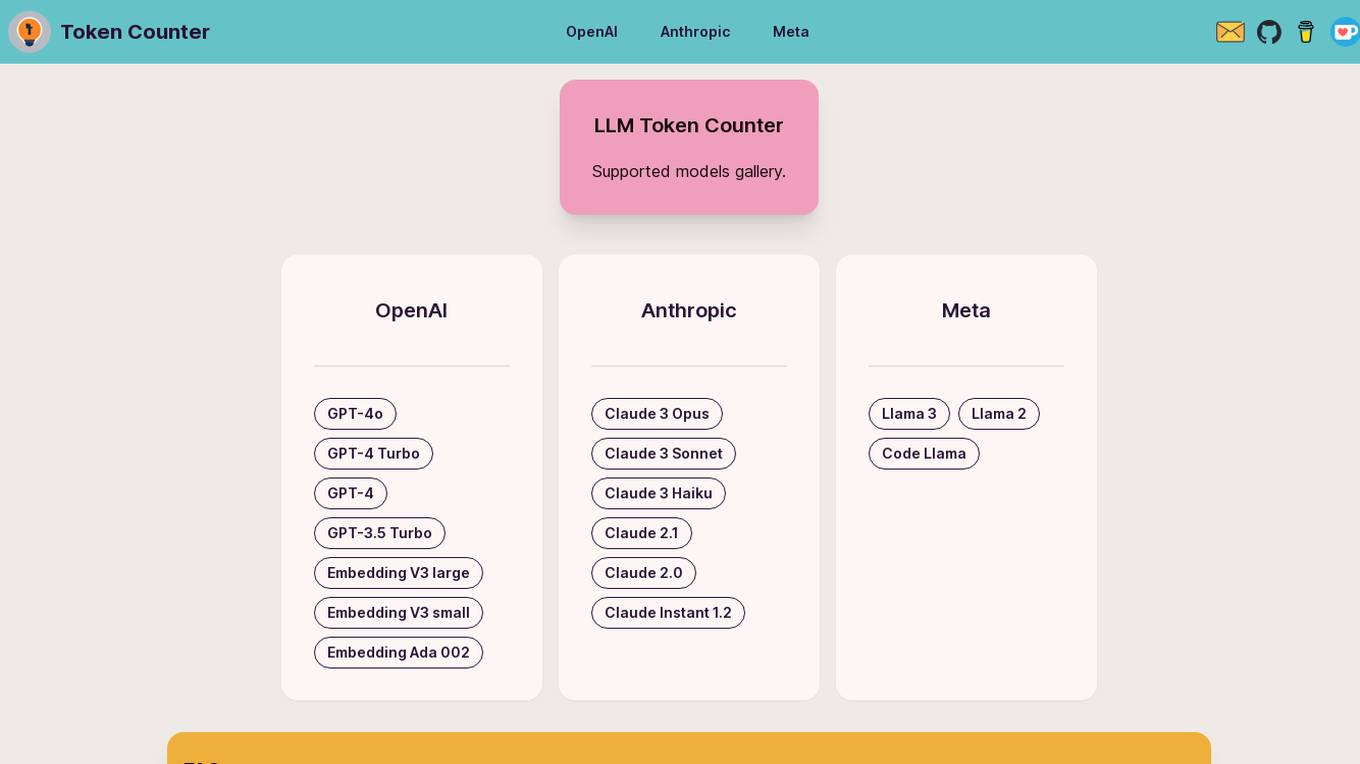
LLM Token Counter
The LLM Token Counter is a sophisticated tool designed to help users effectively manage token limits for various Language Models (LLMs) like GPT-3.5, GPT-4, Claude-3, Llama-3, and more. It utilizes Transformers.js, a JavaScript implementation of the Hugging Face Transformers library, to calculate token counts client-side. The tool ensures data privacy by not transmitting prompts to external servers.
GPT Calculator
GPT Calculator is a free tool that helps you calculate the token count and cost of your GPT prompts. You can also use the API to integrate the calculator into your own applications. GPT Calculator is a valuable tool for anyone who uses GPT-3 or other large language models.
NTM.ai
NTM.ai is an AI-powered platform that provides tools and services for the cryptocurrency market. It offers features such as presales contract scanning, project listing, price tracking, and market analysis. The platform aims to assist users in making informed decisions and maximizing their investments in the volatile crypto market.

Sopdap Technologies
Sopdap Technologies is a leading provider of Web3, AI, and Cybersecurity services. They specialize in Blockchain Technologies, Smart Contracts Creation and Auditing, KYC, Cybersecurity Services, Project Management, and AI Automation. The company offers customized solutions tailored to meet the specific needs of businesses, timely delivery, ongoing support, and maintenance. Their core service areas include Web3 Project Development, Cybersecurity Solutions, AI Solutions, Cloud Security and Infrastructure, and Data Privacy and Compliance Services.

RejuveAI
RejuveAI is a decentralized token-based system that aims to democratize longevity globally. The Longevity App allows users to monitor essential health metrics, enhance lifespan, and earn RJV tokens. The application leverages revolutionary AI technology to analyze human body functions in-depth, providing insights for aging combat. RejuveAI collaborates with researchers, clinics, and data enthusiasts to ensure innovative outcomes are affordable and accessible. The platform also offers exclusive discounts on travel, supplements, medical tests, and longevity therapies.

VABOT
VABOT is an ecosystem of advanced, AI-powered enterprise and consumer-facing solutions integrating blockchain and artificial intelligence to improve users' daily lives and preserve time. It offers tailored virtual assistant bots for various industries like hospitality, retail, travel, health, and finance. The $VABT token serves as the native currency for VABOT, enabling subscriptions, staking, and rewards within the ecosystem. VABOT ensures data security with advanced encryption protocols and offers a roadmap for future development.
Supermaven
Supermaven is a free AI code completion tool designed to help developers write code faster by providing contextual suggestions and code completions. It offers a 1 million token context window, fast and high-quality code suggestions, and compatibility with popular code editors like VS Code, JetBrains IDEs, and Neovim. Supermaven also features a chat interface for developers to interact with AI models like GPT-4 and Claude 3.5 Sonnet, enabling quick code diffs, changes, and conversations. The tool is trusted by engineers for its speed, efficiency, and real-time code assistance.
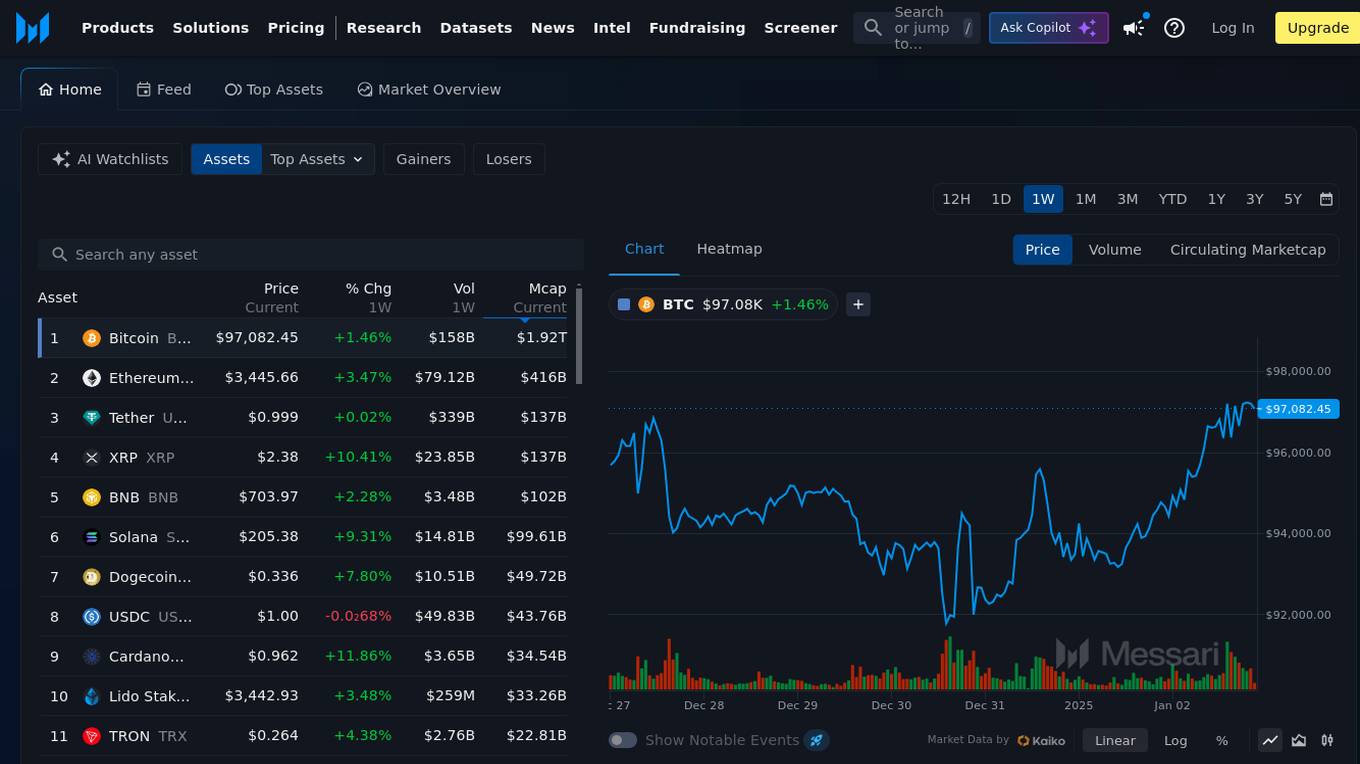
Messari
Messari is an AI-powered platform that provides comprehensive crypto research, reports, AI news, live prices, token unlocks, and fundraising data. It offers a wide range of tools for users to explore and analyze the cryptocurrency market. With features like AI summaries, personalized watchlists, comparative charts, and AI recaps, Messari aims to organize and contextualize all crypto information at a global scale.

GPTSidekick
GPTSidekick is an affordable GPT-4 powered AI assistant that can help you with a variety of tasks, including writing, coding, research, and more. It is easy to use and can be accessed from any device with an internet connection.
Laika AI
Laika AI is the world's first Web3-modeled AI ecosystem, designed and optimized for Web3 and blockchain. It offers advanced on-chain AI tools, integrating artificial intelligence and blockchain data to provide users with insights into the crypto landscape. Laika AI stands out with its user-friendly browser extension that empowers users with advanced on-chain analytics without the need for complex setups. The platform continuously learns and improves, leveraging a unique foundation and proprietary algorithms dedicated to Web3. Laika AI offers features such as DeFi research, token contract analysis, wallet insights, AI alerts, and multichain swap capabilities. It is supported by strategic partnerships with leading companies in the Web3 and Web2 space, ensuring security, high performance, and accessibility for users.
ChatX
ChatX is a free prompt marketplace that offers ChatGPT, DALL·E, Stable Diffusion, and Midjourney AI tools. It provides a platform for users to easily find generative AI prompts for their projects, helping to enhance creativity and productivity. The marketplace also offers a variety of AI-inspired gifts and products for individuals passionate about AI.
CHAPTR
CHAPTR is an innovative AI solutions provider that aims to redefine work and fuel human innovation. They offer AI-driven solutions tailored to empower, innovate, and transform work processes. Their products are designed to enhance efficiency, foster creativity, and anticipate change in the modern workforce. CHAPTR's solutions are user-centric, secure, customizable, and backed by the Holtzbrinck Publishing Group. They are committed to relentless innovation and continuous advancement in AI technology.

Deckee.AI
Deckee.AI is an AI-powered platform that allows users to instantly build blockchain websites and tokens. With Deckee.AI, users can create customized webpages for blogging, consulting, digital creation, and more. Deckee.AI also provides powerful editing tools, domain and SSL, separate hosting options, and the ability to choose the exact layout users want. Additionally, Deckee.AI makes it easy to create professional designs and digital collections, as well as unique digital tokens as a representation of products, events, rewards, and more.

Tensordyne
Tensordyne is a generative AI inference compute tool designed and developed in the US and Germany. It focuses on re-engineering AI math and defining AI inference to run the biggest AI models for thousands of users at a fraction of the rack count, power, and cost. Tensordyne offers custom silicon and systems built on the Zeroth Scaling Law, enabling breakthroughs in AI technology.

Basis Theory
Basis Theory is a token orchestration platform that helps businesses route transactions through multiple payment service providers (PSPs) and partners, enabling seamless subscription payments while maintaining PCI compliance. The platform offers secure and transparent payment flows, allowing users to connect to any partner or platform, collect and store card data securely, and customize payment strategies for various use cases. Basis Theory empowers high-risk merchants, subscription platforms, marketplaces, fintechs, and other businesses to optimize their payment processes and enhance customer experiences.
FACE AI
FACE AI is a pioneering token project that combines blockchain technology and artificial intelligence to revolutionize video production. It offers a suite of AI-powered tools that enable users to create high-quality videos with ease, including text-to-video, image-to-video, face singing, and dance image generation.
MagicVest
MagicVest is an AI-powered crypto intelligence tool that predicts profitable token movements before they happen and warns users about potential scams. It scans real-time signals across exchanges, social media, and smart contracts to provide high-accuracy signals. With features like MagicRadar, MagicDip, and MagicScore, MagicVest helps users make informed decisions in the volatile memecoin market.
DeepSeek v3
DeepSeek v3 is an advanced AI language model that represents a major breakthrough in AI language models. It features a groundbreaking Mixture-of-Experts (MoE) architecture with 671B total parameters, delivering state-of-the-art performance across various benchmarks while maintaining efficient inference capabilities. DeepSeek v3 is pre-trained on 14.8 trillion high-quality tokens and excels in tasks such as text generation, code completion, and mathematical reasoning. With a 128K context window and advanced Multi-Token Prediction, DeepSeek v3 sets new standards in AI language modeling.
1 - Open Source AI Tools

PaddleNLP
PaddleNLP is an easy-to-use and high-performance NLP library. It aggregates high-quality pre-trained models in the industry and provides out-of-the-box development experience, covering a model library for multiple NLP scenarios with industry practice examples to meet developers' flexible customization needs.
20 - OpenAI Gpts

Token Securities Insights
A witty, crypto-savvy GPT for token securities insights, balancing humor and professionalism.
Token Analyst
ERC20 analyst focusing on mintability, holders, LP tokens, and risks, with clear, conversational explanations.
STO Advisor Pro
Advisor on Security Token Offerings, providing insights without financial advice. Powered by Magic Circle

Dungeon Master Assistant
Enhance D&D campaigns with Roll20 setup and custom token creation.

STO Platform
This GPT, combined into the 'STO-Platform', is designed to share expertise in total token offering (STO).㉿㉿

TokenGPT
Guides users through creating Solana tokens from scratch with detailed explanations.

XRPL GPT
Build on the XRP Ledger with assistance from this GPT trained on extensive documentation and code samples.
ChainBot
The assistant launched by ChainBot.io can help you analyze EVM transactions, providing blockchain and crypto info.
Ethereum Blockchain Data (Etherscan)
Real-time Ethereum Blockchain Data & Insights (with Etherscan.io)

Airdrop Hunter
Specialist in cryptocurrency airdrops, providing info and claiming assistance.

Creative Prompt Tokens Explorer
From @cure4hayley - A comprehensive exploration of words and phrases. Includes composite word fusion and emotion-focused. Can also try film, TV and book titles. Enjoy!
Sugma Discrete Math Solver
Powered by GPT-4 Turbo. 128,000 Tokens. Knowledge base of Discrete Math concepts, proofs and terminology. This GPT is instructed to carefully read and understand the prompt, plan a strategy to solve the problem, and write formal mathematical proofs.
Monster Battle - RPG Game
Train monsters, travel the world, earn Arena Tokens and become the ultimate monster battling champion of earth!

Crypto Co-Pilot
Crypto Co-Pilot: Elevate Your Crypto Journey! 🚀 Get instant insights on trending tokens, uncover hidden gems, and access the latest crypto news. Your go-to chatbot for savvy trading and crypto discoveries. Let's navigate the crypto market together! 💎📈