Best AI tools for< Synthesize Sounds >
20 - AI tool Sites
SoundAI
SoundAI is an artificial intelligence-based instrumental web service that enables users to create and generate music samples, MIDI files, and presets for virtual synthesizers. The platform utilizes AI technology to assist musicians and composers in generating new melodies, exploring musical ideas, synthesizing sounds, modifying audio characteristics, and integrating with various projects. SoundAI aims to revolutionize the music industry by providing advanced AI technology for high-quality sound creation and real-time collaboration.
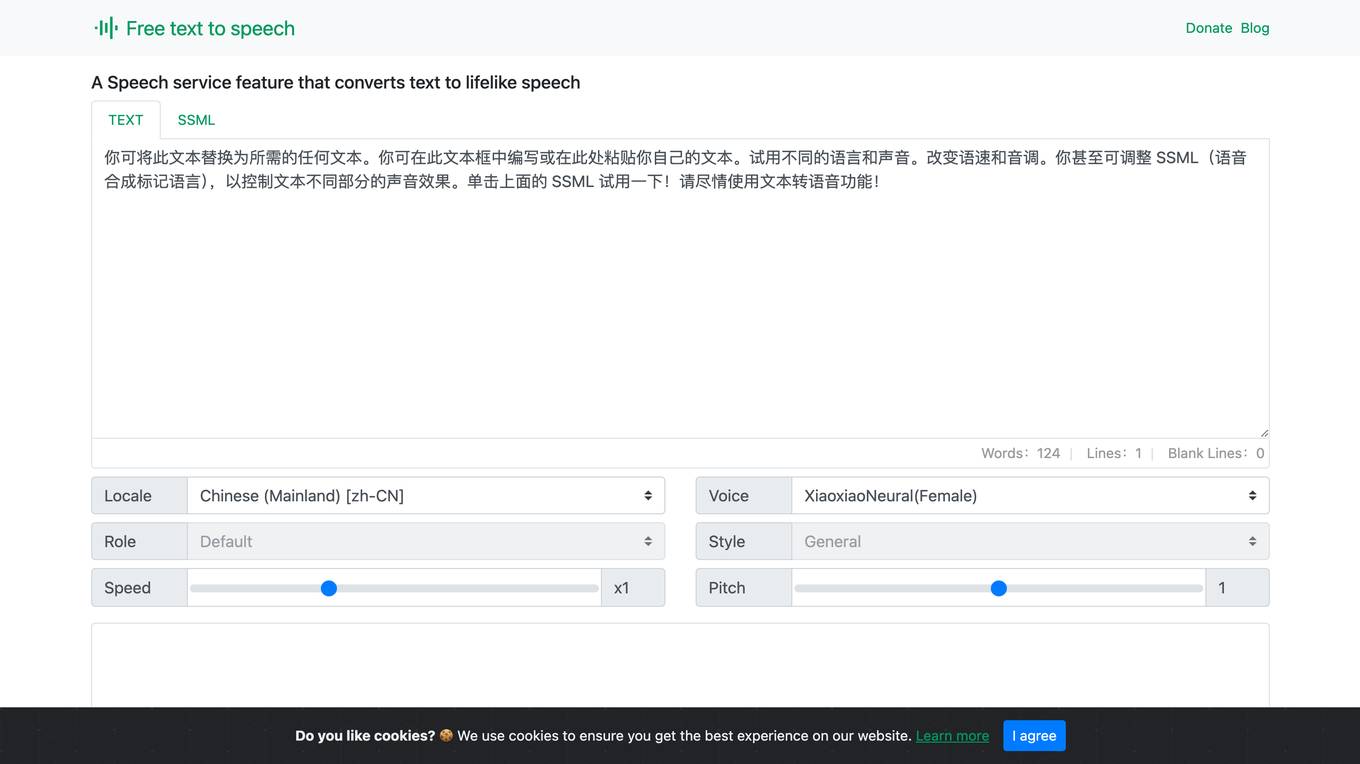
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
Revocalize AI
Revocalize AI is a studio-level AI voice generation and music tool that allows users to create studio-quality AI voices with human-level emotion in one click. The platform offers a range of features such as voice beautification, voice transformation, and real-time auto-pitch, enabling users to enhance their vocal performance and create unique voice models. With Revocalize AI, users can synthesize voices in multiple languages, adjust voice parameters, and generate vocal variations effortlessly. The application is trusted by award-winning creators and professionals and offers a collaborative platform for music enthusiasts to explore the unlimited potential of their voices.
Orb Plugins
Orb Plugins offers a suite of AI-powered music production tools designed for composers, producers, and DJs. Their flagship product, Orb Producer 3, assists users in generating chords, melodies, and rhythms, while Orb Synth X provides a state-of-the-art wavetable synthesizer. Orb Orchestra is tailored for composers, enabling them to experiment with new musical ideas and compose efficiently. The plugins are known for their user-friendly interface, seamless DAW integration, and ability to break creative blocks. Many professionals in the music industry use Orb Plugins to enhance their workflow and explore new sonic possibilities.
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
MMAudio
MMAudio is an AI-powered platform that specializes in transforming silent videos into immersive experiences with intelligent audio synthesis. The advanced AI technology analyzes video content to generate perfectly matched audio, creating professional soundtracks in minutes. MMAudio offers cutting-edge features for video audio generation, catering to various industries such as education, film production, game development, historical film enhancement, social media content, and storytelling. The platform provides seamless AI-powered video to audio transformation in three simple steps: uploading the video, advanced AI analysis, and intelligent audio generation. MMAudio stands out through its high-quality output, real-time processing capabilities, and extensive customization options.
Beat Shaper
Beat Shaper is a generative AI tool for musicians that helps them create beats, basslines, melodies, and VST synthesizer presets. It is designed to augment human creativity and help artists overcome writer's block. Beat Shaper is currently in beta testing, but you can apply for early access on their website.
PlayAI
PlayAI is a powerful AI voice generator and text-to-speech platform that offers a wide range of features to create natural-sounding voiceovers in multiple languages. With over 206 AI voices, users can generate audio content for various purposes such as audiobooks, YouTube videos, documentaries, and more. The platform also provides customization options like speech styles, pronunciations, and voice inflections to enhance the quality of generated voices. PlayAI's API integration allows seamless incorporation into different platforms, making it suitable for a wide range of applications from e-learning to gaming.
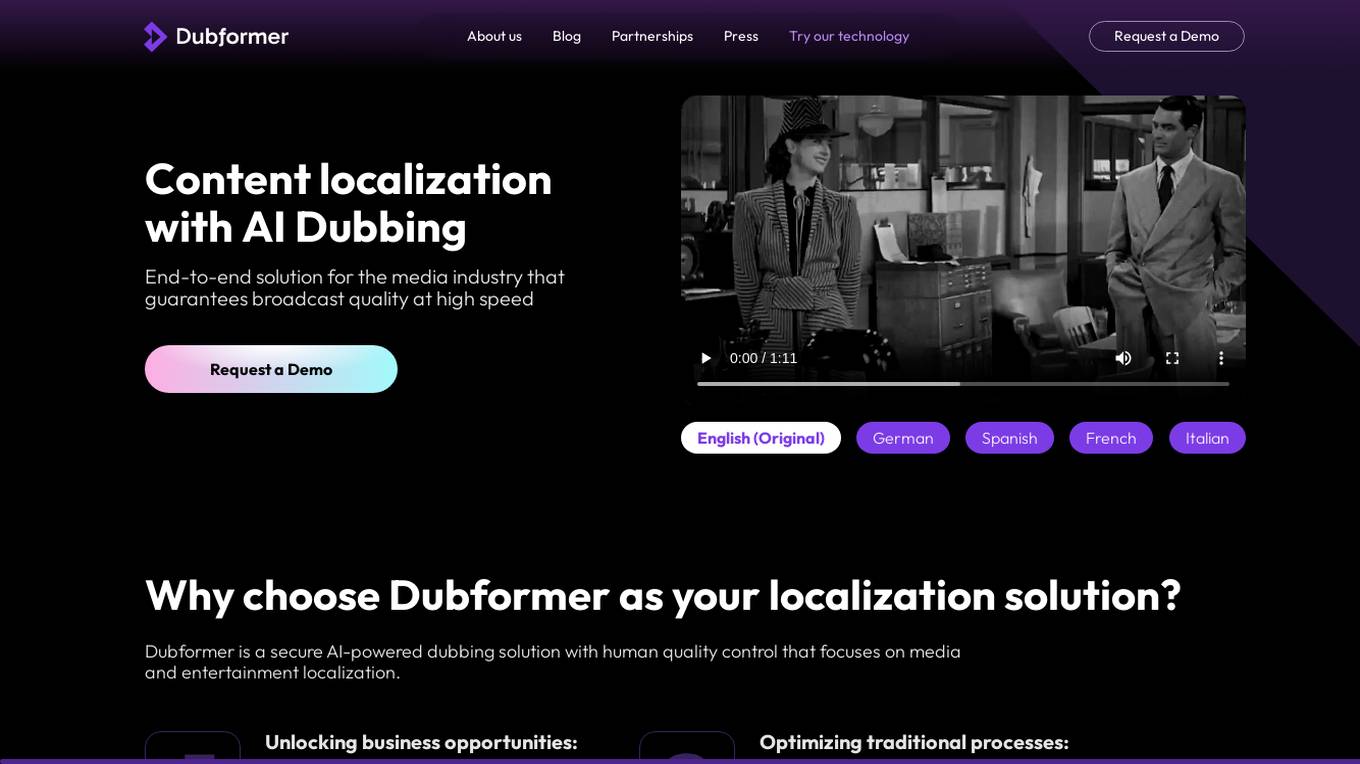
Dubformer
Dubformer is an AI-powered dubbing and video localization provider that offers a secure and end-to-end solution for the media industry. With a focus on quality and speed, Dubformer's technology enables the creation of realistic and natural-sounding voice-overs in multiple languages, making video content more accessible and engaging for diverse audiences. The platform combines AI-driven processes with human quality control to ensure broadcast-quality results. Dubformer's services include AI dubbing, accurate and culturally sensitive translations, AI mixing for immersive soundscapes, and AI-powered subtitles and closed captions.
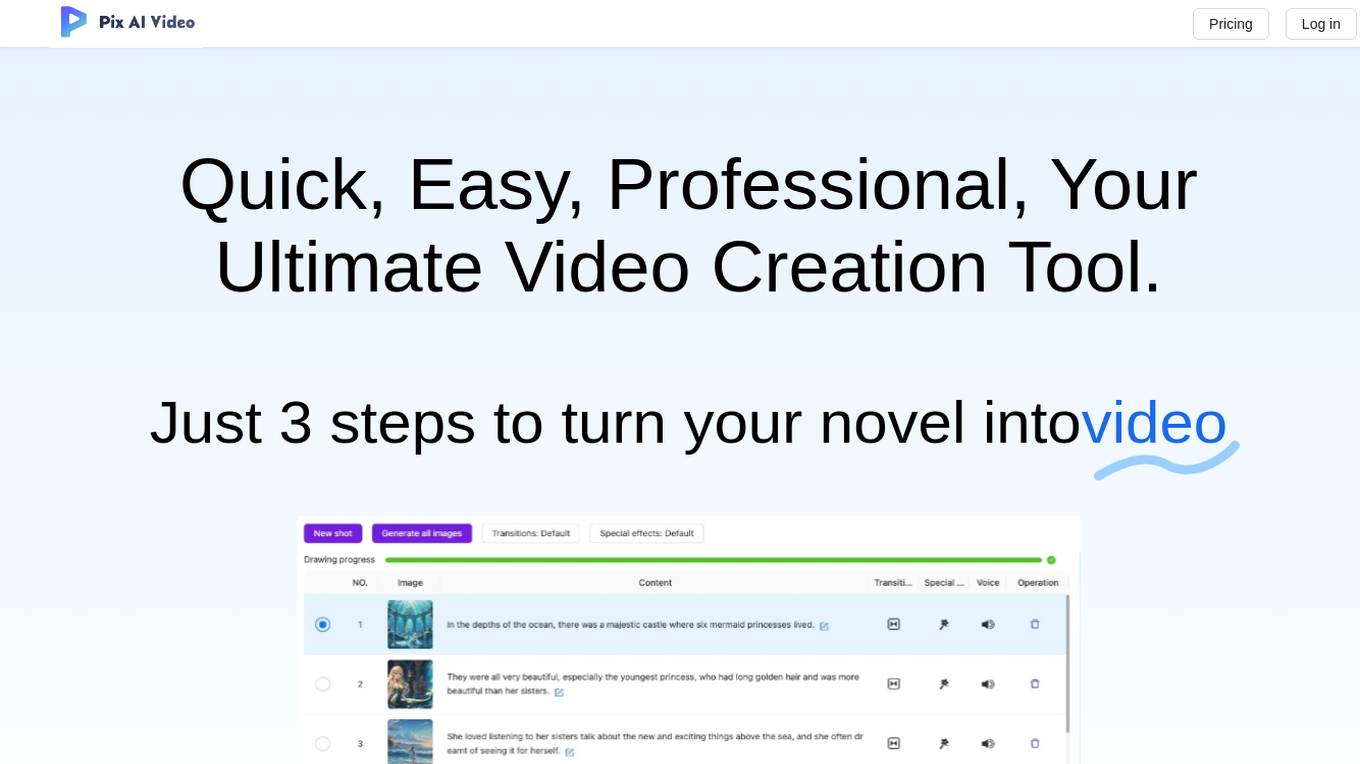
Pix Ai Video
Pix Ai Video is an AI-powered video editing tool that offers a range of features to enhance and customize your videos. With advanced algorithms, it provides automated editing options such as object removal, background replacement, and color correction. The tool is user-friendly and suitable for both beginners and professionals in the video editing field. Pix Ai Video simplifies the editing process and helps users create high-quality videos with ease.
Musico
Musico is an AI-driven software engine that generates music. It can react to gesture, movement, code, or other sound. Musico's engines blend traditional and modern machine learning algorithms to generate endless streams of copyright-free music in a wide variety of styles. Musico's generative approach empowers creators working with music with new ways of producing and applying sound that can adapt to its context in real time. From semi-assisted to fully automatic composition, our engines offer solutions for music pros as well as non-musicians.
Synthesis
Synthesis is a web-based application that allows users to create realistic-sounding synthetic speech from text. The application uses a variety of AI techniques, including natural language processing and machine learning, to generate speech that is both natural-sounding and easy to understand. Synthesis can be used for a variety of purposes, including creating voiceovers for videos, podcasts, and presentations.
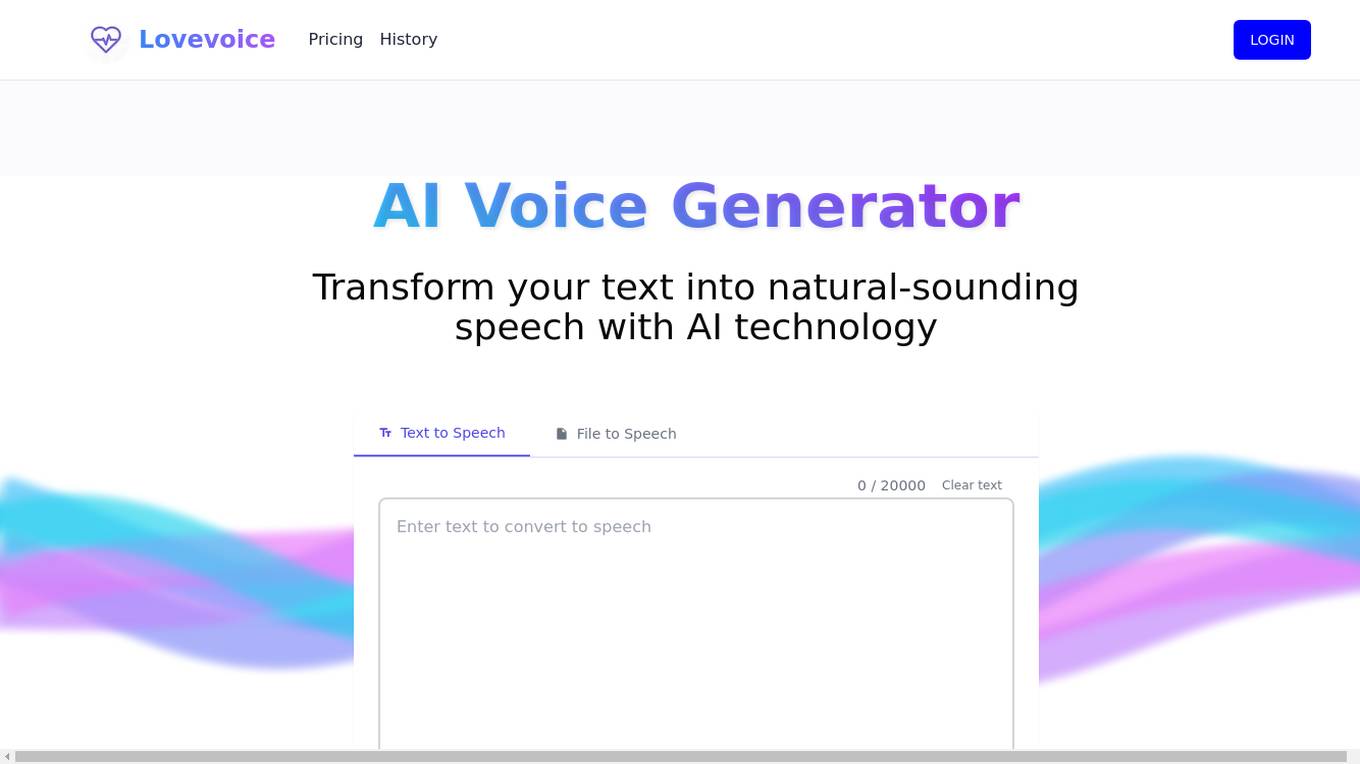
Lovevoice AI Voice Generator
Lovevoice is an AI Voice Generator that transforms text into natural-sounding speech using AI technology. It offers over 70 languages and nearly 300 AI voices, customizable voice settings, file transcription support, and MP3 download capabilities. Lovevoice's advanced AI ensures generated voiceovers are human-like, making it ideal for various applications such as videos, podcasts, audiobooks, and personalized audio messages. Users can quickly convert text into high-quality audio files with multilingual global support.
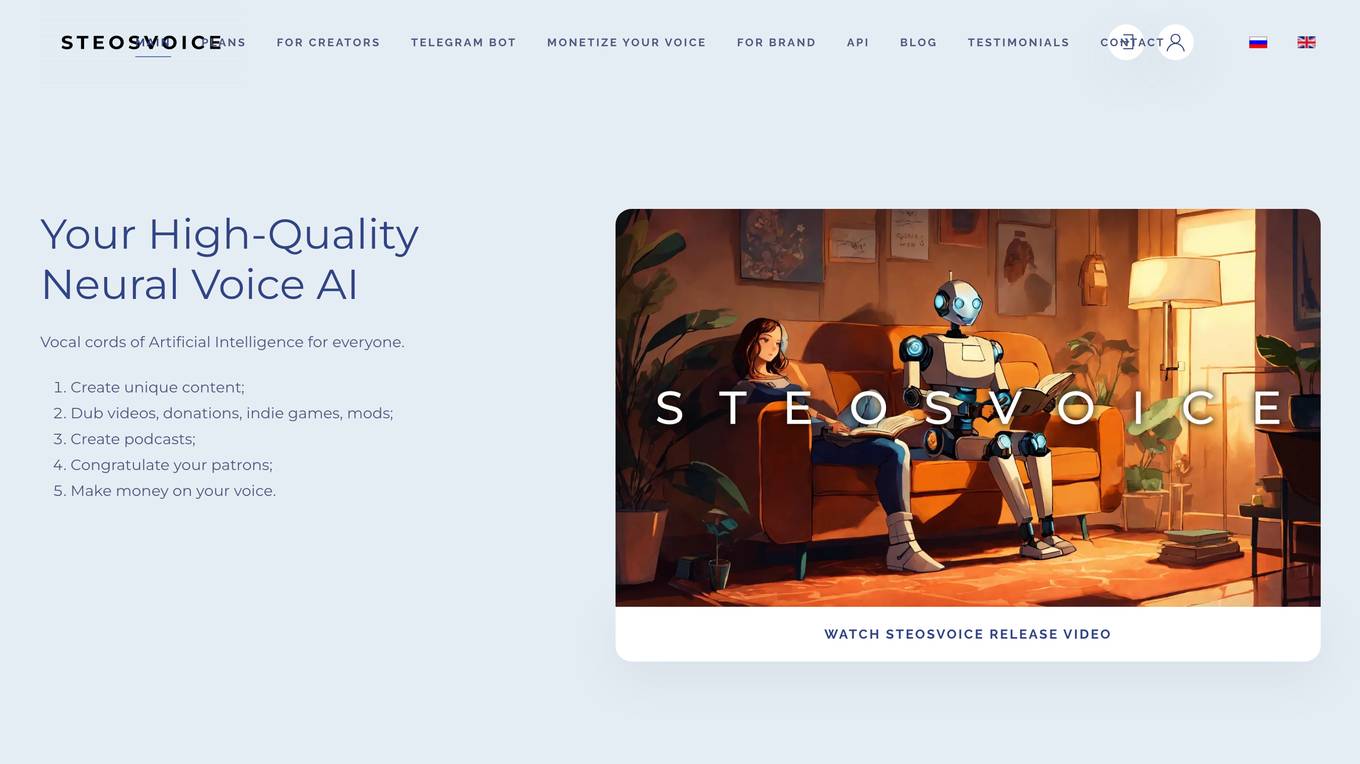
SteosVoice
SteosVoice (formerly CyberVoice) is an AI tool that provides high-quality neural voice AI for everyone. It offers a wide range of voices and speech synthesis technology to create unique content, dub videos, podcasts, and more. With over 800 voices and growing, SteosVoice is a leader in sound generation quality thanks to unique AI developments. The platform allows users to monetize their voice, license their voice for passive income, and offers a free Telegram bot for convenient access to voice synthesis. SteosVoice is used by YouTubers, businesses, media, indie game developers, and more for various voice-related tasks.
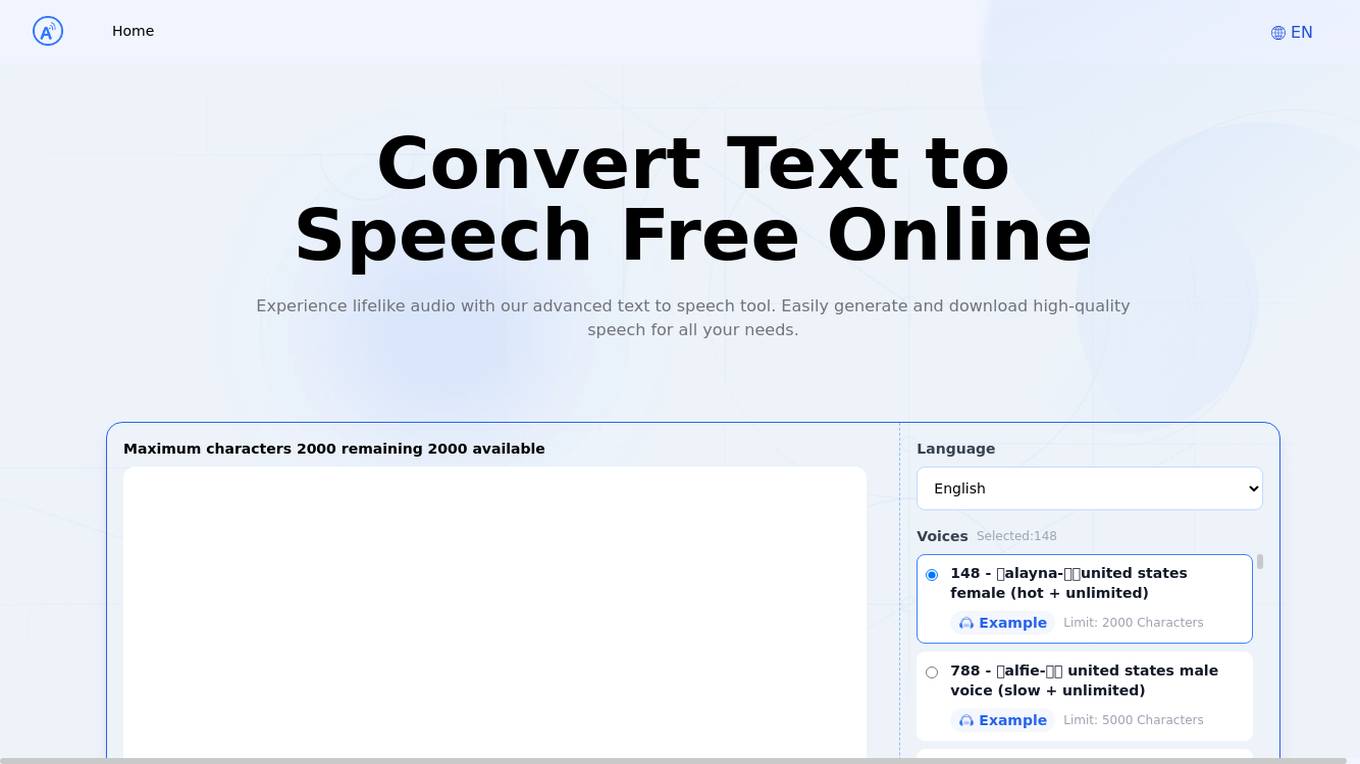
TEXTTOSPEECH.IM
TEXTTOSPEECH.IM is an advanced text to speech tool that utilizes artificial intelligence to convert text to lifelike audio. Users can easily generate and download high-quality speech in multiple languages and voice styles. The tool supports enhanced accessibility, cost-effective content creation, a wide range of voices, convenient offline use, high accuracy in speech synthesis, and cross-device compatibility for maximum flexibility.
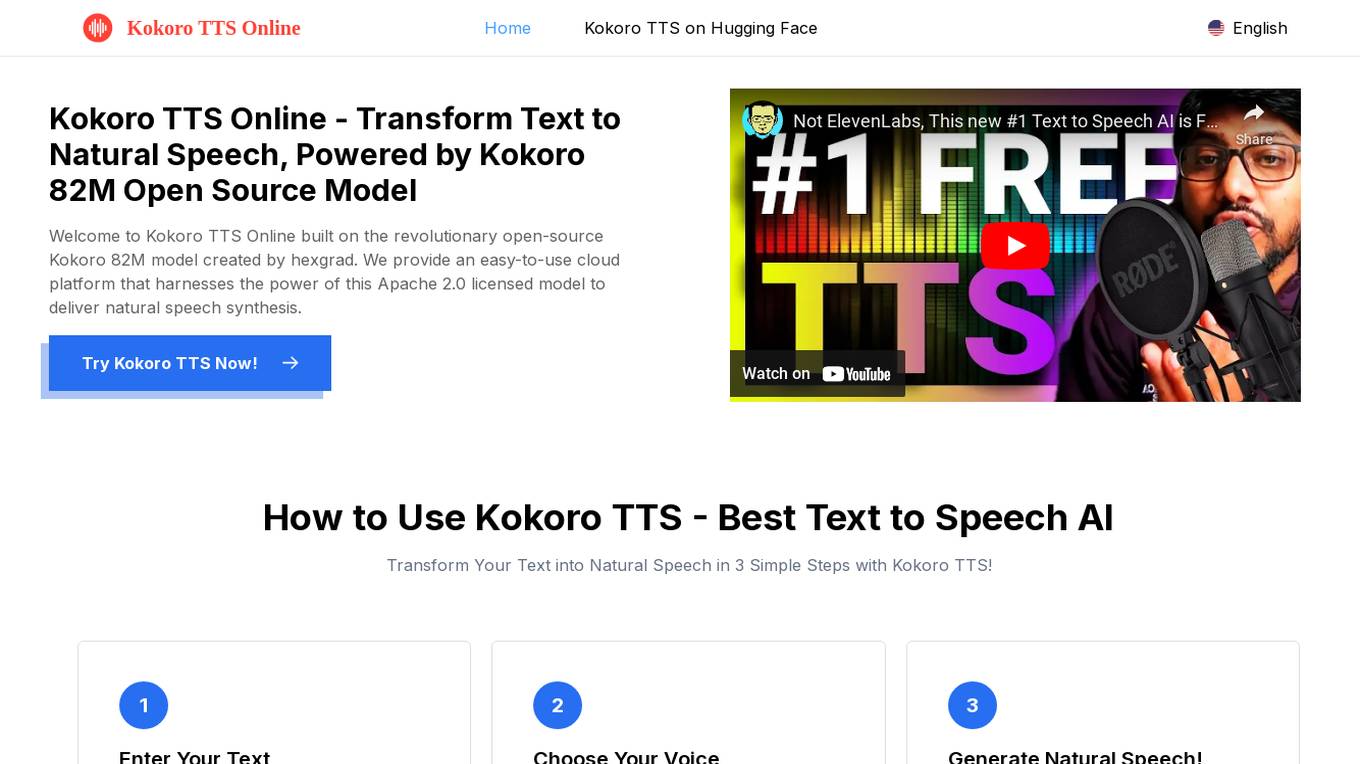
Kokoro TTS Online
Kokoro TTS Online is a professional cloud service powered by the Kokoro 82M open-source model. It offers text-to-speech conversion with natural speech synthesis using advanced AI technology. Users can transform text into natural-sounding speech in seconds, choose from multiple voices, and experience superior audio quality. Kokoro TTS is user-friendly, supports American and British English, and is suitable for various applications such as creating voiceovers, podcasts, and learning materials.
Audiobox
Audiobox is an AI tool developed by Meta for audio generation. It allows users to create custom audio content by generating voices and sound effects using voice inputs and natural language text prompts. The tool includes various models such as Audiobox Speech and Audiobox Sound, all built upon the shared self-supervised model Audiobox SSL. Audiobox aims to make AI safe and accessible for everyone by providing a platform for creative audio storytelling and research in the field of audio generation.
Nemesys Labs
Nemesys Labs is a free AI-powered text-to-speech platform that utilizes artificial intelligence technology to convert written text into spoken words. Users can easily generate high-quality audio files from any text input, making it a valuable tool for content creators, educators, and individuals seeking accessible content. The platform offers a user-friendly interface and a range of customization options to tailor the voice, tone, and speed of the generated speech. Nemesys Labs aims to enhance communication and accessibility by providing a seamless text-to-speech solution for various applications.
ACE Studio
ACE Studio is an AI Vocal Workstation that allows users to generate vocals from various professional AI vocalists by typing MIDI and lyrics. It simplifies the production of lead vocals, harmonies, backing vocals, and choirs. The platform features a next-generation AI Singing Synthesis Engine that aims to deliver natural and expressive vocal performances. Users can access over 41 AI pro-singers in English, Chinese, and Japanese for music production. ACE Studio offers tools for editing and controlling vocal emotions, converting dry vocals into MIDI clips, blending voices, and customizing AI voice models.
0 - Open Source AI Tools
20 - OpenAI Gpts
Synth Guide
Expert in guiding musicians on creating sounds with synthesizers like Serum, Massive, and more.
PANˈDÔRƏ
Pandora is a Posthuman Prompt Engineer powered by the MANNS engine. Surpass human creative limitations by synthesizing diverse knowledge, advanced pattern recognition, and algorithmic creativity


AstroLex
Expertly guides users to identify gaps in research by analyzing and summarizing academic papers.


AI Debate Synthesizer OPED
Game-like GPT in which five AIs dynamically debate a given "theme" and lead to a proposal-based conclusion.
Work Contribution Record Table Synthesizer
Guides in creating a Work Contribution Record Table.