Best AI tools for< Split Audio >
20 - AI tool Sites
Splitter.ai
Splitter.ai is an AI-driven audio processing platform developed by a Swedish research company. It offers advanced audio processing technologies, including stem separation/extraction, reverb removal, and direct YouTube splitting. The platform is designed to assist music producers, DJs, artists, forensics engineers, audio engineers, karaoke enthusiasts, police, scientists, and more in enhancing their audio processing tasks. Splitter.ai aims to provide high-quality services through AI-driven solutions to meet the diverse needs of its users.
Vozart AI Music & Lyrics Generator
Vozart.ai is an advanced AI music and lyrics generator platform that empowers users to create original music tracks, lyrics, voice clones, and more with the help of artificial intelligence technology. The platform offers a wide range of features, from music composition tools to vocal removal and stem splitting capabilities, making professional music production accessible to both beginners and experienced musicians. Vozart.ai revolutionizes the music creation process by providing a seamless and intuitive online experience, allowing users to generate high-quality, royalty-free music tracks in seconds.
SplitSong
SplitSong.com is an AI tool that allows users to split songs into individual instrument tracks using Artificial Intelligence. Created by @markdoppler_, the website offers a user-friendly platform where users can upload their songs or extract them from YouTube. Users can then download separate tracks for drums, instrumental, bass, and vocals, enabling them to remix or study music in a more detailed manner.
LALAL.AI
LALAL.AI is a next-generation vocal remover and music source separation service that offers fast, easy, and precise stem extraction. It allows users to remove vocals, instrumental tracks, drums, bass, guitar, and more without quality loss. The platform uses advanced AI technology to provide high-quality stem splitting based on transformer-based audio separation approach. Users can create custom voices, remove background noise, change voices, and separate lead and backing vocals with pinpoint accuracy. LALAL.AI offers various packages for individuals and businesses, with features like fast processing queue, batch upload, and stem download. The service supports a wide range of input/output formats for audio and video files.
Vocalremover.org
Vocalremover.org is a website that offers a tool to remove vocals from music tracks. Users can upload their audio files and the tool will process them to create a version with the vocals removed. The site aims to provide a simple and efficient solution for users looking to create karaoke tracks or instrumental versions of songs. Vocalremover.org ensures security by verifying user connections and requires enabling JavaScript and cookies for smooth operation.
Melody ML
Melody ML is an AI-powered music processing tool that allows users to separate music tracks using machine learning technology. Users can upload songs, and the tool uses AI algorithms to extract vocals, drums, bass, and other instruments into separate stems. Melody ML offers a user-friendly platform for music enthusiasts, producers, and artists to enhance their music production process.
Jamorphosia
Jamorphosia is an AI-powered application that allows users to remove instruments from a song. With advanced technology and audio separation capabilities, users can easily extract vocals, isolate specific instruments, and create custom backing tracks. The tool transforms audio files into personalized songs, suitable for practice or performance. Jamorphosia enhances the music experience by providing a platform for musicians to engage with original tracks in a more immersive way.
Gaudio Studio
Gaudio Studio is an AI music separation tool designed for creators to unleash their creativity with ease. It allows users to extract background music, separate instruments, and remove vocals from any music content. Powered by GSEP (Gaudio source SEParation), a high-quality and easy-to-use AI stem separation model, Gaudio Studio offers a seamless experience for audio separation. Users can upload their songs in various formats, access the tool from desktop or mobile devices, and enjoy Studio Plans for advanced processing. Additionally, Gaudio Studio can be integrated with cloud APIs and On-device SDKs for business applications, offering a versatile solution for music professionals and enthusiasts.
Music Demixer
Music Demixer is an AI-powered music transcription tool that converts audio recordings into professional sheet music, MIDI files, and stems with unmatched accuracy. It uses advanced AI stem separation technology to generate sheet music, MIDI files, or isolated instrument tracks. The platform is designed for musicians, composers, educators, and music enthusiasts looking to transcribe, analyze, and create music with studio-quality results.
MakeBestMusic
MakeBestMusic is an AI-powered music production suite that allows users to create unique music with just one click using advanced AI technology. The platform offers features such as creating instrumental and vocal music by providing simple descriptive words or lyrics, remixing music by uploading audio files and providing remix descriptions, and splitting music files to extract drums and vocals. MakeBestMusic provides a versatile approach to music creation, catering to both instrumental and vocal preferences with ease. Users can generate dynamic music, remix original audio files, and extract sounds from background music using the powerful AI music tool.
GenerateSongAI
GenerateSongAI is an advanced AI music production tool that revolutionizes the way music creators generate high-quality songs effortlessly. With GenerateSongAI, users can create fully produced songs with just a simple text description or lyrics, customize music styles, extract vocals and instruments, remix existing audio files, and share their music across social platforms. The platform offers a seamless and intuitive experience for music production, catering to a wide range of users from indie filmmakers to content creators, without the need for technical expertise. GenerateSongAI unlocks endless possibilities for creating songs, limited only by the user's imagination.
SecondSoul
SecondSoul is an AI platform that enables users to create their AI clone for engaging 24/7 conversations on Telegram. It allows users to customize their AI clone with unique traits, voice, and train it to mimic their style. The platform offers a straightforward pricing model with a revenue split, where creators earn 80% of the messages fee from users of their clone. SecondSoul aims to enhance user experience, provide companionship, and monetize community interactions through AI technology.
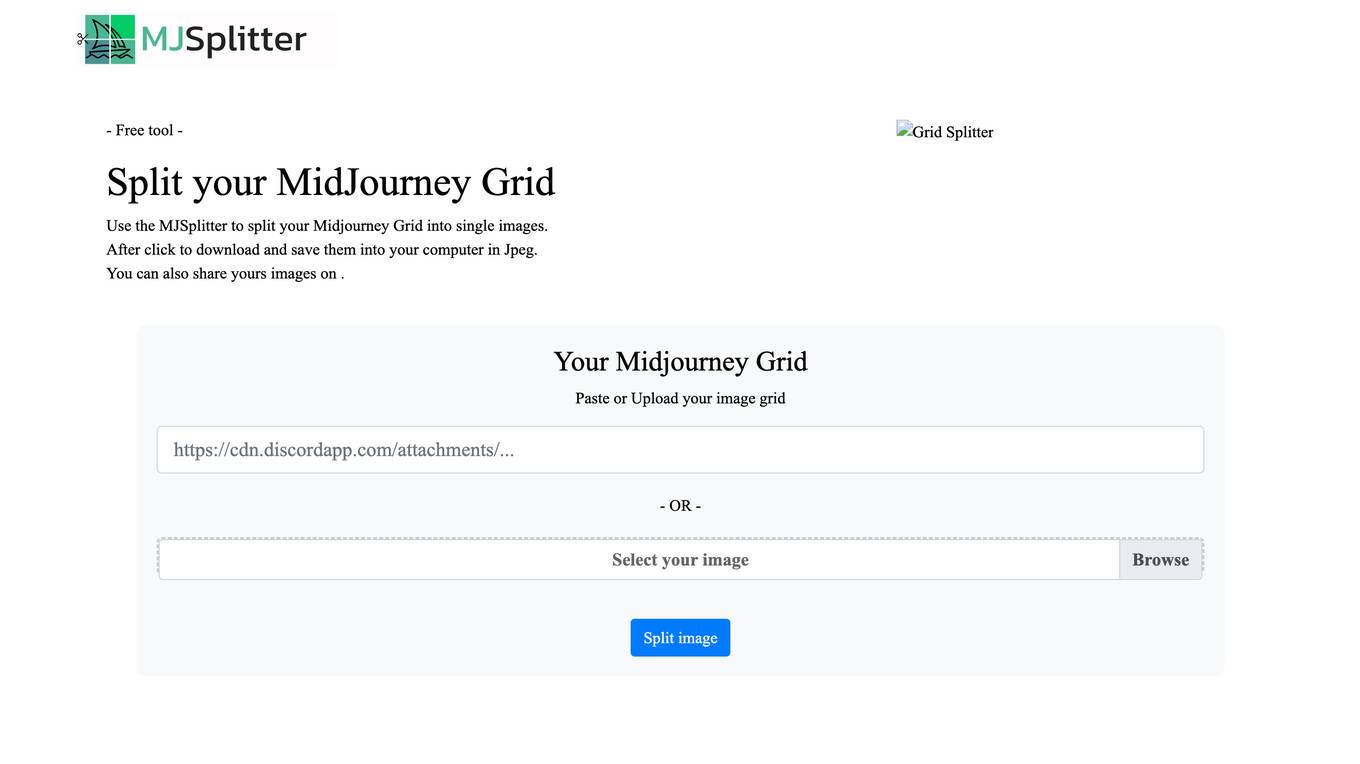
MJSplitter
MJSplitter is a free online tool that allows users to split their Midjourney Grid images into single images. Users can either paste or upload their image grid, and the tool will automatically split the images and save them as JPEGs. The tool is not affiliated with Midjourney, and images are deleted from the server after 24 hours.
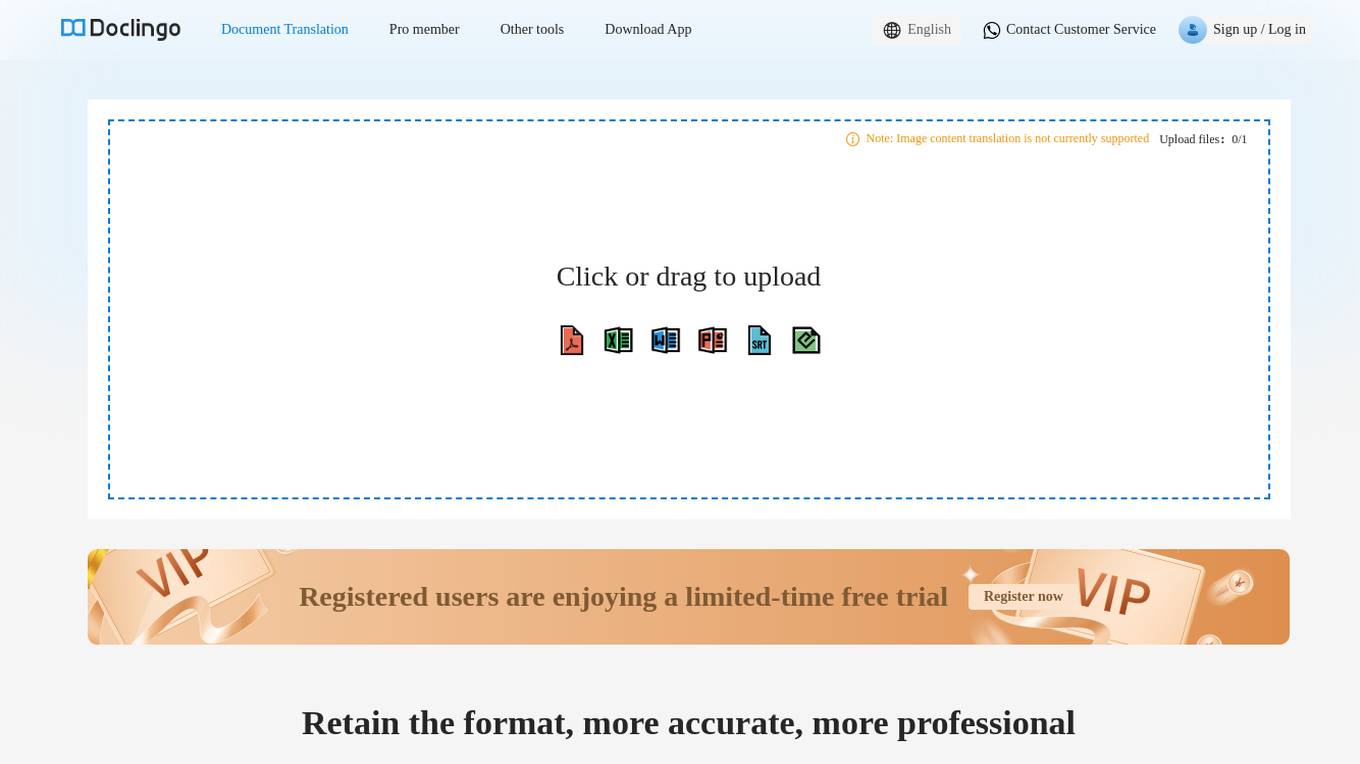
Doclingo
Doclingo is an AI-powered document translation tool that supports translating documents in various formats such as PDF, Word, Excel, PowerPoint, SRT subtitles, ePub ebooks, AR&ZIP packages, and more. It utilizes large language models to provide accurate and professional translations, preserving the original layout of the documents. Users can enjoy a limited-time free trial upon registration, with the option to subscribe for more features. Doclingo aims to offer high-quality translation services through continuous algorithm improvements.
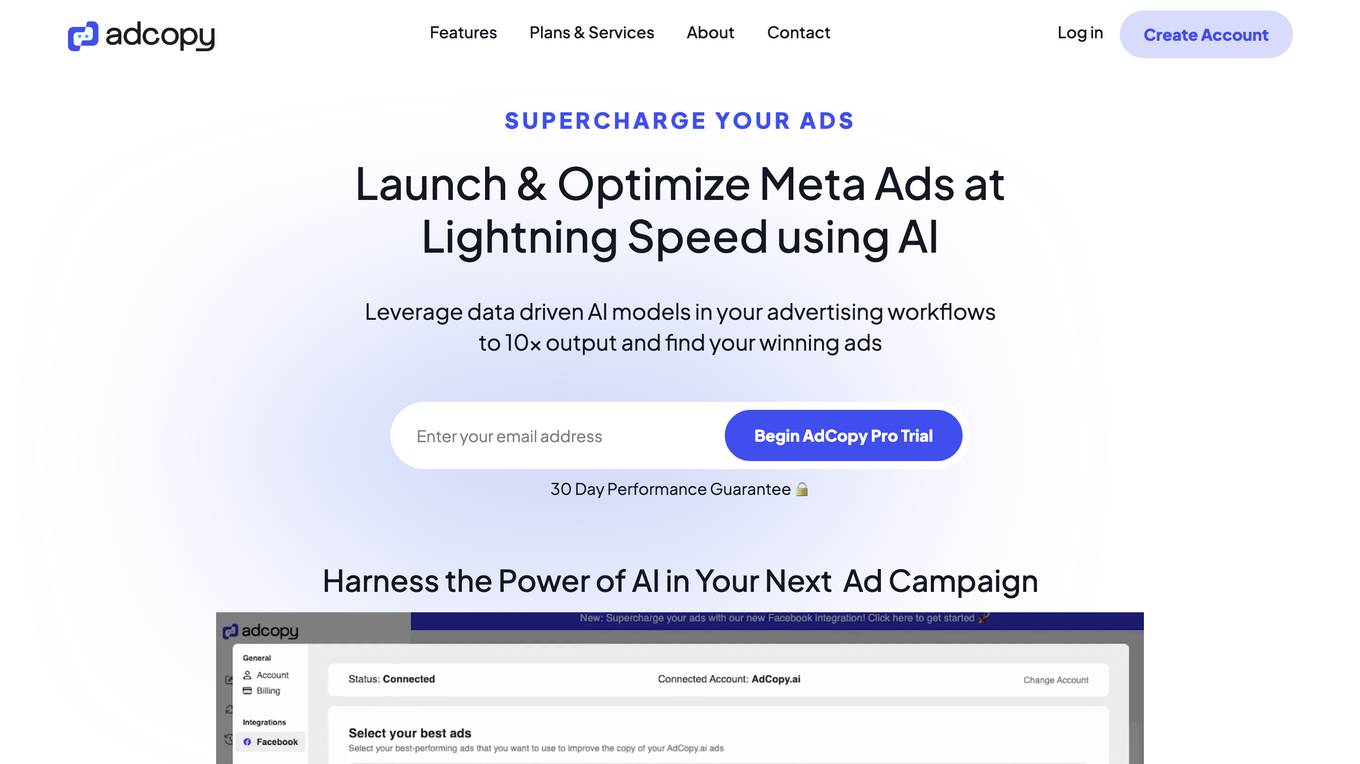
AdCopy
AdCopy is an AI-powered advertising platform that helps businesses create high-quality ads and optimize their ad campaigns. The platform uses AI to generate ad copy, create ad creatives, and provide insights into ad performance. AdCopy is designed to help businesses save time and money on their advertising campaigns, while also improving their results.
SplitMyExpenses
SplitMyExpenses is an AI-powered application designed to simplify shared expenses with friends. It allows users to create groups, split bills effortlessly, track debts, and settle up using integrated payment apps. The app offers modern design, AI receipt itemization, friend data powered by payment apps, and beautiful spending charts to help users manage their expenses efficiently. With over 150 supported currencies and secure handling of data, SplitMyExpenses revolutionizes the age-old problem of bill splitting, providing users with a stress-free experience.

SplitParty
SplitParty is an AI-powered application that simplifies the process of splitting complicated bills with friends. Users can easily split a bill by taking a photo of the receipt, allowing the AI to identify items, quantities, and prices. The application enables users to add friends, select items ordered, and split the bill effortlessly. SplitParty Plus offers additional features such as creating groups, saving bill history, and more. Developed by @dqnamo, SplitParty is a bootstrapped indie product designed to streamline bill-splitting experiences.
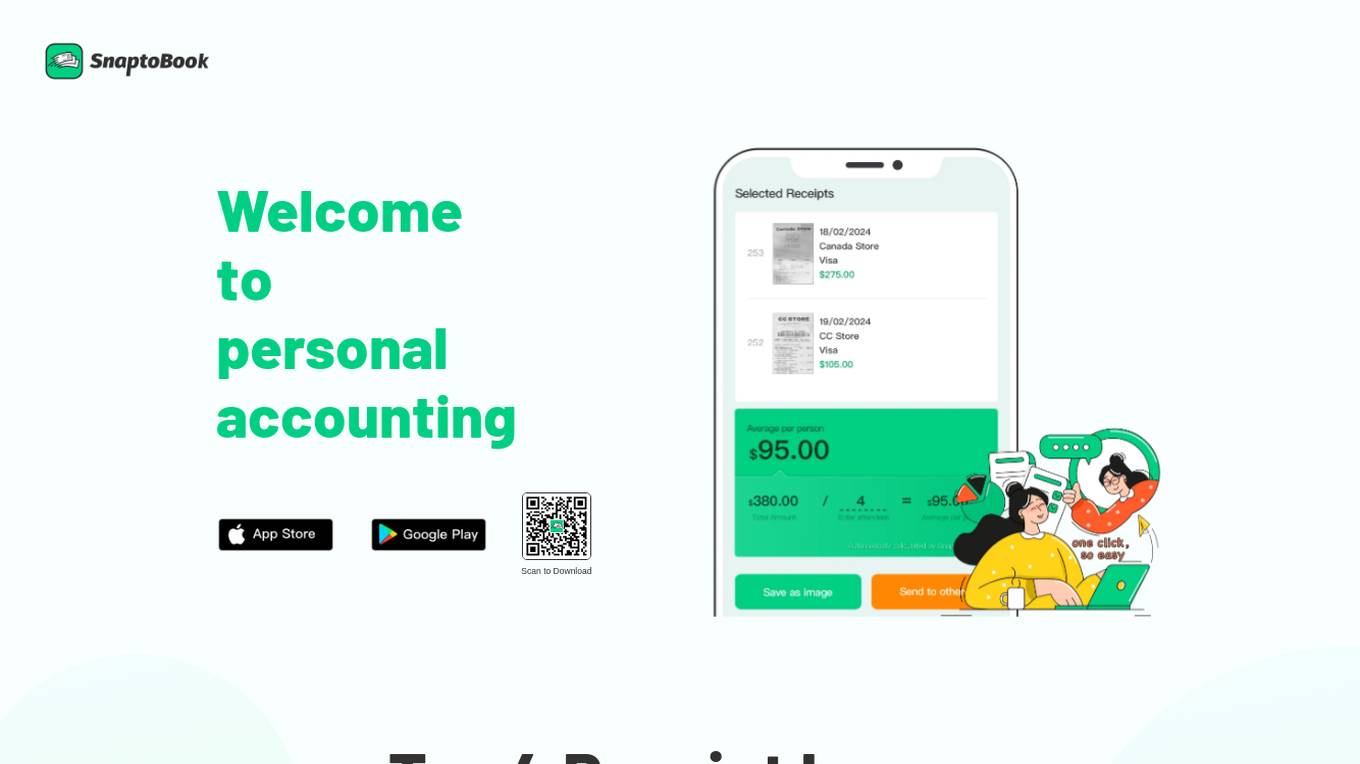
SnaptoBook
SanptoBook is a personal accounting software designed to help individuals manage their finances efficiently. It offers features such as invoice and receipt management, reimbursement facilitation, tax filing assistance, bill splitting, and project tracking. The application aims to simplify financial tasks and improve overall financial organization for users. With AI-powered efficiency, SnaptoBook provides state-of-the-art receipt recognition technology and secure cloud storage for all receipts.
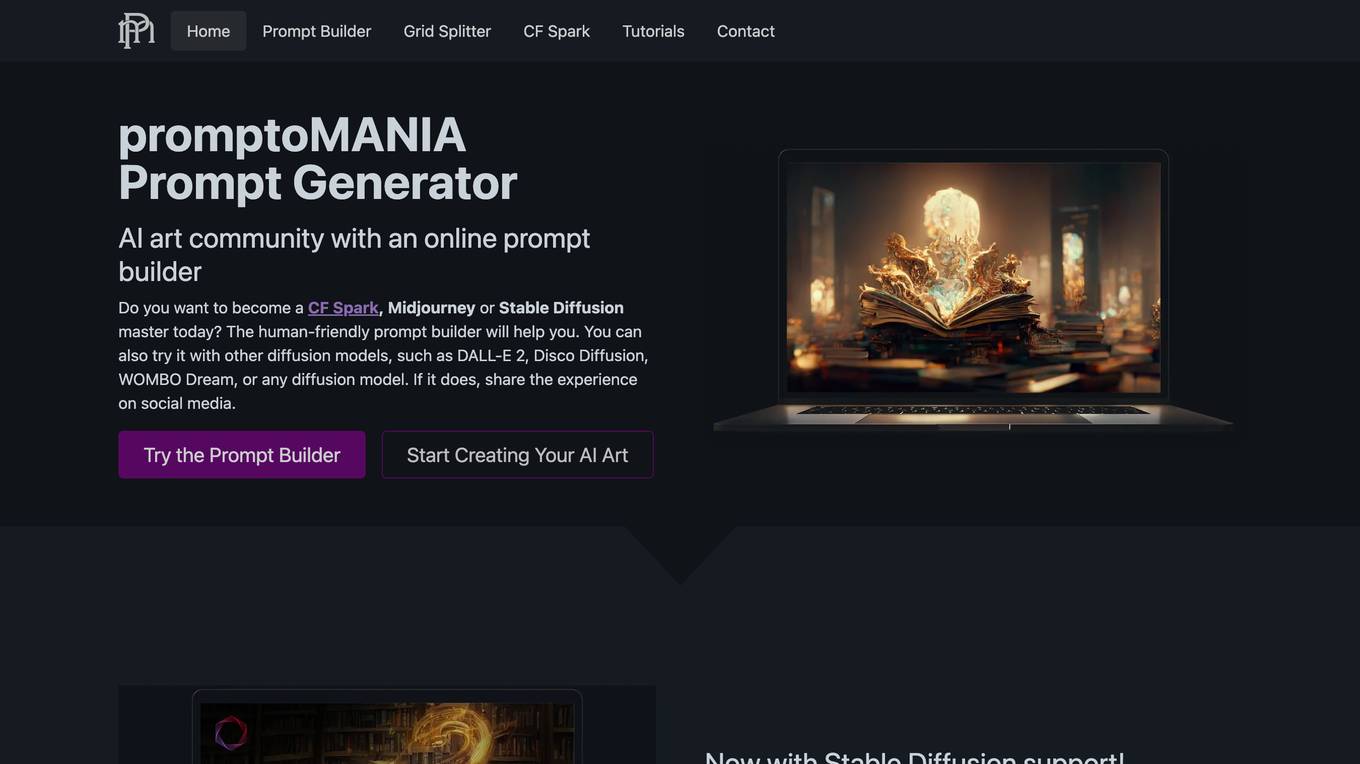
promptoMANIA
promptoMANIA is an AI art community and prompt generator that allows users to create AI images using various diffusion models like CF Spark, Midjourney, and Stable Diffusion. Users can generate high-quality and detailed AI art by providing prompts and selecting different styles and references. The platform offers a user-friendly prompt builder and tools like Grid Splitter to enhance the AI art creation experience. promptoMANIA is a free online tool with no subscription or sign-up required.
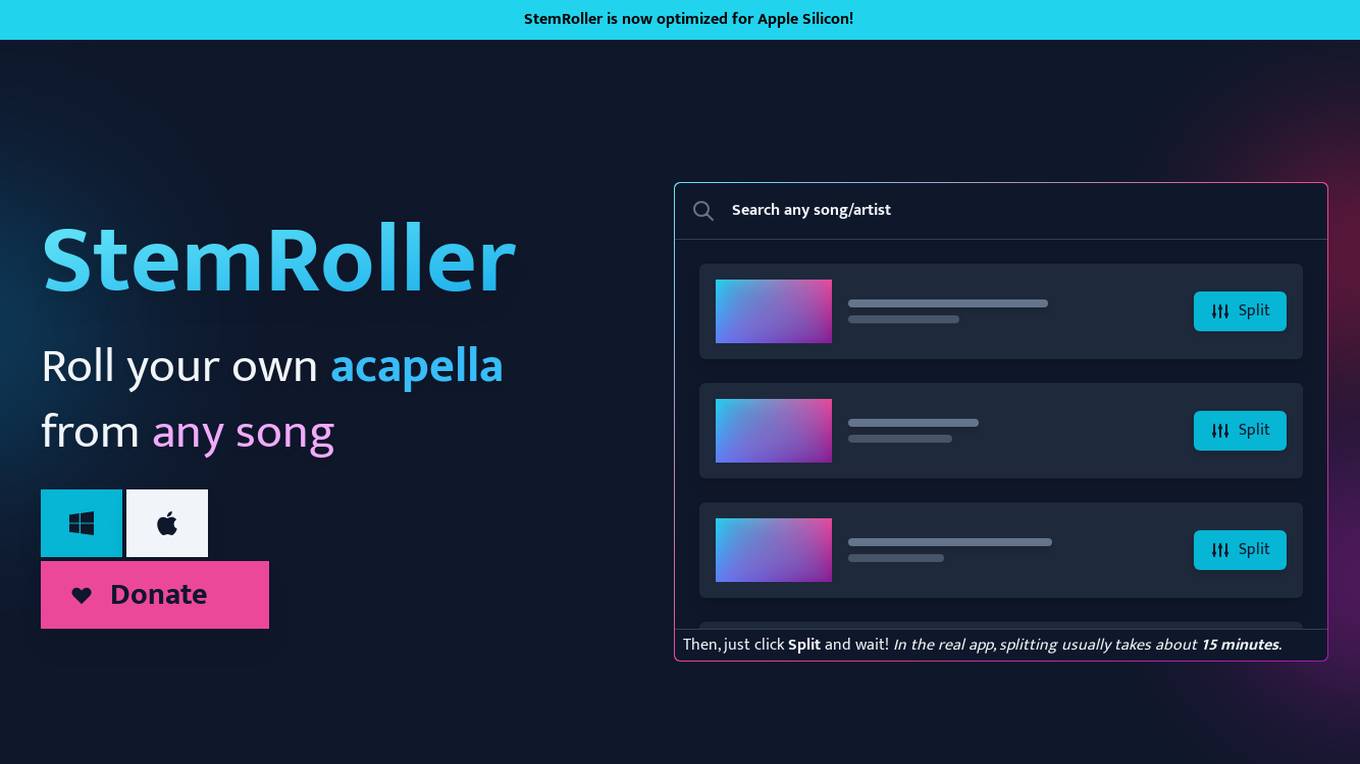
StemRoller
StemRoller is an AI-powered application that allows users to create stems, instrumental, or acapella versions of any song. Users can simply type the name of a song into the search bar, and StemRoller will find the song online and split it into vocals, drums, bass, and other stems. Additionally, an instrumental track is created with all non-vocal stems mixed down into one track. StemRoller is free and open-source, utilizing Facebook's advanced AI and machine learning research project Demucs. Users can also donate to support the app and receive assistance on Discord for any issues or questions.
1 - Open Source AI Tools
AI-Song-Cover-RVC
AI-Song-Cover-RVC is an all-in-one repository that provides tools for downloading YouTube WAV files, separating vocals, splitting audio, training models, and performing inference using Google Colab or Kaggle. The repository offers tutorials in Indonesian for training and inference tasks. Users can access various tools and resources for processing audio data and generating song covers. The repository aims to simplify the process of working with audio data for music-related projects.
7 - OpenAI Gpts
Split Screen Ad Engine
Simply Enter your Niche and we'll create your Split Screen Ads for you.
RFP Proposal Pro (IT / Software Sales assistant)
Step 1: Upload RFP Step 2: Prompt: I need a comprehensive summary of the RFP. Split the summary in multiple blocks / section. After giving me one section wait for my command to move to the next section. Step 3: Prompt: Move to the next section, please :)

Pace Assistant
Provides running splits for Strava Routes, accounting for distance and elevation changes