Best AI tools for< Scrape The Web >
20 - AI tool Sites
Cohesive
Cohesive is an AI tool designed to provide outsourced analysts and assistants for businesses. It enables users to prospect at scale, perform outbound activities with AI enrichment and web scraping directly within Google Sheets. The tool is Google Sheets native, allowing users to enrich and scrape the web without the need to import data into a separate platform. Cohesive also leverages AI for bulk data analysis, personalization generation, web scraping, and email finding/validation. It offers free usage with the option to join the Cohesive Slack community for additional support.
todai
todai is a personal branding assistant enhanced by AI that turbo-charges content creation and posting across social media channels. It helps users create a month's worth of content in less than 30 minutes, offering features like creating viral video clips, carousels, book reviews, and personalized views on any topic. With AI integration, todai provides unique content based on the user's professional profile, tone of voice, and writing style. It consolidates various content creation tools into one platform, enabling users to create visual and interactive personal branded content effortlessly.
Airtop
Airtop is a browser automation tool designed for AI agents, allowing users to automate web tasks using natural language commands. It offers inexpensive and scalable AI-powered cloud browsers, enabling effortless scraping and control of any website. Airtop simplifies the process of managing cloud browser infrastructure, freeing users to focus on their core business activities. The tool supports a wide range of use cases, including automating tasks that were previously challenging, such as interacting with sites behind logins and virtualizing the DOM.

UseScraper
UseScraper is a web crawler and scraper API that allows users to extract data from websites for research, analysis, and AI applications. It offers features such as full browser rendering, markdown conversion, and automatic proxies to prevent rate limiting. UseScraper is designed to be fast, easy to use, and cost-effective, with plans starting at $0 per month.
Exa
Exa is a web API designed to provide AI applications with powerful access to the web by organizing and retrieving the best content using embeddings. It offers features like semantic search, similarity search, content scraping, and powerful filters to help developers and companies gather and process data for AI training and analysis. Exa is trusted by thousands of developers and companies for its speed, quality, and ability to provide up-to-date information from various sources on the web.
Browse AI
Browse AI is a powerful AI-powered data extraction platform that allows users to scrape and monitor data from any website without the need for coding. With Browse AI, users can easily extract data, monitor websites for changes, turn websites into APIs, and integrate data with over 7,000 apps. The platform offers prebuilt robots for various use cases like e-commerce, real estate, recruitment, and more. Browse AI is trusted by over 740,000 users worldwide for its reliability, scalability, and ease of use.
MonkeeMath
MonkeeMath is an AI tool designed to scrape comments from Reddit and Stocktwits containing stock tickers. It utilizes ChatGPT to analyze the sentiment of these comments, determining whether they are bullish or bearish on the outlook of the ticker. The data collected is then used to generate charts and tables displayed on the website, providing insights into the sentiment surrounding various stocks.
AgentQL
AgentQL is an AI-powered tool for painless data extraction and web automation. It eliminates the need for fragile XPath or DOM selectors by using semantic selectors and natural language descriptions to find web elements reliably. With controlled output and deterministic behavior, AgentQL allows users to shape data exactly as needed. The tool offers features such as extracting data, filling forms automatically, and streamlining testing processes. It is designed to be user-friendly and efficient for developers and data engineers.
Web Transpose
Web Transpose is an AI-powered web scraping and web crawling API that allows users to transform any website into structured data. By utilizing artificial intelligence, Web Transpose can instantly build web scrapers for any website, enabling users to extract valuable information efficiently and accurately. The tool is designed for production use, offering low latency and effective proxy handling. Web Transpose learns the structure of the target website, reducing latency and preventing hallucinations commonly associated with traditional web scraping methods. Users can query any website like an API and build products quickly using the scraped data.
ScrapeComfort
ScrapeComfort is an AI-driven web scraping tool that offers an effortless and intuitive data mining solution. It leverages AI technology to extract data from websites without the need for complex coding or technical expertise. Users can easily input URLs, download data, set up extractors, and save extracted data for immediate use. The tool is designed to cater to various needs such as data analytics, market investigation, and lead acquisition, making it a versatile solution for businesses and individuals looking to streamline their data collection process.
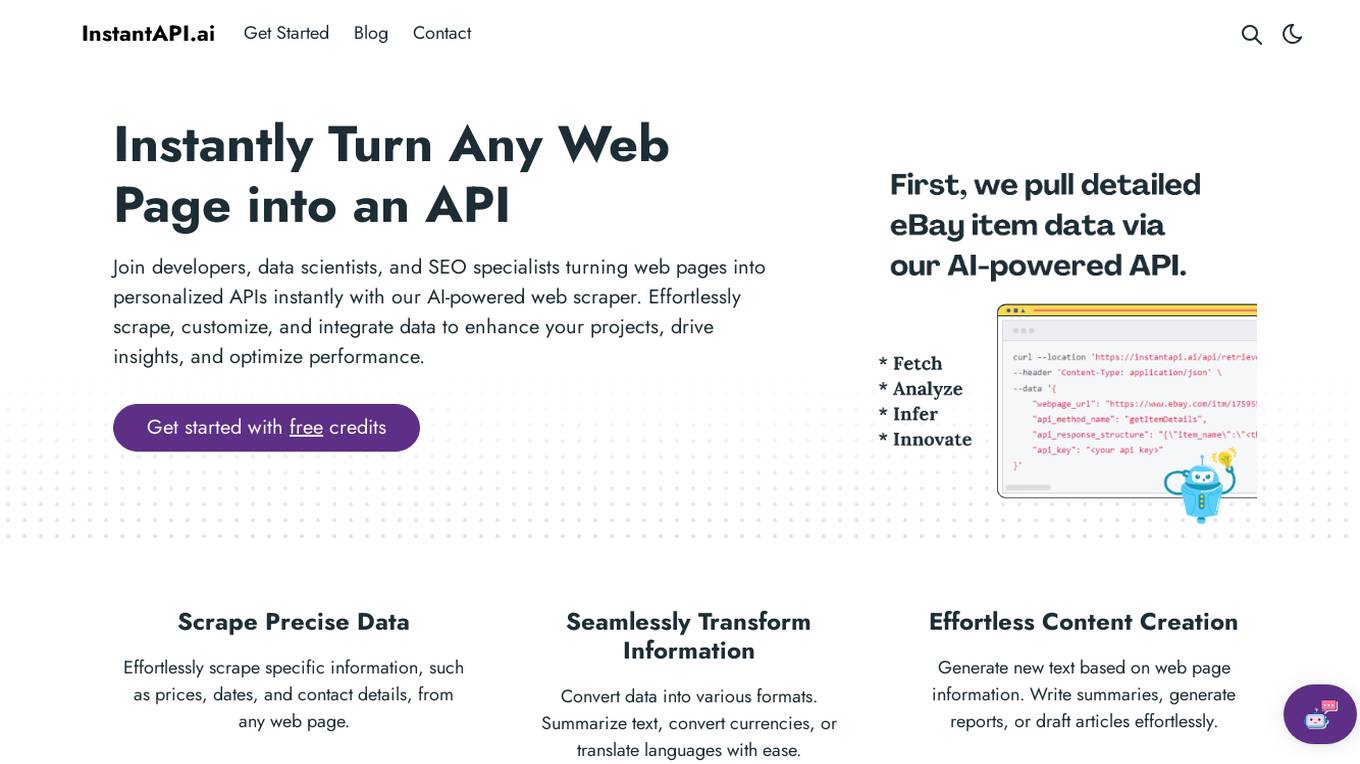
InstantAPI.ai
InstantAPI.ai is an AI-powered web scraping tool that allows developers, data scientists, and SEO specialists to instantly turn any web page into a personalized API. With the ability to effortlessly scrape, customize, and integrate data, users can enhance their projects, drive insights, and optimize performance. The tool offers features such as scraping precise data, transforming information into various formats, generating new content, providing advanced analysis, and extracting valuable insights from data. Users can tailor the output to meet specific needs and unleash creativity by using AI for unique purposes. InstantAPI.ai simplifies the process of web scraping and data manipulation, offering a seamless experience for users seeking to leverage AI technology for their projects.
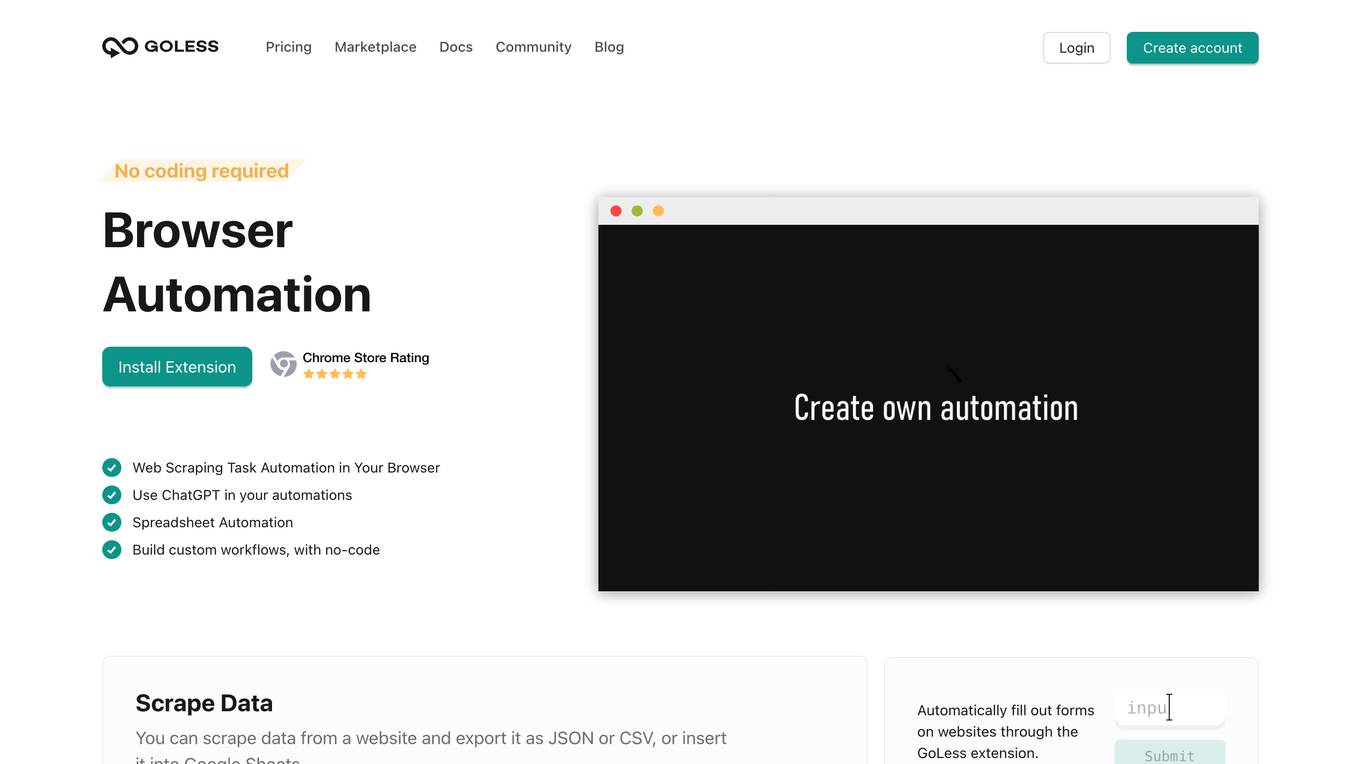
Goless
Goless is a browser automation tool that allows users to automate tasks on websites without the need for coding. It offers a range of features such as data scraping, form filling, CAPTCHA solving, and workflow automation. The tool is designed to be easy to use, with a drag-and-drop interface and a marketplace of ready-made workflows. Goless can be used to automate a variety of tasks, including data collection, data entry, website testing, and social media automation.
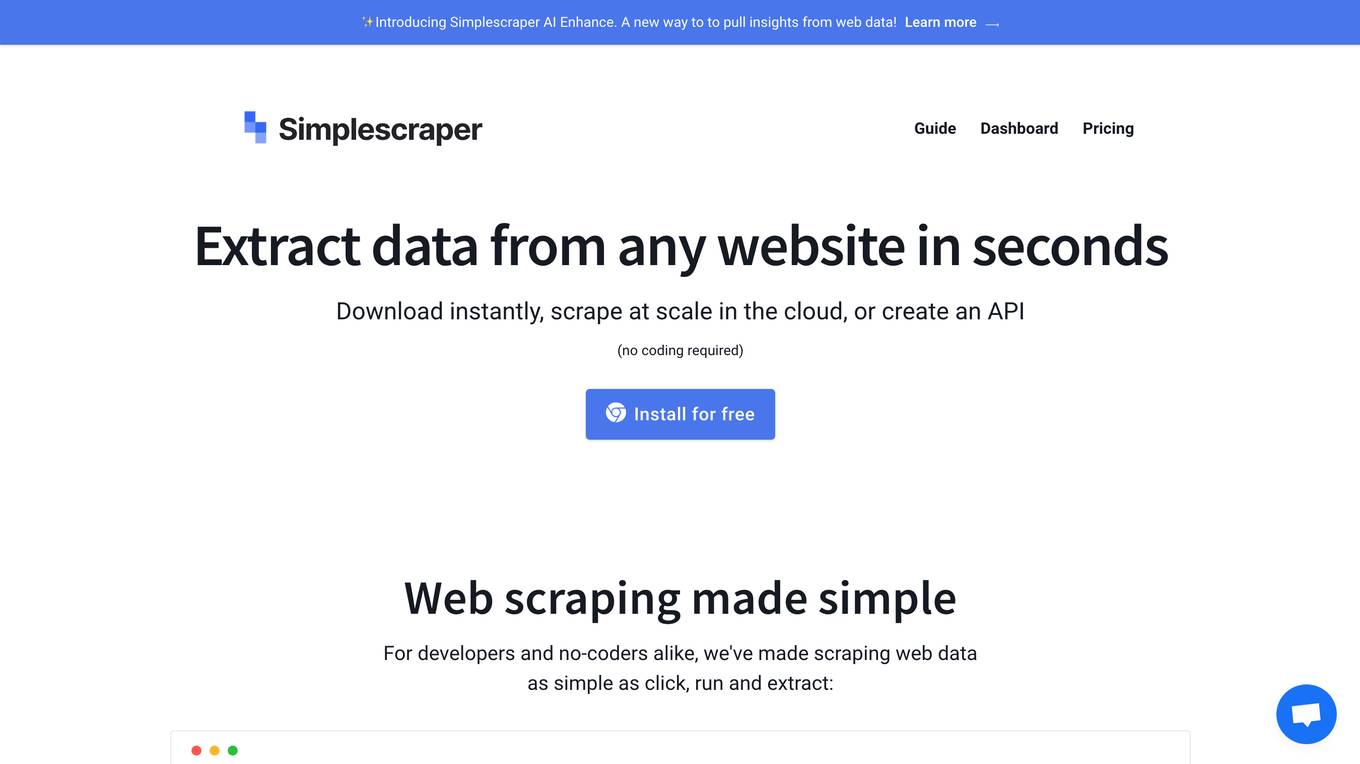
Simplescraper
Simplescraper is a web scraping tool that allows users to extract data from any website in seconds. It offers the ability to download data instantly, scrape at scale in the cloud, or create APIs without the need for coding. The tool is designed for developers and no-coders, making web scraping simple and efficient. Simplescraper AI Enhance provides a new way to pull insights from web data, allowing users to summarize, analyze, format, and understand extracted data using AI technology.
Awesome AI
Awesome AI is a practical directory of AI tools offering a wide range of AI applications for various purposes. With over 500 AI websites and tools, users can find solutions for tasks such as image caption generation, voice conversion, research paper drafting, adult entertainment, lead generation, video translation, chatbot creation, logo design, content generation, and more. The platform caters to global creators with multilingual support and aims to enhance user experiences through AI-powered solutions.
PromptLoop
PromptLoop is an AI-powered web scraping and data extraction platform that allows users to run AI automation tasks on lists of data with a simple file upload. It enables users to crawl company websites, categorize entities, and conduct research tasks at a fraction of the cost of other alternatives. By leveraging unique company data from spreadsheets, PromptLoop enables the creation of custom AI models tailored to specific needs, facilitating the extraction of valuable insights from complex information.
Extracto.bot
Extracto.bot is an AI web scraping tool that automates the process of extracting data from websites. It is a no-configuration, intelligent web scraper that allows users to collect data from any site using Google Sheets and AI technology. The tool is designed to be simple, instant, and intelligent, enabling users to save time and effort in collecting and organizing data for various purposes.
Apify
Apify is a full-stack web scraping and data extraction platform that offers a wide range of tools and services for developers to build, deploy, and publish web scrapers, AI agents, and automation tools. The platform provides pre-built web scraping tools, serverless programs, integrations with various apps and services, and AI agents equipped with Actors. Apify also offers solutions for building and monetizing MCP servers, as well as professional services for custom web scraping solutions. With a marketplace of over 6,000 Actors, Apify caters to a diverse range of use cases and industries, including generative AI, lead generation, market research, and sentiment analysis.
Firecrawl
Firecrawl is an advanced web crawling and data conversion tool designed to transform any website into clean, LLM-ready markdown. It automates the collection, cleaning, and formatting of web data, streamlining the preparation process for Large Language Model (LLM) applications. Firecrawl is best suited for business websites, documentation, and help centers, offering features like crawling all accessible subpages, handling dynamic content, converting data into well-formatted markdown, and more. It is built by LLM engineers for LLM engineers, providing clean data the way users want it.

Runner H
Runner H is an AI tool that enables users to create, run, and scale web automations effortlessly. It offers a platform for building super intelligence through VLMs, LLMs, and Agents API Beta. Users can join the API beta to access advanced features and functionalities. The tool aims to put AI to work for users, providing a seamless experience for automating tasks and processes.

OdiaGenAI
OdiaGenAI is a collaborative initiative focused on conducting research on Generative AI and Large Language Models (LLM) for the Odia Language. The project aims to leverage AI technology to develop Generative AI and LLM-based solutions for the overall development of Odisha and the Odia language through collaboration among Odia technologists. The initiative offers pre-trained models, codes, and datasets for non-commercial and research purposes, with a focus on building language models for Indic languages like Odia and Bengali.
0 - Open Source AI Tools
17 - OpenAI Gpts
CodeGPT
This GPT can generate code for you. For now it creates full-stack apps using Typescript. Just describe the feature you want and you will get a link to the Github code pull request and the live app deployed.
Advanced Web Scraper with Code Generator
Generates web scraping code with accurate selectors.

Scraping GPT Proxy and Web Scraping Tips
Scraping ChatGPT helps you with web scraping and proxy management. It provides advanced tips and strategies for efficiently handling CAPTCHAs, and managing IP rotations. Its expertise extends to ethical scraping practices, and optimizing proxy usage for seamless data retrieval

Domain Email Scraper
Assists in ethically finding domain emails, keeping methods confidential.