Best AI tools for< Scene Understanding >
20 - AI tool Sites

Visual Computing & Artificial Intelligence Lab at TUM
The Visual Computing & Artificial Intelligence Lab at TUM is a group of research enthusiasts advancing cutting-edge research at the intersection of computer vision, computer graphics, and artificial intelligence. Our research mission is to obtain highly-realistic digital replica of the real world, which include representations of detailed 3D geometries, surface textures, and material definitions of both static and dynamic scene environments. In our research, we heavily build on advances in modern machine learning, and develop novel methods that enable us to learn strong priors to fuel 3D reconstruction techniques. Ultimately, we aim to obtain holographic representations that are visually indistinguishable from the real world, ideally captured from a simple webcam or mobile phone. We believe this is a critical component in facilitating immersive augmented and virtual reality applications, and will have a substantial positive impact in modern digital societies.
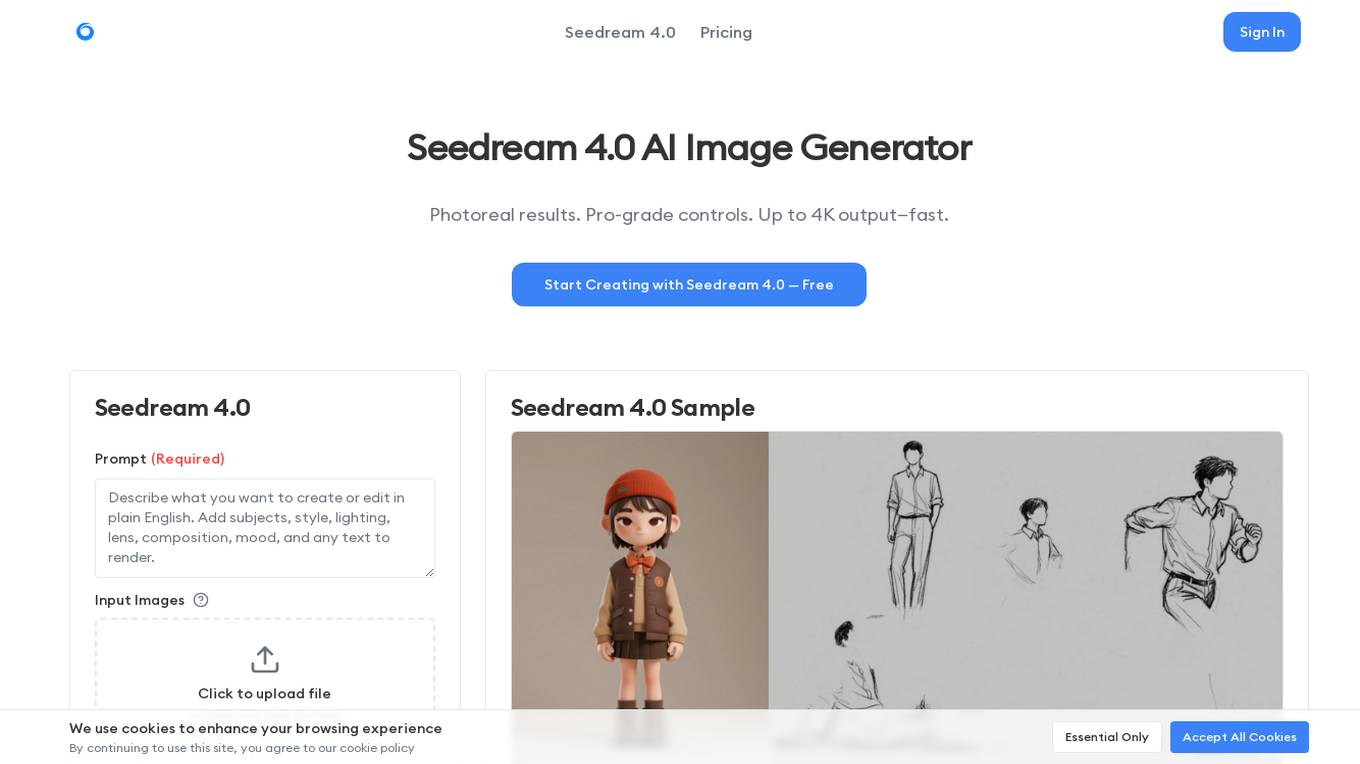
Seedream 4.0
Seedream 4.0 is a next-generation multi-modal AI image generator designed for creators to produce photorealistic images with pro-grade controls and fast rendering capabilities. It offers features such as deep scene understanding, reference-based consistency, artistic style transfer, ultra-fast rendering, sequential story generation, and commercial-grade design. Users can create stunning visuals with AI in four simple steps: adding references, describing their vision, generating and refining, and exporting in high resolution. Seedream 4.0 is ideal for various applications including narrative visuals, product sets, comics, ads, social carousels, posters, key visuals, and marketing graphics.
Grok-1.5 Vision
Grok-1.5 Vision (Grok-1.5V) is a groundbreaking multimodal AI model developed by Elon Musk's research lab, x.AI. This advanced model has the potential to revolutionize the field of artificial intelligence and shape the future of various industries. Grok-1.5V combines the capabilities of computer vision, natural language processing, and other AI techniques to provide a comprehensive understanding of the world around us. With its ability to analyze and interpret visual data, Grok-1.5V can assist in tasks such as object recognition, image classification, and scene understanding. Additionally, its natural language processing capabilities enable it to comprehend and generate human language, making it a powerful tool for communication and information retrieval. Grok-1.5V's multimodal nature sets it apart from traditional AI models, allowing it to handle complex tasks that require a combination of visual and linguistic understanding. This makes it a valuable asset for applications in fields such as healthcare, manufacturing, and customer service.
Sora AI
Sora AI is a text-to-video generator AI software developed by OpenAI. It converts text prompts into realistic videos suitable for movie making, teaching, and animation. The tool uses advanced NLP technology and machine learning algorithms to create high-quality videos based on user input. Sora AI offers features like text-to-video conversion, flexibility in sampling, customization options, prompt by image & video, and integration with other AI tools. Despite its advantages in creativity, time efficiency, accessibility, budget-friendliness, and scalability, Sora AI has limitations such as dependency on input prompt, accuracy issues, complex scene understanding, internet connectivity requirements, privacy concerns, and limited voiceover options.

VO3 AI
VO3 AI is an innovative AI video generator powered by Veo3 AI technology. It transforms scripts, ideas, or prompts into immersive videos with high-fidelity motion and storytelling. Users can create cinematic videos in minutes, customize visuals, and download finished clips in popular formats. The platform offers advanced features like high-fidelity visuals, multi-style rendering, dynamic scene understanding, and fine-grained controls. VO3 AI caters to various industries such as marketing, education, and entertainment, providing a user-centric interface for both creatives and non-technical users.
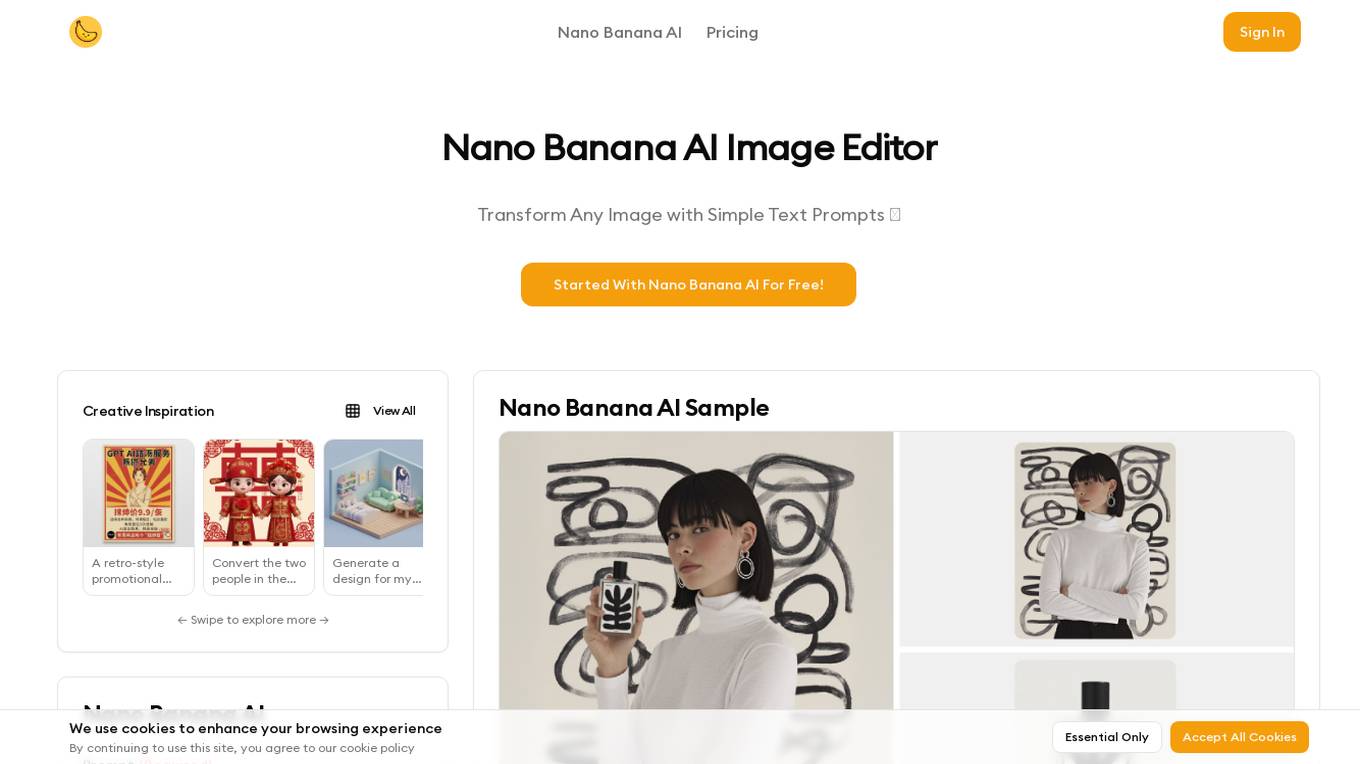
Nano Banana AI
Nano Banana AI is an advanced AI image editor that utilizes natural language understanding to transform images with superior character consistency. It offers features like natural language editing, superior character details preservation, scene fusion, one-shot editing, and multi-image context processing. The application is perfect for creating consistent AI influencers and user-generated content, with support for social media and marketing campaigns. Nano Banana AI stands out for its exceptional image editing capabilities, delivering high-quality outputs for professional use across various industries and applications.
Nano Banana
Nano Banana is an advanced AI image editing tool that combines natural language prompts with intelligent prompt understanding to deliver precise and high-quality image transformations. It excels in maintaining consistent characters, preserving scene context, and generating realistic style transformations. With features like one-shot editing, multi-image support, and reliable multi-character adjustments, Nano Banana revolutionizes the creative workflow for professionals and everyday users alike.

SceneContext AI
SceneContext AI is an AI application that provides transparency and control for CTV (Connected TV) ads. It classifies millions of videos to help publishers and marketers enhance their CTV strategies by leveraging the latest Language Models for human-like understanding of video content. The application prioritizes privacy by focusing solely on content metadata and scene-level data, without the use of cookies or user data. SceneContext AI offers real-time insights, content recognition, ad placement verification, compliance automation, and personalized targeting to boost CTV deals.
Nano Banana
Nano Banana is a state-of-the-art image generation and editing model developed by Google, designed for fast, conversational, and multi-turn creative workflows with unmatched character consistency. Users can upload images and describe desired edits in natural language, and the AI technology delivers instant results with perfect character appearance and scene blending. Nano Banana offers features like conversational editing, multi-image fusion, visual templates support, and SynthID watermarking for responsible AI use. It is ideal for commercial projects and provides deep semantic understanding for complex visual tasks.
Twelve Labs
Twelve Labs is a cutting-edge AI tool that specializes in multimodal video understanding, allowing users to bring human-like video comprehension to any application. The tool enables users to search, generate, and embed video content with state-of-the-art accuracy and scalability. With the ability to handle vast video libraries and provide rich video embeddings, Twelve Labs is a game-changer in the field of video analysis and content creation.
Scene
Scene is an all-in-one web workspace that offers a comprehensive platform for web designers and marketers to manage the entire design process from ideation to execution. With its Muse AI assistant, Scene provides tools for refining website briefs, researching competitors, auto-generating wireframes, and writing web copy. The platform enables visual co-creation, allowing teams to collaborate seamlessly and design together in one place. Scene also offers adaptable blocks for designing responsive websites, one-click publishing, and an ever-growing library of best-practice blocks. It is shaped by community insights and has received great reviews for its intuitive interface and groundbreaking Muse AI capabilities.

Scene One
Scene One is an online book writing software with an AI writing assistant that helps writers to create and organize their manuscripts efficiently. It offers features such as writing on every device, organizing manuscripts, tracking characters and locations, setting reminders, and revising with ease. The application allows writers to write their stories in scenes, snippets, or chapters, and provides tools to build a wiki, attach reminders, and export manuscripts to PDF and Word DocX formats. Scene One aims to simplify the writing process and enhance the overall writing experience for new and experienced writers alike.
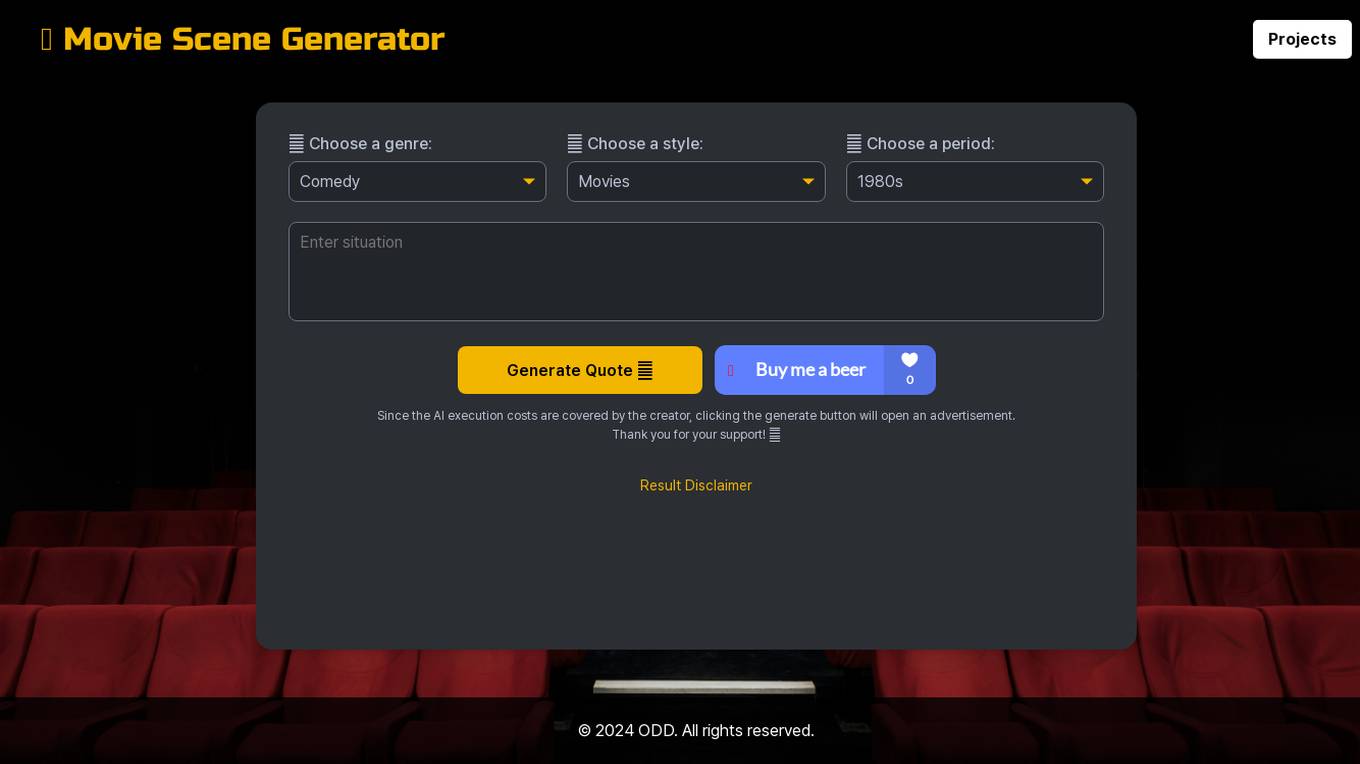
Movie Scene Generator
The Movie Scene Generator is an AI-powered tool that allows users to create fictional movie scenes by selecting genres, styles, and periods. Users can generate quotes and scenes for educational or entertainment purposes. The tool covers AI execution costs through advertisements, ensuring free usage for users. It generates fictional content and emphasizes user responsibility to avoid entering inappropriate content. The tool does not store personal information and is restricted for personal use only.
SceneDreamer
SceneDreamer is an AI tool that learns to generate unbounded 3D scenes from in-the-wild 2D image collections. It synthesizes diverse landscapes with 3D consistency, well-defined depth, and free camera trajectory. The framework comprises an efficient 3D scene representation, generative scene parameterization, and a neural volumetric renderer. SceneDreamer does not require 3D annotations and demonstrates superiority over state-of-the-art methods in generating vivid and diverse unbounded 3D worlds.
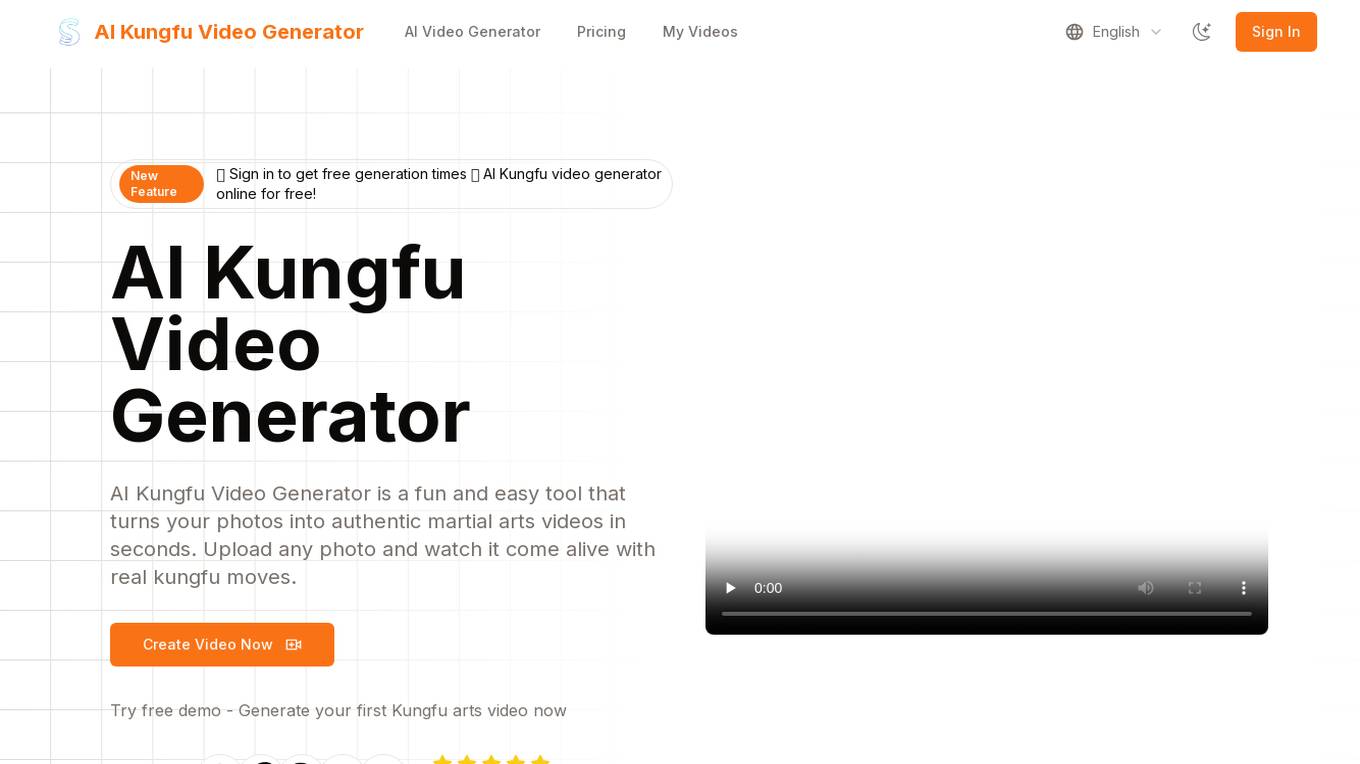
AI Kungfu Video Generator
AI Kungfu Video Generator is a revolutionary AI-powered platform that transforms your photos into authentic martial arts videos in just seconds. By combining cutting-edge AI technology with martial arts expertise, users can create stunning action sequences without any prior training. The tool offers customizable styles, quick results, and high-quality output for effortless video generation. Whether you're a content creator, martial arts enthusiast, or creative novice, AI Kungfu Video Generator provides a fun and easy way to bring your Kungfu dreams to life.

Luma AI
Luma AI is an AI-powered platform that specializes in video generation using advanced models like Ray2 and Dream Machine. The platform offers director-grade control over style, character, and setting, allowing users to reshape videos with ease. Luma AI aims to build multimodal general intelligence that can generate, understand, and operate in the physical world, paving the way for creative, immersive, and interactive systems beyond traditional text-based approaches. The platform caters to creatives in various industries, offering powerful tools for worldbuilding, storytelling, and creative expression.
Luma AI
Luma AI is a 3D capture platform that allows users to create interactive 3D scenes from videos. With Luma AI, users can capture 3D models of people, objects, and environments, and then use those models to create interactive experiences such as virtual tours, product demonstrations, and training simulations.
Story-boards.ai
Story-boards.ai is an AI-driven platform that revolutionizes storyboarding for visual storytellers, including filmmakers, ad creators, and graphic novelists. It empowers users to transform written scripts into dynamic visual storyboards, maintain character consistency, and speed up the pre-production process with AI-enhanced storyboarding. The platform offers tailored storyboards, custom camera angles, character consistency, and a streamlined workflow to elevate narratives and unlock new realms of possibility in visual storytelling.
Fotogram.ai
Fotogram.ai is an AI-powered image editing tool that offers a wide range of features to enhance and transform your photos. With Fotogram.ai, users can easily apply filters, adjust colors, remove backgrounds, add effects, and retouch images with just a few clicks. The tool uses advanced AI algorithms to provide professional-level editing capabilities to users of all skill levels. Whether you are a photographer looking to streamline your workflow or a social media enthusiast wanting to create stunning visuals, Fotogram.ai has you covered.

NEEDS MORE BOOM
The website 'NEEDS MORE BOOM' is a fun and creative platform that allows users to reimagine their favorite movie scenes with more explosions and action-packed elements. Users can input a movie scene, and the team behind the website will transform it into a high-octane spectacle reminiscent of a Michael Bay film. The site aims to inject excitement and adrenaline into mundane movie moments, offering a unique and entertaining experience for users who crave more 'boom' in their cinematic adventures.
0 - Open Source AI Tools
20 - OpenAI Gpts

Actor 'Scene' Writer
I'll help you craft scenes to produce for your demo reel or for scene study in acting class!
TV Film Actor’s Scene Prep
Coaches actors in scene analysis, character development for television and film.
Scene Sculptor
A creative assistant for enhancing story scenes, focusing on vividness and character depth.
Banter Scene Cartoonist
Meet Banter Scene Cartoonist 🎨: where your ideas turn into engaging cartoon scenes with witty dialogues 😄. I create vivid illustrations with educational and humorous exchanges between characters, tailored just for you
Style & Scene
A guide through entertainment, fashion, film, and music, linking current events and culture.
Beautiful Ocean Scene Prints - R2d3.io
Generates breathtaking ocean and beach Images to be printed

FamSocial: DreamMaker
. . . . . . . . . . . ~ From the Mind of Mentis ~ . . . . . . . . . . . . Make a scene from your favorite PFPs! 👀🕳️🐇Upload images, choose key traits, scene and style and let FamSocial bring your dreams to life.
HouseGPT
This GPT will take a user's data and use it to construct a fake TV scene. Start by providing it with your character's Patient Profile, Diagnostic Findings, and Lab Data

Crimeweaver: Infinite Detective
You are the Infinite Detective. Enjoy endless guided interactive crime scene investigations
Identify movies, dramas, and animations by image
Just send us an image of a scene from a video work and i will guess the name of the work!
Détective Virtuel
Incarne un détective sur une scène de crime, enquêtes, trouves des indices et deviens le nouveau Sherlock Holmes . 3 Niveaux de difficulté.
Scriptify
Rewrites articles into engaging scripts with image prompts for each scene and captivating openings and closings.