Best AI tools for< Run Offline Inference >
20 - AI tool Sites
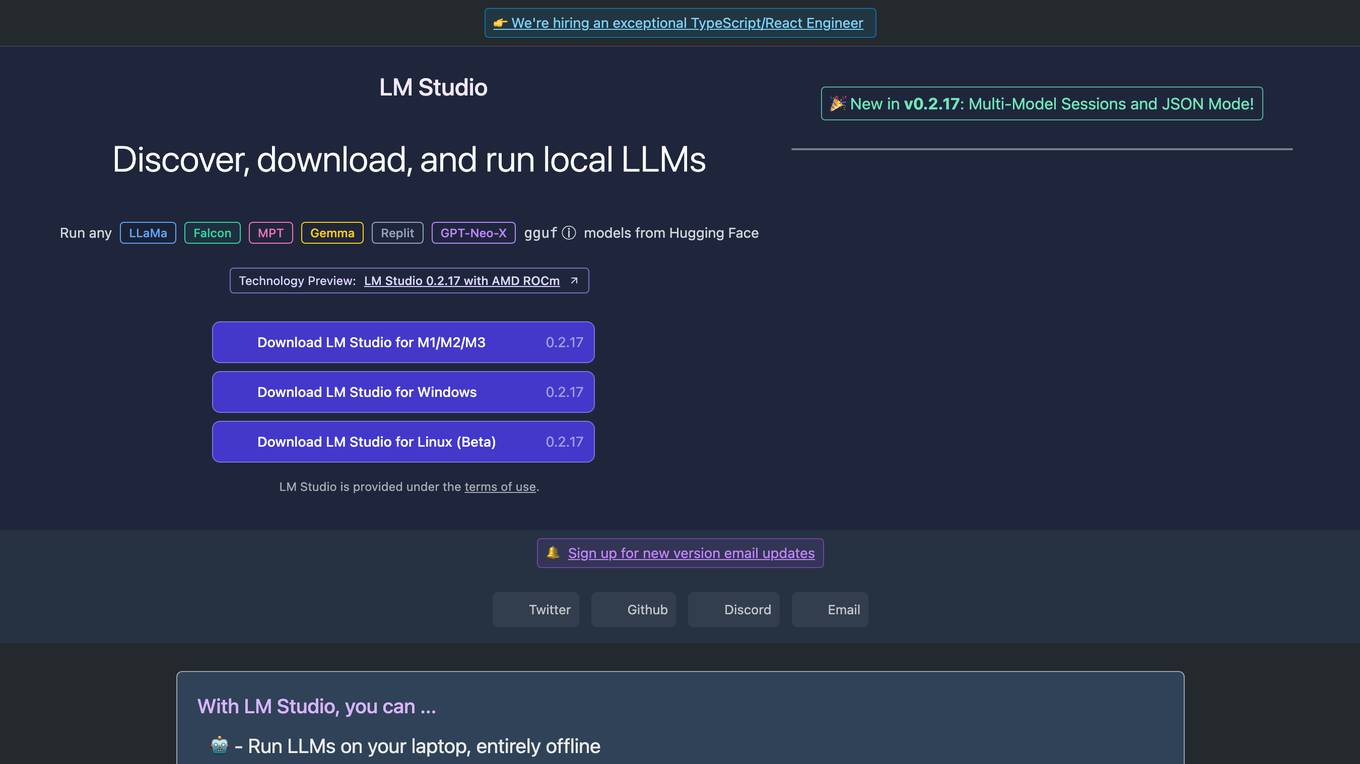
LM Studio
LM Studio is an AI tool designed for discovering, downloading, and running local LLMs (Large Language Models). Users can run LLMs on their laptops offline, use models through an in-app Chat UI or a local server, download compatible model files from HuggingFace repositories, and discover new LLMs. The tool ensures privacy by not collecting data or monitoring user actions, making it suitable for personal and business use. LM Studio supports various models like ggml Llama, MPT, and StarCoder on Hugging Face, with minimum hardware/software requirements specified for different platforms.
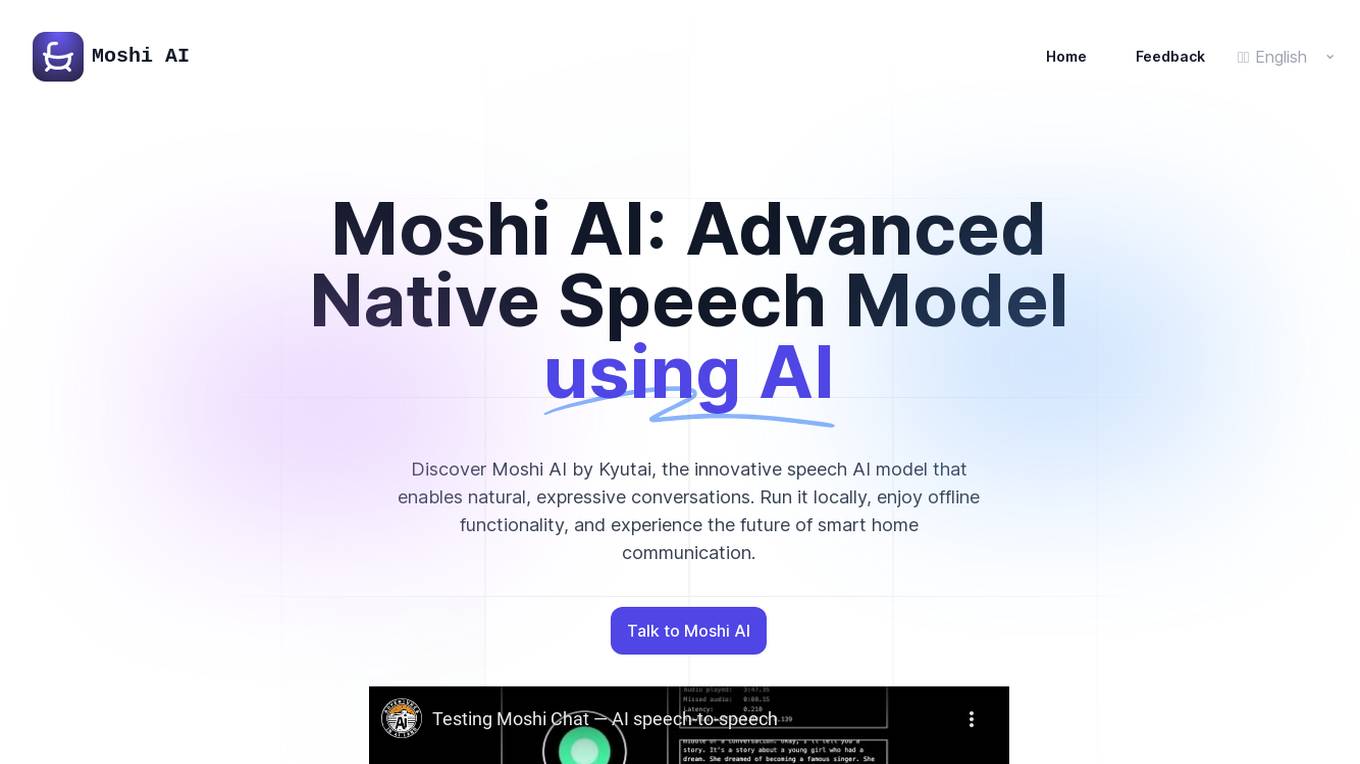
Moshi AI
Moshi AI by Kyutai is an advanced native speech AI model that enables natural, expressive conversations. It can be installed locally and run offline, making it suitable for integration into smart home appliances and other local applications. The model, named Helium, has 7 billion parameters and is trained on text and audio codecs. Moshi AI supports native speech input and output, allowing for smooth communication with the AI. The application is community-supported, with plans for continuous improvement and adaptation.
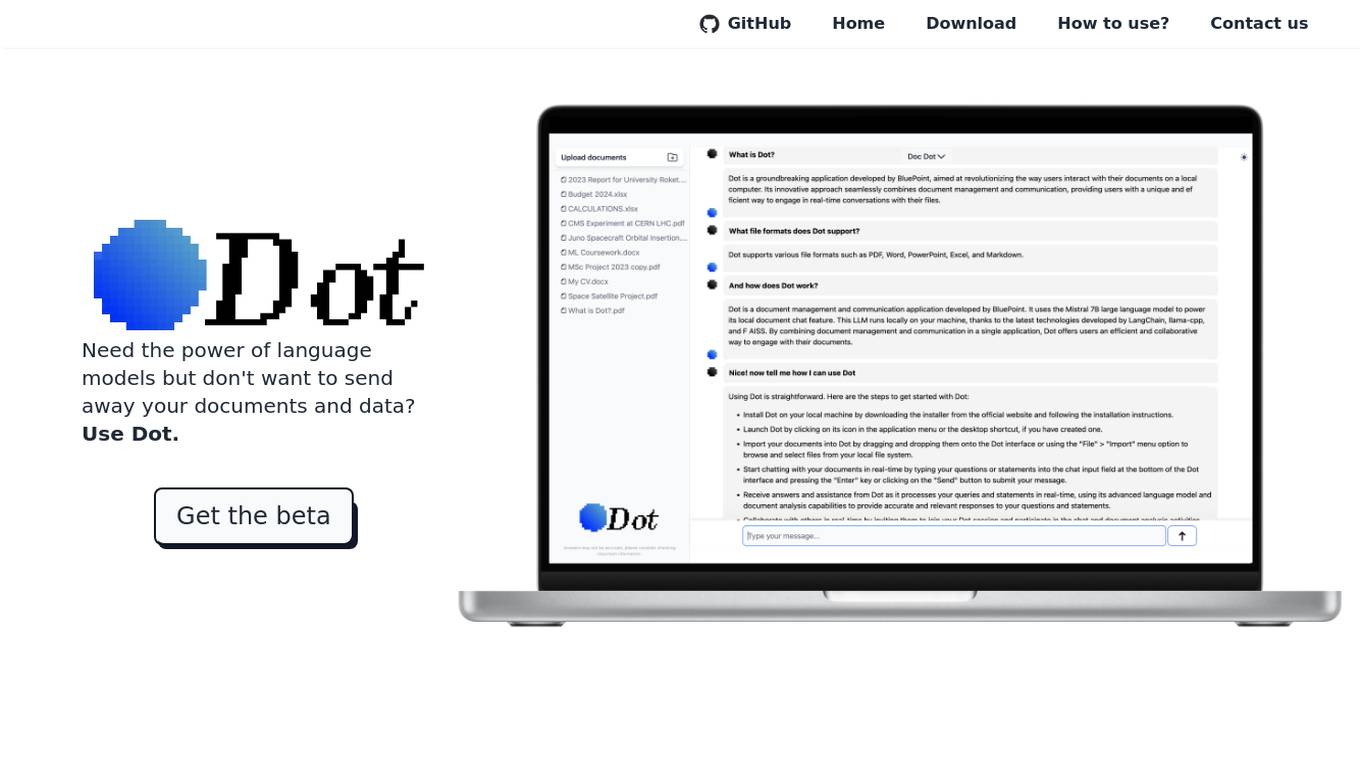
Dot
Dot is a free, locally-run language model that allows users to interact with their own documents, chat with the model, and use the model for a variety of tasks, all without sending their data away. It is powered by the Mistral 7B LLM, which means it can run locally on a user's device and does not give away any of their data. Dot can also run offline.
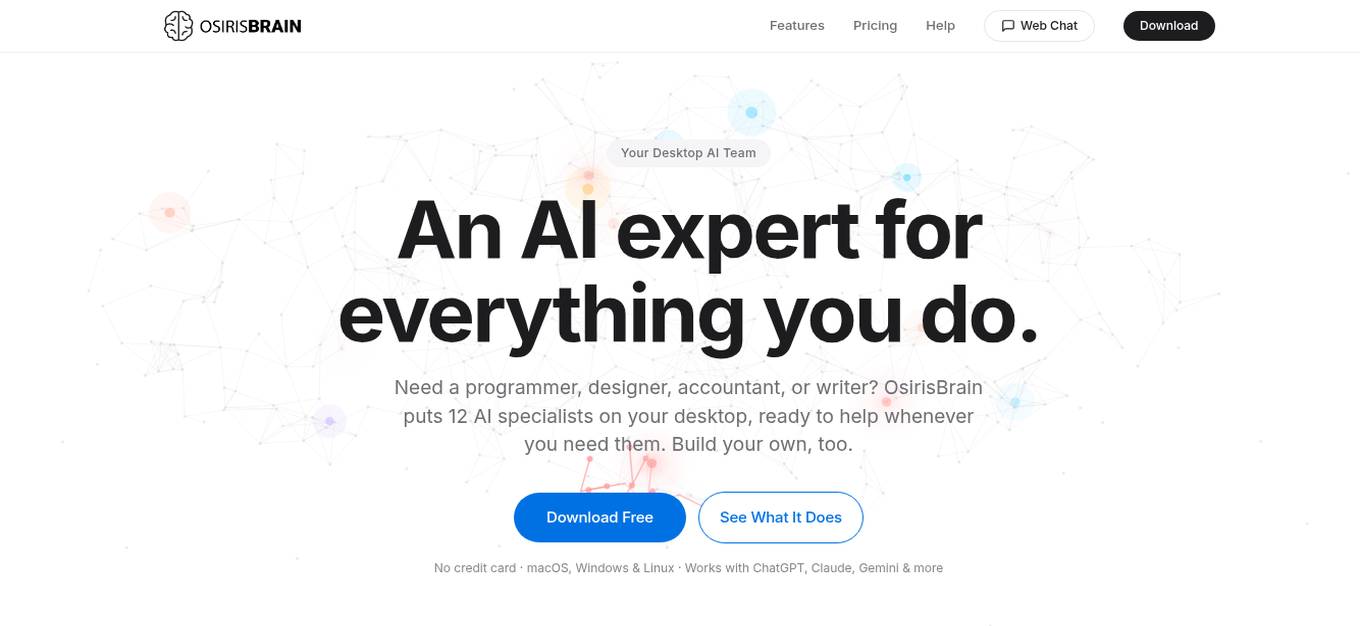
OsirisBrain
OsirisBrain is an AI desktop agent that offers autonomous AI automation for Mac, Windows, and Linux. It provides users with access to 12 AI specialists on their desktop, each with a specialized system prompt tuned for their domain. The application evolves autonomously by analyzing, coding, testing, and deploying new specialized skills in real-time. OsirisBrain runs locally on the user's machine, ensuring data privacy, and offers features such as custom skill building, remote chat, vision capabilities, multi-provider connectivity, zero-config memory, learning loop, plugin manager, voice input, system monitor, and more. Users can use OsirisBrain for 3 hours free per day and benefit from features like Guardian Mode, End-to-End Encryption, Parental Mode, and a Cortex Memory System that mimics a real brain's memory architecture.
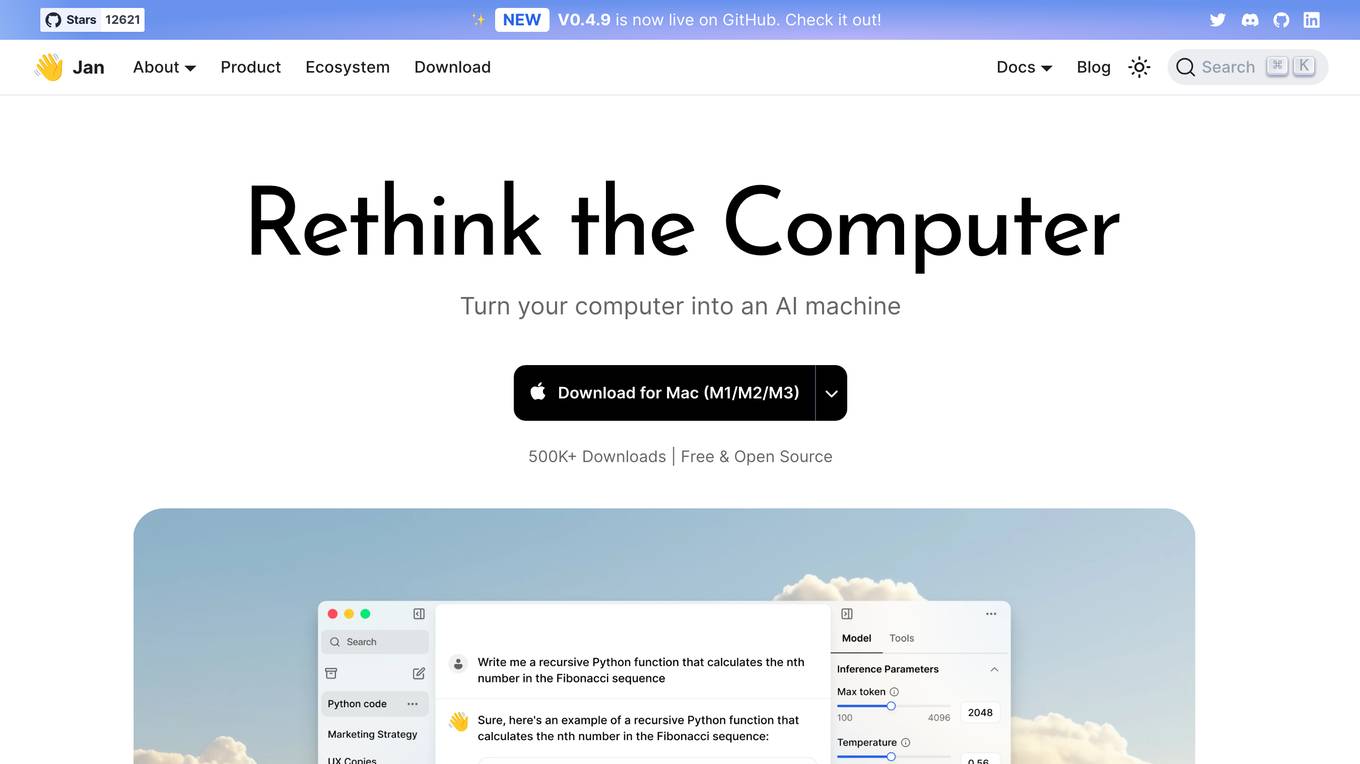
Jan
Jan is an open-source ChatGPT-alternative that runs 100% offline. It allows users to chat with AI, download and run powerful models, connect to cloud AIs, set up a local API server, and chat with files. Highly customizable, Jan also offers features like creating personalized AI assistants, memory, and extensions. The application prioritizes local-first AI, user-owned data, and full customization, making it a versatile tool for AI enthusiasts and developers.
Faraday.dev
Faraday.dev is an offline-first, zero-configuration, desktop app that supports chatting with AI Characters. With Faraday.dev, you can run over 100 different open-source LLMs all on your machine without needing to touch the command line. Faraday.dev also supports Llama 2 models and GPU acceleration.
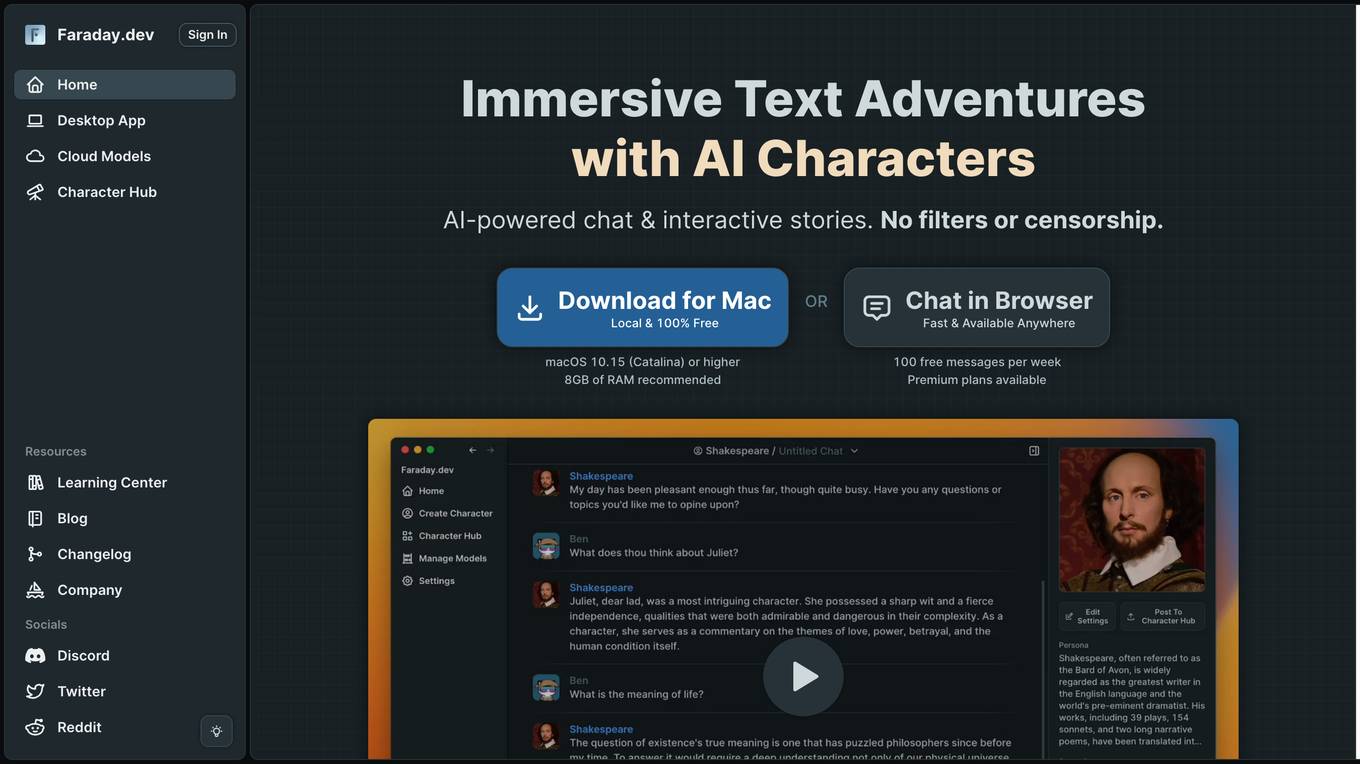
Backyard AI
Backyard AI is an AI-powered platform that offers immersive text adventures with AI characters, enabling users to engage in chat and interactive stories without filters or censorship. Users can bring AI characters to life with expressive customizations and intricate worlds. The platform provides a Desktop App for running AI models locally and a Cloud service for fast and powerful AI models accessible from anywhere. Backyard AI prioritizes privacy and control by storing all data locally on the device and encrypting data at rest. It offers a range of language models and features like mobile tethering, automatic GPU acceleration, and secure chat in the browser.
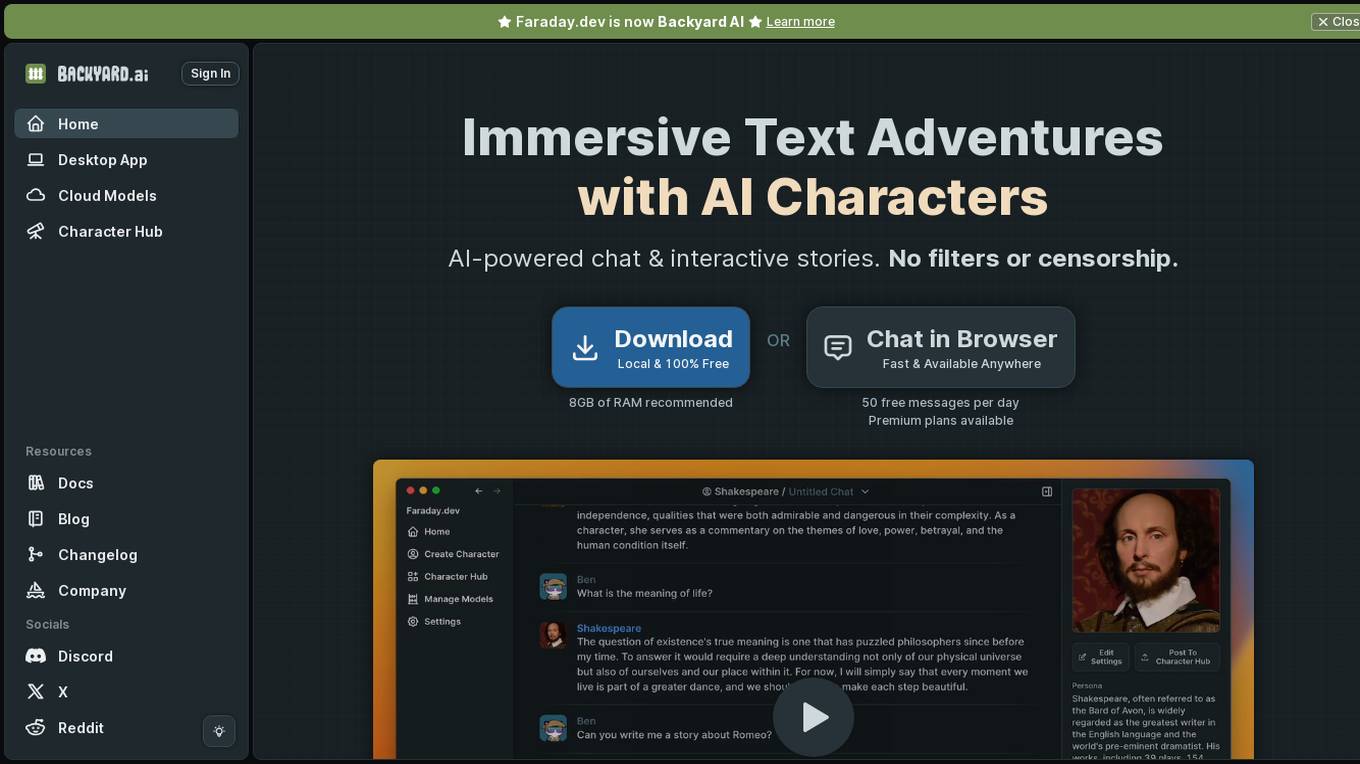
Backyard AI
Backyard AI is an AI-powered platform that offers immersive text adventures with AI characters, chat, and interactive stories. Users can bring AI characters to life with expressive customizations and explore intricate worlds through text RPG experiences. The platform provides a Desktop App for running AI models locally and cloud models for supercharging creativity. Backyard AI prioritizes privacy and control by storing data locally and encrypting it at rest. With a focus on user-friendly features and powerful AI language models, Backyard AI aims to provide an engaging and secure AI experience for users.
Layla
Layla is a private AI assistant that operates offline on your device, ensuring complete privacy and no censorship. It offers different personalities, customizable features, downloadable characters, and advanced settings. Layla can chat, inspire, assist, entertain, and more, making it a versatile AI tool for various tasks. The application is constantly evolving with weekly updates, including features like real-time internet search, task reminders, social features, and 3D models. Layla utilizes cutting-edge technology to run Large Language Models on consumer hardware, providing a unique and personalized AI experience without the need for an internet connection.
NVIDIA Run:ai
NVIDIA Run:ai is an enterprise platform for AI workloads and GPU orchestration. It accelerates AI and machine learning operations by addressing key infrastructure challenges through dynamic resource allocation, comprehensive AI life-cycle support, and strategic resource management. The platform significantly enhances GPU efficiency and workload capacity by pooling resources across environments and utilizing advanced orchestration. NVIDIA Run:ai provides unparalleled flexibility and adaptability, supporting public clouds, private clouds, hybrid environments, or on-premises data centers.
Run Recommender
The Run Recommender is a web-based tool that helps runners find the perfect pair of running shoes. It uses a smart algorithm to suggest options based on your input, giving you a starting point in your search for the perfect pair. The Run Recommender is designed to be user-friendly and easy to use. Simply input your shoe width, age, weight, and other details, and the Run Recommender will generate a list of potential shoes that might suit your running style and body. You can also provide information about your running experience, distance, and frequency, and the Run Recommender will use this information to further refine its suggestions. Once you have a list of potential shoes, you can click on each shoe to learn more about it, including its features, benefits, and price. You can also search for the shoe on Amazon to find the best deals.
Practice Run AI
Practice Run AI is an online platform that offers AI-powered tools for various tasks. Users can utilize the application to practice and run AI algorithms without the need for complex setups or installations. The platform provides a user-friendly interface that allows individuals to experiment with AI models and enhance their understanding of artificial intelligence concepts. Practice Run AI aims to democratize AI education and make it accessible to a wider audience by simplifying the learning process and providing hands-on experience.
Dora
Dora is a no-code 3D animated website design platform that allows users to create stunning 3D and animated visuals without writing a single line of code. With Dora, designers, freelancers, and creative professionals can focus on what they do best: designing. The platform is tailored for professionals who prioritize design aesthetics without wanting to dive deep into the backend. Dora offers a variety of features, including a drag-and-connect constraint layout system, advanced animation capabilities, and pixel-perfect usability. With Dora, users can create responsive 3D and animated websites that translate seamlessly across devices.
Reflect
Reflect is an AI-powered test automation tool that revolutionizes the way end-to-end tests are created, executed, and maintained. By leveraging Generative AI, Reflect eliminates the need for manual coding and provides a seamless testing experience. The tool offers features such as no-code test automation, visual testing, API testing, cross-browser testing, and more. Reflect aims to help companies increase software quality by accelerating testing processes and ensuring test adaptability over time.

Learn Playwright
Learn Playwright is a comprehensive platform offering resources for learning end-to-end testing using the Playwright automation framework. It provides a blog with in-depth subjects about end-to-end testing, an 'Ask AI' feature for querying ChatGPT about Playwright questions, and a Dev Tools section that serves as an all-in-one toolbox for QA engineers. The platform also curates QA and Automation job opportunities, answers common questions about Playwright, hosts a Discord forum archive, offers various videos including tutorials and conference talks, provides a browser extension with a GUI for generating Playwright locators, and features a QA Wiki with definitions of common end-to-end testing terms. Users can quickly access all tools by using the shortcut Ctrl + k + 'Tools'.
Symphony
Symphony is a programming platform that allows users to write programs using natural language. It aims to simplify the process of coding by enabling users to interact with the system through conversational language, making it more accessible to individuals without a technical background. Symphony provides a user-friendly interface for creating scripts and automating tasks, bridging the gap between traditional programming languages and everyday communication.
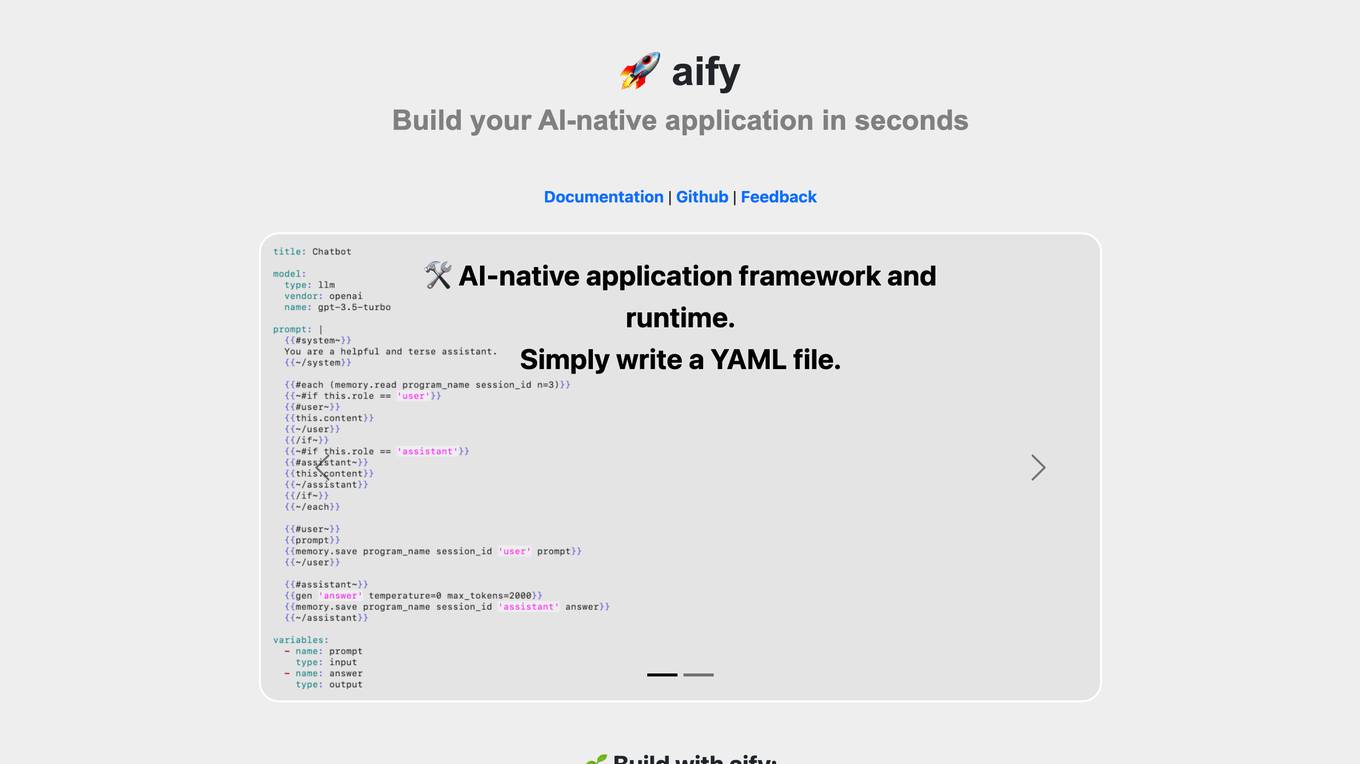
aify
aify is an AI-native application framework and runtime that allows users to build AI-native applications quickly and easily. With aify, users can create applications by simply writing a YAML file. The platform also offers a ready-to-use AI chatbot UI for seamless integration. Additionally, aify provides features such as Emoji express for searching emojis by semantics. The framework is open source under the MIT license, making it accessible to developers of all levels.
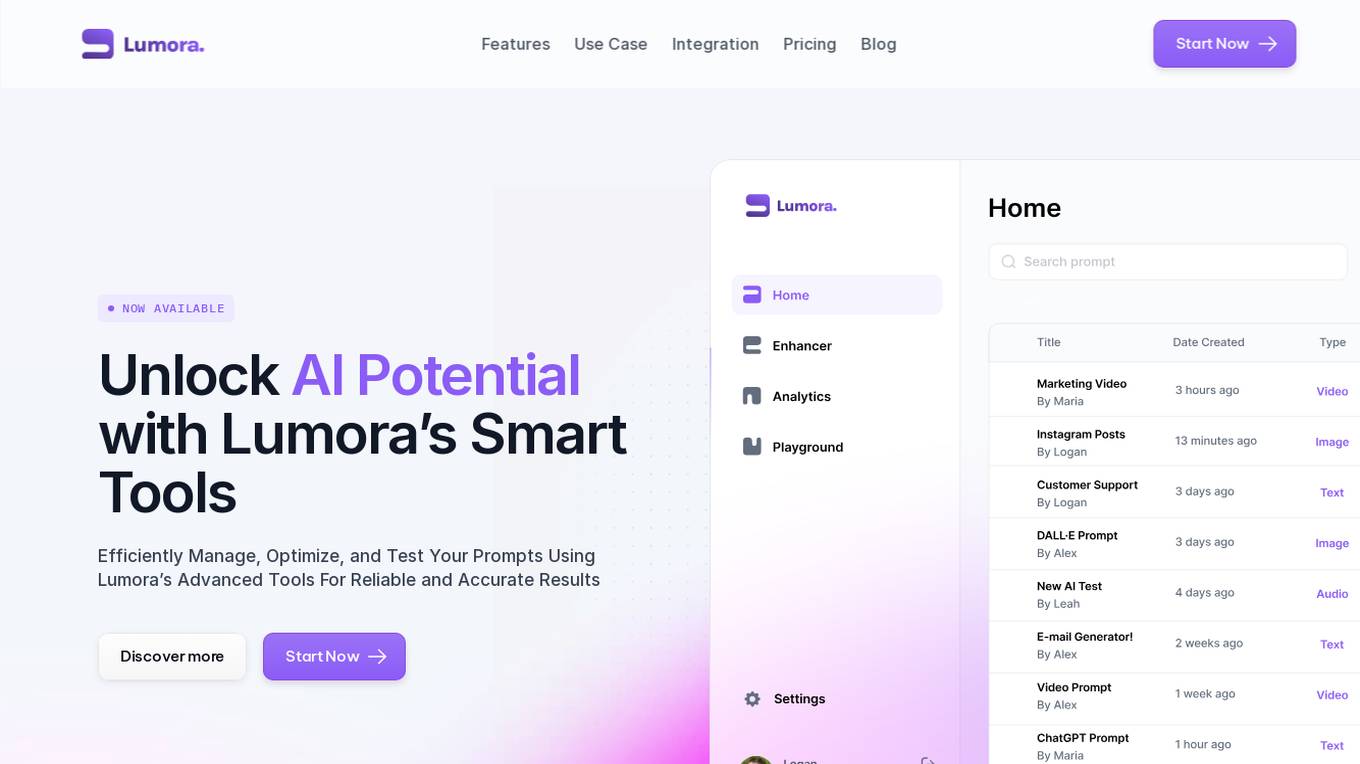
Lumora
Lumora is an AI tool designed to help users efficiently manage, optimize, and test prompts for various AI platforms. It offers features such as prompt organization, enhancement, testing, and development. Lumora aims to improve prompt outcomes and streamline prompt management for teams, providing a user-friendly interface and a playground for experimentation. The tool also integrates with various AI models for text, image, and video generation, allowing users to optimize prompts for better results.

Dora
Dora is an AI-powered platform that enables users to create 3D animated websites without the need for coding. It caters to designers, freelancers, and creative professionals who seek to design visually captivating websites effortlessly. With Dora, users can craft mesmerizing 3D and animated visuals that are responsive and seamlessly translate across devices. The platform is designed for professionals who prioritize design aesthetics and offers a no-code experience for those transitioning from other design tools. Dora leverages advanced AI algorithms to generate, customize, and deploy stunning landing pages, revolutionizing the web design process.

Magnet
Magnet is an AI coding assistant that helps product teams fix issues, share AI threads, and organize projects. It integrates with Linear, GitHub, and Notion, and provides auto-suggested files and code files for personalized and accurate AI recommendations. Magnet also offers prompt templates to help users get started and suggests quick fixes for bugs or enhancements.
1 - Open Source AI Tools
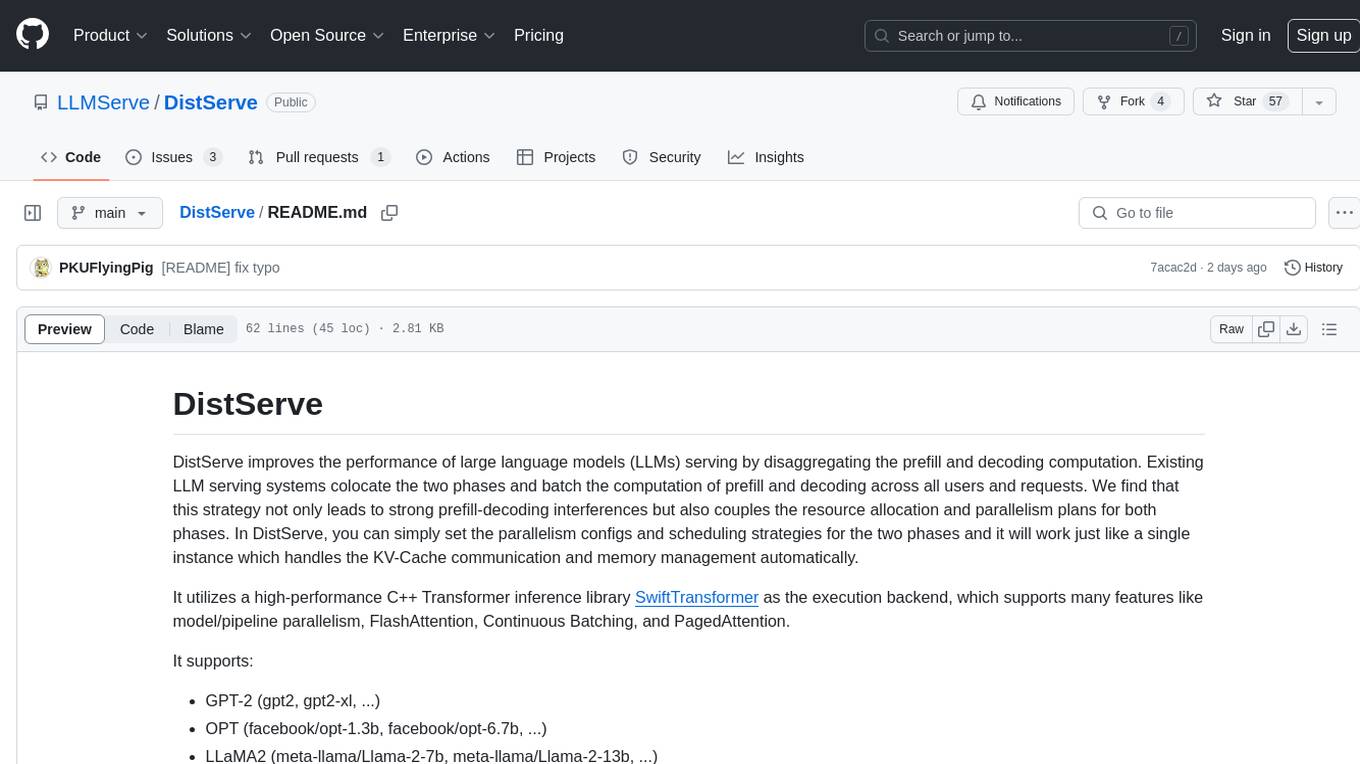
DistServe
DistServe improves the performance of large language models serving by disaggregating the prefill and decoding computation. It allows setting parallelism configs and scheduling strategies for the two phases independently, handling KV-Cache communication and memory management automatically. Utilizes a high-performance C++ Transformer inference library SwiftTransformer with features like model/pipeline parallelism, FlashAttention, Continuous Batching, and PagedAttention. Supports GPT-2, OPT, and LLaMA2 models.
20 - OpenAI Gpts
Consulting & Investment Banking Interview Prep GPT
Run mock interviews, review content and get tips to ace strategy consulting and investment banking interviews

Dungeon Master's Assistant
Your new DM's screen: helping Dungeon Masters to craft & run amazing D&D adventures.
Database Builder
Hosts a real SQLite database and helps you create tables, make schema changes, and run SQL queries, ideal for all levels of database administration.
Restaurant Startup Guide
Meet the Restaurant Startup Guide GPT: your friendly guide in the restaurant biz. It offers casual, approachable advice to help you start and run your own restaurant with ease.

Community Design™
A community-building GPT based on the wildly popular Community Design™ framework from Mighty Networks. Start creating communities that run themselves.
Code Helper for Web Application Development
Friendly web assistant for efficient code. Ask the wizard to create an application and you will get the HTML, CSS and Javascript code ready to run your web application.

Creative Director GPT
I'm your brainstorm muse in marketing and advertising; the creativity machine you need to sharpen the skills, land the job, generate the ideas, win the pitches, build the brands, ace the awards, or even run your own agency. Psst... don't let your clients find out about me! 😉
Pace Assistant
Provides running splits for Strava Routes, accounting for distance and elevation changes



Design Sprint Coach (beta)
A helpful coach for guiding teams through Design Sprints with a touch of sass.