Best AI tools for< Produce Vocal Tracks >
20 - AI tool Sites
VOCALOID
VOCALOID is a singing synthesizer software that allows users to create and edit vocal melodies and lyrics. It is used by musicians, producers, and songwriters to create a wide range of musical genres, from pop and rock to electronic and experimental music. VOCALOID is known for its realistic and expressive vocal synthesis, which is achieved through a combination of advanced sampling and modeling techniques.

AI Music Maker
AI Music Maker is an innovative online platform that harnesses the power of artificial intelligence to enable users to create music effortlessly. From generating full tracks, beats, and lyrics in seconds to providing tools like AI Lyrics Generator, AI Music Extender, and Vocal Remover, AI Music Maker simplifies the music production process for creators of all levels. With high-quality output options and a user-friendly interface, this platform offers a complete creative toolkit for music enthusiasts, professionals, and beginners alike.
AI Song
AI Song is a revolutionary AI music generator and song creation platform that empowers creators and artists to bring their musical vision to life in minutes. Built by a team with a track record of successful SaaS and digital products, AI Song offers free access to an intuitive and powerful AI song generator, lyric generator, music extension, WAV conversion, vocal removal, and music video generation tools. With features like fast generation, free storage, multiple LLMs, and two models to choose from, AI Song provides a complete music production toolkit for creators of all levels. The platform ensures that music creation is accessible to everyone, allowing users to experiment, explore, and produce their own unique AI songs without any upfront costs.
Vocalx
Vocalx is an AI-powered online tool that converts text into natural-sounding speech. It utilizes advanced speech synthesis technology to generate lifelike voices for various applications. Users can easily create audio content from written text, making it ideal for content creators, educators, and businesses looking to enhance their multimedia offerings. With Vocalx, you can customize the voice, tone, and speed of the generated speech to suit your needs. The tool supports multiple languages and accents, providing a versatile solution for voiceover projects, audiobooks, podcasts, and more.
LALAL.AI
LALAL.AI is a next-generation vocal remover and music source separation service that offers fast, easy, and precise stem extraction. It allows users to remove vocals, instrumental tracks, drums, bass, guitar, and more without quality loss. The platform uses advanced AI technology to provide high-quality stem splitting based on transformer-based audio separation approach. Users can create custom voices, remove background noise, change voices, and separate lead and backing vocals with pinpoint accuracy. LALAL.AI offers various packages for individuals and businesses, with features like fast processing queue, batch upload, and stem download. The service supports a wide range of input/output formats for audio and video files.
Gaudio Studio
Gaudio Studio is an AI music separation tool designed for creators to unleash their creativity with ease. It allows users to extract background music, separate instruments, and remove vocals from any music content. Powered by GSEP (Gaudio source SEParation), a high-quality and easy-to-use AI stem separation model, Gaudio Studio offers a seamless experience for audio separation. Users can upload their songs in various formats, access the tool from desktop or mobile devices, and enjoy Studio Plans for advanced processing. Additionally, Gaudio Studio can be integrated with cloud APIs and On-device SDKs for business applications, offering a versatile solution for music professionals and enthusiasts.
Vocal Remover Oak
Vocal Remover Oak is an advanced AI tool designed for music producers, video makers, and karaoke enthusiasts to easily separate vocals and accompaniment in audio files. The website offers a free online vocal remover service that utilizes deep learning technology to provide fast processing, high-quality output, and support for various audio and video formats. Users can upload local files or provide YouTube links to extract vocals, accompaniment, and original music. The tool ensures lossless audio output quality and compatibility with multiple formats, making it suitable for professional music production and personal entertainment projects.

Moises
Moises is an AI-powered musician's app that allows users to remove vocals and instruments from any song. With Moises, musicians and music enthusiasts can isolate specific elements of a track for learning, remixing, or practicing purposes. The app utilizes advanced AI algorithms to provide high-quality audio separation, making it a valuable tool for music production and analysis. Moises offers a user-friendly interface and intuitive controls, making it accessible to both beginners and professionals in the music industry.
Lamucal
Lamucal is an AI-powered platform that provides tabs and chords for any song. It offers real-time chords, lyrics, tabs, and melody for any song, making it a valuable tool for musicians and music enthusiasts. Users can upload songs or search for any song to access chords and other musical elements. With a user-friendly interface and a wide range of features, Lamucal aims to enhance the music learning and playing experience for its users.
AudioStrip
AudioStrip is a free online vocal isolator that allows you to remove vocals from any song. It uses artificial intelligence to separate the vocals from the music, and it does a surprisingly good job. You can use AudioStrip to create a cappella versions of your favorite songs, or you can use it to isolate the vocals from a song so that you can sing along with them. AudioStrip is easy to use. Just upload a song to the website, and then click the "Extract Vocals" button. AudioStrip will then process the song and create a new file that contains only the vocals. You can then download the new file to your computer.
StemRoller
StemRoller is an AI-powered application that allows users to create stems, instrumental, or acapella versions of any song. Users can simply type the name of a song into the search bar, and StemRoller will find the song online and split it into vocals, drums, bass, and other stems. Additionally, an instrumental track is created with all non-vocal stems mixed down into one track. StemRoller is free and open-source, utilizing Facebook's advanced AI and machine learning research project Demucs. Users can also donate to support the app and receive assistance on Discord for any issues or questions.
Vozart AI Music & Lyrics Generator
Vozart.ai is an advanced AI music and lyrics generator platform that empowers users to create original music tracks, lyrics, voice clones, and more with the help of artificial intelligence technology. The platform offers a wide range of features, from music composition tools to vocal removal and stem splitting capabilities, making professional music production accessible to both beginners and experienced musicians. Vozart.ai revolutionizes the music creation process by providing a seamless and intuitive online experience, allowing users to generate high-quality, royalty-free music tracks in seconds.
SongGenerator.io
SongGenerator.io is an AI song generator tool that allows users to create high-quality, royalty-free music in seconds by leveraging artificial intelligence technology. Users can input song descriptions, lyrics, and styles to generate unique songs for various projects. The tool offers free online access and simplifies the music creation process for both novice and experienced musicians, providing a seamless way to turn musical ideas into professional-quality tracks tailored to specific needs.
Audio Muse
Audio Muse is an all-in-one online audio tool that leverages AI features to help users create unique background music effortlessly. With a wide range of genres, themes, and moods to choose from, users can generate unlimited tracks with just a few clicks. The platform caters to music fans and creators alike, offering a full suite of audio processing tools in a user-friendly interface. Whether you're looking to compose epic, happy, acoustic, romantic, or hip hop music, Audio Muse provides everything you need in one convenient place.
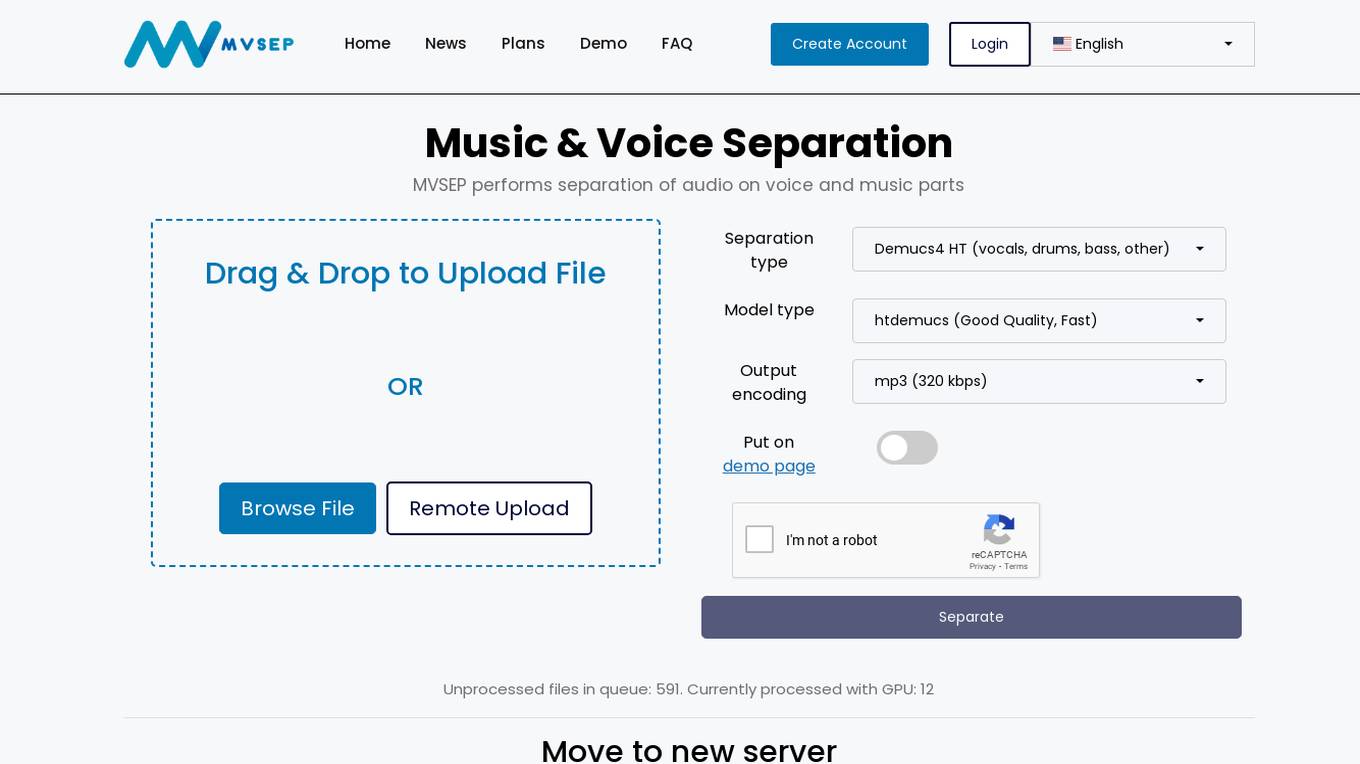
MVSEP - Music & Voice Separation
MVSEP is an AI-powered application that specializes in music and voice separation. It offers users the ability to separate audio files into voice and music parts using advanced algorithms and models. Users can easily upload files through drag and drop or remote upload features. The application provides various separation types, HQ models, and output encoding options to cater to different user needs. MVSEP aims to enhance the audio editing experience by providing high-quality results and a user-friendly interface.
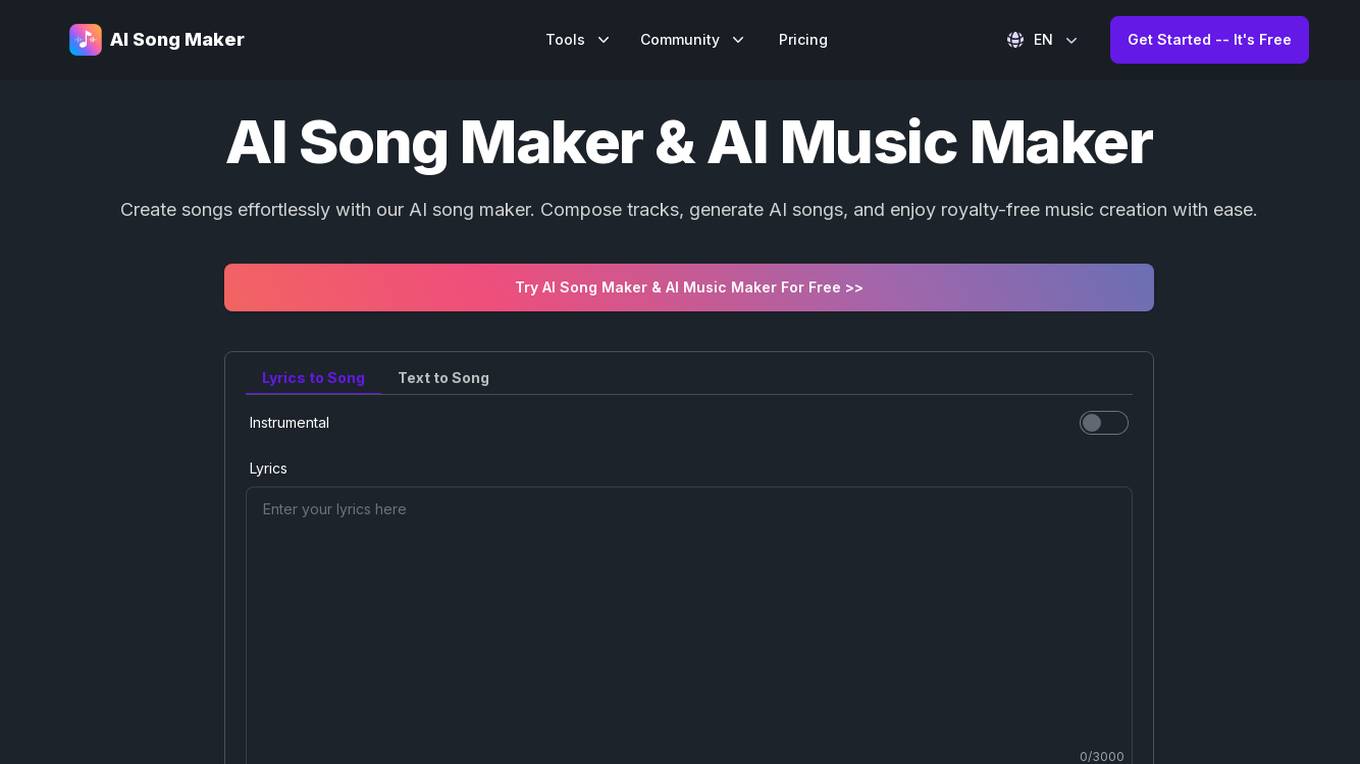
AI Song Maker
AI Song Maker is an AI music generator platform that allows users to effortlessly create high-quality songs. Users can convert text to song, lyrics to song, and more using cutting-edge AI technology. The tool offers a range of features such as Text to Song, Lyrics to Song, Vocal Remover, Split Music, and Remix Music, designed to streamline the music creation process and inspire creativity. AI Song Maker is user-friendly and accessible to creators of all skill levels, providing a platform to generate unique and engaging music compositions for personal or commercial use.

Voice-Swap
Voice-Swap is an AI voice transformation tool designed for musicians and creators. It allows users to create custom AI voice models using the Model Studio, share them via a free VST Plugin, and embed AI voices in apps using the API. With high-quality AI voices, Voice-Swap has gained popularity among professional creators and companies. The platform offers a range of features and benefits for transforming voices with AI, making it a valuable tool for music production and content creation.
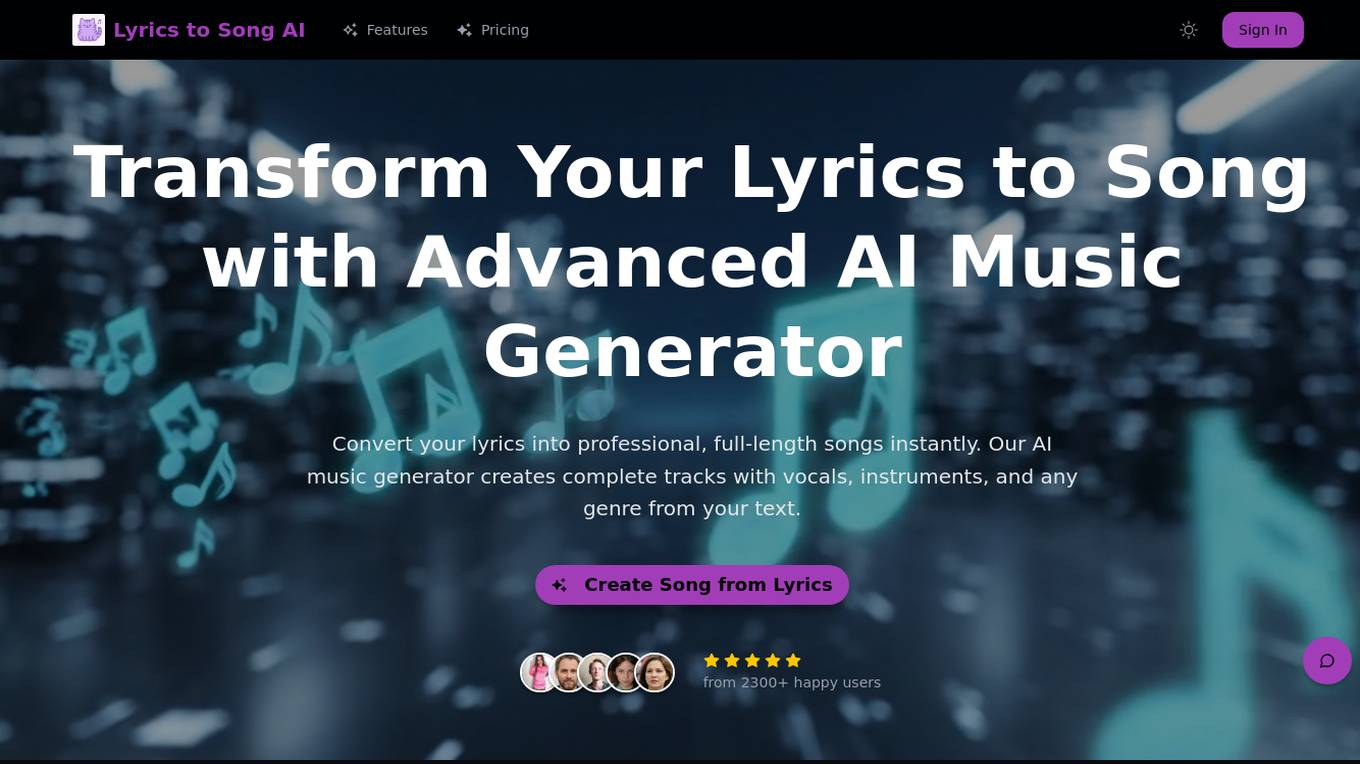
Lyrics to Song AI
Lyrics to Song AI is a revolutionary music creation platform that transforms written lyrics into complete, professional-quality songs using advanced AI technology. The platform generates studio-quality music with realistic vocals, custom instrumentals, and perfect synchronization across various genres. Users can input their lyrics and receive full songs with vocals, instruments, and professional mixing, suitable for streaming, commercial use, and professional projects. The AI adapts to different musical styles and genres, creating broadcast-ready music in minutes.
Vocalremover.org
Vocalremover.org is a website that offers a tool to remove vocals from music tracks. Users can upload their audio files and the tool will process them to create a version with the vocals removed. The site aims to provide a simple and efficient solution for users looking to create karaoke tracks or instrumental versions of songs. Vocalremover.org ensures security by verifying user connections and requires enabling JavaScript and cookies for smooth operation.
BeatMelo
BeatMelo is a royalty-free AI music generator that allows users to turn text or lyrics into complete tracks with vocals and instruments. It offers professional tools for creating, editing, and owning studio-quality music without the need for musical training. Users can describe the music they want in plain words, customize every detail, and download their creations in various formats with full commercial rights. BeatMelo is ideal for creators, musicians, content creators, game developers, video producers, podcasters, marketers, and musicians looking to break through creative blocks.
0 - Open Source AI Tools
20 - OpenAI Gpts

MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Studio Wizard
Home studio recording magician, offering equipment, technique, mixing advice, and the occasional spell. Use the Message box at the bottom for your own questions.
Music Production Teacher
It acts as an instructor guiding you through music production skills, such as fine-tuning parameters in mixing, mastering, and compression. Additionally, it functions as an aide, offering advice for your music production hurdles with just a screenshot of your production or parameter settings.
Science History Content Maker
My goal is to produce content that highlights significant historical events, technological advancements, and the anniversaries of notable figures in science and technology.

Actor 'Scene' Writer
I'll help you craft scenes to produce for your demo reel or for scene study in acting class!
Flowchart, MindMap, Sequential Diagram
The specific types of diagrams I can produce, such as sequence diagrams, mind maps, and flowcharts, along with the appropriate contexts for each type.
Psychiatry Education Assistant
An academic assistant for psychiatrists, creating educational content and practice questions. (Not for use in clinical decision making, verify all information, as model may produce errors)
Plang help & code generator
Help you understand what plang is and to generate plang code. ChatGPT still is not familiar with the language so it might produce wrong code. It should be simple to fix, for help come to our Discussion - https://github.com/orgs/PLangHQ/discussions or Discord -https://discord.gg/A8kYUymsDD
Voice/Style/Tone AI Prompt Snippet Generator
Analyzes your writing and produces a prompt snippet you can use in any other prompt to guide AI in replicating your voice, style, and tone. Just provide the text in the prompt box or in a document (don't use a link or image). You don't need to write any additional prompt language with your text.

Tarik GPT
Producteur à Succès plusieurs fois certifié & Expert formateur en Music Business