Best AI tools for< Process Ocr >
20 - AI tool Sites
Receipt OCR API
Receipt OCR API by ReceiptUp is an advanced tool that leverages OCR and AI technology to extract structured data from receipt and invoice images. The API offers high accuracy and multilingual support, making it ideal for businesses worldwide to streamline financial operations. With features like multilingual support, high accuracy, support for multiple formats, accounting downloads, and affordability, Receipt OCR API is a powerful tool for efficient receipt management and data extraction.
Ocrolus
Ocrolus is an intelligent document automation software that leverages AI-driven document processing automation with Human-in-the-Loop. It offers capabilities such as classifying, capturing, detecting, and analyzing documents, with use cases in cash flow, income, address, employment, and identity verification. Ocrolus caters to various industries like small business lending, mortgage, consumer finance, and multifamily housing. The platform provides resources for developers, including guides on income verification, fraud detection, and business process automation. Users can explore the API to build innovative customer experiences and make faster and more accurate financial decisions.
ImageTextify
ImageTextify is a free, AI-powered OCR tool that enables users to extract text from images, PDFs, and handwritten notes with high accuracy and efficiency. The tool offers a wide range of features, including multi-format support, batch processing, and a mobile-friendly interface. ImageTextify is designed to cater to both personal and professional needs, providing a seamless solution for converting images to text. With a focus on privacy, speed, and support for multiple languages and formats, ImageTextify stands out as a reliable and user-friendly OCR tool.
ABBYY
ABBYY is an intelligent automation company that offers purpose-built AI document processing solutions for efficient business process automation. Their products include ABBYY Vantage, ABBYY Timeline, ABBYY Cloud OCR SDK, and ABBYY FlexiCapture Cloud Platform. ABBYY provides tools for document input, classification, splitting, data extraction, validation, quality analytics, OCR/ICR, and IDP analytics. They also offer solutions for process understanding, optimization, monitoring, prediction, and simulation. ABBYY Marketplace offers pre-trained AI extraction models for limitless automation. The company caters to various industries like financial services, public sector, insurance, transportation & logistics, and offers solutions for accounts payable automation, enterprise automation, process intelligence, and customer onboarding.
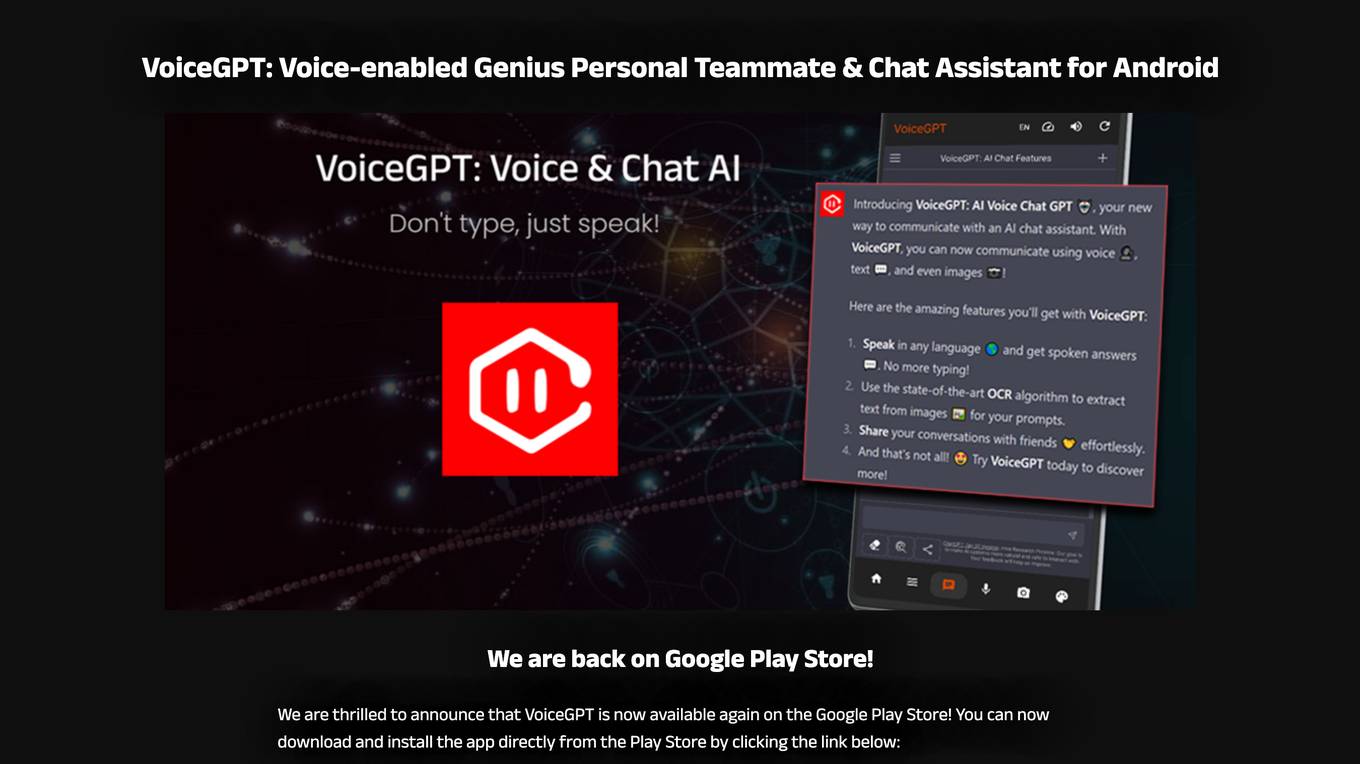
VoiceGPT
VoiceGPT is an Android app that provides a voice-based interface to interact with AI language models like ChatGPT, Bing AI, and Bard. It offers features such as unlimited free messages, voice input and output in 67+ languages, a floating bubble for easy switching between apps, OCR text recognition, code execution, image generation with DALL-E 2, and support for ChatGPT Plus accounts. VoiceGPT is designed to be accessible for users with visual impairments, dyslexia, or other conditions, and it can be set as the default assistant to be activated hands-free with a custom hotword.
GetSearchablePDF
GetSearchablePDF is an online tool that allows users to convert scanned or image-based PDF documents into searchable PDFs. With its advanced OCR (Optical Character Recognition) technology, the tool accurately extracts text from images, making the resulting PDFs easy to search, edit, and share. The process is simple and straightforward: users simply connect their Dropbox or OneDrive account, drag and drop their PDF files into the designated folder, and the tool automatically converts them into searchable PDFs.
InvoiceClip
InvoiceClip is an AI-powered application designed to streamline the process of managing invoices and receipts. It utilizes advanced artificial intelligence algorithms to accurately scan and extract information from invoices and receipts, eliminating the need for manual data entry. With InvoiceClip, users can easily organize and store their financial documents, track expenses, and generate reports with just a few clicks. The application offers a user-friendly interface and robust features to simplify the invoicing process for individuals and businesses alike.
Procys
Procys is a document processing platform powered by AI solutions. It offers a self-learning engine for document processing, seamless integration with over 260 apps, OCR API powered by AI for optical character recognition, customized data extraction capabilities, and AI autosplit feature for automatic document splitting. Procys caters to various industries such as accounting firms, travel & hospitality, and restaurants, providing solutions for invoice OCR, purchase order OCR, ID card OCR, and receipt OCR. The platform aims to automate and streamline document workflows, saving time, reducing errors, and ensuring compliance for businesses.
Shufti Pro
Shufti Pro is an award-winning global identity verification platform that provides businesses with a suite of tools to verify the identities of their customers. The platform uses artificial intelligence (AI) to automate the identity verification process, making it faster, more accurate, and more secure. Shufti Pro's solutions are used by businesses in a variety of industries, including banking, fintech, crypto, forex, gaming, insurance, education, healthcare, e-commerce, and travel.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.

Veryfi
Veryfi is an OCR API tool for invoice and receipt data extraction. It offers fast, accurate, and secure document capture and data extraction on any type of document. Veryfi empowers users to process documents efficiently, automate manual data entry, and implement AI into various business processes. The tool is designed to streamline workflows, enhance accuracy, and unlock new levels of efficiency across industries such as finance, insurance, and more.
Picture to Text Converter
Picture to Text Converter is an online tool that uses Optical Character Recognition (OCR) technology to extract text from images. It can process various image formats like JPG, PNG, GIF, scanned documents (PDFs), and even photos taken with your phone's camera. The extracted text can be copied to the clipboard or downloaded as a TXT file. Picture to Text Converter is free to use and does not require any registration or installation. It is a convenient and efficient way to convert images into editable text.
Wisedocs
Wisedocs is an AI-powered platform that specializes in medical record reviews, summaries, and insights for claims processing. The platform offers intelligent features such as medical chronologies, workflows, deduplication, intelligent OCR, and insights summaries. Wisedocs streamlines the process of reviewing medical records for insurance, legal, and independent medical evaluation firms, providing speed, accuracy, and efficiency in claims processing. The platform automates tasks that were previously laborious and error-prone, making it a valuable tool for industries dealing with complex medical records.
RecordMe
RecordMe is an AI-powered automated accounting and bookkeeping platform that offers fully automated data extraction, real-time access to business records, and streamlined invoice processing. The platform leverages OCR technology to extract and categorize accounting data efficiently, providing users with valuable data insights. RecordMe aims to maximize operational efficiency, eliminate manual data entry processes, and empower businesses to automate accounting and bookkeeping through a simple drag-and-drop process.
Mendel AI
Mendel AI is an advanced clinical AI tool that deciphers clinical data with clinician-like logic. It offers a fully integrated suite of clinical-specific data processing products, combining OCR, de-identification, and clinical reasoning to interpret medical records. Users can ask questions in plain English and receive accurate answers from health records in seconds. Mendel's technology goes beyond traditional AI by understanding patient-level data and ensuring consistency and explainability of results in healthcare.
DocuPipe
DocuPipe is an AI-powered document extraction tool that helps businesses convert various types of documents into structured data. It uses artificial intelligence to extract information from documents such as invoices, medical records, insurance claims, and more. DocuPipe offers custom definitions tailored for different businesses to accurately extract required data. The tool ensures security and compliance by encrypting documents and being GDPR and HIPAA compliant. With features like OCR, document standardization, and document splitting, DocuPipe provides accuracy, flexibility, and speed in handling documents.
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.
FormX.ai
FormX.ai is an AI-powered data extraction and conversion tool that automates the process of extracting data from physical documents and converting it into digital formats. It supports a wide range of document types, including invoices, receipts, purchase orders, bank statements, contracts, HR forms, shipping orders, loyalty member applications, annual reports, business certificates, personnel licenses, and more. FormX.ai's pre-configured data extraction models and effortless API integration make it easy for businesses to integrate data extraction into their existing systems and workflows. With FormX.ai, businesses can save time and money on manual data entry and improve the accuracy and efficiency of their data processing.
Honeybear.ai
Honeybear.ai is an AI tool designed to simplify document reading tasks. It utilizes advanced algorithms to extract and analyze text from various documents, making it easier for users to access and comprehend information. With Honeybear.ai, users can streamline their document processing workflows and enhance productivity.
Golex.AI
Golex.AI is an innovative AI tool designed to streamline document processing and data extraction tasks. It leverages advanced machine learning algorithms to automate the extraction of key information from various types of documents, such as invoices, receipts, and contracts. With its user-friendly interface and powerful OCR technology, Golex.AI simplifies the process of digitizing and organizing documents, saving users valuable time and effort. Whether you are a small business owner, freelancer, or corporate professional, Golex.AI offers a reliable solution for improving efficiency and productivity in document management.
0 - Open Source AI Tools
20 - OpenAI Gpts
kz image 2 typescript 2 image
Generate a Structured description in typescript format from the image and generate an image from that description. and OCR
Veteran's Aid Assistant
Empathetic guide for VA claims, offering precise, reliable assistance.
Loan Management Software
Loan management software expertise. Get the most powerful loan origination and loan servicing software on the market.

Terpene Tracker GPT
Web-enabled cannabis and terpene profile analyzer with image recognition

PMJAY Financial Assistant
Expert in managing and tracking payment recoveries for Hope Hospital.
VA Compensation GPT
Guide on veterans' affairs, focusing on compensation and benefits with updated 38 CFR Part 4.
CT Strain Names GPT 2.0
Translates CT cannabis strain names to true names, with detailed descriptions.
AI Boost Slaughterers and Meat Packers
Feeling Overworked? Let AI help you out! Type "help" for more information.

Abby
Your always-on, always available friendly assistant from BBPD, to help you with all your product queries and orders.


VA: Veterans Benefits Navigator (VBN)
Veterans Benefits Navigator (VBN) is a specialized chatbot designed to guide U.S. veterans through the complexities of VA benefits. It offers tailored, up-to-date information, locates nearest VA facilities, and ensures empathetic, confidential assistance for all benefit-related inquiries.