Best AI tools for< Process Json >
20 - AI tool Sites
Jsonify
Jsonify is an AI tool that automates the process of exploring and understanding websites to find, filter, and extract structured data at scale. It uses AI-powered agents to navigate web content, replacing traditional data scrapers and providing data insights with speed and precision. Jsonify integrates with leading data analysis and business intelligence suites, allowing users to visualize and gain insights into their data easily. The tool offers a no-code dashboard for creating workflows and easily iterating on data tasks. Jsonify is trusted by companies worldwide for its ability to adapt to page changes, learn as it runs, and provide technical and non-technical integrations.
BuildShip
BuildShip is a batch processing tool for ChatGPT that allows users to process ChatGPT tasks in parallel on a spreadsheet UI with CSV/JSON import and export. It supports various OpenAI models, including GPT4, Claude 3, and Gemini. Users can start with readymade templates and customize them with their own logic and models. The data generated is stored securely on the user's own Google Cloud project, and team collaboration is supported with granular access control.

Vavada Casino
Vavada Casino is an online gambling platform that was established in 2017 and quickly gained popularity worldwide. It offers a vast library of 4500 games, operates under a Curacao license, and is known for its reliability and fairness. One of its key advantages is the easy withdrawal process without verification or fees. The platform also provides a unique rewards program for players' achievements. Vavada Casino actively expands its global presence, attracting gamers from various countries and offering a seamless gaming experience.

AI2Page
AI2Page is an advanced AI tool that allows users to easily convert text into structured JSON objects. With its intuitive interface and powerful algorithms, AI2Page simplifies the process of analyzing and extracting information from text data. Users can simply input text, and AI2Page will automatically generate structured JSON output, making it ideal for data extraction, content analysis, and information retrieval tasks. The tool is designed to be user-friendly and efficient, catering to both beginners and experienced users in the field of data analysis and AI applications.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
PDFMerse
PDFMerse is an AI-powered data extraction tool that revolutionizes how users handle document data. It allows users to effortlessly extract information from PDFs with precision, saving time and enhancing workflow. With cutting-edge AI technology, PDFMerse automates data extraction, ensures data accuracy, and offers versatile output formats like CSV, JSON, and Excel. The tool is designed to dramatically reduce processing time and operational costs, enabling users to focus on higher-value tasks.

Fleak AI Workflows
Fleak AI Workflows is a low-code serverless API Builder designed for data teams to effortlessly integrate, consolidate, and scale their data workflows. It simplifies the process of creating, connecting, and deploying workflows in minutes, offering intuitive tools to handle data transformations and integrate AI models seamlessly. Fleak enables users to publish, manage, and monitor APIs effortlessly, without the need for infrastructure requirements. It supports various data types like JSON, SQL, CSV, and Plain Text, and allows integration with large language models, databases, and modern storage technologies.
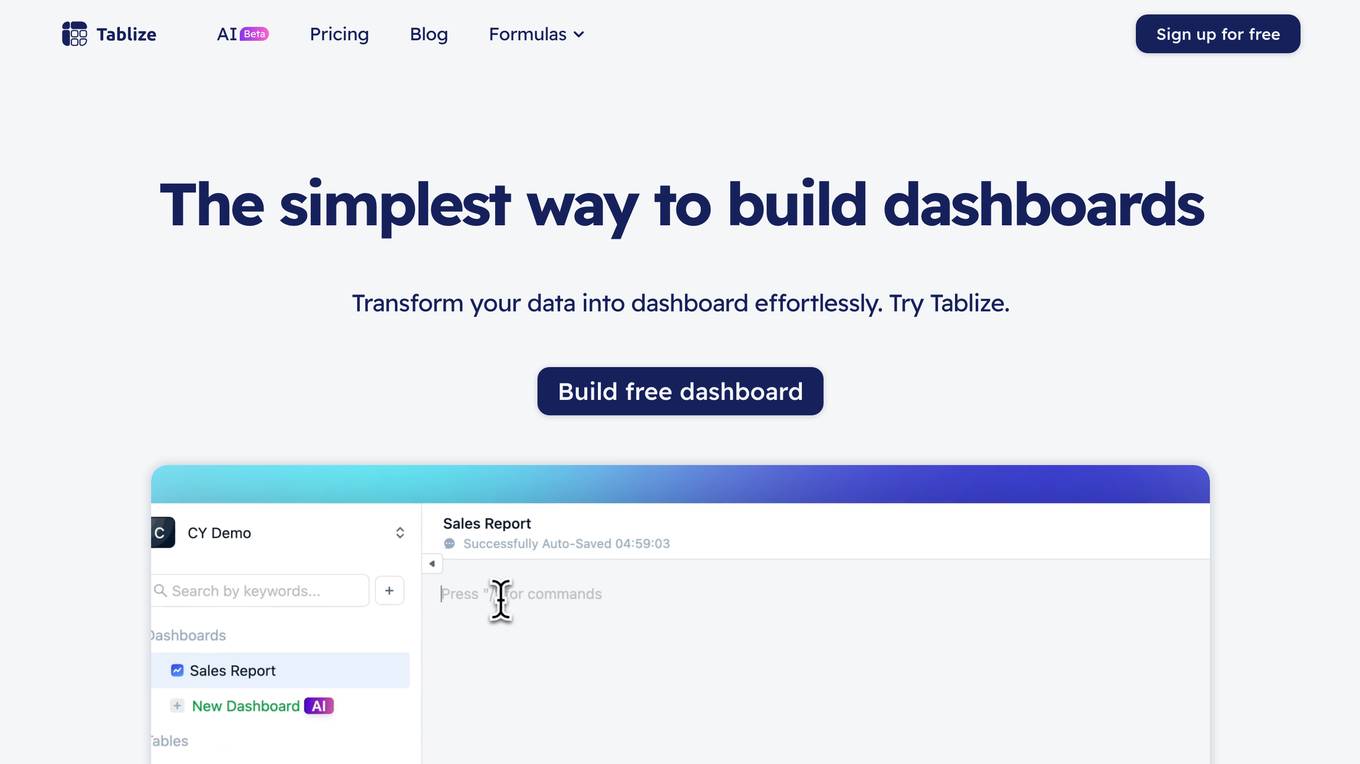
Tablize
Tablize is a powerful data extraction tool that helps you turn unstructured data into structured, tabular format. With Tablize, you can easily extract data from PDFs, images, and websites, and export it to Excel, CSV, or JSON. Tablize uses artificial intelligence to automate the data extraction process, making it fast and easy to get the data you need.
Process Street
Process Street is an AI-powered platform that helps businesses streamline their processes and improve operational efficiency. It offers features such as workflows automation, data unification, document sharing, and AI transformation. With Process Street, users can create, track, and complete tasks efficiently, make data-driven decisions, and automate repetitive tasks using generative AI. The platform also provides analytics to track key performance indicators and ensure consistent adherence to procedures. Process Street is trusted by top companies to revolutionize workflow management and drive productivity and growth.
Process Street
Process Street is a powerful checklist, workflow, and SOP software that is designed to streamline and automate business processes. It offers a wide range of features such as workflows, projects, data sets, forms, and pages to help organizations organize and manage their operations efficiently. With AI capabilities, Process Street can transform manual processes, boost productivity, and empower decision-making with analytics. The platform also provides integrations with various tools for maximum efficiency.
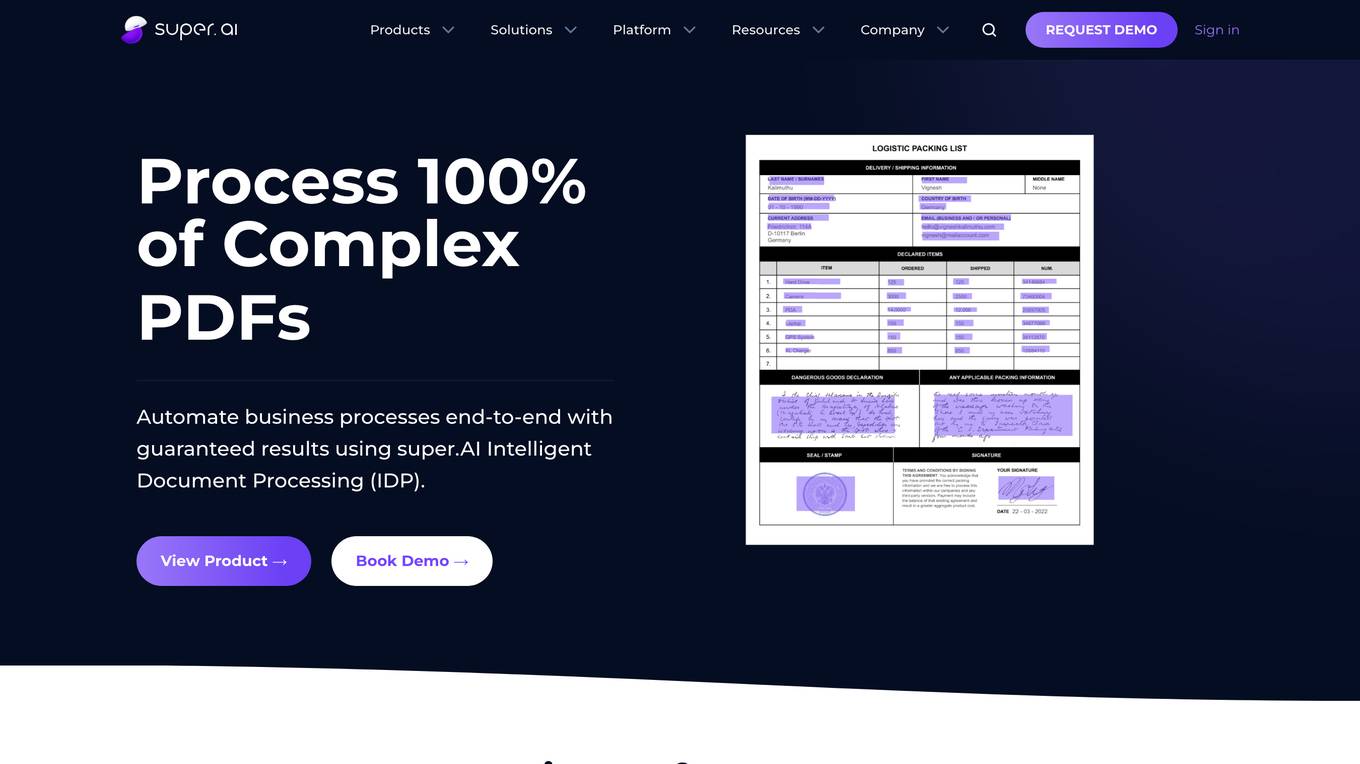
super.AI
Super.AI provides Intelligent Document Processing (IDP) solutions powered by Large Language Models (LLMs) and human-in-the-loop (HITL) capabilities. It automates document processing tasks such as data extraction, classification, and redaction, enabling businesses to streamline their workflows and improve accuracy. Super.AI's platform leverages cutting-edge AI models from providers like Amazon, Google, and OpenAI to handle complex documents, ensuring high-quality outputs. With its focus on accuracy, flexibility, and scalability, Super.AI caters to various industries, including financial services, insurance, logistics, and healthcare.
Smace
Smace is an AI-powered SaaS platform designed to enhance process implementation efficiency. It offers features such as enhanced process collaboration, automated workflows and integration, streamlined task management, and data-driven decision support. Smace aims to bridge the gap between process design and execution, promoting team efficiency, streamlined collaboration, and advanced integration.
Greenhouse
Greenhouse is an AI-powered applicant tracking software and hiring platform that offers smart hiring tools to streamline the hiring process. It provides features such as AI tools for sourcing, texting solutions, and feature upgrades to help connect teams and propel success. Greenhouse is designed to help companies hire fairly and purposefully, offering expertise and advice to maximize hiring ROI and support business growth at any stage.
Expertia AI
Expertia AI is an AI-powered hiring partner that leverages advanced algorithms and machine learning to streamline the recruitment process. It offers a comprehensive suite of tools to assist HR professionals in sourcing, screening, and selecting top talent efficiently. By automating repetitive tasks and providing data-driven insights, Expertia AI helps companies make informed hiring decisions and improve overall recruitment outcomes.

LazyApply
LazyApply is an AI-powered job search tool that automates the job application process across various platforms like Linkedin, Indeed, and Ziprecruiter. It saves users hundreds of hours by streamlining applications through advanced AI job search algorithms and personalized autofill features. With LazyApply, users can apply to multiple jobs with a single click, send smart referral emails, and track all applications and emails in real-time through an analytics dashboard. The tool offers different plans to cater to different needs, with a 30-day money-back guarantee. Thousands of users have successfully automated their job search using LazyApply, resulting in increased interview chances and job offers.

PyjamaHR
PyjamaHR is a leading AI-powered Applicant Tracking System (ATS) and recruitment software designed to streamline the hiring process for businesses of all sizes. It offers advanced features such as source management, candidate evaluation, collaboration tools, and AI-powered candidate tests to enhance the efficiency and effectiveness of the recruitment process. With a user-friendly interface and robust security measures, PyjamaHR is a trusted solution for managing talent acquisition and improving hiring outcomes.
Stockimg AI
Stockimg AI is an all-in-one design and content creation tool powered by AI. It allows users to generate logos, illustrations, wallpapers, posters, and more, manage social media end-to-end, and schedule content endlessly. With integrations supporting over 10 social media platforms, users can automate post scheduling and create stunning designs in minutes. Stockimg AI aims to streamline content production and design processes, helping businesses and brands enhance their online presence efficiently.
MyEssayWriter.ai
MyEssayWriter.ai is an AI-powered essay writing tool that offers advanced features to help students generate high-quality essays efficiently. The tool is designed to save time, improve writing skills, and provide unique and plagiarism-free content. With a user-friendly interface and customizable essays, MyEssayWriter.ai aims to revolutionize the writing process for students worldwide.
La Growth Machine
La Growth Machine is a multichannel sales automation tool that helps users import and enrich leads, automate conversions, manage leads, and analyze performances. It offers features such as LinkedIn Voice Messages, multichannel inbox, calls, automation of actions and messages, AI-powered writing assistance, campaign analysis, lead management, and more. La Growth Machine streamlines operational processes, enhances performance, and centralizes data in one place. With a focus on multi-channel prospecting, the tool aims to increase conversations and opportunities for users. Trusted by over 10,000 professionals, La Growth Machine provides a seamless experience for reaching out to leads across various platforms.
myInterview
myInterview is an AI tool designed for intelligent candidate video screening. It utilizes artificial intelligence to streamline the recruitment process by analyzing video interviews. The tool helps employers efficiently evaluate candidates' communication skills, personality traits, and overall suitability for the job role. With myInterview, organizations can save time and resources typically spent on traditional screening methods, leading to faster hiring decisions and improved candidate experience.
1 - Open Source AI Tools
partialjson
PartialJson is a Python library that allows users to parse partial and incomplete JSON data with ease. With just 3 lines of Python code, users can parse JSON data that may be missing key elements or contain errors. The library provides a simple solution for handling JSON data that may not be well-formed or complete, making it a valuable tool for data processing and manipulation tasks.
20 - OpenAI Gpts
Process Map Optimizer
Upload your process map and I will analyse and suggest improvements
Process Engineering Advisor
Optimizes production processes for improved efficiency and quality.
Customer Service Process Improvement Advisor
Optimizes business operations through process enhancements.

R&D Process Scale-up Advisor
Optimizes production processes for efficient large-scale operations.
Process Optimization Advisor
Improves operational efficiency by optimizing processes and reducing waste.


Manufacturing Process Development Advisor
Optimizes manufacturing processes for efficiency and quality.


Trademarks GPT
Trademark Process Assistant, Not an Attorney & Definitely Not Legal Advice (independently verify info received). Gain insights on U.S. trademark process & concepts, USPTO resources, application steps & more - all while being reminded of the importance of consulting legal pros 4 specific guidance.

Prioritization Matrix Pro
Structured process for prioritizing marketing tasks based on strategic alignment. Outputs in Eisenhower, RACI and other methodologies.

👑 Data Privacy for Insurance Companies 👑
Insurance providers collect and process personal health, financial, and property information, making it crucial to implement comprehensive data protection strategies.

ScriptCraft
To streamline the process of creating scripts for Brut-style videos by providing structured guidance in researching, strategizing, and writing, ensuring the final script is rich in content and visually captivating.
Notes Master
With this bot process of making notes will be easier. Send your text and wait for the result

Cali - ISO 9001 Professor
I will give you all the information about the Audit and Certification process of ISO 9001 Management Systems, either in the form of a specialization course or consultations.