Best AI tools for< Performance Testing >
20 - AI tool Sites
Tricentis
Tricentis is an AI-powered testing tool that offers a comprehensive set of test automation capabilities to address various testing challenges. It provides end-to-end test automation solutions for a wide range of applications, including Salesforce, mobile testing, performance testing, and data integrity testing. Tricentis leverages advanced ML technologies to enable faster and smarter testing, ensuring quality at speed with reduced risk, time, and costs. The platform also offers continuous performance testing, change and data intelligence, and model-based, codeless test automation for mobile applications.
Abstracta Solutions
Abstracta Solutions is an AI software development company that provides holistic solutions for software quality. They offer services such as AI software development, testing strategy, functional testing, test automation, performance testing, tool development, accessibility testing, security testing, and DevOps services. Abstracta Solutions empowers organizations with AI-driven solutions to streamline software development processes and enhance customer experiences. They focus on continuously delivering high-quality software by co-creating quality strategies and leveraging expertise in different areas of software development.
bottest.ai
bottest.ai is an AI-powered chatbot testing tool that focuses on ensuring quality, reliability, and safety in AI-based chatbots. The tool offers automated testing capabilities without the need for coding, making it easy for users to test their chatbots efficiently. With features like regression testing, performance testing, multi-language testing, and AI-powered coverage, bottest.ai provides a comprehensive solution for testing chatbots. Users can record tests, evaluate responses, and improve their chatbots based on analytics provided by the tool. The tool also supports enterprise readiness by allowing scalability, permissions management, and integration with existing workflows.

BlazeMeter
BlazeMeter by Perforce is an AI-powered continuous testing platform designed to automate testing processes and enhance software quality. It offers effortless test creation, seamless test execution, instant issue analysis, and self-sustaining maintenance. BlazeMeter provides a comprehensive solution for performance, functional, scriptless, API testing, and monitoring, along with test data and service virtualization. The platform enables teams to speed up digital transformation, shift quality left, and streamline DevOps practices. With AI analytics, scriptless test creation, and UX testing capabilities, BlazeMeter empowers users to drive innovation, accuracy, and speed in their test automation efforts.
Kobiton
Kobiton is a mobile device testing platform that accelerates app delivery, improves productivity, and maximizes mobile app impact. It offers a comprehensive suite of features for real-device testing, visual testing, performance testing, accessibility testing, and more. With AI-augmented testing and no-code validations, Kobiton helps enterprises streamline continuous delivery of mobile apps. The platform provides secure and scalable device lab management, mobile device cloud, and integration with DevOps toolchain for enhanced productivity and efficiency.
mabl
Mabl is a leading unified test automation platform built on cloud, AI, and low-code innovations that delivers a modern approach ensuring the highest quality software across the entire user journey. Our SaaS platform allows teams to scale functional and non-functional testing across web apps, mobile apps, APIs, performance, and accessibility for best-in-class digital experiences.
Website Builder Hub
Website Builder Hub is an AI-powered website creation platform that offers a user-friendly interface for building professional websites. It provides a range of features such as GPT integration, hiring designers, and discounts on services. The platform aims to help users create visually appealing websites with enhanced SEO capabilities. With a focus on design, customer support, and performance testing, Website Builder Hub assists users in selecting the best website builder for their specific needs.
Sitelifter
Sitelifter is an AI-powered website optimization tool that provides actionable insights to improve design, messaging, and user flow. It helps users save time, reduce costs, and maximize conversions by offering AI-driven recommendations tailored to specific goals and audiences. Sitelifter is designed to be user-friendly and accessible for marketers, startups, freelancers, SaaS companies, and anyone looking to enhance their website performance without extensive testing or hiring consultants.

Webo.AI
Webo.AI is a test automation platform powered by AI that offers a smarter and faster way to conduct testing. It provides generative AI for tailored test cases, AI-powered automation, predictive analysis, and patented AiHealing for test maintenance. Webo.AI aims to reduce test time, production defects, and QA costs while increasing release velocity and software quality. The platform is designed to cater to startups and offers comprehensive test coverage with human-readable AI-generated test cases.
Byterat
Byterat is a cloud-based platform that provides battery data management, visualization, and analytics. It offers an end-to-end data pipeline that automatically synchronizes, processes, and visualizes materials, manufacturing, and test data from all labs. Byterat also provides 24/7 access to experiments from anywhere in the world and integrates seamlessly with current workflows. It is customizable to specific cell chemistries and allows users to build custom visualizations, dashboards, and analyses. Byterat's AI-powered battery research has been published in leading journals, and its team has pioneered a new class of models that extract tell-tale signals of battery health from electrical signals to forecast future performance.
Keak
Keak is the first AI agent designed to continuously improve websites by generating variations through thousands of A/B tests. It automates the process of launching A/B tests, fine-tuning AI models, and self-improving websites. Keak works seamlessly on various platforms and offers a Chrome extension for easy access. With a focus on event tracking and determining winning variations, Keak aims to optimize websites efficiently and effectively.
aqua
aqua is a comprehensive Quality Assurance (QA) management tool designed to streamline testing processes and enhance testing efficiency. It offers a wide range of features such as AI Copilot, bug reporting, test management, requirements management, user acceptance testing, and automation management. aqua caters to various industries including banking, insurance, manufacturing, government, tech companies, and medical sectors, helping organizations improve testing productivity, software quality, and defect detection ratios. The tool integrates with popular platforms like Jira, Jenkins, JMeter, and offers both Cloud and On-Premise deployment options. With AI-enhanced capabilities, aqua aims to make testing faster, more efficient, and error-free.
Giskard
Giskard is an automated Red Teaming platform designed to prevent security vulnerabilities and business compliance failures in AI agents. It offers advanced features for detecting AI vulnerabilities, proactive monitoring, and aligning AI testing with real business requirements. The platform integrates with observability stacks, provides enterprise-grade security, and ensures data protection. Giskard is trusted by enterprise AI teams and has been used to detect over 280,000 AI vulnerabilities.
Webflow Optimize
Webflow Optimize is a website optimization and personalization tool that empowers users to create high-performing sites, analyze site performance, and maximize conversions through testing and personalization. It offers features such as real-time collaboration, shared libraries, CMS management, hosting, security, SEO controls, and integration with various apps. Users can create custom site experiences, track performance, and harness AI for faster results and smarter insights. The tool allows for easy setup of tests, personalized messaging, and monitoring of results to enhance user engagement and boost conversion rates.
CloudExam AI
CloudExam AI is an online testing platform developed by Hanke Numerical Union Technology Co., Ltd. It provides stable and efficient AI online testing services, including intelligent grouping, intelligent monitoring, and intelligent evaluation. The platform ensures test fairness by implementing automatic monitoring level regulations and three random strategies. It prioritizes information security by combining software and hardware to secure data and identity. With global cloud deployment and flexible architecture, it supports hundreds of thousands of concurrent users. CloudExam AI offers features like queue interviews, interactive pen testing, data-driven cockpit, AI grouping, AI monitoring, AI evaluation, random question generation, dual-seat testing, facial recognition, real-time recording, abnormal behavior detection, test pledge book, student information verification, photo uploading for answers, inspection system, device detection, scoring template, ranking of results, SMS/email reminders, screen sharing, student fees, and collaboration with selected schools.

PerfAI.ai
PerfAI.ai is an AI-driven platform that focuses on API privacy, security, and governance. It offers comprehensive solutions to protect SaaS, mobile, and public APIs against AI attacks. The platform delivers privacy-compliant and secure APIs by continuously testing API changes for leaks and vulnerabilities before they go live in production. PerfAI.ai supports top industry standards for privacy, security, and governance testing, automates the generation of custom privacy and security tests, suggests fixes for issues, and generates detailed security and compliance reports.
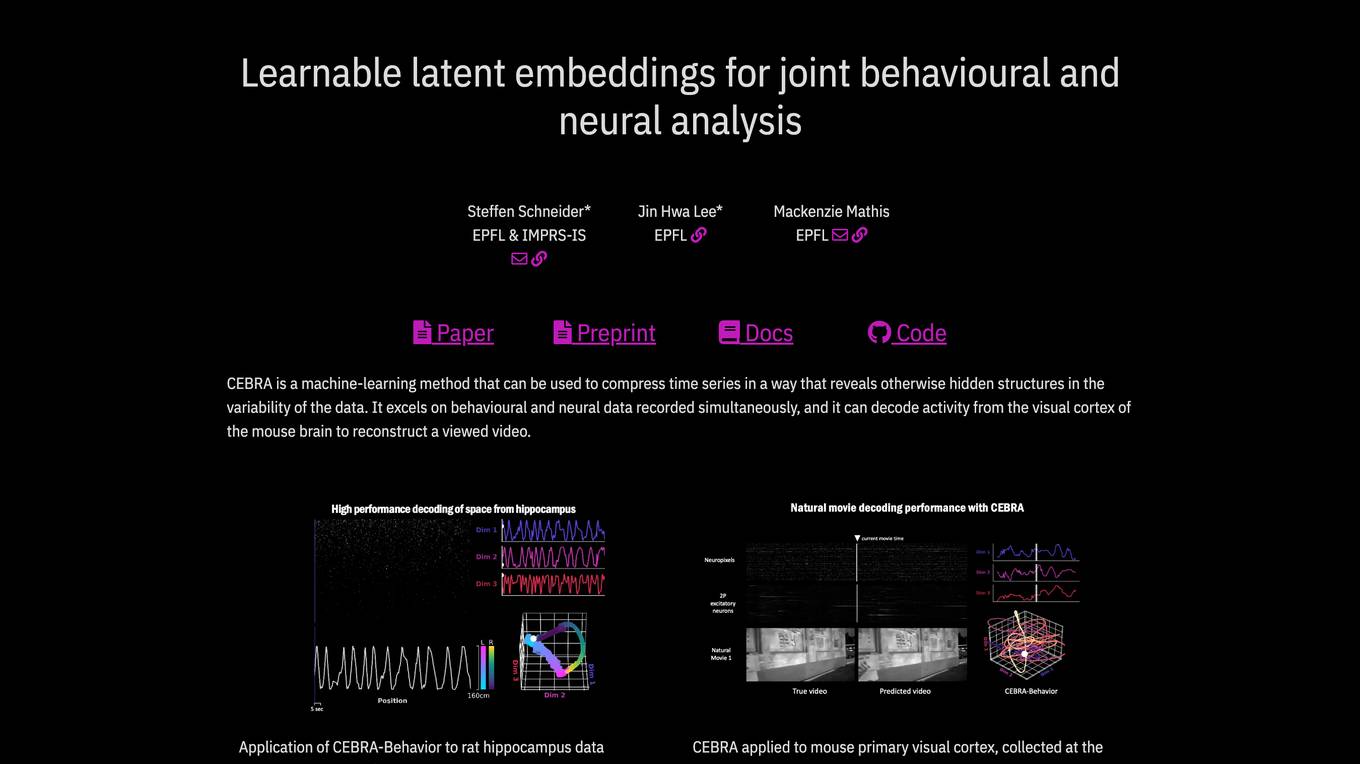
CEBRA
CEBRA is a self-supervised learning algorithm designed for obtaining interpretable embeddings of high-dimensional recordings using auxiliary variables. It excels in compressing time series data to reveal hidden structures, particularly in behavioral and neural data. The algorithm can decode neural activity, reconstruct viewed videos, decode trajectories, and determine position during navigation. CEBRA is a valuable tool for joint behavioral and neural analysis, providing consistent and high-performance latent spaces for hypothesis testing and label-free applications across various datasets and species.
Vocera
Vocera is an AI voice agent testing tool that allows users to test and monitor voice AI agents efficiently. It enables users to launch voice agents in minutes, ensuring a seamless conversational experience. With features like testing against AI-generated datasets, simulating scenarios, and monitoring AI performance, Vocera helps in evaluating and improving voice agent interactions. The tool provides real-time insights, detailed logs, and trend analysis for optimal performance, along with instant notifications for errors and failures. Vocera is designed to work for everyone, offering an intuitive dashboard and data-driven decision-making for continuous improvement.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
Prompt Dev Tool
Prompt Dev Tool is an AI application designed to boost prompt engineering efficiency by helping users create, test, and optimize AI prompts for better results. It offers an intuitive interface, real-time feedback, model comparison, variable testing, prompt iteration, and advanced analytics. The tool is suitable for both beginners and experts, providing detailed insights to enhance AI interactions and improve outcomes.
0 - Open Source AI Tools
20 - OpenAI Gpts
Performance Testing Advisor
Ensures software performance meets organizational standards and expectations.

React Native Testing Library Owl
Assists in writing React Native tests using the React Native Testing Library.

GetPaths
This GPT takes in content related to an application, such as HTTP traffic, JavaScript files, source code, etc., and outputs lists of URLs that can be used for further testing.
IQ Test
IQ Test is designed to simulate an IQ testing environment. It provides a formal and objective experience, delivering questions and processing answers in a straightforward manner.
Ads Incrementality & Campaign Analyst
Expert in ads incrementality and campaign will help you interpret data, forecasting and share you testing frameworks using advanced Python libraries


DevOps Mentor
A formal, expert guide for DevOps pros advancing their skills. Your DevOps GYM
Conversion Rate Pro
Optimize Website Landing Page Conversion Rates. You will use the advice in the provided knowledge base to help optimize website conversion rates. The user can upload screenshots of the landing page and you'll use the knowledge provided to your to recommend the best possible courses of action.
Your Edu Gurus Free SAT Score Calculator & Expert
Upload your SAT score PDF to our calculator and analyze how you did and how to preform better
Performance Controlling Advisor
Drives financial performance improvement via strategic analysis and advice.
Performance Measurement Advisor
Optimizes financial performance through strategic analysis and planning.
Optimisateur de Performance GPT
Expert en optimisation de performance et traitement de données

Java Performance Specialist
Enthusiastic Java code optimizer with a focus on clarity and encouragement.