Best AI tools for< Modularize Project >
5 - AI tool Sites
Convr
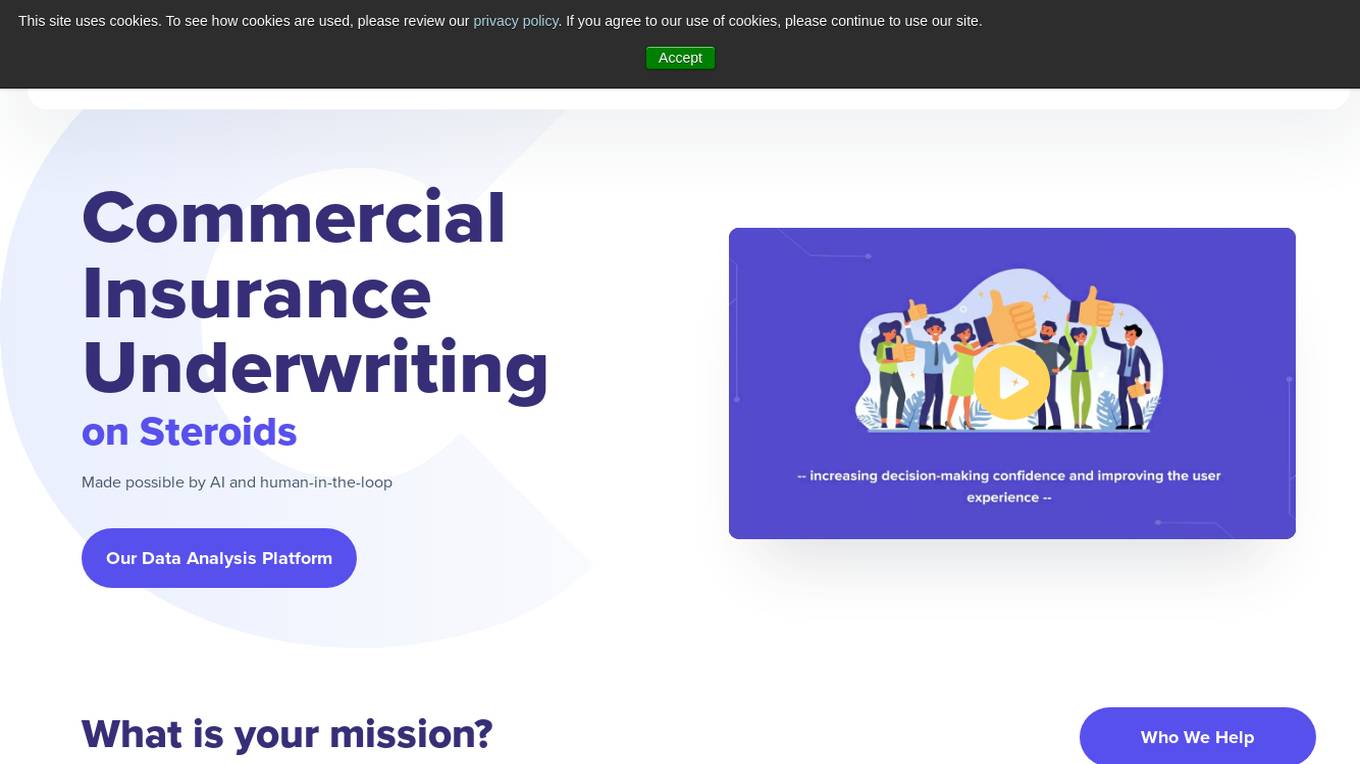
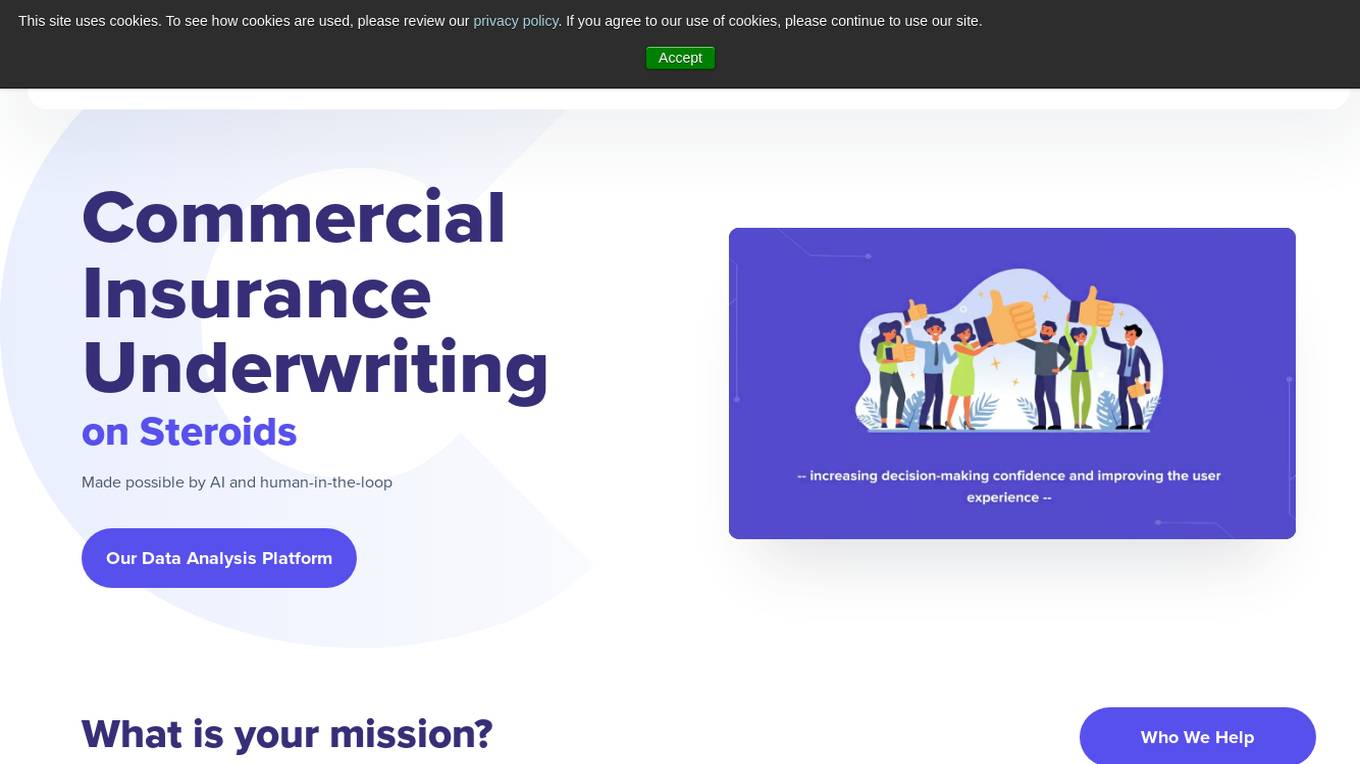
Convr is a modularized AI underwriting and intelligent document automation workbench that enriches and expedites the commercial insurance new business and renewal submission flow with underwriting insights, business classification and risk scoring. As a trusted technology partner and advisor with deep industry expertise, we help insurance organizations transform their underwriting operations through our AI-driven digital underwriting analysis platform.
Convr
Convr is an AI-driven underwriting analysis platform that helps commercial P&C insurance organizations transform their underwriting operations. It provides a modularized AI underwriting and intelligent document automation workbench that enriches and expedites the commercial insurance new business and renewal submission flow with underwriting insights, business classification, and risk scoring. Convr's mission is to solve the last big problem of commercial insurance while improving profitability and increasing efficiency.

Caffe
Caffe is a deep learning framework developed by Berkeley AI Research (BAIR) and community contributors. It is designed for speed, modularity, and expressiveness, allowing users to define models and optimization through configuration without hard-coding. Caffe supports both CPU and GPU training, making it suitable for research experiments and industry deployment. The framework is extensible, actively developed, and tracks the state-of-the-art in code and models. Caffe is widely used in academic research, startup prototypes, and large-scale industrial applications in vision, speech, and multimedia.
Sacred
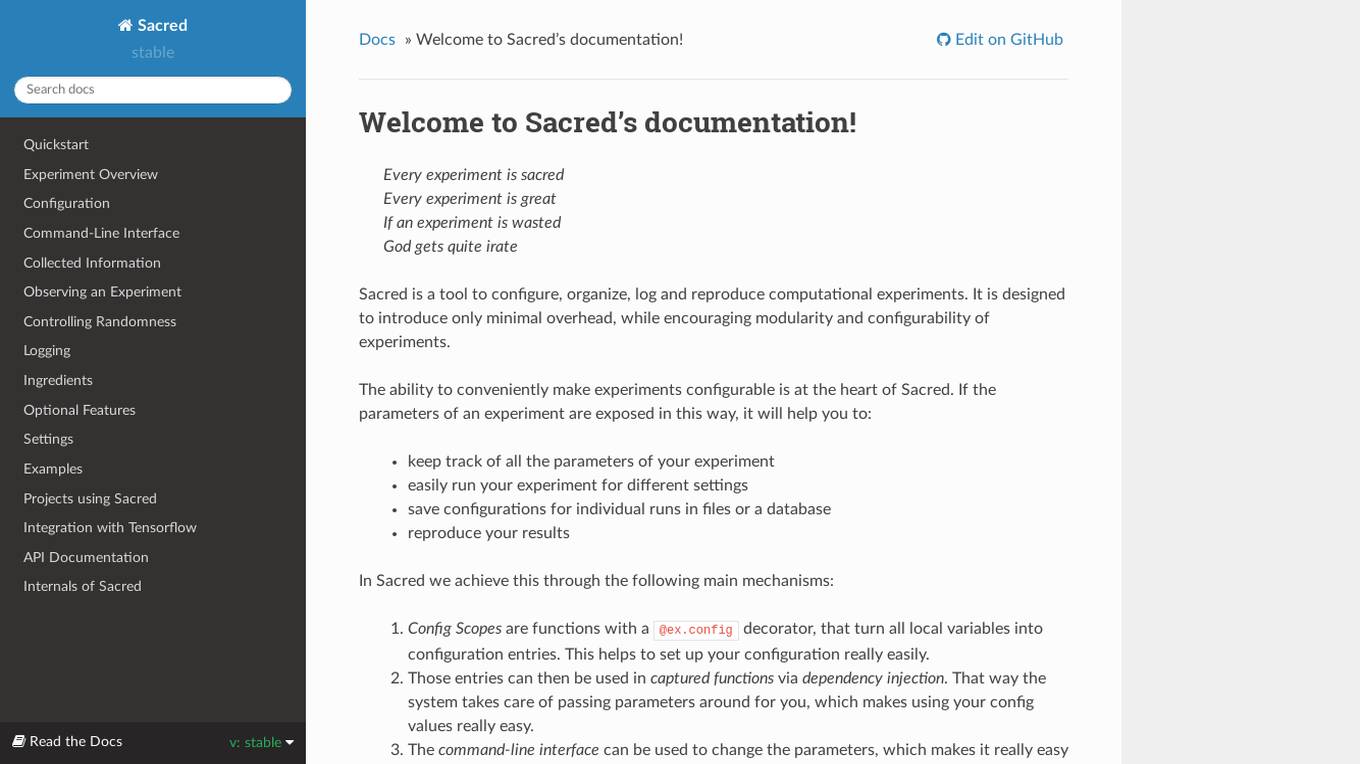
Sacred is a tool to configure, organize, log and reproduce computational experiments. It is designed to introduce only minimal overhead, while encouraging modularity and configurability of experiments. The ability to conveniently make experiments configurable is at the heart of Sacred. If the parameters of an experiment are exposed in this way, it will help you to: keep track of all the parameters of your experiment easily run your experiment for different settings save configurations for individual runs in files or a database reproduce your results In Sacred we achieve this through the following main mechanisms: Config Scopes are functions with a @ex.config decorator, that turn all local variables into configuration entries. This helps to set up your configuration really easily. Those entries can then be used in captured functions via dependency injection. That way the system takes care of passing parameters around for you, which makes using your config values really easy. The command-line interface can be used to change the parameters, which makes it really easy to run your experiment with modified parameters. Observers log every information about your experiment and the configuration you used, and saves them for example to a Database. This helps to keep track of all your experiments. Automatic seeding helps controlling the randomness in your experiments, such that they stay reproducible.
Vilosia
Vilosia is an AI-powered platform that helps medium and large enterprises with internal development teams to visualize their software architecture, simplify migration, and improve system modularity. The platform uses Gen AI to automatically add event triggers to the codebase, enabling users to understand data flow, system dependencies, domain boundaries, and external APIs. Vilosia also offers AI workflow analysis to extract workflows from function call chains and identify database usage. Users can scan their codebase using CLI client & CI/CD integration and stay updated with new features through the newsletter.
1 - Open Source AI Tools
RapidRAG
RapidRAG is a project focused on Knowledge QA with LLM, combining Questions & Answers based on local knowledge base with a large language model. The project aims to provide a flexible and deployment-friendly solution for building a knowledge question answering system. It is modularized, allowing easy replacement of parts and simple code understanding. The tool supports various document formats and can utilize CPU for most parts, with the large language model interface requiring separate deployment.