Best AI tools for< Model Evaluation >
20 - AI tool Sites
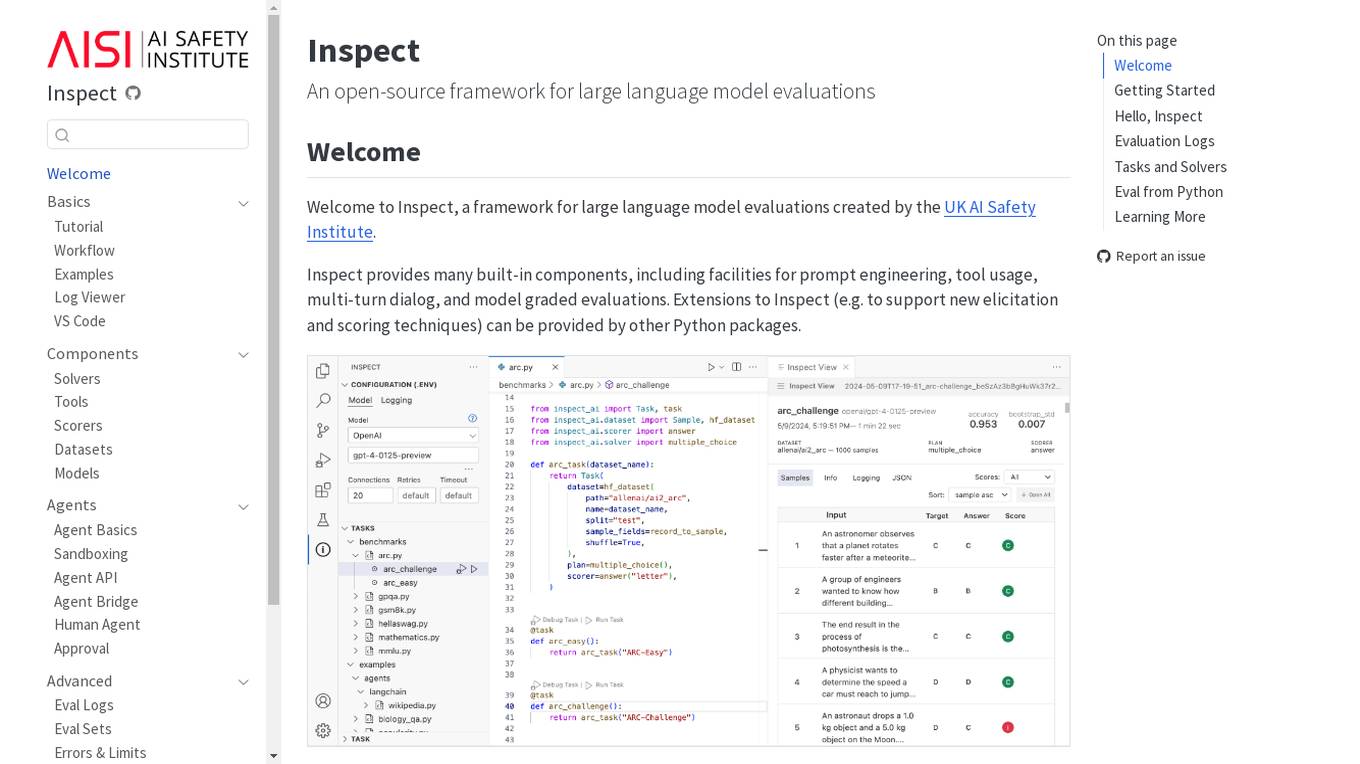
Inspect
Inspect is an open-source framework for large language model evaluations created by the UK AI Safety Institute. It provides built-in components for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations. Users can explore various solvers, tools, scorers, datasets, and models to create advanced evaluations. Inspect supports extensions for new elicitation and scoring techniques through Python packages.
MindpoolAI
MindpoolAI is a tool that allows users to access multiple leading AI models with a single query. This means that users can get the answers they are looking for, spark ideas, and fuel their work, creativity, and curiosity. MindpoolAI is easy to use and does not require any technical expertise. Users simply need to enter their prompt and select the AI models they want to compare. MindpoolAI will then send the query to the selected models and present the results in an easy-to-understand format.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
Encord
Encord is a leading data development platform designed for computer vision and multimodal AI teams. It offers a comprehensive suite of tools to manage, clean, and curate data, streamline labeling and workflow management, and evaluate AI model performance. With features like data indexing, annotation, and active model evaluation, Encord empowers users to accelerate their AI data workflows and build robust models efficiently.

Rawbot
Rawbot is an AI model comparison tool designed to simplify the selection process by enabling users to identify and understand the strengths and weaknesses of various AI models. It allows users to compare AI models based on performance optimization, strengths and weaknesses identification, customization and tuning, cost and efficiency analysis, and informed decision-making. Rawbot is a user-friendly platform that caters to researchers, developers, and business leaders, offering a comprehensive solution for selecting the best AI models tailored to specific needs.
Scale AI
Scale AI is an AI tool that accelerates the development of AI applications for various sectors including enterprise, government, and automotive industries. It offers solutions for training models, fine-tuning, generative AI, and model evaluations. Scale Data Engine and GenAI Platform enable users to leverage enterprise data effectively. The platform collaborates with leading AI models and provides high-quality data for public and private sector applications.
Scale AI
Scale AI is an AI tool that accelerates the development of AI applications for enterprise, government, and automotive sectors. It offers Scale Data Engine for generative AI, Scale GenAI Platform, and evaluation services for model developers. The platform leverages enterprise data to build sustainable AI programs and partners with leading AI models. Scale's focus on generative AI applications, data labeling, and model evaluation sets it apart in the AI industry.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.

HappyML
HappyML is an AI tool designed to assist users in machine learning tasks. It provides a user-friendly interface for running machine learning algorithms without the need for complex coding. With HappyML, users can easily build, train, and deploy machine learning models for various applications. The tool offers a range of features such as data preprocessing, model evaluation, hyperparameter tuning, and model deployment. HappyML simplifies the machine learning process, making it accessible to users with varying levels of expertise.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.
Encord
Encord is a complete data development platform designed for AI applications, specifically tailored for computer vision and multimodal AI teams. It offers tools to intelligently manage, clean, and curate data, streamline labeling and workflow management, and evaluate model performance. Encord aims to unlock the potential of AI for organizations by simplifying data-centric AI pipelines, enabling the building of better models and deploying high-quality production AI faster.

Flow AI
Flow AI is an advanced AI tool designed for evaluating and improving Large Language Model (LLM) applications. It offers a unique system for creating custom evaluators, deploying them with an API, and developing specialized LMs tailored to specific use cases. The tool aims to revolutionize AI evaluation and model development by providing transparent, cost-effective, and controllable solutions for AI teams across various domains.
Weights & Biases
Weights & Biases is an AI tool that offers documentation, guides, tutorials, and support for using AI models in applications. The platform provides two main products: W&B Weave for integrating AI models into code and W&B Models for building custom AI models. Users can access features such as tracing, output evaluation, cost estimates, hyperparameter sweeps, model registry, and more. Weights & Biases aims to simplify the process of working with AI models and improving model reproducibility.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
SDXL Turbo
SDXL Turbo is a cutting-edge text-to-image generation model that leverages Adversarial Diffusion Distillation (ADD) technology for high-quality, real-time image synthesis. Developed by Stability AI, SDXL Turbo is a distilled version of the SDXL 1.0 model, specifically trained for real-time synthesis. It excels in generating photorealistic images from text prompts in a single network evaluation, making it ideal for applications demanding speed and efficiency, such as video games, virtual reality, and instant content creation. SDXL Turbo is accessible to both professionals and hobbyists alike, with simple setup requirements and an intuitive interface. It presents unparalleled opportunities for research and development in advanced AI and image synthesis.
IngestAI
IngestAI is a Silicon Valley-based startup that provides a sophisticated toolbox for data preparation and model selection, powered by proprietary AI algorithms. The company's mission is to make AI accessible and affordable for businesses of all sizes. IngestAI's platform offers a turn-key service tailored for AI builders seeking to optimize AI application development. The company identifies the model best-suited for a customer's needs, ensuring it is designed for high performance and reliability. IngestAI utilizes Deepmark AI, its proprietary software solution, to minimize the time required to identify and deploy the most effective AI solutions. IngestAI also provides data preparation services, transforming raw structured and unstructured data into high-quality, AI-ready formats. This service is meticulously designed to ensure that AI models receive the best possible input, leading to unparalleled performance and accuracy. IngestAI goes beyond mere implementation; the company excels in fine-tuning AI models to ensure that they match the unique nuances of a customer's data and specific demands of their industry. IngestAI rigorously evaluates each AI project, not only ensuring its successful launch but its optimal alignment with a customer's business goals.
Arthur
Arthur is an industry-leading MLOps platform that simplifies deployment, monitoring, and management of traditional and generative AI models. It ensures scalability, security, compliance, and efficient enterprise use. Arthur's turnkey solutions enable companies to integrate the latest generative AI technologies into their operations, making informed, data-driven decisions. The platform offers open-source evaluation products, model-agnostic monitoring, deployment with leading data science tools, and model risk management capabilities. It emphasizes collaboration, security, and compliance with industry standards.
1st things 1st
1st things 1st is an online tool that helps users prioritize tasks and make decisions. It offers two prioritization tools: intuitive and smart. The intuitive tool allows users to compare options in pairs and organize them based on personal preferences. The smart tool uses AI-powered autosuggestion and fast evaluations to help users make confident and informed decisions. 1st things 1st also provides customizable templates and allows users to export their priorities to their favorite productivity apps. The tool is designed to help users clarify their goals, make complex decisions, and achieve their objectives.
How Attractive Am I
How Attractive Am I is an AI-powered tool that analyzes facial features to calculate an attractiveness score. By evaluating symmetry and proportions, the tool provides personalized beauty scores. Users can upload a photo to discover their true beauty potential. The tool ensures accuracy by providing guidelines for taking photos and offers a fun and insightful way to understand facial appeal.
2 - Open Source AI Tools

CuMo
CuMo is a project focused on scaling multimodal Large Language Models (LLMs) with Co-Upcycled Mixture-of-Experts. It introduces CuMo, which incorporates Co-upcycled Top-K sparsely-gated Mixture-of-experts blocks into the vision encoder and the MLP connector, enhancing the capabilities of multimodal LLMs. The project adopts a three-stage training approach with auxiliary losses to stabilize the training process and maintain a balanced loading of experts. CuMo achieves comparable performance to other state-of-the-art multimodal LLMs on various Visual Question Answering (VQA) and visual-instruction-following benchmarks.
BlueLM
BlueLM is a large-scale pre-trained language model developed by vivo AI Global Research Institute, featuring 7B base and chat models. It includes high-quality training data with a token scale of 26 trillion, supporting both Chinese and English languages. BlueLM-7B-Chat excels in C-Eval and CMMLU evaluations, providing strong competition among open-source models of similar size. The models support 32K long texts for better context understanding while maintaining base capabilities. BlueLM welcomes developers for academic research and commercial applications.
20 - OpenAI Gpts

Startup Advisor
Startup advisor guiding founders through detailed idea evaluation, product-market-fit, business model, GTM, and scaling.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model
Startup Critic
Apply gold-standard startup valuation and assessment methods to identify risks and gaps in your business model and product ideas.
Face Rating GPT 😐
Evaluates faces and rates them out of 10 ⭐ Provides valuable feedback to improving your attractiveness!
Financial Modeling GPT
Expert in financial modeling for valuation, budgeting, and forecasting.


Seabiscuit Business Model Master
Discover A More Robust Business: Craft tailored value proposition statements, develop a comprehensive business model canvas, conduct detailed PESTLE analysis, and gain strategic insights on enhancing business model elements like scalability, cost structure, and market competition strategies. (v1.18)

Create A Business Model Canvas For Your Business
Let's get started by telling me about your business: What do you offer? Who do you serve? ------------------------------------------------------- Need help Prompt Engineering? Reach out on LinkedIn: StephenHnilica
BITE Model Analyzer by Dr. Steven Hassan
Discover if your group, relationship or organization uses specific methods to recruit and maintain control over people
EIA model
Generates Environmental impact assessment templates based on specific global locations and parameters.
Business Model Canvas Wizard
Un aiuto a costruire il Business Model Canvas della tua iniziativa
Business Model Advisor
Business model expert, create detailed reports based on business ideas.